基于标记依赖关系集成分类器链的多示例多标签支持向量机算法①
2017-05-17李村合王文杰中国石油大学计算机与通信工程学院青岛266580
李村合, 王文杰(中国石油大学 计算机与通信工程学院, 青岛 266580)
基于标记依赖关系集成分类器链的多示例多标签支持向量机算法①
李村合, 王文杰
(中国石油大学 计算机与通信工程学院, 青岛 266580)
ECC-MIMLSVM+是多示例多标签学习框架下一种算法, 该算法提出了一种基于分类器链的方法, 但其没有充分考虑到标签之间的依赖关系, 而且当标签数目的增多, 子分类器链长度增加, 使得误差传播问题凸显.因此针对此问题, 提出了一种改进算法, 将ECC-MIMLSVM+算法和标签依赖关系相结合, 设计成基于标记依赖关系集成分类器链(ELDCT-MIMLSVM+)来加强标签间信息联系, 避免信息丢失, 提高分类的准确率. 通过实验将本文算法与其他算法进行了对比, 实验结果显示, 本文算法取得了良好的效果.
多示例多标签; 支持向量机; 标签依赖关系; 分类器链
1 引言
在传统监督学习[1]中, 每个对象用一个示例进行描述, 该示例隶属于一个概念标签, 在该框架下对象不具有歧义性. 在多示例学习[2]中, 每个对象由多个示例进行描述, 并且同时隶属于一个概念标签, 其描述对象的内容存在歧义性. 在多标签[3,4]学习中, 每个对象由单个示例描述, 并且隶属于多个概念标签, 其描述对象的概念存在歧义性. 然而在现实生活中的对象通常同时具有内容、概念两方面的歧义性, 因此出现了多示例多标签学习框架(MIML)[5,6].
2007年, 南京大学的周志华等人提出两个多示例多标签支持向量机算法, 分别是MIMLBOOST 算法[6]和MIMLSVM算法[7].
2010年, 河海大学的张敏灵提出MIML-KNN[8]算法, 该算法在K-NN算法基础上的改进算法并应用于MIML学习. 该算法不仅考虑一个样本的近邻(称为neighbors), 还考虑了以该样本为近邻的样本.
2011年, 美国的Nguyen提出的一种新的解决MIML学习问题的SVM算法, SISL-MIML算法[9]. 该算法假设MIML样本中的每一个示例只有一个最准确的与之对应的标签, 因为在传统的MIML样本退化为SISL样本时会丢失信息, 即会标错很多示例的标签.
2013年, 哈尔滨工业大学的Wu等人提出一种基于马尔科夫链的MIML学习算法[10].
鉴于支持向量机(SVM)[11]在解决小样本、非线性及高维模式识别问题中的优势, 因此在多示例多标签学习框架下的许多算法都采用了支持向量机技术, 如E-MIMLSVM+算法[12]等.
然而这些算法通常基于退化策略, 该策略会导致退化过程中有效信息的丢失, 降低了分类准确率. ECC算法[13,14]是对所有的CC模型进行集成学习. 虽然在一定程度上改善退化过程中信息丢失, 但当标签数目的增多, 子分类器链长度增加, 使得误差传播问题凸显.
因此本文提出新算法, 改进了ECC算法误差传播凸显问题,提高分类准确率. ELDCT-MIMLSVM+算法是在训练过程中依次加入依赖程度最大的标签信息.主要目的在于减少其他无关标签的干扰, 避免了信息丢失, 同时也降低因增加子分类链而使误差传播凸显的问题, 从而达到较好的分类效果.
本文的组织结构如下: 第二部分介绍相关工作,第三部分提出改进算法, 第四部分给出了实验结果,第五部分进行了总结.
2 相关工作
在传统监督学习中, 每个对象由一个示例描述并且隶属于一个概念标签, 在该学习框架下, 对象与示例和标签都是一一对应的关系[15], 学习对象不具有歧义性. 其通过已有的部分输入数据与输出标签生成一个函数, 建立输入输出数据间的关系, 将输入数据映射到合适的输出.
在多示例学习中, 每个对象由多个示例描述并且隶属于一个概念标签, 其主要考查了对象在概念空间的歧义性. 多示例学习在给定的多示例数据集合上学习一个映射函数:2x→其中x∈x(j =1,2,...,ni)是第i个包Xi中的一个示例, 每个包⊆X是个示例的集合, y∈{-1,+1}是包X的所属类别. ii
在多标签学习中, 每个对象由单个示例描述并且同时隶属于多个概念标签, 其主要考察对象在语义空间的歧义性. 多标签学习在给定的多标签数据集合上学习一个映射函数x→, 其中x是单个示例描述的对象, Y⊆Yii是对象i所属的类别标签的集合{...},∈Y(k =1,2,...,l). i在现实生活中, 对象往往同时具有概念歧义性和语义歧义性, 为同时考察这两方面的歧义性, 多示例多标签学习框架应运而生. MIML既不像多标签学习中那样将对象仅用单一示例描述引起对象概念信息的丢失[16], 也不像多示例学习中那样仅将对象划分到单个预定义的语义类别引起对象语义信息的丢失. 在该框架下, 每个对象由多个示例表示同时隶属于多个概念标签[17], 因此它能够充分考虑到输入输出空间中的歧义性, 对歧义性对象进行有效地学习. 多示例多标签学习在给定的多示例多标签数据集合上学习一个从示例集合X到标签集合上的映射函数f→, 其中i⊆X是个示例∈x(j =1,2,...,n)的集合i,,...,,⊆Y是与包相关的类别标签∈Y(k =1,2,...,l)的集合{,,...,}. 传i统监督问题、多示例问题、多标签问题都是多示例多标签问题的特殊表示形式, 上述三种问题都可在多示例多标签框架下进行求解.
目前, 在MIML框架下问题的解决方式主要有两种:
一种是基于退化的策略, 将多示例多标签问题退化为多示例或多标签, 再转化为传统监督学习框架下的等价形式进行求解, 如MIMLSVM[7]、MIMLBOOST[6]等算法, 两者分别以多标签学习和多示例学习为桥梁, 将多示例多标签问题退化为传统监督问题进行求解. 但这两种方式在退化过程中都会引起有效信息的丢失, 导致分类效果不理想, 而且针对大规模机器学习问题时有明显不足;
另一种是考察示例与标签之间的关系, 直接设计针对多示例多标签样本的学习算法, 如M3MIML算法[18]. 但这种算法设计难度大, 样本训练时间长, 而且实验证明分类效果不好.
Ying-xin Li和Shui-wang Ji等在果蝇基因表达模式注释的问题中提出基于支持向量机的多示例多标签算法的MIMLSVM+算法[12], 这是一种针对大规模学习问题提出的算法. 该算法具有较低的训练时间和较好的分类效果, 但其没有考虑标签之间的依赖性, 忽略了标签内在联系, 影响力分类准确率.
3 改进的算法
3.1 MIMLSVM+算法(Multi-instance Multi-label SVM for Large-scale Learning)
MIMLSVM+算法同MIMLSVM和MIMLBOOST算法相似是一种基于退化的算法, MIMLSVM+将多示例多标签问题退化为多示例单标签问题进行求解, 该算法主要针对大规模的数据问题. MIMLSVM+算法每次为单个标签训练分类器, 收集所有具有该标签的包为正包, 不具有该标签的包为负包, 得到一系列二类分类任务, 每个任务利用支持向量机处理. 为处理类不平衡问题, MIMLSVM+采用不同的惩罚参数分别应用于正类和负类的松弛条件.
3.1.1 MIMLSVM+算法主要包括以下步骤:
①将多示例多标签退化为二分问题, 对每个二分类问题设计SVM算法进行处理
②处理数据不平衡问题, 在训练过程中优化SVM, 采用“rescaling”(尺度改变)方法来调节惩罚参数大小.
③不同的核函数的计算结果不同, 选取恰当的核函数.
④设计总的分类模型.
3.1.2 MIMLSVM+的惩罚参数
对于每个标签Yy∈, 若1),(=yXiφ, 则说明包iX具有标签y, 若1-),(=yXi
φ
, 表明包iX不具有标签y. MIMLSVM+的相关优化问题为:
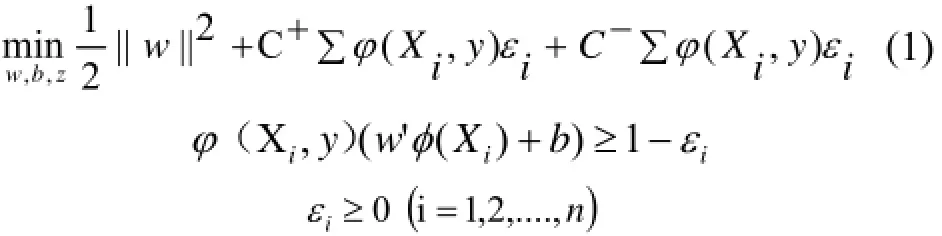
其中, φ(Xi)是将示例包Xi映射到核空间的映射函数, φ(Xi,y)表示包Xi是否具有标签y. εi是hinge loss, n是示例包的数目, w和b是用于表示核空间线性描述函数的参数. C+和C-分别为正类和负类的惩罚因子.
3.1.3 MIMLSVM+的改进
为了增强分类模型的容错率和减少训练样本被错误分类, 我们对算法引入非负松弛变量ξiy. 引入之后将公式转化为:
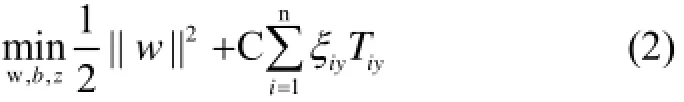
经过上述改进, SVM的优化变为以上问题(MIMLSVM+步骤2).
3.1.4 核函数MIMLSVM+算法采用多示例核函数[19]KMI( X,X′):
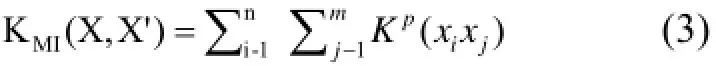
该核函数是通过对标准设置内核函数
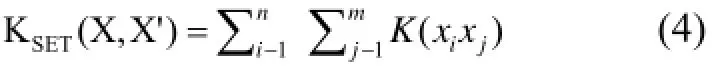
取合适的p值得到的, 其中p≥1, K(.,.)为示例级别的内核.
为进一步利用本地视觉特征和空间特征的信息, MIMLSVM+算法重新定义了核函数
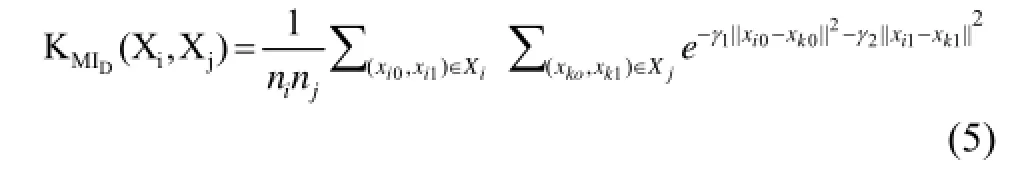
其中||xt0-xk0||衡量了两个图像补丁间本地视觉特征的相似性, ||xti-衡量了两个图像补丁间的的空间距离. 通过调节参数γ1和γ2可对本地视觉特征和空间信息进行显式利用. MIMLSVM+的核函数十分恰当, 所以我们采用其核函数. 最终的判别函数为:
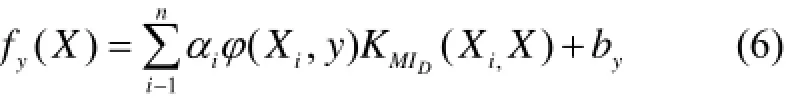
3.2 ELDCC(Ensembles of Label Dependencies Classifier Chain)
MIMLSVM+算法为每个标签建立一个二类分类器, 忽略了标签之间的联系信息, 退化过程中信息丢失, 因此本篇论文提出了基于标记依赖关系的多示例多标签分类器链算法. 本篇文章采用ECC技术对标签间的联系信息加以利用, 并依据某种策略计算标签间的依赖程度值, 根据获得的标签依赖程度组织基分类器链.
ELDCC主要目标是依据标签间的依赖程度的大小依次训练基分类器, 在训练时依次加入依赖程度最大的标签信息, 以达到较好的分类效果. 这样在保持了ECC算法低时间复杂度、低空间复杂度优势的同时,又能够对标签间的依赖关系加以利用, 进一步提高分类的准确率. 该算法不仅能降低时间、空间复杂度, 还能消除标签顺序对分类的影响.
以下是ELDCC算法的主要步骤:
第一步: 计算标签间的依赖程度值.
首先依据表1统计数据集中相应样本的数目. 其中N表示数据集中的样本总数, 各个变量(a/b/c/d)对应在数据集中与两个标记相关的样本的统计量, 例如a表示数据集中同时与标签i和标签j相关的样本个数.
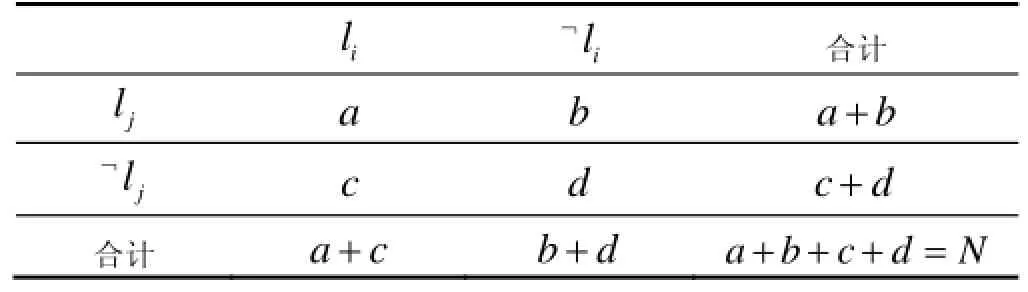
表1 标记和的关联表
获得表1求得的变量值, 依据公式(1)量化标签i与标签j的依赖程度.
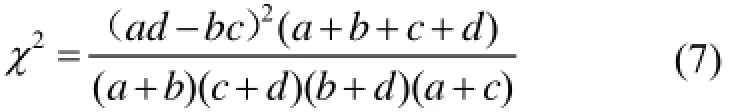
第二步: 随机选择m个标签作为初始根节点, 利用prim算法生成m个有序分类器链.
取依赖程度值的倒数, 利用prim算法获得最小生成树. 集合U是已加入链中的标签, 集合V是待加入标签, 每次从集合V中选取到集合U中依赖程度最大的标签, 并将其加入到集合U中, 更新集合V到集合U中的依赖程度值, 循环直到集合V中所有的标签都加入到集合U中. 将依次加入集合U中标签结点的顺序作为一个分类器链的训练标签的顺序.
第三步: 利用训练样本训练基分类器.
假设共有L个标签, 依据第二步获得的标签顺序C(c1,c2,.....cL)为每个标签构建一个二类分类器, L个二类分类器组成一个有序分类器链. 分类器链中第一个基分类器的输入为初始样本, 其余基分类器的输入为上一个基分类器的输入样本以及该样本相应输出标签的组合, 即:
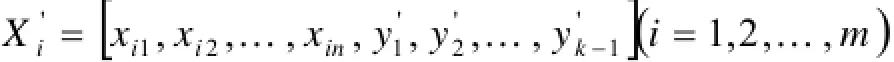
其中Xi表示第i个包, xij为包Xi中的第j个示例, yk是第k个基分类器的输出标签. 鉴于ECC算法是解决单示例多标签问题的算法, 本篇论文采用与ECC-MIMLSVM+算法相同的策略, 对ECC算法加以改造使其适用于解决多示例多标签问题. 即在第k个基分类器训练之前, 首先将标签yk-1扩展为d维向量y=(y,y,......,y)T(k=1,...,L), 其中d为示例的维k-1k-1k-1k-1d数, L为标签的数目.
最终基于新的数据集合训练第k个基分类器.第四步: 置信度的计算.
为取得更准确的分类结果, ELDCC对多个链的输出结果进行汇总. 假设有m个有序分类器链:为m个有序分类器链上的输出. h1,h2......,hm.....y根据公式计算该样本在所有分类器链的平均值.
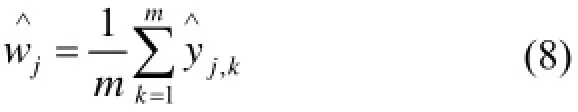
第五步: 确定阈值t.
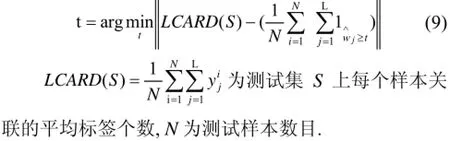
第六步: 计算样本的最终输出.
利用第四步的置信度, 结合第五步的阈值函数计算该样本的最终输出标签. 当第=(,.....,....,) j个标签的置信度大于或等于阈值t时, 第j个标签的最终输出为1, 表明该样本具有第j个标签, 否则该样本在标签j上的输出为0, 表明该样本不具有标签j.
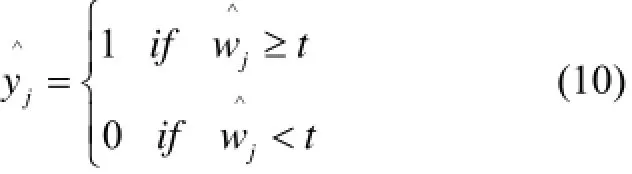
对于一个未知标签的测试样本X, 将样本输入到m个分类器链中. 对应其中的一个分类器链, 在进行第j个标签预测时, 获得对应链第j-1个基分类器的输出值并进行d维扩展获得新的样本将该样本代入第j个标签的分类函数中fj(X′), 获得样本X关于第j个标签的估计值yj. 对于所有的有序分类器链都重复上述过程,将m个分类器链的结果进行计算获得置信向量, 利用置信向量和阈值确定样本的最终输出标签.改进算法的伪代码:

?
1) 将标签数据集O随机分N次, 得到不同的n个数据集L(ii=1,2,…,N).
2) 循环训练集S={(Xi, Yi)}(i=1,2,…,n), 计算多示

?
4 实验
4.1 实验设置
本文使用周志华等人提供的两个数据集(即表2图像样本集和文本样本集特征)进行实验.
表2的scene数据集是图形图像数据集. 该数据集包含2000个场景图像, 其中每个图像都被分配一组标签. 总共5个类别, 分别是海、沙漠、山、树和日落. 其中单标签样本数目1544个, 约占整个样本集数量77%左右; 双标签441, 约占整个样本集数量的22%左右,同时属于三个类的样本数目极少. 平均每个样本与1.24±0.44个类标签有关联. 每幅图片所对应的多示例多标签样本的示例数为9, 本文用一个15维的特征向量表示每一个示例[20].
表二的Reuters是文本数据集, 从Reuters-21578样本集[21]中获得. 我们基于最常用的7个类, 删除部分只属于一个类别的文本, 再删除其中没有类别和没有正文的文本, 总共得到8848个文本. 抽出一部分单标签样本和所有双标签和三标签样本, 得到该样本集所包含2000个文本. 属于多个类的文本数占该数据集的15%左右, 平均每个文本所属的类别数是1.15±0.37.每个文本通过滑动窗口术用一组实例向量表示, 滑动窗口的大小设置为50. 包中的示例采取基于词频的词袋模型进行表示, 将词频为前3%的词汇予以保留[22],最终包中的每个示例都由243维的特征向量进行表示.
把本文提出的ELDCT-MIMLSVM+算法跟、MIMLSVM+、MIMLBOOST与MIMLSVM算法进行对比. MIMLBOOST和MIMLSVM算法的参数分别根据文献[6]和[12]设置为它们的最佳值, MIMLSVM的高斯核为γ=0.22, MIMLBOOST的boosting rounds的值设为25. 为了保证实验客观正确, ELDCT-MIMLSVM+算法和MIMLSVM+算法的gamma=le-5. 比较四种算法的平均分类表现.
这四种多示例多标签算法的评价指标采用五个标准的多示例评价指标: one-error、average precision、hamming loss、ranking loss和coverage. 对于这五个评价指标, 简单来说one-error、hamming loss、ranking loss和coverage这四个值越小说明算法效果越好; 而average precision则值越大说明算法效果越好.

表2 图像样本集和文本样本集特征
4.2 实验结果
表3和表4分别显示了四种不同的多示例多标签算法在图像数据集和文本数据集上的实验结果.
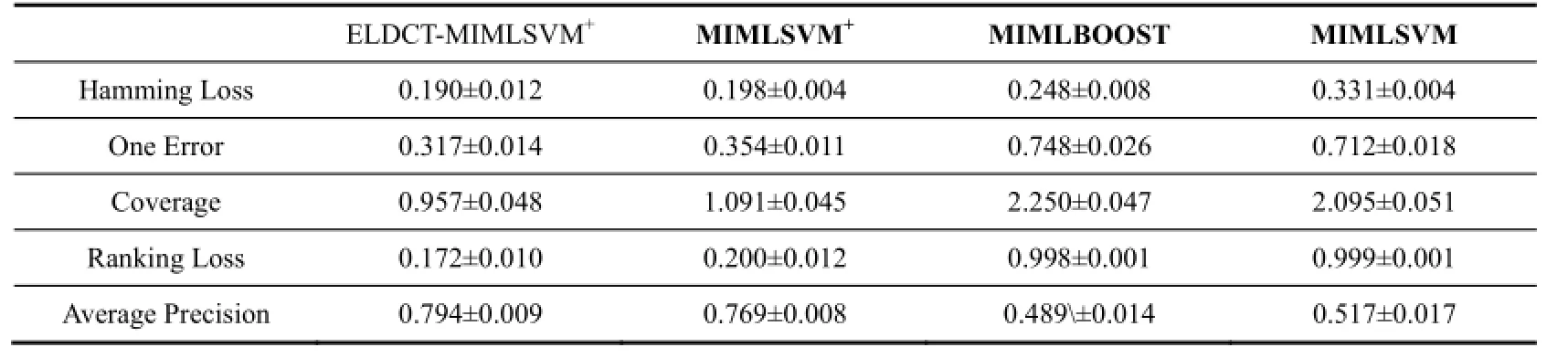
表3 场图形图像样本集实验结果
从表3可以看出, 在图像数据集上, ELDCT-MIMLSVM+算法略好于MIMLSVM+, 对于MIMLBOOST和MIMLSVM有明显的优势.
图形图像样本的分类复杂, 计算数据量大. MIMLSVM+算法主要是为大规模机器学习设计的算法, 采用了SVM来提高分类, 所以其效率要好于MIMLBOOST和MIMLSVM. ELDCT-MIMLSVM+采用了分类器链技术, 也是将问题退化为传统的机器学习. ELDCT-MIMLSVM+与其它算法不同在于, 在退化过程中依次加入标签之间的依赖关系, 增强了标签之间联系, 所以可以取得比较好的效果.
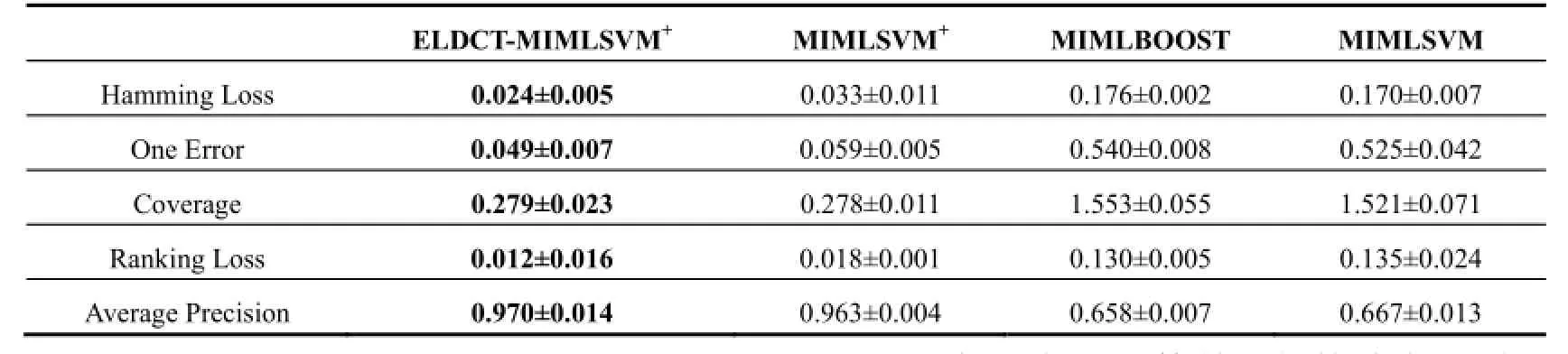
表4 文本样本集实验结果
从表4可以看出, 在文本数据集上, ELDCT-MIMLSVM+算法的前四项指标均小于其他各项算法, Average precision大于其他算法, 所有指标在四种算法中表现最佳.
文本分类相对简单, 各算法之间差距比较小. SVM在二分问题上有巨大的优势, ELDCT-MIMLSVM+采用了SVM技术, 将问题二分然后再求解, 体现SVM优势, 效果明显.

表5 算法在图像数据集上的训练时间对比
从表5可以看出, 在图形图像数据集上ELDCT-MIMLSVM+的训练时间和测试时间比MIMLSVM+差,略微优于MIMLSVM, 对MIMLBOOST有比较明显的优势.
ELDCT-MIMLSVM+采用分类器链设计模式, 当子分类器链增加, 耗时就会比较多. 更重要的是ELDCT-MIMLSVM+比MIMLSVM多一步计算标签之间依赖关系, 这增加了计算量. 所以在训练时间上会比MIMLSVM+多.

表6 四种算法在文本数据集上的训练时间对比
从表6可以看出, 在文本数据集上, MIMLSVM+的训练时间和测试时间最少, ELDCT-MIMLSVM+的训练时间小于MIMLSVM, 但测试时间比MIMLSVM多. 效率最低的是MIMLBOOST.
与在图形图像数据集一样, ELDCT-MIMLSVM+多一步计算标签依赖关系, 所以耗时较多, 但这一步骤增强标签之间联系, 提高了分类准确率. 如果在强调准确率而不是对时间有特别严格的要求, ELDCT-MIMLSVM+算法是首选.
5 总结
从上面数据分析可知, 对于图像数据集和文本数据集, 在保证训练时间和测试时间的前提下, ELDCT-MIMLSVM+算法的准确率略优于MIMLSVM+,明显高于另外两种算法, 并且ELDCT-MIMLSVM+在各项指标中表现优异. 因此, 我们可推出结论: ELDCT-MIMLSVM+算法在训练过程中可以依据标签依赖关系, 逐步加入依赖程度较大标签的信息来辅助分类器训练学习, 从而进一步提高分类器分类的准确率.
1 Kotsiantis SB, Zaharakis I, Pintelas P. Supervised machine learning: A review of classification techniques. Informatica, 2007, 31(3): 249–268
2 Dietterich TG, Lathrop RH, Lozano-Pérez T. Solving the multiple-instance problem with axis-parallel rectangles. Artificial Intelligence, 1997, 89(1-2): 31–71.
3 Boutell MR, Luo J, Shen X, Brown CM. Learning multi-label scene classification. Pattern Recognition, 2004, 37(9): 1757–1771.
4 Schapire RE, Singer Y. BoosTexter: A boosting-based system for text categorization. Machine Learning, 2000, 39(2-3): 135–168.
5 Zhou ZH. A Framework for machine learning with ambiguous objects. Proc. Brain Informatics, International Conference(BI 2009). Beijing, China. 2009. 5819. 6–6
6 Zhou ZH, Zhang ML, Huang SJ, et al. Multi-instance multi-label learning. Artificial Intelligence, 2012, 176(1): 2291–2320
7 Zhou ZH, Zhang ML. Multi-instance Multi-label learning with application to scene classification. The Neural Information Processing Systems, 2006: 1609–1616.
8 Zhang ML. A k-nearest neighbor based multi-instance multi-label learning algorithm. 22ND International Conference on Tools with Artificial Intelligence. 2010, 2. 207–212.
9 Nguyen N. A new SVM approach to multi-instance multi-label learning. 2010 IEEE International Conference on Data Mining. 2010. 109.
10 Wu QY, Ng MK, Ye YM. Markov-MIML: A Markov chain-based multi-instance multi-label learning algorithm. Knowledge and Information System, 2013, 37(1): 83–104.
11 Vapnik V. The Nature of Statistical Learning Theory. Springer-Verlag, 1995.
12 Li YX, Ji SW, Kumar S, Ye JP, Zhou ZH. Drosophila gene expression pattern annotation through multi-instance multi-label learning. Trans. on Computational Biology and Bioinformatics, 2012: 98–111.
13 Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification. Machine Learning, 2011, 85(3): 254–269.
14 Briggs F, Fern XZ, Raich R. Context-aware MIML instance annotation: exploiting label correlations with classifier chains. Knowledge and Information Systems, 2015, 43(1): 53–79
15 Platt JC. Fast training of support vector machines using sequential minimal optimization. Advances in Kernel Methods-Support Vector Rning. MIT Press, 1999: 185–208
16 Gǎrtner T, Flach PA, Smola AJ. Multi-instance kernels. Proc. of the 19th Intenational Conference on Machine Learning. Sydney, Australia. 2002. 179–186.
17 Yakhnenko O, Honavar V. Multi-instance multi-label learning for image classification with large vocabularies. BMVC. 2011. 1–12
18 Pei Y, Fern XZ. Constrained instance clustering in multi-instance multi-label learning. Pattern Recognition Letters, 2014, 37(1): 107–114.
19 Zhang ML, Zhou ZH. M3MIML: A maximum margin method for multi-instance multi-label learning. Proc. of the 8th IEEE International Conference on Data Mining (ICDM’08). Pisa, Italy. 2008. 688–697.
20 Haussler D. Convolution kernels on discrete structures, [Technical Report]. UCSC-CRL-99-10. Dept. of Computer Science, Univ. of California at Santa Cruz. Santa Cruz, CA. July 1999.
21 Sebastiani F. Machine learning in automated text categorization. ACM Computing Surveys, 2002, 34(1): 1–47.
22 Andrews S, Tsochantaridis I, Hofmann T. Support vector machines for multiple-instance learning. Advances 696 in Neural Information Processing Systems 15, 2003: 561–568.
23 Yang Y, Pedersen JO. A comparative study on feature selection in text categorization. Proc. of the 14th International Conference on Machine Learning. Nashville, TN. 1997. 412–420.
Multi-Instance Multi-Label Support Vector Machine Algorithm Based on Labeled Dependency Relation Ensemble Classifier Chain
LI Cun-He, WANG Wen-Jie
(College of Computer and Communication Engineering, China University of Petroleum, Qingdao 266580, China)
ECC-MIMLSVM+is an algorithm of multi-instance and multi-label learning framework. This algorithm proposes a method based on classifier chain, but it does not consider the dependencies between labels. When the number of tags increases, the length of the sub classifier chain also increases, making the error propagation problem prominent. Therefore, this paper presents a kind of improved algorithm, combining ECC-MIMLSVM+algorithm and the label dependencies. ELDCT-MIMLSVM+algorithm is designed, which is based on ensembles of label dependencies classifier chain to avoid the information loss and improve the classification accuracy. The experiment results show that the algorithm has good effect.
multi-instance multi-label; SVM; ensembles of label dependencies; classifier chains
2016-07-24;收到修改稿时间:2016-08-22
10.15888/j.cnki.csa.005686
