云计算环境下医院档案信息管理系统研究
2017-05-13赵海静王永峰张新平
赵海静,王永峰,张 娟,张新平
(河北省人民医院 河北 石家庄 050000)
云计算环境下医院档案信息管理系统研究
赵海静,王永峰,张 娟,张新平
(河北省人民医院 河北 石家庄 050000)
针对医院档案信息数据提取复杂度高的问题,本研究将医院的档案信息分为文字信息和数字信息,提出了一套基于云计算环境下的档案信息管理系统,利用线性归一化和非线性归一化对文字信息进行去噪预处理,结合外边框和质心归一化进行文字信息的数据提取;针对字符信息利用点阵图和字符轮廓平滑处理,将字符的轮廓获取和存储进行特征值提取。通过设计医院档案信息的容器编码,并结合分布式关联数据库以供信息的汇总和共享,方便了系统管理员对档案信息的综合调度使用。在对医院档案信息数据提取实验测试,结果显示:初步识别提取率与综合数据提取率均分别保持在90%和80%以上,并且云计算数据提取效率明显高于电子标签(RFID)数据提取。
云计算;文字提取;字符提取;档案信息;编码设计
随着计算机网络的迅速发展,我国的各类档案信息管理不断推入云计算系统[1-3]。在系统的运行和管理过程中,档案信息依靠计算机数据挖掘技术[4],不仅提升了整体的档案信息管理水平,还促进了档案管理人员的工作效率。档案信息的数字化为信息系统管理的自动化和智能化带来了便利,目前的档案信息管理系统主要依靠电子标签(RFID)[5]、二维码[6]和Web Service[7]等技术。相比已有研究,文中从数据挖掘技术的云计算理念出发,对档案中的文字信息利用外边框和质心归一化处理,对字符信息利用点阵图和字符轮廓平滑处理,将档案中的信息进行有效提取。结合医院的档案信息管理系统的特点,分别设计了档案录入、删减、编辑权限,给出了档案信息编码准则,并在分布式数据库结构下建立起医院档案信息管理数据库。该云计算下的档案信息管理系统提高了医院信息档案管理效率。
1 档案的云计算数据提取
1.1 文字信息提取
通过将档案中待对序列的文字进行输入之后,最先进行的重要环节是对档案信息输入进行预处理。在预处理的环节中主要任务是去除获取信息中的白噪声,这样的预处理步骤主要用于提取关键信息[8]。对信息的关联程度进行筛选和加强,主要的预处理的方法是利用线性归一化和非线性归一化的方法,通过这样的变量工具使得处理后的信息和图像相对的便于识别和稳定,增强系统的管理识别能力[9]。对于医院档案中的图像信息,通过字符图像的方式进行线性规划的处理。归一化相对于不同的问题其含义有所不同,在进行医院档案信息处理的过程中,通过将汉字的信息字符构成的点阵图移动到既定的方位和区域,以此来消除汉字字符在点阵图上的位置偏差,这样的过程即完成了整个位置归一化的处理。一般来说位置归一化的方法最常用的分为两种[10]:以文字外边框为参考物进行位置的归一处理;以质心为参考物进行位置的归一处理。以文字外边框为参考物进行位置的归一处理方法首先需要计算出文字的外边框,然后将基于外边框的文字中心找到,最后的步骤是将基于外边框的文字中心移动到既定的位置和区域上;以质心为参考物进行位置的归一处理方法首先需要计算出汉字的质心,再然后将汉字的质心移动到既定的位置和区域上[11]。在本文中主要采用基于外边框的文字位置归一化和线性大小归一化相结合的方法进行处理,利用这样的方法进行信息的提取和管理之前,需要对等待识别的文字字符和图像字符进行归一化的处理,首先将其转化为规格标准的大小,然后才能进行系统特征值的提取。其次,对等待识别的文字的位置进行归一化的处理,将等待识别文字的边框提取出来,再将四周边框中间的点阵图获取储存。最后的环节是对获取储存的四周边框中间的点阵图进行线性大小的归一化处理,从而得到标准点阵图。具体表达式如下:

其中,s是在上一个环节获取的文字边框内的点阵,s*是进行线性大小归一化处理后的点阵,h和w分别是s的高和宽,h*和w*分别是s*的高和宽。
1.2 字符信息提取
在进行了文字信息的预处理后还需要对字符的轮廓进行提取,若白点的四周在四个方位邻接着一个黑点,那么这个黑点就是轮廓上的点[12]。通过在字符轮廓上的黑点提取系统的特征向量,实际上也可以通过从字符的构架上提取系统的特征向量,但通常情况下字符中存在一定的污点[13]。因此,采取后者的方法往往会丢失字符污点处的关键信息。有些情况下存在字符损坏严重的情况,这样的情况下仍然可以对存在的笔画和轮廓中提取系统的特征[14]。对字符的轮廓获取和存储之后则可以进行特征值提取[15],通常此时的字符轮廓容易产生毛刺,多是因为成像质量欠佳存在干扰因素等原因,因此在本文中将采用模板法对处理中的特征值提取环节之间进行平滑处理以消除类似的影响,将轮廓边缘进行平滑性处理。黑点轮廓中需要平滑的点与之相对应的经过模板法平滑处理后的点的排列情况,如图1所示。

图1 消除轮廓中直角边平滑处理的前后对比
图1中,黑色的点代表黑的像素,空白的区域代表白的像素,九方格能够表示两种像素,即可以代表黑像素也可以代表白像素。对于字符轮廓中存在的每一个黑点。首先都要将其四周的8个相邻像素进行考察。当图像中的黑点同四周的相邻像素的排列组合与图中的任意一个相吻合那么需要将这个黑的像素变为白的像素。当字符轮廓四周的相邻像素排列组合与某一个黑像素的排列相同,则抹去此黑像素,利用图1的排列情况经过平滑处理来代替之前的黑像素,字符轮廓中的直角能够被全部抹除,用于消除字符轮廓中微小的突起。
2 系统设计
2.1 档案管理
在医院的档案信息管理系统中,操作管理人员拥有与档案管理有关的各种操作权限,例如档案录入、档案删减、档案编辑等权限,从而提高了医院信息档案管理效率。
1)档案录入:医院的档案信息操作管理人员通过信息管理系统平台对医院病人信息等资料进行档案信息数据库的筛选和查找,并对每一份档案进行独立编号以确保没有重复档号。接着按照医院信息管理系统的编程算法和医院的相关档案调档条例进行相应的检测,如若不存在错误,则由医院的档案信息操作管理人员将新的档案信息录入到档案信息数据库当中并与用户进行关联。
2)档案删减:医院的档案信息操作管理人员通过信息管理系统平台登陆档案数据库,并对需要删减的档案进行筛选,如若存在需要删减的档案则由档案信息操作管理人员从数据库中将其删除。
3)档案编辑:医院的档案信息操作管理人员通过信息管理系统平台登陆档案数据库,并对需要编辑的档案进行筛选,如若存在需要重新编辑和修改的档案则由档案信息操作管理人员在数据库进行编辑和修改以完成数据库的更新,避免错误档案信息的发生。档案管理的具体操作流程如图2所示。

图2 档案添加数据流图
2.2 编码设计
为了保证医院档案信息管理系统的良好运转,一个必要条件就是容器编码[16]。文中设计了医院档案信息管理系统的一些常用和主要的编码,其具体的编码的准则定义如下:
以医院人力资源部门的的统一编码为用户和操作人员进行编码为例,以4位编码为各个部门进行编码。第1~2位代表单位编号,第3~4位表示职员的班组编号,用大小写的字母表示。例如:21Aa表示Aa组,21Ab表示Ab组。利用3位编码来为功能进行编码:第1~2位代表功能模块编号,第3位表示在此功能模块下的进行操作的编号,利用大写英文字母表示,A表示档案录入权限,B表示档案编辑权限,C表示档案删减权限,D表示档案查询权限。例如:03B表示具有3号功能模块的档案删减权限,图纸编码可直接从系统中截取,也可使用现有的产品编码规则。用户的编码规则使用8位数字型编码,系统的编码规则使用8位数字型编码。模块的编码规则使用4位数字型编码。角色的编码规则使用4位字母型编码。
2.3 数据库设计
在计算机的存储设备上通过按照一定的规则存放在关联的数据所构成的集合构成了带有鲜明特征的数据库。通过这样的规则所构成的数据库主要有收集信息、数据信息组织、信号存储、数据加工、筛选和传播信息的主要功能。由于负责上述的数据库特有功能,数据库设计的完善程度将会对信息管理系统产生多方面性能的影响。为了更加方便的实现对档案数据信息的汇总和传播共享,因而在分布式的数据库环境下建立起医院档案信息管理数据库将更加便捷。在医院档案信息管理系统的操作流程中,纸质档案的设置具体如表1所示。

表1 纸质信息数据设置
3 系统测试
针对医院档案信息的数据提取测试如下:档案的分类包括病人的病例信息、医院工作人员信息和医院物资信息等不同种类,首先通过文字信息和字符信息提取对测试则的不同样本进行初步识别提取,样本为各类型待识别纸质档案。初步识别提取的效果如表2所示。
由表2可得,在1 070张医院档案纸质信息中,成功识别了1 003张,未识别63张。其中,各样本的初步识别提取率均在90%以上,总样本提取率为93.69%。在纸质档案信息初步识别提取后,继续对提取的样本进行数据提取。结果如表3所示。
由表3可得,在已成功识别的1003张医院档案纸质信息中,各样本的再次数据提取率和综合提取率分别均在90%和83%以上,总样本提取率和总样本综合提取率分别为94.12%和88.17%。通过档案系统的流程设计,从档案管理员的信息录入到系统管理员的综合运维,对100张医院纸质档案信息进行数据提取,分别利用本研究提出的云计算数据提取与电子标签(RFID)数据提取性能重复进行10次测试,如图3所示。
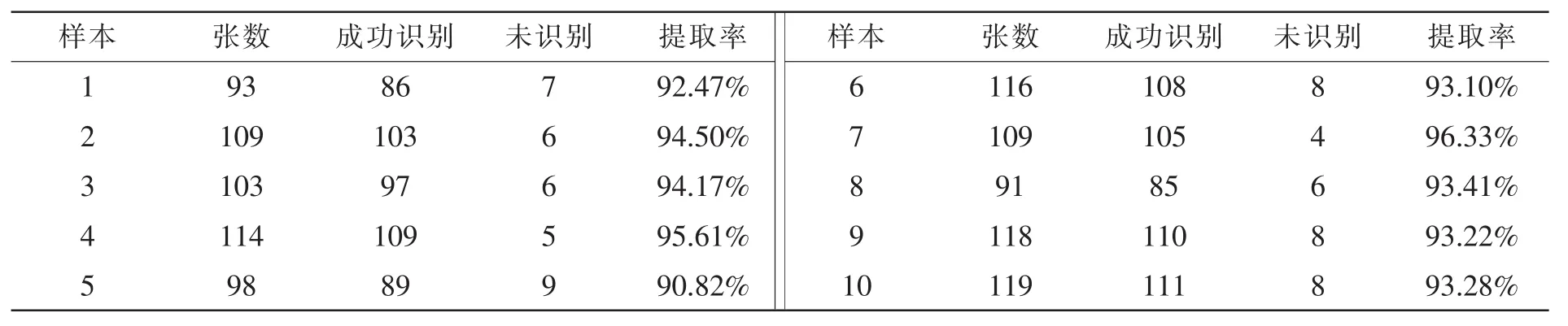
表2 初步提取效果

表3 综合提取效果

图3 数据提取量性能比较
由图3可见,对100张医院纸质档案信息提取过程中,本研究使用的云计算数据提取量明显高于电子标签(RFID)数据提取。对于较少页数的纸质档案信息,使用电子标签(RFID)数据提取效果高于云计算数据提取;而对于类似医院档案信息量巨大的操作业务压力,使用云计算数据提取可以有效的提高档案信息的录入效率,为医院档案信息管理系统的综合信息汇总和共享提供了便利。
通过对本研究设计的医院档案信息管理系统的数据提取性能测试表明,各类型档案信息数据提取率较高,对于拒绝识别的纸质档案出现报错信息,这是由于数据量巨大超过了终端计算机运行的速度出现的响应不及时。而医院的纸质档案信息的识别与分组储存对于文字信息和字符信息具有较高的数据识别提取功能,经过初步提取和综合提取的处理后,最高的提取率可达到90%以上,这对于医院档案信息包含众多复杂数据提取具有较好的处理效果。数据信息提取测试也说明了,当医院原有的纸质档案信息出现文字和字符不清晰时,数据的识别提取仍然不能很好的进行。因此,在医院档案信息录入与综合管理过程中,本研究可以提升医院信息档案管理效率,但还需要档案管理人员的输入和审核确认来确保档案信息管理系统的准确性。
4 结 论
本研究针对传统医院纸质档案数据录入信息管理系统的问题,开发了一套云计算环境下的数据信息提取录入设计。首先,将档案信息分为文字信息和数字信息分别进行数据提取录入。在对文字信息去噪预处理后,考虑文字信息外边框和质心之间的关系,利用点阵图线性归一化原理对文字信息的数据进行提取。在对字符信息提取过程中,从字符的构架上提取系统的特征向量并采用模板法对数据特征值进行平滑处理。其次,根据医院档案信息管理系统流程操作和纸质档案信息数据类型,设计了一套针对医院档案数据信息录入容器编码。最后,通过模拟不同类型的医院档案信息录入性能测试结果表明,对于医院纸质档案数据提取率高,数据提取量大,为医院的数字化档案信息管理提供了有价值的参考。
[1]崔海莉,张惠达.云计算环境下档案信息管理系统风险分析[J].档案学研究,2013(1):56-60.
[2]鞠国山,王俊,范吉峰.基于RFID技术的档案信息管理自动化系统[J].中国数字电视,2012(2):89-91.
[3]曹吉超,孙帅.智能档案馆与数字档案馆辨析[J].办公自动化,2013(12):17-19.
[4]於立勇.计算机数据挖掘技术应用在档案信息管理系统中的探讨[J].电脑知识与技术,2012,8(1): 260-261.
[5]范浩明.电子标签(RFID)技术在档案管理自动化系统中的应用[J].电视工程,2012(1):29-30.
[6]李朝洋,袁海琼.基于二维码技术的档案信息管理系统研究与设计[J].兰台世界,2013(9):23-24.
[7]李仕琼.数据挖掘技术在档案信息管理系统中的应用分析[J].科技展望,2015(1):53-57.
[8]易剑,彭宇新,肖建国.基于颜色聚类和多帧融合的视频文字识别方法[J].软件学报,2011,22(12): 2919-2933.
[9]刘英杰,杨风暴,吉琳娜,等.一种古建墙壁受污题记文字图像边缘提取方法[J].图学学报,2015(5):783-788.
[10]贾建忠,孙萍.脱机维吾尔文组合特征提取及模糊聚类识别[J].新疆大学学报(自然科学版),2013(3):347-353.
[11]徐凌,王江晴,李波.基于骨架平滑与均匀膨胀的女书轮廓字形生成方法[J].科学技术与工程,2014,14(34):229-234.
[12]王忠飞,陈元正.基于轮廓特征的车牌英文和数字识别方法[J].浙江工业大学学报,2015,43(5): 522-526.
[13]何兆成,佘锡伟,余文进,等.字符多特征提取方法及其在车牌识别中的应用[J].计算机工程与应用,2011,47(23):228-231.
[14]高保平,白瑞林,温振市.基于轮廓层次和小波分析的工业字符识别 [J].计算机工程与设计,2012,33(6):2423-2427
[15]殷羽,郑宏,王静,等.一种自适应烟标字符提取方法[J].计算机应用研究,2015,32(4):1248-1252.
[16]申利峰,戴萌,宋亚峰,等.基于信息自动识别技术的核燃料仓储管理标准化[J].核标准计量与质量,2014(1):26-32.
Research on management system of file information of hospital with cloud computing environment
ZHAO Hai-jing,WANG Yong-feng,ZHANG Juan,ZHANG Xin-ping
(Veteran Cadres of Hebei Provincial People's Hospital,Shijiazhuang 050000,China)
For the problem of hospital records information data extraction of high complexity,the study will be divided into text files hospital information and digital information,a set of file-based information management system for cloud computing environment,the use of linear and non-linear normalization normalization of text messages denoising pretreatment,combined with external borders and the centroid of the normalized data for text information extraction;smoothing process for the use of bitmap character information and character outline,the outline of the character is captured and stored eigenvalue extract. Hospital records through the container code design information,combined with the distributed relational database for aggregation and sharing of information,facilitate system administrators to archive information integrated scheduling use.In the archives of the hospital information data extraction experimental test results show that:the extraction rate of the initial recognition and integrated data extraction rates were maintained at above 90%and 80%,and cloud computing data extraction efficiencysignificantly higher than the electronic tags(RFID)data extraction.
cloud computing;text extraction;extracting character;file information;coding design
TN914.3
A
1674-6236(2017)09-0014-04
2016-08-07稿件编号:201608052
国家自然科学基金项目资助(81071710)
赵海静(1983—),女,河北石家庄人,硕士,档案管理员。研究方向:档案管理。
