Hadoop日志压缩算法的研究与实现
2017-05-12王煜骢
王煜骢
(四川大学计算机学院,成都 610065)
Hadoop日志压缩算法的研究与实现
王煜骢
(四川大学计算机学院,成都 610065)
Hadoop集群由于规模增大、运行时间增长使得日志量持续增加,导致存储压力过大。为了节约存储资源,研究并实现一种高效的Hadoop日志无损压缩算法。实验结果表明,该压缩算法与传统的LZW压缩算法的压缩比基本相同,但压缩和解压操作的耗时均小于LZW压缩算法且受文件大小影响更小。
Hadoop;日志;压缩
0 引言
Hadoop[1]作为目前较为流行的分布式计算框架,已被广泛地应用于大数据处理。为了方便用户使用及调试,Hadoop会将其自身的运行状况以日志的形式写入磁盘,主要包括:各类守护进程的运行日志、MapReduce作业的运行日志等。当Hadoop集群规模增大及其使用时间的增长,日志的产生量会急剧增加,从而对磁盘存储造成极大的压力。
为了解决 Hadoop日志过大的问题,本文对Hadoop的日志结构进行了分析,并根据其特点,设计并实现了一种高效的无损压缩算法,对日志进行压缩以节省存储资源,同时保证解压缩过程的高速性。
1 Hadoop日志结构分析
Hadoop日志信息通过Log4j[2]产生,其具体格式为%d{ISO8601}%p%c:%m%n,具体参数说明如下:
●%d:日志时间点的日期或时间,默认格式为ISO8601
●%p:级别,包括:DEBUG,INFO,WARN,ERROR,FATAL
●%c:所属的类,通常为所在类全名
●%m:代码中输出的信息
●%n:回车换行符
由此可知,Hadoop日志信息的具体结构如下:
日志产生时间+空格+级别+空格+所在类全名+冒号+空格+代码输出信息+回车换行符
因此,本文将该日志信息切分为4部分:日志产生时间、级别、所在类全名、代码输出信息。其中,日志产生时间又可分为日志产生日期与具体时间,因此又将日志产生时间分为两块:日志产生日期与日志产生时间(精确到毫秒)。
通过分析Hadoop具体的日志,发现日志产生日期、优先级、所在类全名重复率较高,因此,本文最终采用基于字典的方式实现Hadoop日志压缩算法。
2 Hadoop压缩算法
2.1 压缩算法实现
本文提出的压缩算法基于字典方式实现,建立了三张字典:mDate(用于存放日志产生时间)、mLevel(用于存放日志级别)、mName(用于存放所在类全名)。每张字典的表项为一个序号,用于区分与检索。
压缩算法的具体执行流程如图1所示,首先判断每一行中的数据是否为日志信息,若是则对其进行解析并进行切分,否则直接将其写入缓存;然后判断字典中是否已包含切分得到的值,若有则从字典中提取相应序号进行编码,否则分配新序号进行编码并更新字典;接着将编码后的内容写入缓存,若文件已压缩完成,则先将字典写入文件头部,然后再写入缓存中的压缩内容。
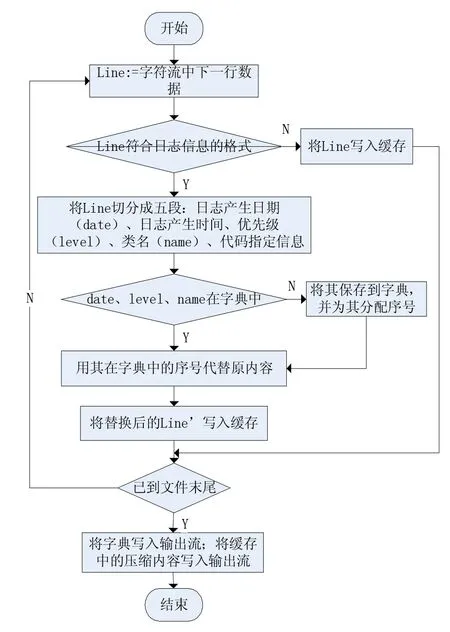
图1 压缩算法执行流程图
2.2 解压算法实现
解压算法的具体执行流程如图2所示,解压时首先读取相应的三张字典(mDate、mLevel、mName),并将其加载进入内存,然后判断读入的每一行是否符合日志消息格式,若是,则根据字典将压缩后内容中的序号替换为其在字典中对应的内容后写入解压缩文件,否则直接将该行写入解压缩文件。
3 实验
本文实验环境包含一台主机,其CPU为Intel Core i5-3230M CPU 2.60GHz,内存为4GB,系统为64位Window7版。本文设计的压缩算法利用了Java编程语言实现,JDK版本为1.7,堆大小配置如下:-Xms512m–Xmx512。
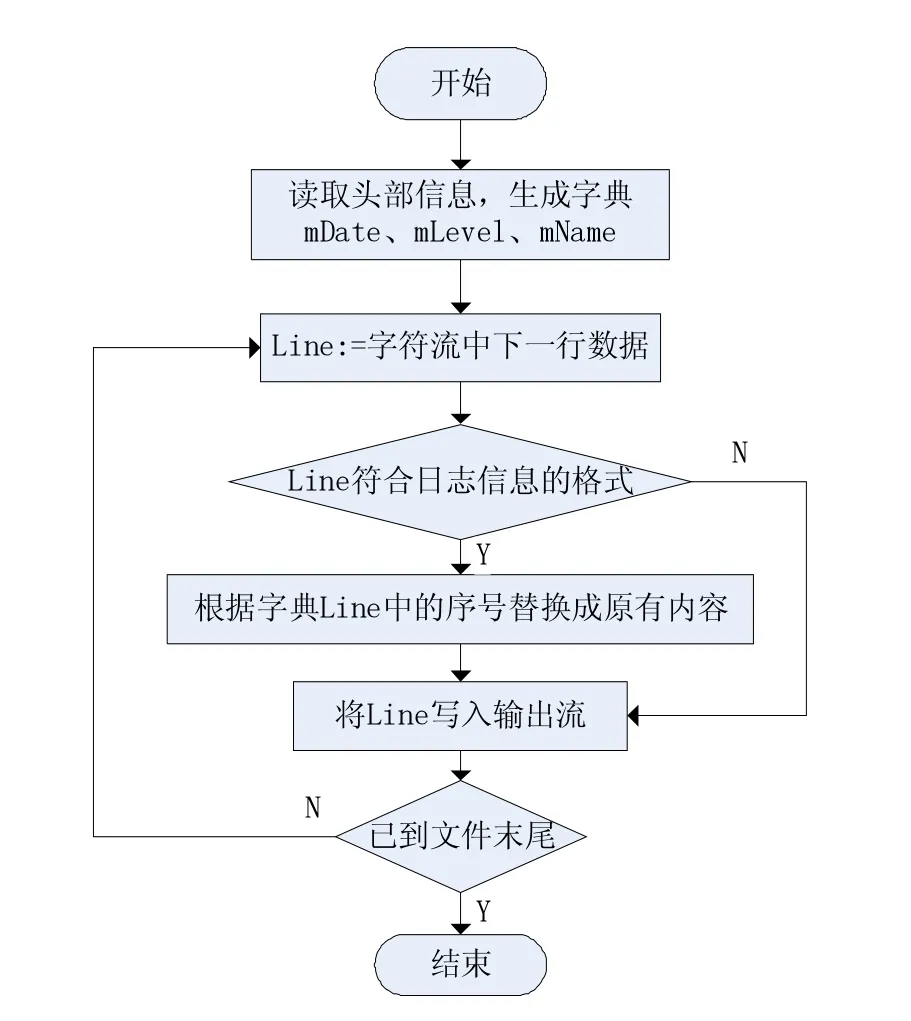
图2 解压算法执行流程图
为了测试该算法性能,本文将其与传统的LZW压缩算法[3]进行了比较,具体做法是:利用两种算法分别对6个不同大小的Hadoop日志文件进行压缩和解压,记录了二者压缩和解压分别消耗的时间,并对比了二者的压缩比 (压缩比=压缩后文件大小/压缩前文件大小),各类测试分别进行了6次实验,结果取其平均值。
本文提出的算法和LZW算法对不同文件大小的压缩比对比结果如图3所示,由结果可见,两种算法对于不同大小的Hadoop日志文件的压缩比基本相同。
本文提出的算法和LZW算法对不同文件大小的压缩、解压操作耗时对比结果如图4所示,LZW压缩算法随着日志文件的增大,压缩及解压操作耗时均会线性增长,而本文提出的压缩算法压缩及解压操作均较为快速,同时,日志文件增大时,压缩及解压操作基本不受影响,耗时变化不大。
4 结语
本文首先研究了Hadoop日志的组成结构,然后对其日志特点进行了分析,最后基于字典方式设计并实现了一种高效的Hadoop日志无损压缩算法。通过测试可知,该算法压缩及解压速度快于LZW压缩算法,且压缩比与其基本相同,同时Hadoop日志文件增大对压缩、解压缩过程的耗时影响较小。

图3 本文算法与LZW算法的压缩比对比图
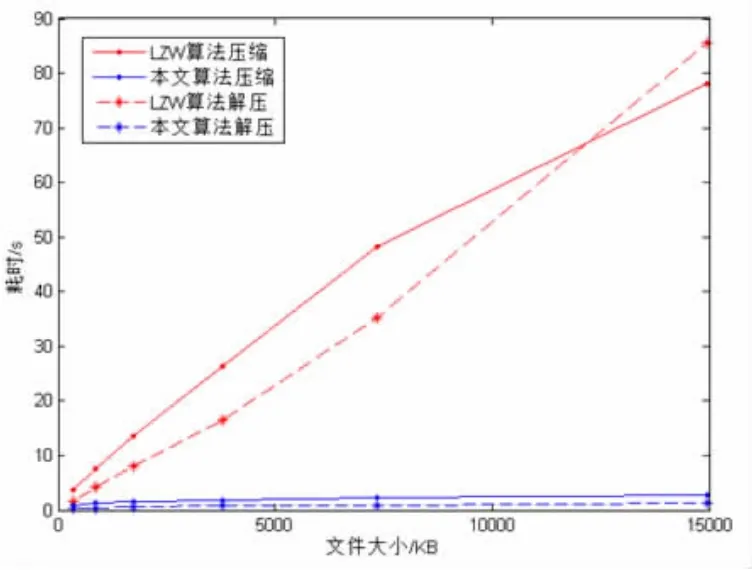
图4 本文算法与LZW算法的解、压缩平均耗时对比图
[1]Apache Hadoop Home Page[EB/OL].[2017-1-27].http://hadoop.apache.org.
[2]Apache Log4j Home Page[EB/OL].[2017-1-27].http://logging.apache.org/log4j/1.2/.
[3]Welch T A.A technique for high-performance data compression[J].Computer,1984,6(17):8-19.
Research and Implementation of Hadoop Log Compression Algorithm
WANG Yu-cong
(College of Computer Science,Sichuan University,Chengdu 610065)
The increased size and run-time growth of Hadoop cluster make the log data continued to increase,which leads to the large storage pressure.In order to save storage resources,studies an efficiently lossless compression algorithm of Hadoop log.The results show that the compression algorithm proposed is basically the same as the compression ratio of LZW compression algorithm,but the compression,decompression operation time of the proposed algorithm is much shorter than the LZW compression algorithm,and the proposed algorithm is less affected by the file size.
Hadoop;Log;Compress
1007-1423(2017)09-0134-03
10.3969/j.issn.1007-1423.2017.09.031
王煜骢(1991-),男,江苏无锡人,在校学生,研究方向为分布式处理
2017-03-09
2017-03-15
