大伙房水库水质预测中水文水质模型联合应用分析
2017-05-09陈俊
陈 俊
(辽宁省抚顺水文局,辽宁 抚顺 113015)
大伙房水库水质预测中水文水质模型联合应用分析
陈 俊
(辽宁省抚顺水文局,辽宁 抚顺 113015)
水质是水库运行质量的重要参考标准,水质的检测项目包括水中所溶解的氧气含量、磷的含量、叶绿素a的含量以及水体透明度等,通过对这些指标的检测来评价水体的富营养化程度。文章使用了线性回归分析法,对参数进行了优化,并建立多种数学模型,利用现有的检测数据对大伙房水库的水质进行预测,并通过一些误差计算方式对预测的结果进行评价。根据预测结果与评价结果,自适应神经模糊推理数据预测模型对水质的预测效果要比多元化线性预测模型以及径向基神经预测模型要好,所以对大伙房水库的水质预测结果以自适应神经模糊推理数据预测模型的预测结果为参考标准。
水质预测;自适应神经模糊推理;大伙房水库;多元线性预测
1 工程概况
大伙房水库位于浑河流域、抚顺市的东部,1958年建设完成并投入使用,坝顶高度为139.8m,长度为1366.7m,宽度为8m,水坝高度约为50m,水库总容量约为22.7亿m2,水体深度最深为36.5m,总储水面积为113km2,水库正常水位标准为130m,死水位为107m,是一座集防洪、供水、发电等多种功能于一体的综合型水利工程[1]。
2 水质取样与测量数据分析
如图1所示,在大伙房水库分别设置5个水质取样点,测量项目包括水体透明度x1、水体温度x2、水体酸碱度x3、水体电导率x4、水体溶氧量x5、水体含磷量x6、水体叶绿素a含量x7、浑浊度x8、悬浮物x9、水体含氮量x10、水体钙镁化合物含量x11、总碱度x12等12种水质因子[2],经过分析处理以后所得到的结果如表1所示。
3 建立水质预测模型
3.1 多元线性预测模型
多元线性预测模型是利用函数关系建立起因变量与多个自变量之间的数学关系模型,其中因变量y即待预测的数据,而自变量则是影响因变量数值的多种因素[3]。因变量与自变量之间的关系用公式表示为:
y=b0+b1x1+b2x2+…+bixi
(1)
式中:xi指的是第i种影响因素,即第i项自变量;bi即第i项自变量所对应的自变量系数。
3.2 径向基神经预测模型
径向基神经预测网络是通过函数逼近的方法在输入端、输出端以及隐藏部分之间进行线性映像和组合[4]。输入端将函数进行非线性变换以后传输到隐藏层,然后输出端从隐藏层的函数中进行变量提取,并进行线性组合最后得到输出数值。隐藏层的维度要比较高,才能保证输出数值的准确性。对此,可以将高斯函数作为径向基神经预测模型的基础,单一变量在m个隐藏层中的公式表示方式为:
(2)
(3)
(4)
式中:x为输入的自变向量;ωi为隐藏层与输出端之间的权重;ci为隐藏层中第i个核心向量;dmax是输入向量与核心向量之间的最大距离;x-ci的绝对值是指x与ci之间的欧几里得距离。
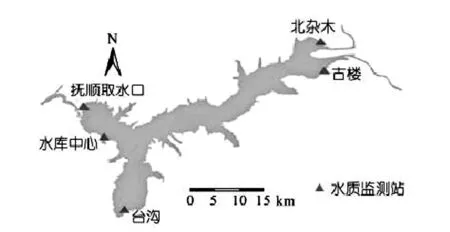
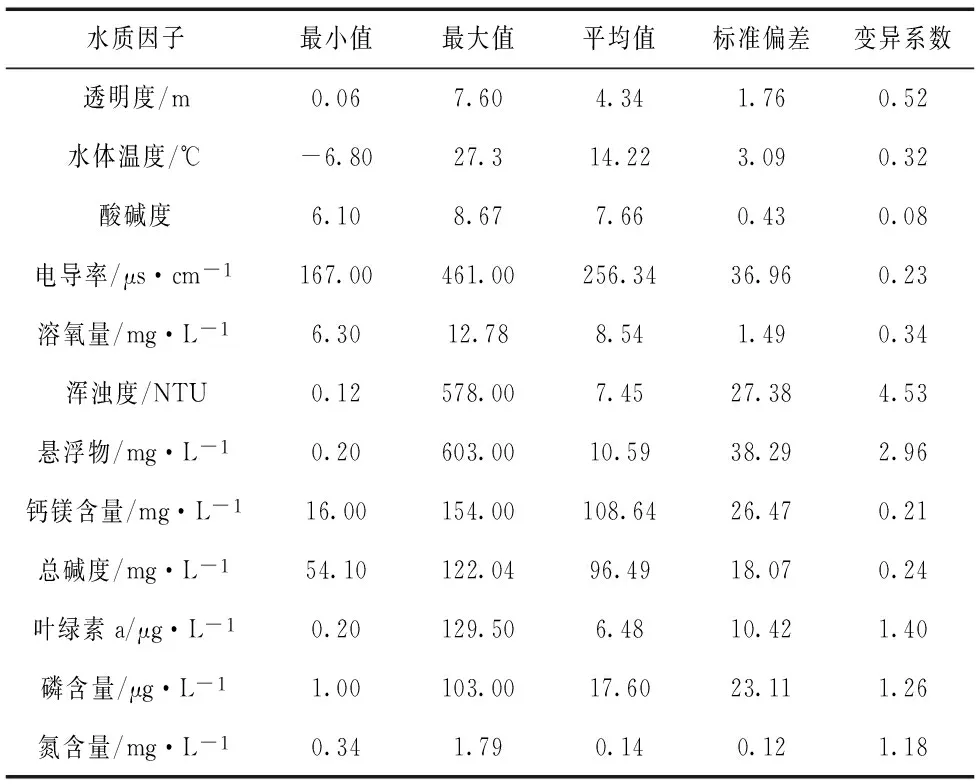
图1 大伙房水库水质取样点分布表1 大伙房水质检测项目检测结果
3.3 自适应神经模糊推理数据预测模型
径向基神经预测模型虽然具有极强的数据组织能力和逻辑推理能力,但是对于已经定性的数据却无法很好地进行处理。所以,以模糊推理为理论基础,再加入自组织特性,构建自适应神经模糊推理数据预测模型[5]。自适应神经模糊推理数据预测模型相比径向基神经预测模型而言,新增了规则模块、正规化模块以及解模糊模块,具体结构如图3所示。
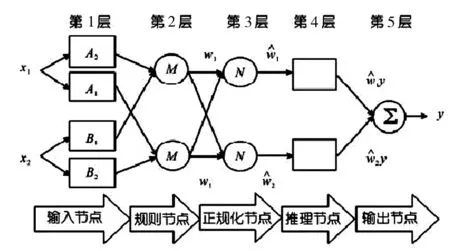
图2 自适应神经模糊推理 数据预测模型结构示意图
从图中可以看出,自适应神经模糊推理数据预测模型一共可以分为5层,第5层输出结果的计算公式为:
(5)
式中:ωi为隐藏层与输出端之间的权重。
3.4 误差分析
误差分析评价方式有平均绝对误差M、均方根误差R两种,其计算的公式分别为:
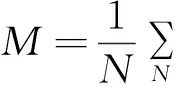
(6)
(7)
式中:N为所测数据的总量;CP和Cm是预测的水质影响因素数据与实测的水质影响因素数据。
4 计算结果分析
4.1 输入因素简化方法
在本次预测中,影响水质的因素一共有12种,如果一一代入进行计算预测,那么计算过程将过于繁琐,计算结果分析也不方便[6]。对此,特采用线性回归方法分析各影响因素之间的关系,探索各影响因子对水质影响的重要程度,简化输入因子。表2为水质各影响因子与磷含量、透明度、溶氧量以及叶绿素a含量的关系系数,从表中数据可以看出,对磷含量影响比较大的影响因子有透明度、浑浊度、悬浮物、叶绿素a含量、氮含量以及总碱度;而对水体透明度影响比较大的影响因子有磷含量、水体温度、酸碱度、浑浊度、溶氧量、悬浮物;对溶氧量影响比较大的影响因子有水体温度、酸碱度、透明度、叶绿素a含量、钙镁化物含量以及总碱度;对叶绿素a含量影响比较大的影响因子有磷含量、酸碱度、电导率、溶氧量、钙镁化物含量以及总碱度[7]。
4.2 多元线性预测模型的预测结果及误差分析
将磷含量、溶氧量、叶绿素a含量以及透明度4种水质关键影响因子的测量数据代入公式中可得:
x5=-0.013x2+1.6207x3-0.1599x1+0.0291x7-0.0029x11-0.0089x12-2.9673
x6=-1.5141x1-0.3687x8+0.5931x9+0.2449x7+138.9015x10-0.0832x12+14.7914
x7=0.1021x6+6.207x3-0.0423x4+1.1630x5+0.0211x11-0.2264x12-30.4197
x1=-0.0115x6-0.0794x2-0.3187x3-0.0518x8-0.1936x5+0.1071x9+8.2971
其中x5为溶氧量的预测结果,预测可以分为两个阶段,主要阶段和次要阶段,主要阶段占预测量的70%,次要阶段占预测量的30%。使用多远线性预测模型的误差分析,从表4中数据可以看出,4种主要影响因子的预测结果准确度都比较低。

表2 各水质影响因子与磷含量、溶氧量、叶绿素、透明度之间的关系系数
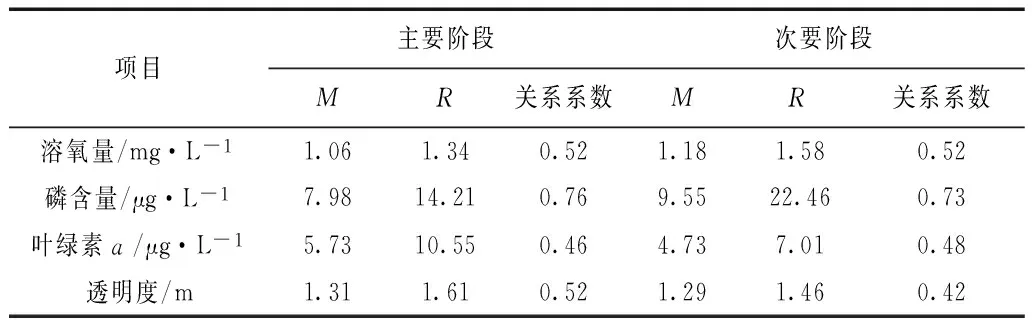
表3 多远线性预测模型预测结果误差分析
4.3 径向基神经预测模型预测结果及误差分析
径向基神经预测模型的误差分析也是针对这4种主要影响因子,分为2个阶段,进行误差分析,分析结果如表4。
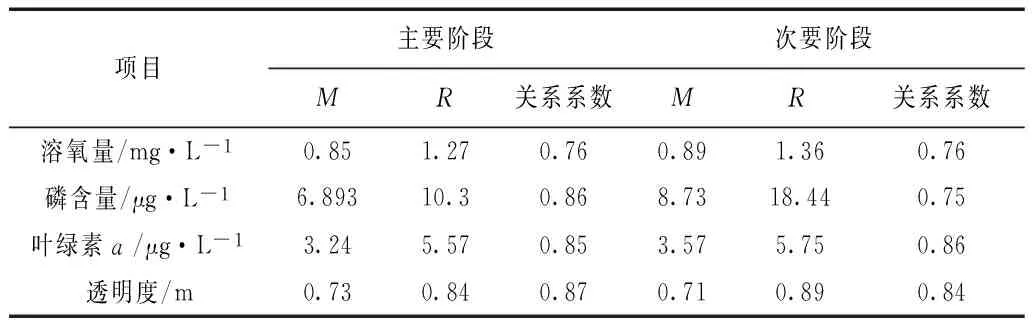
表4 径向基神经预测模型预测结果误差分析
径向基神经预测模型预测结果的关系系数明显要大于多元线性预测模型,说明其相关性更好,预测结果更准确[8]。
4.4 自适应神经模糊推理数据预测模型预测结果及误差分析
代入数据,可得误差分析结果如表5。
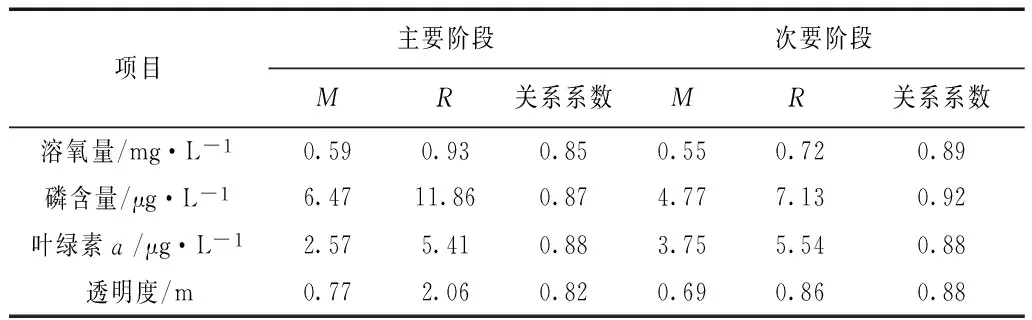
表5 自适应神经模糊推理数据 预测模型预测结果误差分析
从表5中的误差分析数据可得,自适应神经模糊推理数据预测模型对于透明度的预测结果在主要阶段比其他两者要差,但是在次要阶段明显要优于其他两种模型;对于溶氧量、磷含量以及叶绿色a,自适应神经模糊推理数据预测模型的预测结果比其他两种模型都要准确。所以,总的来说,自适应神经模糊推理数据预测模型的预测结果最符合水库的实际水质情况。
5 结 论
1)多元线性预测模型各影响因子的关系系数在主要阶段和次要阶段都偏低,所以所预测结果的准确度比较低,与实际情况偏差较大,不适用于大伙房水库的水质预测。
2)自适应神经模糊推理数据预测模型对于透明度的预测结果在主要阶段比径向基神经预测模型预测结果要差,但是在次要阶段结果更好;对于溶氧量、磷含量以及叶绿色a,自适应模型的预测结果都更加准确。所以选择自适应神经模糊推理数据预测模型的预测结果作为参考数据。
[1]贺光华,杨龙.防治水质污染 提高饮水安全[J].水利规划与设计,2006(04):12-14.
[2]李学森.凌河流域水资源现状及保护措施[J].水土保持应用技术,2015(03):36-37.
[3]金云杰.凌河流域人工湿地对水环境质量影响分析评价[J].水土保持应用技术,2015(05):27-28.
[4]杨锦华.佛寺水库水源饮水安全与水环境保护[J].水利技术监督,2006(03):50-52.
[5]温树成.大伙房水库水体富营养化现状分析及对策研究[J].水土保持应用技术,2015(02):31-32.
[6]田冰.河北省自然湿地生态需水量分析[J].水土保持应用技术,2007(02):34-36.
[7]李强.城镇河道综合治理探析[J].水土保持应用技术,2014(05):32-33.
[8]王怀柏,李跃奇,李儒道.关于水质评价问题的探讨[J].水利技术监督,2011(04):6-8.
1007-7596(2017)01-0146-03
2016-12-16
陈俊(1981-),男,江苏泰县人,工程师,研究方向为水文、水资源管理与水资源评价等。
P
B
