对比模式挖掘研究进展
2017-04-28
西安石油大学计算机学院,陕西 西安 710065
引言
数据挖掘又称数据库中的知识发现,指通过算法从大量的数据集中揭示隐含的、先前未知的信息的过程,这些信息往往具有潜在价值。作为一门交叉性学科,它的实现通常与计算机科学相关,并通过统计学、模式识别、专家系统、机器学习、在线分析处理和数据可视化等诸多方法实现挖掘目的[1]。对比模式挖掘作为数据挖掘领域中的一个的重要组成部分,凭借其特有的优势近年来受到广泛关注,它的基本任务是区分和对比数据集间的显著差异。这项技术可以有助于了解事物本质特征,更好地处理所面临的问题和了解未知知识。
一般的研究方法是通过对比给定的数据对象类,产生对比模式,以确定它们之间存在的差异。这些差异可以提供有价值的见解,比如能够说明为什么这些对象会有不同以及造成的相应影响。对比模式挖掘相关概念的提出最早可以追溯到 1993 年,Agrawal 等人以关联规则挖掘的形式进行了市场购物篮分析,通过频繁模式对比确定商品购买的相关联系[2]。自这项新兴数据挖掘任务及其相关高效挖掘方法问世至今,在生产和生活的诸多方面已取得有效应用,相关数据挖掘算法层出不穷,更多的数据类型得以应用,引发了大量的研究和开发尝试。
1 基本概念
对比模式挖掘面向的是具有差异特征的数据集,特指以类为对象并在约束条件下,发现数据集中存在的对比特性,用模式表示并进行比较分析[3]。对比模式的概念定义为属性和值的组合,它们在数据集间的分布或数值表现存在不同,关注分析这些差异,往往能得到某些未被认知却有价值的信息。
给定两个或多个数据集,为了挖掘其中存在的隐含信息,首先需要找到能够描述差异的模式。如果模式 p 相对于每个数据集的某一些统计值 (例如,支持度) 高度不同,则模式 p 能够认为是两个数据集存在差异的影响因子,或称对比模式。早期的研究主要集中在对比模式在简单条件下属性的关联,现在的研究关注对比模式涉及的更强大的结构,包括分离模式,模糊模式,对比不等式等。对比数据挖掘在许多类型的数据中可以有效应用,例如教育研究者获得学生相关数据后,可以利用对比模式进行针对性的规则挖掘发现男女学生学习习惯的差异[4]。
2 技术与算法
2.1 EP 模式挖掘技术
显露模式 (Emerging Pattern,EP) 应用于对比模式挖掘研究已有很长时间,它的不俗表现一直受到广泛关注。在 1999 年的 KDD 大会上,Dong 和 Li 提出了这一影响深远的知识模式[5],显露模式描述的项集能够表现出数据集之间支持度发生显著变化的特性,这种表示方法的优势明显,能够揭示目标类和非目标类上多组属性之间存在的差异,发现不同类中数据关联的固有特征,可以很好地实现分类效果。在对显露模式 (EP) 的应用进行讨论之前,先给出 EP 的相关概念。
定义 2.1:项集 X 在类 C 中的支持度,记为supc(X),supc(X)=countc(X)/|C|,其中countc(X)表示在类 C中包含 X 的样本个数,而 |C| 是类 C 中样本的总数。
定义 2.2:给定两个数据集 D' 和 D,项集 X 从D' 到 D 的增长率 GR (X,D',D) 定义如下。
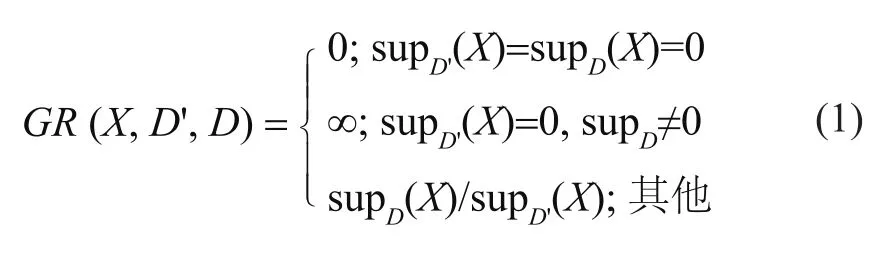
定义 2.3:给定增长率阈值ρ> l,如果项集 X 从D' 到 D 的增长率 GR (X, D', D) ≥ρ,则称 X 是从 D'到 D 的 EP,简称 X 是 D 的 EP。
自显露模式的概念出现以来,基于显露模式的挖掘算法可谓层出不穷。如 Dong 提出基于边界的显露模式发现方法[5],只需处理集合的边界,能够使用简洁的边框来描述大量的项目集;Bailey 提出基于超图的显露模式发现思想[6],指出最小超图遍历和挖掘显露模式存在紧密联系,利用基于超图遍历算法来挖掘 EP;Loekito 提出基于零压缩决策图 (ZBDD) 的显露模式发现的方法[7],在稀疏矩阵中依然能有效挖掘EP。
显露模式在有类别的数据集中表现出强大的区分能力,EP 的增长率为它的分类能力和预测能力提供了良好的理论基础,它的支持度体现了所起作用的范围。显露模式技术是对比挖掘领域的一个有效应用,主要挖掘各个类别之间研究对象之间存在的差异,并以信息的变化揭示隐含的知识。
2.2 ConSGapMiner 算法
为了发现数据集合之间的对比模式,Ji 等人提出ConSGapMiner 算法[8],表示为根据间隙约束来挖掘所有的最小区分子序列。最小区分子序列 (MDS) 是一种新的对比模式,发生在一个类序列中,而在另一个类序列中很少出现。MDS 的一个关键特性是它的项不必连续出现,它们之间可能存在间隙。
利用 ConSGapMiner 算法能够使用相对较低的频率阈值,从一些密集的数据库中高效地挖掘具有间隙 g 约束的最小区分子序列 (简称为 g-MDS)。算法首先采用深度优先遍历集合枚举树的方式产生候选 c,然后对 pos 和 neg 的频率支持度和间隙满意度进行计算。如果满足频率条件和非频率条件,则 c 保留。最后在第三阶段去除所有非最小子序列,产生最终的g-MDS 集合。
ConSGapMiner 算法挖掘得到的模式可以被人们直观理解并能够产生强烈的对比效果,但间隔约束要综合多方面先验条件,不合适的约束值会造成有用的模式未被发现,在此理论基础上,免预设间隔约束的思想被提出。王等人设计了带紧凑间隔约束的最小对比序列模式挖掘算法,可以对候选模式自动处理得到最适合的间隔约束,挖掘效率大幅度提高[9]。近期的研究表明,无特殊条件的间隙约束序列模式挖掘实现,无重叠条件的间隙约束序列模式匹配问题已经能够找到完备解[10]。
2.3 gd-DSPMiner 算法
引入密度概念扩展了以往考虑间隙和支持约束的研究,进一步描述给定的序列类。Wang 等人提出 gd-DSPMiner 算法,将密度与满足间隙约束的对比模式进行融合[11]。
从给定的顺序数据库中发现最小的间隙和密度约束的识别序列模式 (gd-DSP),gd-DSPMiner 算法以迭代的方式完成以下三个主要步骤:生成候选模式集、最低限度测试、以及 gd-support 检查。在每次迭代中,算法找到一些长度为 L(L ≥ 1) 的所有 gd-DSP,通过候选模式的两两连接生成长度大于 L 的待挖掘项。对这些项进一步挖掘就能得到相应的的对比模式。
gd-DSPMiner 算法能够有效的发现密度感知的具有间隙约束的序列模式,相比于先前的挖掘算法计算速度有明显提高。但由于设置的参数数目相对偏多,可能要进行多次试验以确定合适的密度、间隙约束以及支持度阈值,要避免由于设置不合理而影响挖掘效果。序列区分模式 (DSP) 的研究发展迅速,近期Yang 等人提出了 itemset-DSP 的简洁的边界式表示方法,它侧重于从元素为项集的序列中挖掘模式,每个元素都视为一个 itemset,而不是单个项目[12]。
2.4 kDSP-Miner 算法
现有的大多数对比模式挖掘算法在运行时需要用户事先设定正例支持度阈值和负例支持度阈值,然而现实条件下很多情况并不没有足够的先验知识,用户缺乏参考难以设置合适的阈值条件,某些对比显著的模式可能无法有效挖掘。为此,杨等人提出了kDSP-Miner 算法,目的是挖掘带间隔约束的 top-k对比模式[13]。该算法不需要人为设定支持度阈值,只需设定期望得到的对比最显著的模式个数就能完成有效挖掘。
kDSP-Miner 算法首先对数据集进行扫描并生成字母表,同步建立集合枚举树。算法以深度优先的方式层层遍历整个集合枚举树,逐步得到对比序列模式的候选集。然后对候选模式通过停止条件进行剪枝,在间隔约束为 γ 的条件下计算相应对比度,如果候选模式对比度小于已有 top-k 的对比度最小的模式则进行剪枝,否则将其作为新的参照模式进行下一轮比较,以此不断进行遍历,最终得到对比模式的集合。
kDSP-Miner 算法应用广泛,为了满足大规模数据挖掘的需求,有必要利用并行计算技术,设计并行挖掘算法,在 Spark 框架下利用 top-k 对比模式挖掘技术目前受到广泛关注[14]。
3 对比模式挖掘的应用
3.1 采用对比模式进行分类
分类是数据挖掘领域的一个重要分支,可以用来抽取能够描述重要数据集合的模型。由于数据的对比度模式包含区分类的信号,使用对比度模式来构建精确分类器受到众多研究者的密切关注。一般来说,为了构建一个基于分类模型的对比模式,需要解决三个问题:分类决策的挖掘、选择和评分策略。使用对比模式构建分类器的算法研究成效显著,其中最具代表性的是 CBA 和 CAEP。
CBA 算法全称 Classification base of Association,即基于关联规则进行分类的算法,由 Liu 等人率先提出[15]。CBA 算法利用 Apriori 算法挖掘出关联规则,然后做分类判断,在某种程度上讲,CBA 算法是一种集成挖掘算法。
在应用 CBA 算法时,首先给定一些预先知道的属性,然后算法进行判断分类得到相应的决策属性。判断的依据是 Apriori 算法挖掘出的频繁项,如果一个项集中包含预先知道的属性,同时也包含分类属性值,然后计算此频繁项,导出已知属性值推出决策属性值的关联规则,如果满足规则的最小置信度要求,那么可以把频繁项中的决策属性值作为最后的分类结果。
CBA 算法进行分类预测是相当可靠的,具有很高的准确度,但它使用类似 Apriori 的算法需要不断迭代来产生大量的分类关联规则,数据集需要进行重复扫描,对时间和主存空间都是一种极大的挑战。
CAEP 算法全称 Classification by Aggre- gate Emerging Patterns,即基于集成显露模式进行分类,是由 Dong 和 Li 等人提出基于 EP 的分类算法[16]。EP 的支持度在不同类之间有明显差异,但一个 EP通常仅仅能区分所有样本中的一小部分。我们需要在(1 ≤ i ≤ K) 目标类中找到满足支持度阈值和增长率阈值的所有 EPs,把除 类之外的所有样本定义为非目标类。通过增长率和在目标类上的支持度来判断每个 EP 的区分能力,记为 strength (X),具体表示如下。
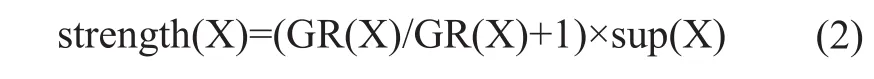
CAEP 算法把在测试样本中的所有 EP 的区分能力进行聚合,然后计算实例在每一个类上的得分,最后根据所得分数进行判断其所属类别。给定一个实例 S,从训练数据集中挖掘属于类 C 的 EPs集合 E(C),S 属于类 C 的得分 score (S, C) 表示如下:

通过公式计算每个测试实例对于每个类的得分,分值最大的即为实例的归属类,以此实现分类。
CAEP 表现出很好的分类效果,是基于 EP 算法的有效沿用。它所采用思想方法在后续的 EP 分类算法研究中得到进一步推广,如基于显露模式的决策分类、基于显露模式的贝叶斯分类、跳跃显露模式分类等等,由于篇幅限制,这里不予详细叙述。
对比模式在分类上有着明显优势,它同时也可以用来改进传统的分类器。比如可以与加权支持向量机(SVM) 构建集成的显露模式,或者将显露模式作为权重决策树结构的一部分,还可以采用显露模式扩展训练数据,提高稀有类的分类。这些应用在具体的实现中都有不错的表现。
3.2 采用对比模式进行聚类
聚类分析涉及根据内在特征或相似性对对象进行分组。传统的聚类方法通常以距离函数来定义对象之间的相似性,并评估聚类的质量。一般的聚类算法通常存在不稳定性,它们所获得的聚类结果对诸如数据中的微小扰动,访问实例的顺序以及算法参数的轻微变化等因素非常敏感。在先验领域知识稀缺,或在高维数据中,一般的聚类方法难以收到有效结果。Dong提出了一种新的基于对比模式的聚类算法,用于在不依赖数据集先验知识的前提下,从分类数据中发现高质量的聚类[17]。这种算法有两个明显优点:聚类时不需要距离函数;CPC (基于对比模式的聚类) 和 CPCQ(基于聚类的聚类质量指数) 可以发现小的高质量的对比模式,以表明集群的潜在主题。聚类的对比度模式(CP) 在其归属集群中出现频率远高于在其他类型中的频率,频率的差异使得 CP 成为高度区分性的模式来描述其归属集群,并将该集群与其他集群区分开来。
基于对比模式的聚类算法 (CPC) 使用 CP 质量、丰富度和多样性等概念构建集群,确保每个集群拥有大量高质量和多样化的 CPs,同时确保进行划分集群的 CPs 总数。这里引入相互模式质量 (MPQ) 的概念,MPQ 的值被定义为给予其相互模式的某些权重的归一化总和。对于给定的两个对比模式,高 MPQ值表示两个模式应属于同一个集群,而低值表示它们应属于不同的集群。当两个元组多样模式成为同一个集群的 CP 时,MPQ 主要测量可能成为 CP 的其他模式的数量 (丰富度) 和质量。
CPC 算法从需要集群的数据集中挖掘的频繁模式,使用 CP 的特性构建一个具有高 CPCQ 值的集群。CPCQ 指数旨在识别数据集中的高质量集群,而不需要距离函数。高 CPCQ 聚类是指每个集群中具有多样和高质量的 CP 集群。每个 CP 的质量根据它们的长度、支持度和它们相关的闭模式的长度来定义。为了计算聚类的 CPCQ 值,Liu 等人提出 CPCQ 增量分组 (CPCQ_IncGroup) 算法[18],主要分为两步。第一步从给定聚类的集群中挖掘所有 CP 及其等价类,通过使用高效的 DPMiner 算法完成。第二步构建 N 个最高质量的 CP 组,然后基于这些组计算 CPCQ 值。
CPCQ 指数克服了其他流行的数据聚类质量指标的缺点,如基于距离的,基于熵的和基于频繁项目的指标,它对大量或少量的聚类没有任何偏好,也不要求用户定义距离函数或提供领域知识,同时 CPCQ 指数也可以处理高维分类数据集。这项工作有许多潜在的扩展,包括将 CPCQ 指数扩展到混合数据类型和处理领域知识,以及在一种新的聚类算法中使用该指数来发现最优的集群解决方案。
3.3 其他对比模式的应用
以下我们关注对比模式挖掘的其他几种应用:
(1) 诊断基因组的识别。通过进行一系列基因表达实验可以检测与疾病密切相关的基因组,进而思考疾病治疗的更有效方案。基因组中的每个基因在大多数同类样本中的基因表达值分布在特定范围内,在一类细胞中具有大的频率,但在另一类细胞的这些范围中从未一致地发现。Murphy 等人对基因组进行了分析,利用比较基因组学对一种新型害虫的鉴别方法进行分子诊断,可以用来检测果蝇的特征进化[19]。将这些表现特殊的基因组称为显露模式,以强调两类细胞之间的模式频率变化,接着使用有效的算法从这些基因中提取模式来获得最具歧视性的基因。
(2) 博客社区的分析。博客为个人和社会团体表达意见并在感兴趣的事项上相互交流提供了易于获取的渠道。Dong 在文献中提出博客社区中一个关注热点可以对应于一个对比模式 (CP),为此使用“集群”术语看作博客社区的同义词[20]。聚类集群数对应于博客社区的数量,CP 是指在一个集群的博客中比在其他集群中更频繁地出现的模式。CPCQ 和 CPC 可以自动发现最近发布的博客动态集合,非常适合博客社区的动态特性。晏提出基于固定时间区间的 top-k 对比挖掘算法,可以让用户自定义时间区间,并获得在此区间内模式显著变化的关注热点[21]。
(3) 文本分类。文本分类是指按照事先所给的主题类型,为文档集合中的每一个文档确定一个所属类型,有着重要的应用价值。程等人将对比模式挖掘技术应用于文本自动分类,结合基本显露模式 (eEP) 在分类上的良好区分特性和基于最小期望风险代价的决策粗糙集模型,首先采用 eEP 分类方法获得对比模式,接着利用相似性公式和语义相关度,计算得出文本相似性得分[22]。
(4) 图像分类。文献 [23] 提出将跳跃显露模式(JEP) 应用于图像分类的思想。图像以符号,颜色和纹理为基础被分割为多个图块,以捕获足够的信息来推理其底层内容。这样表示能够发现在图像数据库中提议的发生次数的跳跃显露模式 (occJEP),并完成基于模式的分类。在文献 [24] 中,结合 CEP 所给出的频繁闭显露模型,提出一种新的图特征提取方法,解决了 CEP 算法由于支持度阈值设置过低而导致的无法计算现象,大大提高了图像分类效率。
(5) 子群发现与分析。子群发现能够根据用户感兴趣的属性条件,在数据集中找到统计明显的子群。文献 [25] 对于显露模式挖掘和子群发现进行了详细研究。提出显露模式挖掘中使用的启发式方法可以转化为子群发现中使用的挖掘算法,其目的是在覆盖和分配差异之间进行折衷。
(6) 离群概念发现。离群点检测的目的是寻找一组与数据集中其他对象不一致或明显偏离的对象。文献 [26] 将基于互信息的特征选择方法和基于密度的分数搜索方法结合,提出了 OA Rank 的方法,可以在大数据集上有效进行离群点的挖掘。
4 对比模式挖掘的研究展望
基于研究现状,对接下来对比模式挖掘研究可以进行如下展望:
(1) 设计更为高效的挖掘算法。算法的好坏直接影响研究结果,高效的算法应该能够在满足给定的约束条件下获得更为紧凑和高质量的模式集。
(2) 深入理解对比模式。为了提高对比模式的可解释性和可用性,深入理解对比模式相关语义含义尤为重要,获得含有丰富语义的对比模式同时对于那些冗余的数据进行及时筛选,这样能够利用现有数据获得更为科学的结论。
(3) 基于非结构化数据的对比模式。已有的对比模式研究都集中在结构化的数据处理上,而现实生活中有大量如声音和影视等非结构化数据,我们应该设计出更有效的算法扩展对比模式的应用领域,实现对非结构化数据的处理。
(4) 利用对比模式处理一些不确定和流数据环境下的数据。近来新兴的不确定数据管理引起广泛关注,与模糊显露模式相比,基于不确定性数据挖掘的对比模式更为复杂。对于流数据的数据挖掘处理,时间和空间效率要得到足够关注。
5 结语
本文简要介绍了基于对比模式挖掘的研究现状和未来方向。对比模式挖掘注重不同类别之间对象存在的差异性,通过分析比较得到新的未知信息。作为数据挖掘中的一个重要的新兴领域,对比模式挖掘的研究已经取得了丰硕成果,虽然仍有一些关键问题需要深入研究,但相信在不久的将来,问题一定会得到有效解决,这项技术的影响必定日趋深远。
[1] 刘洲洲. 面向不平衡数据集的对比模式挖掘算法研究[D]. 长沙: 湖南大学, 2016.
[2] Agrawal R., Imielinski T., Swami A. Mining associa- tion rules between sets of items in large databases[C].SIGMOD ICMD,1993:207-216.
[3] Elaheh Alipour Chavary,Sarah M.Erfani,Christopher Leckie. Summarizing significant changes in network traffic using contrast pattern mining[C].the 2017 ACM,2017:2015-2018.
[4] X Tian,J Kong,T Zhu,H Xia. Discovering learning patterns of male and female students by contrast targeted rule mining [C].International Conference on Enterprise Systems,2017:196-202.
[5] Guozhu Dong,LI JinYan.Efficient Mining of emerging patterns:discovering trends and differences[C].the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,1999:43-52.
[6] Bailey J,Manoukian T,Ramamohanarao K.A fast algor- ithm for computing hypergraph transversals and its application in mining emerging patterns [C].the Third IEEE International Conference on Data Mining, 2003:485-488.
[7] Loekito E,Bailey J.Fast mining of high dimensional expressive contrast patterns using zero-suppressed binary decision diagrams[C].the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2006:307-316.
[8] Ji Xiaonan,Bailey J,Guozhu Dong. Mining minimal distinguishing subsequence patterns with gap constraints[J]. Knowledge and Information Systems,2007,11(3):259-286.
[9] 王慧锋,段磊,左劼等.免预设间隔约束的对比序列模式高效挖掘[J].计算机学报,2016,39(10):1979-1991.
[10] 苗学连.间隙约束序列模式挖掘的对比研究[J].网络安全技术与应用,2017,2(2):66-67.
[11] Wang Xianming,Duan Lei,Guozhu Dong, et a1. Ef fi- cient mining of density-aware distinguishing sequential patterns with gap constraints[J]. Springer,2014,8421:372-387.
[12] H Yang,L Duan,G Dong, et a1.Mining itemset-based distinguishing sequential patterns with gap constraint[C].International Conference on Database Systems for Advanced Applications, 2015: 39-54.
[13] 杨皓,段磊,胡斌等.带间隔约束的Top—k对比序列模式挖掘[J].软件学报,2015,26(11):2994-3009.
[14] 张鹏,段磊,秦攀等.基于Spark的top-k对比序列模式挖掘[J].计算机研究与发展,2017,54(7):1452-1464.
[15] Bing Liu,Wynne Hsu,Yiming Ma. Integrating classification and association rule mining[C]. International Conference on Knowledge Discovery and Data Mining,1998:80-86.
[16] Guozhu Dong,Xiuzhen Zhang,Limsoon Wong,Jinyan Li. CAEP:classification by aggregating emerging patterns[C]. International Conference on Disco- very Science,1999:30-42.
[17] Neil Fore,Guozhu Dong.CPC:A contrast pattern based clustering algorithm requiring no distance function[R].Wright State University: Department of Computer Science and Engineering,2011.
[18] Qingbao Liu,Guozhu Dong.CPCQ: Contrast pattern based clustering quality index for categorical data[J]. Pattern Recognition, 2012,45(4):1739-1748.
[19] KA Murphy,TR Unruh,LM Zhou,et a1.Using comparative genomics to develop a molecular diagnostic for the identification of an emerging pest Drosophila suzukii[J].Bulletin of Entomological Research, 2015,105(3): 364-372.
[20] Guozhu Dong,Neil Fore.Discovering dynamic logical blog communities based on their distinct interest profiles[C].The First International Conference on Social Eco-Informatics(SOTICS 2011),2011.
[21] 晏力.基于时序数据的top-k时间区间对比序列模式挖掘算法[J].现代计算机,2017,6(9):28-30.
[22] 程玉胜,梁辉,王一宾,黎康.基于风险决策的文本语义分类算法[J].计算机应用,2016,36(11):2963-2968.
[23] Kobyli, ski, ukasz, K Walczak. Jumping emerging patterns with occurrence count in image classifi- cation[C].International Conference on Knowledge Discovery and Data Mining,2008:904-909.
[24] 尹婷婷,刘俊焱等.基于动态抽样的图分类算法[J].南京师大学报(自然科学版),2015,38(1):113-118.
[25] Zengyou He,FeiyangGu,et a1. Conditional discriminative pattern mining[J].Information Sciences, 2017,375(3): 1-15.
[26] NX Vinh, J Chan, J Bailey, et a1. Scalable outlyinginlying aspects discovery via feature ranking[C]. IEEE International Symposium on Biomedical Imaging, 2015:182-185.
