非负组合模型及其在声源分离中的应用*
2017-04-27张雄伟李轶南时文华胡永刚陈栩杉
张雄伟 李轶南 时文华,2 胡永刚 陈栩杉
(1.解放军理工大学指挥信息系统学院,南京,210007;2.空军航空大学教官基地,蚌埠,233000;3.武警政治学院政工信息化教研室,上海,201703)
非负组合模型及其在声源分离中的应用*
张雄伟1李轶南1时文华1,2胡永刚1陈栩杉3
(1.解放军理工大学指挥信息系统学院,南京,210007;2.空军航空大学教官基地,蚌埠,233000;3.武警政治学院政工信息化教研室,上海,201703)
非负组合模型在人工智能、数据挖掘和智能信息处理研究领域具有十分重要的应用意义,已经逐渐成为声源分离中最常使用以及最具代表性的模型之一。内含于其中的非负成分的加性组合与人类听觉系统的感知机理高度契合。利用非负组合模型进行声源分离的技术正在变得越来越流行。本文从被称作非负矩阵分解的最基本的非负组合模型开始,首先回顾了非负组合模型的基本原则,包括需要求解的基本问题、目标函数的度量以及求解相关问题的常用方法。在此基础上,系统地讨论了非负矩阵分解在声源分离不同应用领域的拓展。最后指出并讨论非负组合模型研究中有待进一步研究的开放问题。
声源分离;非负组合模型;非负矩阵分解
引 言
如何准确、高效地发掘和表示样本数据中潜在的特征是机器学习和数据挖掘领域的一个重要问题。实际应用中的很多数据可以视作由一些“部分”通过“组合”的结合方式所构成的。这种组合的构成方式,意味着构成部分之间不会出现相减或抵消的现象,而是通过叠加的方式相互组合而成。典型的组合数据包括人口、自然语言处理中字词出现频度等计数类数据。学者们提出了大量的数学模型来表示和处理此类数据[1],旨在与这类数据的组合叠加本质相吻合。这些数学模型的核心思想是通过非负元素的非负组合来实现对于数据整体的表示和描述,进而更好地把握和挖掘出观测数据整体内含的基本规律。本文将以“非负组合模型”来指代具备上述特征的数学模型。非负组合模型可以大致分为两类:(1)以矩阵分解为代表的线性叠加组合模型;(2)在以神经网络为代表的非线性模型上添加非负性,从而构建非线性的叠加模型。尽管非负组合模型最适合于处理计数数据,但是近年来,基于非负组合模型的各类方法也被广泛应用于语言习得[2]、音乐分析[3]、图像分类[4]、波束成型[5]和高光谱分析[6]等诸多领域。在处理多声源信号分离这样的老问题中,也取得了比较理想的效果。这主要是由于两点原因:(1) 非负组合模型所得到的结果具有物理上的可解释性,因此能够较容易地与客观物理现象找到合理的对应关系(很多物理信号,不可能存在负的构成分量),无论是各个频率分量的大小,还是某个特定频率成分出现的时间及其相应的强度变化,都能在非负组合模型下得到很好的表示和解释。(2) 这种组合叠加的方式与人类感知系统通过对于客观事物从部分到整体的认知过程相契合。例如,在听交响乐时,人类听觉系统的感知过程,可以被认为是通过将听到的弦乐器、管乐器和打击乐器等各种乐器的分别感知来实现对于交响乐整体的感知。
在人工智能和机器学习领域,为了提高所设计计算系统的智能水平,常常借鉴人类大脑对于信息的处理机制。在此方面,非负组合模型由于其简洁(纯加性的方式容易导致稀疏的表示结果,使得对于数据的描述变得较为简洁)、灵活(能够很容易地与涌现出的新方法相融合)的特点,其合乎人类大脑感知的直观体验,具有确定物理意义的计算结果[7-8],展现出强大的生命力。本文将从最基本的非负组合模型,即非负矩阵分解开始,逐步阐述非负组合模型的基本定义和求解方法;然后结合声源分离的实际应用,对各类基于非负组合模型的算法进行介绍和综述。最后总结全文,指出有待进一步解决的开放问题。
1 非负矩阵分解
非负组合模型是一种非常灵活的数据表示模型,能够很方便地与最新的诸如深度神经网络、稀疏字典学习算法及稀疏低秩分解等相融合并拓展出新的基于非负组合模型的算法。这一系列算法全都起源于基于乘法迭代的非负矩阵分解(Nonnegative matrix factorization, NMF)[9]。
1.1 非负矩阵分解的定义及基本问题

(1)

式(1)的分解结果通常使用如下的最小化问题来求解,即有
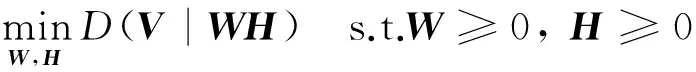
(2)
式中:记法A≥0表示矩阵A的所有元素都非负。其中,D(V|WH)是一个可分离的测量,即
(3)
其中d(x|y)是一个标量的目标函数。目标函数是在给定x的条件下关于y的正值函数,只有在x=y时取得最小值。
1.2 目标函数的刻画与度量
为了求解式(3)中的优化问题,首先确定目标函数,用以刻画重构数据对观测数据的逼近程度。在NMF中,最常见的是以β散度作为度量标准定义的一系列目标函数。β散度最早由Basu等提出[10],这一系列目标函数本质上讲是一些关于参数β的函数,不同的β取值对应着不同的噪声假设,其定义为
(4)

β散度可以看做是关于β的连续函数,图1给出了式(4)在x=1条件下,不同取值β下的对应的关于变量y的变化曲线(图中的所有值均无量纲)。需要指出的是,对于任意β的取值,都满足式(5)所呈现出的尺度特性[11],该性质可以表示为
(5)
这表明当β>0时,左右目标函数的主要是那些数值较大(能量较大)的取值;而β<0 则恰恰相反,是那些比较小的值。当β=0时所对应的IS散度恰好具备尺度不变性,这是其他β取值下所不具备的性质。

表1 常见的散度及其对应的概率生成模型

图1 在NMF中使用的典型散度函数说明Fig.1 Illustration of typical divergence functions used in NMF
1.3 非负矩阵分解的求解算法
NMF算法交替更新W和H两个矩阵,首先给定W更新H,然后给定H更新W。由于NMF的对称性,以上两个步骤在本质上是相同的(V≈WH等同于VT≈HTWT,而W和H的位置正好发生了互换)。因此,聚焦于如下的子问题,则

(6)
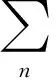

(7)

图2 非负矩阵分解在人脸数据集上的运行结果Fig.2 Result of NMF on human faces dataset
求解NMF问题最直观的方法是采用传统的梯度下降法,最早提出的正矩阵求解就是采用这样方法来进行求解[12],然而加法迭代的过程中难以避免地会产生负值,一般需要将这些负值强制置零。文献[9,13]巧妙地采用了乘法迭代的方式来获得NMF的更新公式,避免了出现强制置零的现象,这种采用乘法迭代实现对NMF进行求解的方法已经成为求解此类问题的经典方法。此外,这种只做加法不做减法的计算方式,得到的计算结果往往具有稀疏特性,使得对于数据的表示更加清晰简洁。图2给出了在人脸数据集上运行前后的结果,可以看出,分解所得的非负基函数,与人脸的局部信息(例如鼻子、眉毛和眼睛等)相类似,因此实现了对人脸从“部分”到“整体”的表示。
常用的用于获得乘法迭代更新公式的途径有两种:一种是通过构造辅助函数进行优化而得到更新公式的优化最小(Majorizationminimization,MM)算法;另一种则是基于变化步长的启发式乘法算法(Heuristicmultiplicativealgorithm)。优化最小算法具有严格的理论基础,会保证推导出的NMF最终收敛到一个局部最小值,缺点是寻找并构造满足要求的辅助函数比较困难,文献[11]给出了各种β取值下的辅助函数,本文不再赘述;启发式乘法算法缺乏理论支撑,其本质上是变化步长的梯度下降算法,但推导简便,并且一般情况下也能获得令人满意的结果,因此也被经常使用。

(8)
除了经典的乘法迭代算法之外,近年来还涌现出很多其他的快速求解方法,例如采用基于交替乘子法(Alternatingdirectionmethodofmultipliers,ADMM)的更新方法[14]和Nesterov最优梯度[15]等方法。从统计视角来看,上述方法本质上在不同的概率模型下,使用期望最大算法来进行最大似然估计,进行参数估计。文献[16]在此基础上,进一步考虑了更加复杂的推断方法(包括变分贝叶斯 (VariationalBayesian,VB)以及马尔科夫链蒙特卡洛(MarkovchainMonteCarlo,MCMC))来计算边际似然,进而进一步提升了模型的表示能力。然而,为了计算边际似然的积分,VB方法常常需要挑选满足共轭性质的先验概率分布来使计算变得简洁;MCMC方法则由于其过于巨大的计算开销限制了其在实际工程中的应用。
2 声源分离中的非负组合模型
基于非负组合模型的声源分离算法大体上可以分为2类:一类处理的是多声源分离问题,采用的技术手段主要包括全监督模式、半监督模式以及无监督模式这3种声源分离模式;另一类处理的是去混响问题,研究如何从密闭空间中,与反射信号相混合的混合声音信号中恢复出纯净的原始声源信号的问题。在上述两类4种分离条件下,通常假设混合声源的幅度谱由不同声源的幅度谱相互叠加而成,尽管现实世界中的信号并不是如此简单的叠加,但是这样的假设通常能够得到令人满意的结果[17]。
2.1 全监督模式下的声源分离

(9)
最后,通过维纳滤波器估计出纯净语音信号的幅度谱为
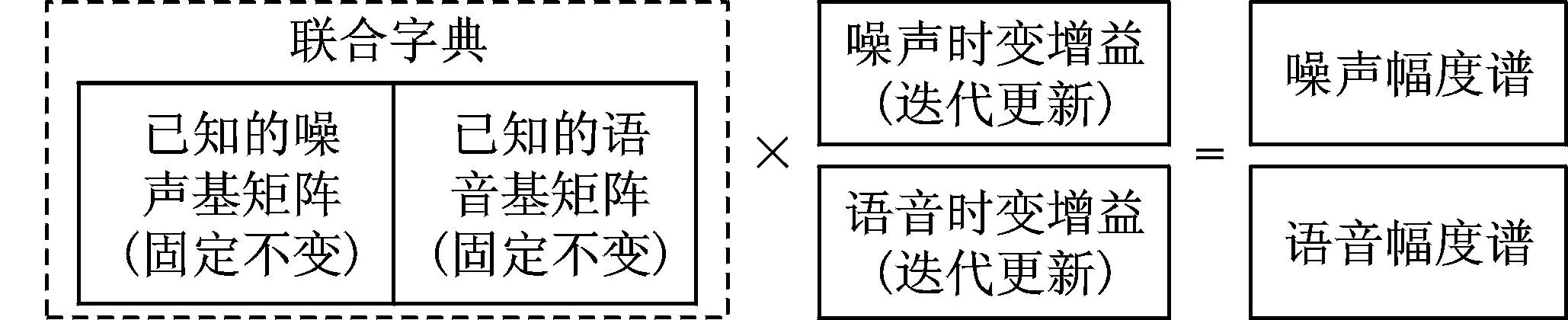
图3 全监督模式下的更新方式Fig.3 Update strategy of supervised fashion
(10)
其中,除法是矩阵对应位置的元素相除,符号“⊙”则表示对应元素之间的乘法。
在全监督条件下,基于非负组合模型的语噪分离可以用图3来表示。文献[19]通过添加稀疏约束,在一定程度上提升了语音噪声分离的效果。在文献[20]中,Paris基于类似的方法,实现了男女说话人的有监督分离,此种方法需要语音和噪声(或者男女说话人)的样本作为先验信息,然而在实际应用中,并不一定能够具备如此多的先验信息来进行预先训练。半监督和无监督分离算法正是用于解决先验信息不足问题的方法。
2.2 半监督模式下的声源分离
半监督模式所具备的先验信息少于全监督模式,在进行声源分离前,只有一部分(而非全部)声源已知。例如在语噪分离中,特定背景噪声的声音样本可以在无语音的间歇期获得,然而具体说话人的声音却无法预先获得,这种条件下的声源分离被称为半监督模式下的声源分离[21-24]。在半监督模式下,固定已知的声源训练所得的非负基矩阵不变,未知声源的基矩阵通常采用随机初始化的方式进行初始化,迭代地更新剩余的3个矩阵(包括未知声源的基矩阵、已知声源的时变增益和未知声源的是时变增益),即可进行分离(所需先验信息少于全监督模式,但多于后面将要介绍的无监督模式)。

图4 半监督模式下的更新方式Fig.4 Update strategy of semi-supervised fashion
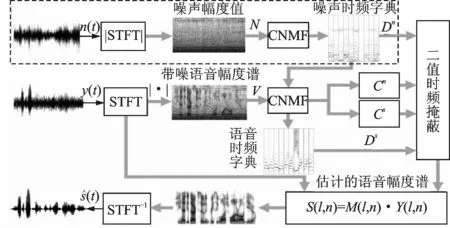
图5 时频字典学习语噪分离算法框图Fig.5 Block diagram of speech and noise separation based on the time-frequency dictionary learning
上述过程如图4所示,在图4中,假设噪声信号为已知信号而语音信号为未知信号。图5给出了半监督模式下,基于非负组合模型的时频字典学习语噪分离算法[22],其思路与图4一致,独特之处在于采用了卷积非负矩阵分解(Convolutivenon-negativematrixfactorization,CNMF)来对噪声信号进行建模,从而能够更好地建模出噪声信号内部所存在的短时相关性。CNMF对于声学信号短时变化的建模,是通过在NMF的基础上,引入一个额外的时间维度来实现的。此时,式(1)的就被重新改写为

(11)


2.3 无监督模式下的声源分离
在资源较少的条件下进行无监督模式的声源分离,常常只有少量的先验信息可以利用。以语音和噪声分离为例,在某些应用场景中,语音和噪声特征并不可提前预知,只能根据语音和噪声的固有特点进行建模和分离[25]。相较于有监督模式(包括全监督和半监督模式),无监督模式具备较少的先验信息,因此,通常情况下获得的结果会劣于有监督模式。但是其不依赖先验知识的特性,使得无监督模式也有非常广泛的应用。基于非负组合模型的无监督模式下的语噪分离主要有3类实现方法:

图6 在语音间歇期在线学习噪声基函数的无监督算法Fig.6 Unsupervised algorithm which learns the noise bases in an online fashion during the pauses of speech
(1) 通过语音断点检测(Voiceactivitydetection,VAD)来区分带噪语音和纯噪声[26-27]。图6为文献[27]中给出的无监督语音增强算法,在该算法中,通过VAD来判断语音间歇期,并在语音间歇期使用在线的卷积非负稀疏编码算法(Convolutivenon-negativesparsecoding,CNSC)来学习不断更新噪声的基函数,进而实现语音增强。
(2) 无监督分离算法,基于通用语音字典的增强方法,即训练一个能够囊括所有说话人特征的通用语音字典,来实现将目标语音信号从背景噪声中分离出来的目的[28-30]。Sun和Mysore分别对每个说话人构建一个小的非负基矩阵(局部字典)。然后将这些小的非负基矩阵连结起来构成一个较大的语音字典(全局字典),在使用时,通过添加组稀疏约束,一次只激活其中的一个或几个局部字典,很好地实现了无监督下语音和噪声的分离[28]。Kim等在文献[28]的基础上,提出了能够更好保持声源流形的(Mixtureoflocaldictionaries,MLD)的方法[29],进一步提高了增强算法的效果。Germain等在文献[28]的基础上,开发出了能够实现在线处理的增强方法[30]。

图7 考虑背景噪声短时连续性的无监督增强算法Fig.7 Unsupervised speech enhancement considering temporal continuity of background noise
(3) 将非负组合模型与稀疏低秩分解(Sparseandlow-rankdecomposition)相融合来实现语噪分离[31-34]。在某种特定的噪声环境中,背景噪声的时频结构会随着时间的推移反复出现,呈现出一定的低秩结构;与之相对应的,语音信号由于富有变化、具有谐波结构等固有特征,会表现出稀疏结构。因此,采用稀疏低秩模型即能够实现无监督模式下的语音噪声分离[34]。Huang首次将在基于稀疏低秩结构的鲁棒主成分分析(Robustprincipalcomponentanalysis,RPCA)应用到音乐伴奏分离,并取得了很好的分离效果[35]。然而,RPCA并不能保证分离结果的非负性,需要对非负部分进行强制置零。为了解决此问题,Sun等将非负组合模型与稀疏低秩分解想融合,即保持了稀疏低秩模型在无监督条件下分解的优势,又使得分解结果具备了物理上的可解释性,通过信息融合的方式进一步提升了增强效果[31]。Li等在此基础上进一步发展,考虑到了背景噪声特定模式在时间上的重复性,利用自相关方法确定重复模式的长度,引入卷积基函数来对重复模式进行建模,并推导了相应的迭代公式,从而提出了新的增强方法[32],所用算法的流程如图7所示。
2.4 声源信号的去混响问题
声源去混响是另一类比较特殊的声源分离问题。从本质上讲,声源只有一个,但是由于在密闭空间内,存在不可预知的多径问题,导致由于多径效应反射回来的音频信号与原始信号相叠加,造成原始信号质量下降[36]。近年来,非负组合模型也被尝试用于解决去语音混响问题。文献[37]基于非负卷积变换函数(Non-negativeconvolutivetransferfunction,N-CTF)和NMF模型提出了去混响算法。


(12)

3 非负组合模型的在线处理与阶数选择
在使用非负组合模型处理声学信号时,常常需要面对两个问题:(1) 在线处理。因为音频信号是典型的流式数据,在一些应用中,无法完全采集下来再进行处理,而是需要不断地根据信号的变化,保持对于基函数的不断更新,即实现在线处理;(2) 阶数的选择。在对声源信号进行建模时,究竟需要多少个基函数来实现对于特定声源的表示,是阶数选择问题研究的核心问题。过少的基函数将无法承载丰富的声源信息,而过多的基函数不仅会浪费宝贵计算资源和内存,更容易产生过拟合的问题,同样影响最终的分离效果。因此选取刚好够用的基函数非常重要。
3.1 非负组合模型的在线处理
在线处理是一种针对海量或流式数据的处理方式。在进行在线处理时,通常需要设定一个统计量,用于存储过去样本的信息,当新样本到来时,通过一定的方式将其内化转变为内部统计量的信息,最终实现在线处理[41]。式(13~14)给出欧式距离下CNSC的迭代公式为
(13)
(14)
式中:Ξ表示一个与V同样大小的全1矩阵,而λ是用于控制编码矩阵稀疏程度的参数。
Wang等[42]在此基础上,通过对式(14)交换次序,引入统计量A和B,得到了CNSC的欧式距离下的在线处理公式,即
(15)
其中训练数据被切分为等长的小块,u为训练样本切片的序号(此处假设各个切片之间相互独立),并且
(16)
(17)
分别为样本切片u的对于统计量A和B的贡献。因此,前面u个样本切片所对应的统计量为

(18)

(19)
伴随着新样本的不断到来以及式(15)的反复迭代,基函数根据新样本的特性不断地对原有基函数进行调整和改变,而过去样本的统计信息则通过A和B不断积累和存储起来。通过上述方式,不断地在原有样本的基础上添加新样本信息的处理方法即为在线处理。文献[27]则推导出了在广义Kullback-Leibler散度下,CNSC的在线学习公式,并将其应用于无监督语音增强中。Lefèvre给出了在Itakura-Saito散度下在线学习的更新公式[43]。
3.2 非负组合模型的阶数选择
当训练样本量规模一定时,如何选择合适的阶数(用于表示非负观测数据的非负基函数的个数),就变成一个非常重要的问题。进行阶数选择的方法有很多,组稀疏[44]、计算密集的马尔科夫链蒙特卡罗(Markov chain Monte Carlo, MCMC)[45]、正则化熵[46]和自相关决策(Automatic relevance determination, ARD)[47]等方法均被用于进行阶数选择。
其中文献[47]结合ARD,引入将W和H相连结的超参数λ(假设Wfk和Hkn服从参数为λk的半高斯分布或指数分布,如式(20,21)所示),并通过最大后验概率(Maximumaposteriori,MAP)估计的方法自动获得合理的阶数。
(1) 当为W和H分配半高斯分布时有
(20)

(2) 当为W和H分配指数先验时,有
(21)
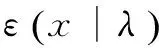
对于每个超参数λk,∀k,添加Inverse-Gamma先验,即
(22)
式中:a和b分别为非负的形状和尺度超参数。所有的λk,∀k共享相同的形状和尺度超参数。文献[48]进一步将其拓展为张量形式,实现了对于具备一定时频结构模式阶数的自动选择。文献[49]使用变分贝叶斯期望最大(VariationalBayesexpectationmaximization,VBEM)的方法,通过对增益矩阵的各个变量进行积分,改进了文献[47]中的算法,通过计算出充分统计量,解决了所需要估计随样本个数增加而线性增大的问题,然而采用变分方法为了计算方面的便利,往往需要选择一些具备共轭性质的分布对。这样的分布虽然便于进行变分求解,然而所做的先验并不总是与实际情况很好吻合。Hoffman基于贝叶斯非参数化方法提出了伽马过程非负矩阵分解(GammaProcessNonnegativeMatrixFactorization,GaP-NMF)算法,在一定程度上使得假设更趋合理[50]。
4 结束语
本文综述了非负组合模型及其在声源分离中的应用。从非负组合模型的定义和优化问题的建立出发,讨论了目标函数的构造与度量,给出了启发式求解算法的推导,作为接下来具体应用的铺垫。在基于非负组合模型的声源分离领域,分全监督、半监督和无监督3种情况分别予以系统的分析、总结和比较。此外,对于非负组合模型经常遇到的在线处理和阶数选择问题,亦给与了介绍和总结,以期为了解非负组合模型算法研究的现状和相关工作的开展提供有益参考。尽管目前基于非负组合模型的声源分离算法取得了一定的成果,然而目前依然存在很多开放的问题有待进一步解决,这些问题主要包括:(1) 求解非负组合模型的高效计算方法。(2)如何在具有噪声污染或数据缺失的自然数据中自适应地选取出所需要的阶数。(3)在有监督声源分离时,训练数据与实际数据之间难免会出现一些出入,当偏差相对较大时,分离算法的性能将会显著下降,如何设计出一种能够依据实际样本特征来进行自适应调整和改变的模式(包括说话人自适应调整和背景噪声自适应学习),依然是有待进一步研究的问题。(4)现有的非负组合模型,往往是基于相对简单的线性叠加方式来进行运算,这样的方法虽然简单易行,然而在面对海量数据时,并不能很好地刻画出数据内在的规律,文献[24]将非负组合模型和深度神经网络的基本思想相结合,利用神经网络的非线性特性,产生了一些初步的研究成果,然而相关领域的发展依然方兴未艾。(5)时序信号的相关性建模一直是音频信号研究的热点和难点问题[51],然而相关性建模问题至今依然未能得到很好的解决。近年来,以循环神经网络(Recurrentneuralnetworks,RNN)和长短时间记忆(Longshort-termmemory,LSTM)为代表的深度时序模型的出现,为相关方向的研究带来了新的希望。针对这些开放问题的进一步研究必将推动相关领域的进一步发展。
[1]VirtanenT,GemmekeJF,RajB,etal.Compositionalmodelsforaudioprocessing:Uncoveringthestructureofsoundmixtures[J].IEEESignalProcessingMagazine,2015,32(2):125-144.
[2]GemmekeJF,J.VanDeLoo,G.DePauw,etal.Aself-learningassistivevocalinterfacebasedonvocabularylearningandgrammarinduction[C]// 13thAnnualConferenceoftheInternationalSpeechCommunicationAssociation2012.Portland,Oregon,USA:InternationalSpeechCommunicationAssociation(ISCA)Press,2012: 1-4.
[3]SmaragdisP,BrownJC.Non-negativematrixfactorizationforpolyphonicmusictranscription[C]//IEEEWorkshoponApplicationsofSignalProcessingtoAudioandAcoustics.NewPaltz.NY:IEEEPress, 2003: 177-180.
[4]GuillametD,SchieleB,VitriaJ.Analyzingnon-negativematrixfactorizationforimageclassification[C]// 16thInternationalConferenceonPatternRecognition.QuebecCity,Canada:IEEEPress, 2002:116-119.
[5]GaoY,ChurchG.Improvingmolecularcancerclassdiscoverythroughsparsenon-negativematrixfactorization[J].Bioinformatics, 2005, 21(21):3970-3975.
[6]FévotteC,DobigeonN.Nonlinearhyperspectralunmixingwithrobustnonnegativematrixfactorization[J].IEEETransactionsonImageProcessing, 2015, 24(12):4810-4819.
[7] 刘维湘, 郑南宁, 游屈波. 非负矩阵分解及其在模式识别中的应用[J]. 科学通报, 2006, 51(3):241-250.
LiuWeixiang,ZhengNanning,YouQubo.Nonnegativematrixfactorizationanditsapplicationsinpatternrecognization[J].ChineseScienceBulletin, 2006, 51(3):241-250.
[8] 李乐, 章毓晋. 非负矩阵分解算法综述[J]. 电子学报, 2008, 36(4):737-743.
LiLe,ZhangYujin.Asurveyonalgorithmsofnon-negativematrixfactorization[J].ACTAElectronicaSinica, 2008, 36(4):737-743.
[9]LeeDD,SeungHS.Learningpartsofobjectsbynon-negativematrixfactorization[J].Nature, 1999, 401(6755):788-791.
[10]BasuA,HarrisIR,HjortNL,etal.Robustandefficientestimationbyminimisingadensitypowerdivergence[J].Biometrika, 1998, 85(3):549-559.
[11]FévotteC,BertinN,DurrieuJ.NonnegativematrixfactorizationwiththeItakura-Saitodivergence:Withapplicationtomusicanalysis[J].NeuralComputation, 2009, 21(3):793-830.
[12]PaateroP,TapperU.Positivematrixfactorization:Anon-negativefactormodelwithoptimalutilizationoferrorestimatesofdatavalues[J].Environmetrics, 1994, 5:111-126.
[13]LeeDD,SeungHS.Algorithmsfornonnegativematrixfactorization[C]//AdvancesinNeuralInformationProcessingSystems(NIPS).Denver,CO,USA:MITPress, 2001:556-562.
[14]SunD,FévotteC.Alternatingdirectionmethodofmultiplicativefornon-negativematrixfactorizationwithbeta-divergence[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing.Florence,Italy,IEEEPress, 2014:6201-6205.
[15]GuanN,TaoD,LuoZ,etal.NeNMF:Anoptimalgradientmethodfornonnegativematrixfactorization[J].IEEETransactionsonSignalProcessing, 2012, 60(6):2882-2898.
[16]CemgilAT.Bayesianinferencefornonnegativematrixfactorisationmodels[J].ComputationalIntelligenceandNeuroscience, 2009,2009:1-17.
[17]VirtanenT.Monauralsoundsourceseparationbynonnegativematrixfactorizationwithtemporalcontinuityandsparsenesscriteria[J].IEEETransactionsonAudio,Speech,andLanguageProcessing, 2007, 15(3):1066-1074.
[18]MohammadihaN,SmaragdisP,LeijonA.Supervisedandunsupervisedspeechenhancementusingnon-negativematrixfactorization[J].IEEETransactionsonAudio,Speech,andLanguageProcessing, 2013, 21(10):2140-2151.
[19]张立伟, 贾冲, 张雄伟, 等. 稀疏卷积非负矩阵分解的语音增强算法[J]. 数据采集与处理, 2014, 29(2):259-265.
ZhangLiwei,JiaChong,ZhangXiongwei,etal.Speechenhancementbasedonconvolutivenonnegativematrixfactorizationwithsparsenessconstraints[J].JournalofDataAcquisitionandProcessing, 2014, 29(2):259-265.
[20]SmaragdisP.Convolutivespeechbasesandtheirapplicationtosupervisedspeechseparation[J].IEEETransactionsonAudio,Speech,andLanguageProcessing, 2007, 15(1):1-12.
[21]DuanZ,MysoreGJ,SmaragdisP.Speechenhancementbyonlinenon-negativespectrogramdecompositioninnon-stationarynoiseenvironments[C]// 13thAnnualConferenceoftheInternationalSpeechCommunicationAssociation2012 (INTERSPEECH2012).Portland,Oregon,USA:InternationalSpeechCommunicationAssociationPress, 2012:1-4.
[22]黄建军, 张雄伟, 张亚非, 等. 时频字典学习的单通道语音增强算法[J]. 声学学报, 2012, 37(5):539-547.
HuangJianjun,ZhangXiongwei,ZhangYafei,etal.Singlechannelspeechenhancementviatime-frequencydictionarylearning[J].ACTAAcustica, 2012, 37(5):539-547.
[23]李轶南, 张雄伟, 曾理, 等. 改进的稀疏字典学习单通道语音增强算法[J]. 信号处理, 2014, 30(1):44-50.
LiYinan,ZhangXiongwei,ZengLi,etal.Animprovedmonauralspeechenhancementalgorithmbasedonsparsedictionarylearning[J].SignalProcessing, 2014, 30(1):44-50.
[24]SunM,ZhangX,hammeHV,etal.Unseennoiseestimationusingseparabledeepautoencoderforspeechenhancement[J].IEEE/ACMTransactionsonAudio,SpeechandLanguageProcessing, 2016, 24(1):93-104.
[25]李轶南, 贾冲, 杨吉斌, 等. 稀疏低秩模型下的单通道自学习语音增强算法[J]. 数据采集与处理, 2014, 29(2):286-292.
LiYinan,JiaChong,YangJibin,etal.Self-learningapproachformonauralspeechenhancementbasedonsparseandlow-rankmatrixdecomposition[J].JournalofDataAcquisitionandProcessing, 2014, 29(2):286-292.
[26]SchmidtM,LarsenJ.Reductionofnon-stationarynoiseusinganon-negativelatentvariabledecomposition[C]//IEEEWorkshoponMachineLearningforSignalProcess.(MLSP).Cancun,Mexico:IEEEPress, 2008:486-491.
[27]LiY,ZhangX,SunM,etal.Onlineconvolutivenon-negativebaseslearningforspeechenhancement[J].IEICETransactionsonFundamentalsofElectronicsCommunicationsandComputerSciences, 2016,E99-A(8):1609-1613.
[28]SunDL,MysoreGJ.Universalspeechmodelsforspeakerindependentsinglechannelsourceseparation[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Vancouver,BritishColumbia,Canada:IEEEPress,2013:141-145.
[29]KimM,SmaragdisP.Mixturesoflocaldictionariesforunsupervisedspeechenhancement[J].IEEESignalProcessingLetters, 2015, 22(3):293-297.
[30]GermainFG,MysoreGJ.Speakerandnoiseindependentonlinesingle-channelspeechenhancement[C]∥IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Brisbane,Queensland,Australia,IEEEPress,2015:71-75.
[31]SunM,LiY,GemmekeJF,etal.SpeechenhancementunderlowSNRconditionsvianoiseestimationusingsparseandlow-rankNMFwithKullback-Leiblerdivergence[J].IEEE/ACMTransactionsonAudio,Speech,andLanguageProcessing, 2015, 23(7):1233-1242.
[32]LiY,ZhangX,SunM,etal.Adaptiveextractionofrepeatingnon-negativetemporalpatternsforsingle-channelspeechenhancement[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Shanghai,China:IEEEPress,2016:494-498.
[33]LiY,ZhangX,SunM,etal.Speechenhancementusingnon-negativelow-rankmodelingwithtemporalcontinuityandsparsenessconstraints[C]// 17thPacific-RimConferenceonMultimedia.Xi′an,China:SpringerPress, 2016:24-32.
[34]李轶南, 张雄伟, 贾冲, 等. 稀疏低秩噪声模型下无监督实时单通道语音增强算法[J]. 声学学报, 2015, 40(4):607-614.
LiYinan,ZhangXiongwei,JiaChong,etal.Unsupervisedreal-timesinglechannelspeechenhancementwithlow-rankandnoisemodel[J].ActaAcustica, 2015, 40(4):607-614.
[35]Po-SenHuang,ScottDeeannChen,ParisSmaragdis,etal.Singing-voiceseparationfrommonauralrecordingsusingrobustprincipalcomponentanalysis[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Kyoto,Japan:[s.n.],2012:57-60.
[36]WuB,LiK,YangM,etal.Areverberation-time-awareapproachtospeechdereverberationbasedondeepneuralnetworks[J].IEEE/ACMTransactionsonAudio,SpeechandLanguageProcessing, 2017, 25(1):98-107.
[37]MohammadihaN,DocloS.Speechdereverberationusingnon-negativeconvolutivetransferfunctionandspectro-temporalmodeling[J].IEEE/ACMTransactionsonAudio,Speech,andLanguageProcessing, 2016, 24(2):276-289.
[38]YasuraokaN,KameokaH,YoshiokaT,etal.I-divergence-baseddereverationmethodwithauxiliaryfunctionapproach[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing.Prague,CzechRepublic:IEEEPress, 2011:369-372.
[39]MohammadihaN,SmaragdisP,DocloS.Jointacousticandspectralmodelingforspeechdereverberationusingnon-negativerepresentation[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing.Brisbane,Queensland,Australia:IEEEPress, 2015:4410-4414.
[40]SinghR,RajB,SmaragdisP.Latent-variabledecompositionbaseddereverberationofmonauralandmulti-channelsignals[C]//IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Dallas,Texas,USA:IEEEPress,2010:1914-1917.
[41]GuanN,TaoD,LuoZ,etal.Onlinenon-negativefactorizationwithrobuststochasticapproximation[J].IEEETransactionsonNeuralNetworksandLearningSystems, 2012, 23(7):1087-1099.
[42]WangD,VipperlaR,EvansN,etal.Onlinenon-negativeconvolutivepatternlearningforspeechsignals[J].IEEETransactionsonSignalProcessing, 2013:61(1):44-56.
[43]LefèvreA,BachF,FévotteC.OnlinealgorithmsfornonnegativematrixfactorizationwiththeItakura-Saitodivergence[C]//IEEEWorkshoponApplicationsofSignalProcessingtoAudioandAcoustics.MohonkMountainHouse,NewPaltz,NY,USA:IEEEPress, 2011:313-316.
[44]YuanM,LinY.Modelselectionandestimationinregressionwithgroupedvariables[J].JournaloftheRoyalStatisticalSociety,SeriesB, 2007, 68(1):49-67.
[45]ZhongM,GirolamiM.ReversiblejumpMCMCfornonnegativematrixfactorization[C]//InternationalConferenceonArtificialIntelligenceandStatistics.Florida,USA:MITPress,2009:663-670.
[46]SunM,ZhangX,HammeHV.Astableapproachformodelorderselectioninnonnegativematrixfactorization[J].PatternRecognitionLetters, 2015 (54):97-102.
[47]TanVYF,FévotteC.Automaticrelevancedeterminationinnonnegativematrixfactorizationwiththebetadivergence[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2013, 35(7):1592-1605.
[48]LiY,ZhangX,SunM,etal.Automaticmodelorderselectionforconvolutivenon-negativematrixfactorization[J].IEICETransactionsonFundamentalsofElectronicsCommunicationsandComputerSciences, 2016,E99-A(10):1867-1870.
[49]RenkensV,hammeHV.AutomaticrelevancedeterminationfornonnegativedictionarylearningintheGamma-Poissonmodel[J].SignalProcessing, 2017, 132:121-133.
[50]HoffmanM,BleiD,CookP.Bayesiannonparametricmatrixfactorizationforrecordedmusic[C]// 27thInternationalConferenceonMachineLearning(ICML2010).Haifa,Israel:TheInternationalMachineLearningSociety(IMLS)Press, 2010:439-446.
[51]SmaragdisP,FévotteC,MysoreGJ,etal.Staticanddynamicsourceseparationusingnonnegativematrixfactorizations:Aunifiedview[J].IEEESignalProcessingMagazine, 2014, 31(3):66-75.
@163.com。

胡永刚(1991-),男,博士研究生,研究方向:多媒体信息处理。

李轶南(1988-),男,博士研究生,研究方向:语音分离、语音增强。

陈栩杉(1987-),男,博士,讲师,研究方向:多媒体信息处理,E-mail:cxs_papip@163.com。

时文华(1982-),女,博士研究生,研究方向:语音与图像处理、多媒体信息处理。
Non-negative Compositional Models and Its Application in Acoustic Source Separation
Zhang Xiongwei1, Li Yinan1, Shi Wenhua1,2, Hu Yonggang1, Chen Xushan3
(1.College of Command Information System, PLA University of Science and Technology, Nanjing, 210007, China;2.Flight Instructor Training Base, Air Force Aviation University, Bengbu, 233000, China;3.Lab of Political Information, People′s Armed Police Institute of Politics, Shanghai, 201703, China)
Non-negative compositional models are of great importance in the application of artificial intelligence, data mining and intelligent information processing research. They have gradually become one of the most representative and frequently used models of acoustic source separation in recent years. The embedded additive combination of non-negative components matches well with the characteristic of human perception. Techniques that make use of non-negative compositional models have been increasingly popular in acoustic source separation. Starting from the most basic non-negative compositional model, which is termed as non-negative matrix factorization (NMF), we firstly review the principles of non-negative compositional model, including the basic problem to be solved, the measurement of objective function and some typical methods to solve related problems. Based on these principles, we systematically discuss the variety extensions of NMF designed for particular applications in acoustic source separation. Finally, some open problems are presented and discussed.
acoustic source separation; non-negative compositional model; non-negative matrix factorization
国家自然科学基金(61471394,61402519)资助项目;江苏省自然科学基金(BK20140071, BK20140074)资助项目。
2015-06-05;
2016-06-30
TN912.3
A

张雄伟(1965-),男,教授,博士生导师,研究方向:语音与图像处理、多媒体信息处理,E-mail:xwzhang9898
