基于项目属性偏好的个性化推荐技术∗
2017-04-27冯晓川王正成
冯晓川 王正成
随着各电子商务系统中用户和项目数据的指数性增长,如何与用户建立联系并实时高效地推荐系统信息,从而实现信息消费者和商家的双赢局面,越来越受到重视。但目前推荐评价数据稀缺,这严重影响到推荐系统的推荐精度,而且已经成为各类电子商务系统发展的瓶颈。要实现有效的个性化推荐必须解决好当前所面临的两大主要问题:数据稀疏性和算法有效性。
针对项目的具体属性评价有效性数据稀疏这一问题,研究人员提出了不少增加有效性数据的方法,如缺省值填充法和预测值填充法等。在一定程度上,前者可以降低数据稀疏性,但没有考虑到不同的项目和各个用户之间的差异。后者为根据项目之间的相似性使用预测值填充的方法来初步预测用户对未评分项目的评分[1],相应的预测方法有Slope One方法[2]、BP神经网络[3]等。甚至一些学者提出通过删除一些无效数据或无效评分项目来降低数据稀疏性,这虽然在一定程度上减少了标记稀疏矩阵,但是,被删除的用户或项目已经失去了推荐和被推荐的机会[4]。
比较经典传统的个性化推荐算法是最近邻协同过滤推荐算法。该算法需要在整个用户空间搜索目标用户的最近邻居,采用一种混合加权预测填充算法。然而在现实中大型的专业电子商务推荐网站,因为用户的项目评分矩阵稀疏性过高,导致系统项目中被用户有效评分过的项目数量低于总数的 1%[5]。因此通过基于传统的用户协同过滤相似度计算方法很难找到准确的最近邻居,导致推荐质量降低。
笔者提出基于用户的特定属性偏好值计算用户之间的相似度,并在此基础上进一步预测用户对项目的具体属性未评分部分的评分,以此改善原始用户项目评价矩阵的数据稀疏状况,达到数据的稠密性要求。最后采用流行的协同过滤算法实现基于项目属性偏好的个性化推荐。
1 基于项目属性偏好的推荐过程模型
针对现有的基于用户的协同过滤算法存在的不足,笔者提出了基于项目属性偏好的协同过滤算法,推荐过程模型如图1所示。

图1 基于项目属性偏好的推荐过程模型Fig.1 Recommendation process model based on item attribute preference
2 基于项目属性偏好的协同推荐算法
2.1 项目特征属性矩阵
一个项目包含多种类别属性,例如木材有物质和非物质的属性。项目属性集合可以用集合{Attr1,Attr2,… ,Attrk}表示,其中某个项目特征属性矩阵用A表示, 其中A(i,j)=1。若项目i具备属性j,则值为1;为0则代表项目i不具备属性j。基于上述考虑,构建项目特征属性矩阵如表1。

表1 项目特征属性矩阵示意表Tab.1 Schematic table of project characteristic properties matrix
2.2 用户项目属性偏好矩阵
借鉴文献[6]用户项目属性偏好计算方法,不同用户对某项目的属性i偏好程度L(u,i)计算公式如(1)所示:

上式allScore(u,i)表示用户u对具有项目属性i的所有项目的评分值之和,allScore(u)表示用户u对所有项目的评分值和。
根据公式(1)计算结果,可用一个二维数组来表示用户对所有的项目属性的偏好程度,如表2所示。

表2 用户项目属性偏好示意表Tab.2 Schematic table of preference of project properties for users
2.3 基于项目属性偏好的用户相似性
借鉴传统协同过滤推荐算法中余弦相似性方法,笔者提出用户u和v基于项目属性偏好的相似度sim(u,v)计算如公式(2)所示。

其中,k代表项目具有k种属性。
2.4 基于用户相似性项目评分预测
为了解决传统的基于用户的协同过滤算法中相关相似度计算数据稀疏性问题,提出基于项目属性偏好的用户相似性计算方法:假设用户u参与评分的项目集合为Iu,用户v参与评分的项目集合为Iv,找到它们的并集为U(u,v)=Iu∪Iv。用户u或用户v对项目集合U(u,v)中项目i的评分计算如公式(3)所示:

ru,i为原始用户项目矩阵中用户u对项目i的评分。当用户u对项目i有评分,则评分等于其实际评分。当用户u对项目未评价,则评分可通过基于项目属性偏好的用户相似性进行预测,该预测值Pu,i计算如公式(4)所示。

其中siml(u,v)表示用户u和用户v是基于项目属性偏好用户相似度,Rv,i表示用户v对项目i的实际评分,N(u)为用户u的基于项目属性偏好相似度的最近邻居集合。
经过上述处理,用户u与用户v的共同评分项目数据集增加,这样用户u和v对U(u,v)的评分就都是非0值,可有效缓解传统的协同过滤算法相似性计算中的数据稀疏性问题。
3 实验结果与分析
3.1 数据集
笔者实验所采用的数据集是 epinion数据集,此数据集包含了 49 290 个独立用户对139 738件物品的评分,每个物品都至少被评分一次,共有 664 824个评分记录,其中物品的属性被定义为127种类别,每一件物品具有一种或多种属性。10 501个评分数据被随机选择为实验数据集,其中共包含101个独立用户和1 288件物品,其中每个用户至少对200件以上物品进行了评分。稀疏等级为:

整个实验数据集按一定规则分成训练集和测试集,笔者从实验数据集中选取75%的数据作为训练集,25%作为测试集。
3.2 评价标准
实验中,笔者采用平均绝对误差作为度量算法优劣的标准。推荐精度与平均绝对误差值成反比。假设测试集中有t条有效评分数据,分别为{R1,… ,Rt},提出的推荐算法对这些评分的预测值分别设定位为{P1,… ,Pt},则目标用户u的平均绝对误差计算如公式(5)所示。
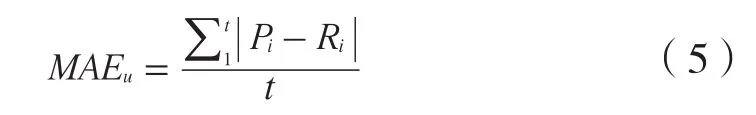
3.3 实验设计
根据文中第1章节中提出的推荐过程模型及第2章节中所述的推荐算法,设计算例实现类如图2所示。
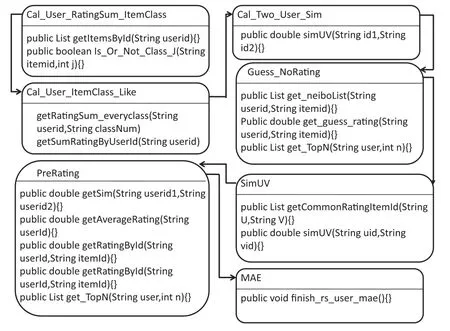
图2 算例设计类图Fig.2 Class diagram of an example design
图2的类Cal_user_RatingSum_ItemClass中实现获得用户userid有评分的所有项目。类Cal_user_ItemClass_Like中封装的两个方法来计算用户对每个项目属性的偏好值。类Cal_Two_user_Sim计算不同用户之间相似度。类Guess_NoRating中有3个行为方法,其中TopN(){}目的是获得用户user的前n个邻居, get_neiboList(){}目的是获得userid的邻居集,方法get_guess_rating(){}预测userid对itemid的评分。类SimuV主要实现计算用户之间的相似度,其中getCommonRatingItemId(){}方法实现不同用户共同评分的项目编号的获取。类PreRating中5个行为方法, 不同用户的相似度通过getSim(){}实现获取, 用户u对public double getRatingById平均分通过getAverageRating(){}来获取用户对项目的评分。类MAE主要功能是通过训练集预测测试集中的用户对项目的评分。
3.4 实验结果
以传统的协同过滤推荐算法作为对照,笔者对提出的改进算法的推荐质量进行了测试。在预测用户未评分的项目评分时,笔者是通过计算基于项目属性偏好的用户相似度,选取5作为最近邻居数。改进的算法以相关相似性方法作为用户/项目之间相似性度量标准并计算其平均绝对误差,实验中目标用户/项目的邻居个数从4增加到20,间隔为4。实验数据库为Oracle,开发环境为myeclipse,开发语言选用Java实现。实验结果如图3所示。
由图3可知,笔者提出的算法在不同的邻居数情况下均具有最小的平均绝对误差。这是因为在基于项目属性偏好的协同过滤方法中,用户项目评分矩阵中无评分项目的评分是通过基于项目属性偏好的用户相似度初步预测的,这就使得多用户之间共同评分项目增多,提高了算法的推荐精度。实验表明,与传统的推荐算法相比,该解决方案能切实提高项目的推荐精度。

图3 推荐算法的推荐绩效对比示意图Fig.3 Contrast schematic diagram of recommended algorithm
4 结语
面对指数增长的海量信息,如何根据用户的个性化需求提供快速有效的产品服务推荐是当今网络信息社会研究的重点与难点。传统的推荐算法目前还存在一些难以克服的缺点,如用户评分的有效数据稀疏、预测结果不精确等问题。笔者提出的基于项目属性偏好的协同过滤个性化推荐模型与算法,在理论上为解决个性化推荐技术中项目评分数据稀疏性和预测精确性问题提出了一种新的研究方案,在实践中通过验证表明,该解决方案能切实提高推荐精度。文中提出的方法如用于行业特色鲜明、供求信息精简的木制品贸易网站,可很好地提升产品推荐的效率。
[1]雷琨.电子商务个性化推荐系统研究[D].成都:电子科技大学,2012.
[2]李聪.电子商务推荐系统中协同过滤瓶颈问题研究[D].合肥:合肥工业大学,2013.
[3]陈晓诚.基于信任传播模型的协同过滤推荐算法研究[D].广州:中山大学,2010.
[4]孙小华.协同过滤系统的稀疏性与冷启动问题研究[D].杭州:浙江大学,2012.
[5]Matevi Kunaver,Tomai Poirl,Matevi Pogacnik,et al.Optimization of combined collaborative recommender systems[J].International Journal of Electronics and Communications,2007,61(7):433-443.
[6]夏培勇.个性化推荐技术中的协同过滤算法研究[D].青岛:中国海洋大学,2011.
