基于降噪自动编码器特征学习的音乐自动标注算法
2017-04-27华东理工大学信息科学与工程学院上海200237
黎 鹏, 陈 宁(华东理工大学信息科学与工程学院,上海 200237)
基于降噪自动编码器特征学习的音乐自动标注算法
黎 鹏, 陈 宁
(华东理工大学信息科学与工程学院,上海 200237)
目前,音乐自动标注模型大多采用手动设计模式,因而存在最佳特征难以选择的问题。提出了一种基于非监督学习的特征学习算法,该算法能自动学习特征的潜在结构而不需要依赖先验知识。 首先,预处理阶段主要提取音乐的音级轮廓频率谱并进行PCA白化降维处理;然后,采用深度学习中的降噪自动编码器算法对降维后的特征进行无监督的学习,并采用最大值池化和取均值来聚合得到新的特征向量;最后,将特征向量和标签送入多层感知机中进行有监督的学习。 基于Magnatagatune和GTZAN数据库的实验结果表明,本文算法在一定程度上提高了音乐自动标注的准确率。
深度学习; 音乐自动标注; 降噪自动编码器; 多层感知机
随着数字化技术、多媒体技术和互联网的广泛兴起和应用,在线数字音乐蓬勃发展,其数量按指数规律增长。 互联网使得人们更加容易共享、浏览各种音乐资源,同时也产生了诸多具有挑战性的问题,例如,用不同的方法实现歌曲检索、歌曲分类、翻唱歌曲的识别或者个性化推荐音乐等。 基于内容的音乐信息检索(Music Information Retrieval,MIR)在一定程度上解决了这些问题。
音乐自动标注的目的是根据音乐内容来预测多种标签,进行自动识别和标注,它是一种基于音乐内容的音乐分类技术。 一般地,音乐分类任务分成两步:特征提取和监督学习。Hamel等[1]提出了提取PCA降维后的Mel频率谱特征,利用池化函数将频率谱聚合成新的特征,最后用监督学习算法学习标签。之后,Hamel等[2]提出利用监督学习将不同分帧长度的特征融合成新的特征。 Mel频率谱都是手动设计的,虽然在一定程度上取得了较好效果,但是这些基于先验知识的特征往往需要大量实验,而且如何实现特征的选择以达到最佳的组合也是一个问题。
近几年,机器学习和深度学习在计算机视觉和自然语言处理领域已取得了很好的效果[3]。深度学习是具有多层结构的机器学习算法,它能有效地表征特征的潜在结构,其中深度置信网络和卷积神经网络就是两种典型的算法。尽管深度学习取得了较好的性能,但是人们很难解释这些数据挖掘算法以及学习算法与音乐语义之间存在的内在联系。
分类算法是机器学习中常见的算法,被广泛运用于信号处理领域,例如KNN算法用于手写识别[4]、半监督式排序用于学习推荐系统中的用户偏好[5]以及多协同表示用于人脸识别[6]等。在音乐信息检索领域,MIR研究人员将分类算法应用于自动标注。 Lee等[7]提出基于卷积深度置信网络的频谱学习和音乐分类算法;Henaff等[8]提出基于稀疏编码无监督学习的对数频率谱特征,然后用线性支持向量机SVM进行学习;Wulfing等[9]提出基于自举式K-means算法对特征聚类形成特征字典,然后用SVM进行分类;Nam等[10]提出基于稀疏限制玻尔兹曼机无监督学习的Mel频率谱,并对其采用线性分类器进行分类;Sigtia等[11]用深度神经网络进行音乐流派分类;Oord等[12]提出用球形K-means算法无监督学习音乐特征,然后用MLP进行音乐分类;Dieleman等[13]提出用卷积神经网络对频率谱和原始歌曲特征学习,用学习后的特征进行音乐自动标注;Choi等[14]提出用完全卷积神经网络进行音乐自动标注。
本文提出了基于降噪自动编码器[15]深度特征学习的音乐自动标注算法。目前,将降噪自动编码器用于音乐自动标注领域的研究鲜见报道。 本文算法采用无监督和监督两种不同的学习方法对降维后的chroma标度的频率谱进行学习,在无监督学习阶段,采用降噪自动编码器对特征矩阵进行无监督的学习,然后将学习后的特征矩阵进行最大值池化和取均值来聚合成“词袋”(Bag-of-features)形式的特征向量。 在监督学习阶段,将聚合后的特征向量作为输入,对应歌曲的标签作为输出,采用预训练后的多层感知机模型进行有监督的学习。 最后,仿真实验结果验证了非监督学习的特征比手动设计特征具有更好的性能,显示出非监督学习算法特征学习具有一定的优势.
1 降噪自动编码器
1.1 自动编码器算法
降噪自动编码器(Denoising autoencoder)是自动编码器(Autoencoder)[15]的一种变形,是一种无监督学习算法,多层叠加可构成深度学习网络。
自动编码器是一种无监督学习算法,是一种特殊的神经网络。 神经网络将输入数据x(i)映射成输出标签z(i),是一种监督学习算法。 而自动编码器的特点是它的输出标签就是输入本身,即z(i)=x(i),它通过网络来学习输入数据潜在的结构和特性,而用潜在的隐含层作为真正的输出y(i)。
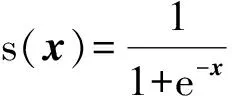
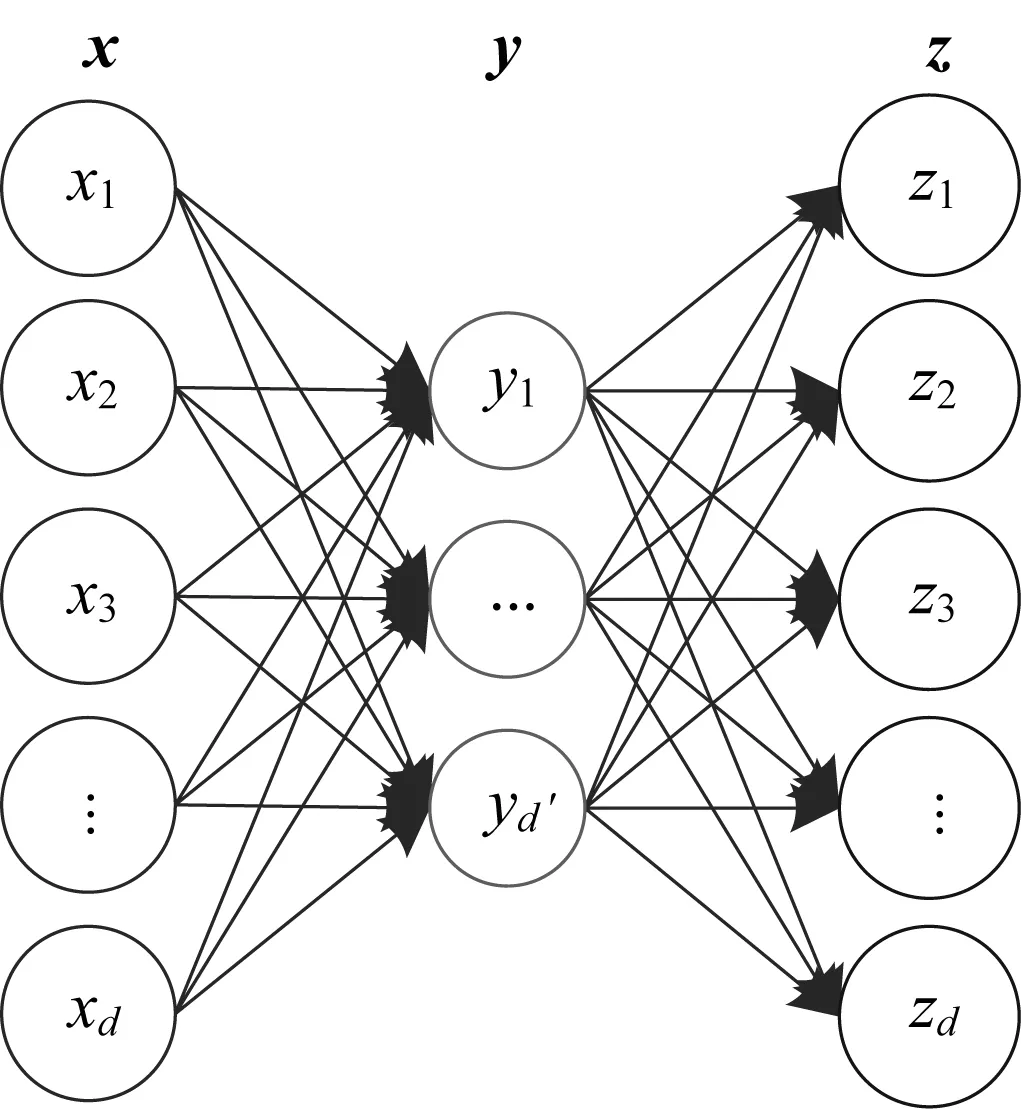
图1 自动编码器算法示意图
每个输入向量x(i)都映射成了对应的隐含层向量y(i)以及重构输出向量z(i),模型参数的优化值可以通过最小化重构误差得到。 最优化的过程可以通过对式(1)进行随机梯度下降法来实现。
(1)
其中L为损失函数。最常见的损失函数是均方误差L(x,z)=‖x-z‖2,如果输入x∈[0,1]d或服从Bernoullis分布,损失函数也可以定义为式(2)的重构交叉熵形式。
(2)
1.2 降噪自动编码器

图2 降噪自动编码器示意图
降噪自动编码器是在自动编码器的基础上,在训练数据中加入噪声,所以自动编码器必须学习去除这种噪声而获得真正的没有被噪声污染的输入。因此,这就迫使编码器去学习输入信号更加鲁棒性的表达,这也是它的泛化能力比一般编码器强的原因。
2 音乐自动标注算法
2.1 概述
本文提出的方法可以分为3个阶段:预处理阶段、无监督学习和聚合阶段、监督学习阶段。 图3展示了该算法的主要流程,图中虚线表示只在训练过程中执行该步骤。

图3 音乐自动标注的主流程图
2.2 预处理
这一阶段的主要目的是提取未归一化的chroma频率谱特征,并进行PCA降维处理。 预处理阶段可以大致分成短时傅里叶变化、自动增益控制、映射成未归一化的chroma频率谱、幅度压缩以及PCA白化5个步骤。
首先,对音乐信号进行短时傅里叶变换,从而得到频率谱。 由于音乐信号在声音幅度上有较大的动态差别,受到人耳动态范围压缩机制的启发,利用自动增益控制[16]来调节音乐幅度。
然后,将自动增益调节后的线性频谱映射为chroma频谱。与传统方法不同,在提取chroma时不对数据进行归一化处理,这一步既保留了原来线性频谱的显著特性,又降低了输出的维度。
之后,将chroma频率谱按对数压缩公式(3)进行幅度压缩。
Z=lg(1+C·chroma)
(3)
其中C控制压缩程度。在这一步后,每一首歌曲对应了一个幅度压缩后的chroma特征矩阵。
由于在训练过程中,训练的歌曲较多,每首歌都对应着一个特征矩阵,如果不加以选择全部用于训练会导致训练中的特征矩阵维度非常大,而且并不是所有特征都是有用且具有代表性的。为了在第2阶段无监督学习过程中,尽可能学习到有用的特征向量,采用起始点检测的方法从每首歌的特征矩阵中抽取出起始点处的特征向量,将这些向量构成新的特征矩阵作为训练的输入特征。需要注意的是,起始点检测仅仅用于训练过程,在非训练过程中,特征依然是整个幅度压缩后的chroma频率谱。
PCA白化是预处理的一个常见步骤,它被用来去除成对的相关性或降低数据的维度。PCA白化矩阵实际上是在训练过程中得到的,它的计算是将起始点检测后的样本矩阵进行PCA处理,并在PCA空间进行个体方差归一化后得到,本文在PCA降维过程中保留了90%的方差。
2.3 无监督学习和聚合
在这个阶段,对PCA降维后的特征矩阵无监督地学习,然后用最大值池化和取均值来聚合成“词袋”(Bag-of-features)形式的特征向量。
(1) 降噪自动编码器。在前一阶段,我们得到了PCA白化后的chroma特征,由于这个特征是根据先验知识手动设计的,因此在这一步,采用具有较强鲁棒性和泛化能力的降噪自动编码器来无监督学习特征。
降噪自动编码器是个典型的瓶颈模型,隐含层作为真正输出。 在训练过程中,将PCA白化后的特征矩阵X破坏成X0,并让破坏后的X0无监督学习得到最终输出层Xc,我们希望Xc尽可能与未破坏的X接近。在这一阶段要优化目标函数(式(4))并得到最佳的参数权重矩阵W和偏差向量b:
(4)
其中:λ为正则项参数,也称为权值衰减(Weight decay);‖·‖F为Frobenius范数。
在训练过程中,将起始点检测抽样的每帧特征作为输入向量,隐含层节点数设置为1 024,使用AdaDelta[17]进行梯度更新。该方法不需要手动微调学习速率,同时对模型结构中的噪声梯度信息和方差具有较强鲁棒性。 降噪自动编码器算法采用一个深度学习软件库(deepmat),在训练过程中使用GPU加速,大大缩短训练时间。
(2) 聚合。训练结束后,学习起始点检测后的特征矩阵,并得到最优的权重矩阵W和偏差向量b。 然后将每首歌的所有特征通过具有最优参数的降噪自动编码器模型激活得到隐含层,将该特征作为之后的输入。
按照图4所示的聚合过程采用最大值池化和取均值对学习到的特征进行聚合。用最大值池化聚合特征已在文献[1]中被证明是有效的,因为它按照时域对固定的特征分块,最大值池化用来保留分块中具有最大峰值的帧,滤除剩余不具典型的帧。 将最大值池化后的特征取均值得到新的“词袋”形式的特征向量。
2.4 监督学习
在这一阶段,有监督地将“词袋”形式的特征向量和对应的歌曲标签送入分类器学习,采用预训练后的多层感知机MLP来预测音乐的标签。构造具有4层结构的多层感知机,即隐含层3层,以监督学习方式来学习“词袋”形式的特征向量和对应歌曲语义标签。

图4 “词袋”形式的特征向量的聚合过程
在预训练过程中,首先利用叠加的3层降噪自动编码器对“词袋”形式的输入特征向量进行无监督学习;然后,用降噪自动编码器学习到的各层优化后的参数分别初始化多层感知机的隐含层参数;最后通过BP(Back Propagation)算法对整个多层感知机模型进行微调。
假设第i个“词袋”向量为ui,对应的标签向量为vi∈[0,1]160(本实验数据库中每首歌对应160个标签,所有标签向量维数为160),微调过程中需要优化的目标函数如下:
(5)
对误差进行随机梯度下降法可以优化得到最佳的参数θ,本文采用AdaDelta进行梯度更新。除此之外,采用dropout[18]技术通过将隐含层和输入层随机置0来实现增强神经网络的泛化误差。AdaDelta和dropout有效地提升了学习的性能。
3 仿真实验
3.1 实验1
3.1.1 数据库 Magnatagatune歌曲库[19]是音乐标注领域一个常用的数据库,也是本文实验采用的数据库。 该库包含长度为29 s的带标签的MP3歌曲片段,每个歌曲片段对应160个歌曲标签。 本文采用与文献[1]相同的2009版本的数据库,将该数据库分成训练库、验证库和测试库,对应的库分别包含14 660、1 629、6 499首歌曲,训练库和验证库用于训练,测试库用于测试得出最终实验结果。
3.1.2 评估方法 采用与文献[1]相同的评估方法,分别为针对标签的ROC(Receiver Operating Characteristic)曲线下的面积(AUC-T)、针对歌曲片段的ROC曲线下的面积(AUC-C),以及top-K准确度,实验中K分别取值3、6、9、12、15。
3.1.3 实验参数 预处理阶段,将采样率为22.05 kHz的音频文件分帧,每帧1 024点(约46 ms)且50%重叠,加汉宁窗,映射到chroma频率带,但是不对chroma进行归一化,过滤掉较低频率带,最终得到80维的chroma特征。 幅度压缩时将压缩强度参数C设置为10,PCA白化过程中保留了90%的方差。
无监督过程中,将学习速率为0.03的降噪自动编码器的隐含层设置为1 024,然后分别按照时间长度为0.25、0.5、1、2、4 s分块对特征进行最大值池化,讨论池化长度对实验结果的影响。
在监督学习的预训练过程中,将3层降噪自动编码器的每一层的权值衰减系数λ在0.000 1和0.001之间调整,并对实验结果进行讨论。
3.1.4 实验结果 分别按照时间长度为0.25、0.5、1、2、4 s分块对特征进行最大值池化,讨论最大值池化的不同长度对本文算法的影响,图5示出了池化长度对实验结果的影响。 实验结果表明,随着池化长度的增加,AUC-T结果呈现出先增加后微弱下降的趋势,而当池化长度为1 s时取得最好的AUC-T结果。
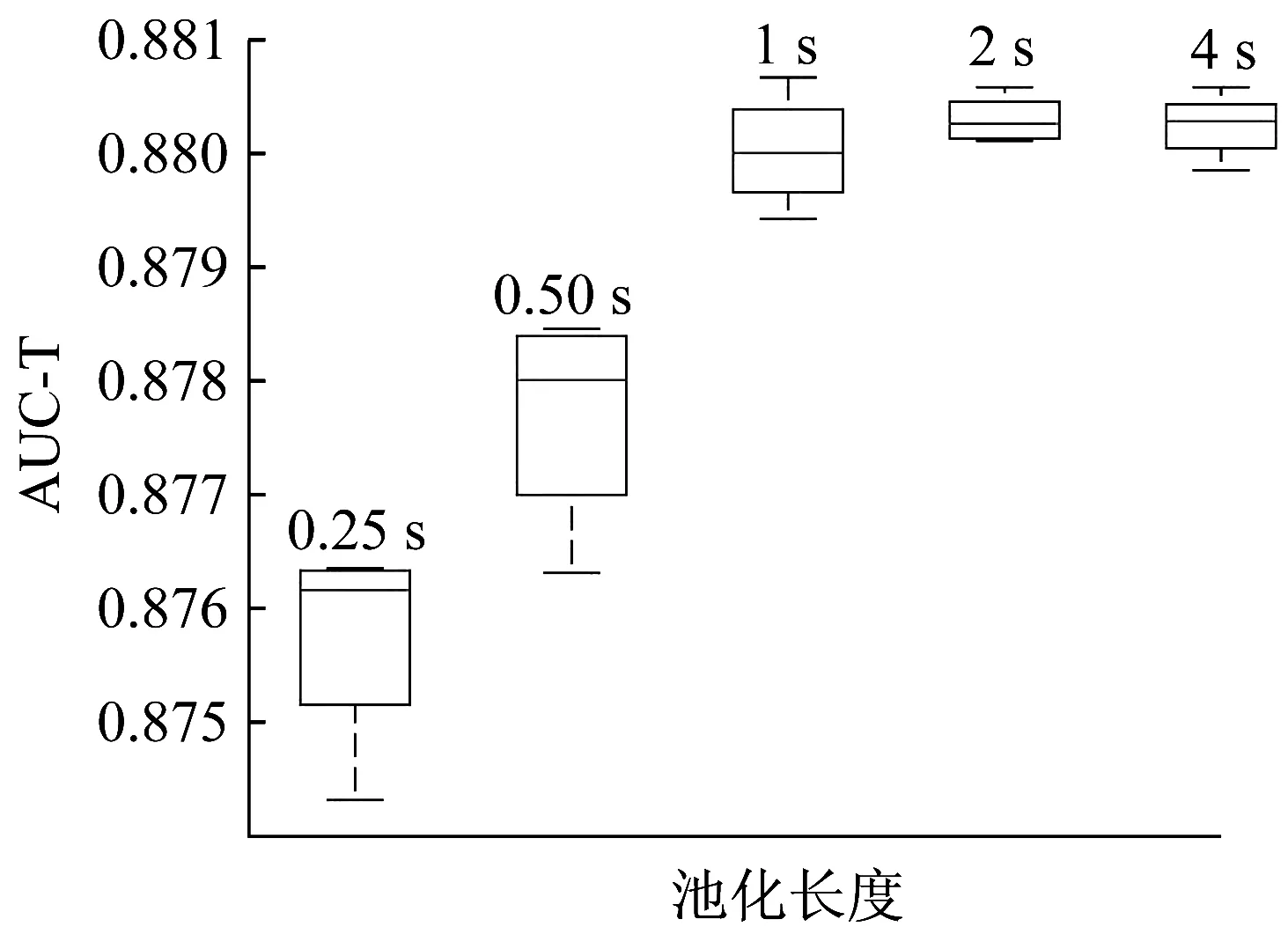
图5 不同池化长度对实验结果的影响
在用多层感知机进行3层监督学习之前,采用预训练的降噪自编码器的参数对多层感知机进行初始化,具体做法是分别调整各层的权值衰减系数为0.000 1和0.001,在调节单层时,保持该层参数不变,其他层参数变化,分别讨论3个隐含层L1、L2、L3降噪自编码器的权值衰减λ对实验结果的影响,得到8种不同的预训练结果。分析这些数据得到如图6的分析图。可以发现L1层随着权值衰减系数λ的增加,实验结果呈下降趋势,最优的实验结果在λ为0.000 1时得到。L2层中,当权值衰减系数λ取0.001时,实验结果具有最大值和平均值,而L3层中,当权值衰减系数λ增加时,实验结果具有缓慢下降的趋势。 分析结果表明,随着L1和L3层权值衰减系数λ的增加,实验结果呈现下降的趋势,实验结果的最优值倾向于衰减系数较小时得到。
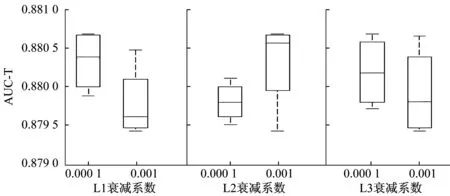
图6 不同层的权值衰减系数λ的实验结果
通过实验发现,当池化长度设置为1 s,L1衰减系数系数设置为0.000 1,L2和L3衰减系数设置为0.001时,实验取得最佳结果。将本文算法与文献[1-2]提出的算法进行对比,表1列出了对比结果,但文献[1-2]是对所有160个标签进行AUC-T评估。实验结果显示,本文算法的实验结果比文献[1-2]的实验结果要好,AUC-T160达到了0.881,AUC-C达到了0.954,而top-K中P3和P6的准确率提高了0.02左右,P9、P12和P15也都有所提高。
文献[12-14]提出的音乐自动标注算法都是基于Magnatagatune数据库,但是这些算法都选取Top-50标签,以此来进行实验评估。由于这些算法只有Top-50标签的ROC曲线下的面积AUC参数,为了对比,本文在之前的实验基础上,也将输出的标签设置为Top-50的标签,以此对整个歌曲库作出AUC-T50的评估,实验结果如表2所示。实验结果显示,当池化长度设置为1 s,L1衰减系数设置为0.000 1,L2和L3衰减系数设置为0.001时,取得基于Top-50的标签最大的AUC-T50。

表1 160个标签时的实验对比结果

表2 AUC-T50的实验对比结果
3.2 实验2
3.2.1 数据库 为了验证本文算法的有效性,在实验1的基础上增加了GTAZN歌曲库[20],它是音乐标注领域一个常用的数据库。 该库包含了1 000首歌曲片段,每首歌曲片段长30 s,一共有10种标签,每首歌曲对应一个标签。由于GTAZN歌曲库是第一个被公开的音乐分类库,因此被广泛作为音乐自动标注的基准库[20]。
3.2.2 评估方法 用准确度进行评估,并用10折交叉验证评估方法,每次交叉验证时,将1 000首歌曲中的900首作为训练,余下的100首作为验证,一共进行10次,然后将10次得到的准确度取均值,得到最后的平均准确度。
3.2.3 实验结果 参照Magatagatune歌曲库相同的调节参数过程,得到了基于GTAZN库的最优的实验结果。 当池化长度设置为1 s,L1衰减系数设置为0.000 1,L2和L3衰减系数分别设置为0.001时,实验取得最佳结果,表3列出了对比结果。 实验结果显示,基于GTAZN歌曲库,在取得较好的平均准确率的同时,也验证了本文算法的有效性。

表3 基于GTAZN的10-fold CV准确度实验结果
4 结 论
本文提出了基于降噪自动编码器深度学习音乐特征的自动标注算法,采用无监督的深度学习算法自动地学习特征的潜在结构而不需要依赖先验知识。首先,在提取特征后,采用降噪自动编码器对起始点检测后的特征进行无监督的学习;然后,将学习到的特征进行最大值池化并取均值聚合成词袋形式的特征向量;最后,用预训练后的多层感知机将特征向量映射成对应标签。讨论并分析了池化长度和不同层权值衰减系数对实验结果的影响,调节参数以达到最优。 基于Magnatagatune歌曲库的最优实验结果显示本文算法取得了较高的识别率,其中AUC-T160达到0.881,AUC-C达到0.954,top-K中P3和P6都提高了0.02左右的准确率,AUC-T50达到了0.896 5。 同时为了验证算法的有效性,在GTAZN库上的实验得到了0.885 2的平均准确度,在一定程度上体现了深度学习算法对音乐自动标注的有效性。在之后的研究中,可以尝试采用其他深度学习算法实现音乐自动标注。
[1]HAMEL P,LEMIEUX S,BENGIO Y,etal.Temporal pooling and multiscale learning for automatic annotation and ranking of music audio[C]// International Society for Music Information Retrieval Conference.Miami,Florida,USA :DBLP,2011:729-734.
[2]HAMEL P,BENGIO Y,ECK D.Building musically-relevant audio features through multiple timescale representations[C]// Conference of the International Society for Music Information Retrieval(ISMIR).Porto,Portugal:DBLP,2012:553-558.
[3]BENGIO Y.Learning Deep Architectures for AI [M].USA:Now Publishers Inc.,2009.
[4]WAKAHARA T,YAMASHITA Y.k-NN classification of handwritten characters via accelerated GAT correlation[J].Pattern Recognition,2014,47(3):994-1001.
[5]CHI Y,PORIKLI F.Classification and boosting with multiple collaborative representations[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(8):1519-1531.
[6]PAN Z,YOU X,CHEN H,etal.Generalization performance of magnitude-preserving semi-supervised ranking with graph-based regularization[J].Information Sciences,2013,221:284-296.
[7]LEE H,PHAM P,LARGMAN Y,etal.Unsupervised feature learning for audio classification using convolutional deep belief networks[C]// Advances in Neural Information Processing Systems.British Columbia,Canada:DBLP,2009:1096-1104.
[8]HENAFF M,JARRETT K,KAVUKCUOGLU K,etal.Unsupervised learning of sparse features for scalable audio classification[C]//Conference of the International Society for Music Information Retrieval(ISMIR),Miami,Florida,USA:DBLP,2011:681-686.
[9]WÜLFING J,RIEDMILLER M A.Unsupervised learning of local features for music classification[C]// Conference of the International Society for Music Information Retrieval(ISMIR).Porto,Portugal:DBLP,2012:139-144.
[10]NAM J,HERRERA J,SLANEY M,etal.Learning sparse feature representations for music annotation and retrieval[C]//Conference of the International Society for Music Information Retrieval(ISMIR).Porto,Portugal:DBLP,2012:565-570.
[11]SIGTIA S,DIXON S.Improved music feature learning with deep neural networks[C]//2014 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).USA:IEEE,2014:6959-6963.
[12]VAN DEN OORD A,DIELEMAN S,SCHRAUWEN B.Transfer learning by supervised pre-training for audio-based music classification[C]//Conference of the International Society for Music Information Retrieval.Taipei,China :DBLP,2014:29-34.
[13]DIELEMAN S,SCHRAUWEN B.End-to-end learning for music audio[C]//2014 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).USA:IEEE,2014:6964-6968.
[14]CHOI K,FAZEKAS G,SANDLER M.Automatic tagging using deep convolutional neural networks[EB/OL].[2016-05-10] .https://arxiv.org/abs/1606.00298.
[15]VINCENT P,LAROCHELLE H,BENGIO Y,etal.Extracting and composing robust features with denoising autoencoders[C]//Proceedings of the 25th International Conference on Machine Learning.USA:ACM,2008:1096-1103.
[16]ELLIS D.Time-frequency automatic gain control,Web resource,available[EB/OL].[2010-10-20].http://labrosa.ee.columbia.edu/matlab/tf-agc/.
[17]ZEILER M D.ADADELTA:An adaptive learning rate method[EB/OL].[2012-03-10] .https://arxiv.org/abs/1212.5701.
[18]SRIVASTAVA N,HINTON G E,KRIZHEVSKY A,etal.Dropout:A simple way to prevent neural networks fromoverfitting [J].Journal of Machine Learning Research,2014,15(1):1929-1958.
[19]LAW E,VON AHN L.Input-agreement:A new mechanism for collecting data using human computation games[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.USA:ACM,2009:1197-1206.
[20]STURM B L.The GTZAN dataset:Its contents,its faults,their effects on evaluation,and its future use[EB/OL].[2013-10-11] .https://arxiv.org/abs/1306.1461.
[21]STURM B L.A survey of evaluation in music genre recognition[C]// International Workshop on Adaptive Multimedia Retrieval(AMR).Copenhagen,Denmark:Springer International Publishing,2012:29-66.
[22]BOGDANOV D,PORTER A,HERRERA P,etal.Cross-collection evaluation for music classification tasks[C]// Conference of the International Society for Music Information Retrieval (ISMIR).New York City,USA:DBLP,2016:379-385.
[23]BERGSTRA J,CASAGRANDE N,ERHAN D,etal.Aggregate features and AdaBoost for music classification[J].Machine Learning,2006,65(2/3):473-484.
Feature Learning for Music Auto-Tagging Using Denoising Autoencoder
LI Peng, CHEN Ning
(School of Information Science and Engineering,East China University of Science and Technology,Shanghai 200237,China)
At present,the models used in music auto-tagging are mostly hand-engineered,so the choice of the optimal feature is always difficult.We propose an unsupervised feature learning algorithm,which can automatically learn the underlying structure of feature without prior knowledge.The algorithm is achieved in three stages.The preprocessing stage extracts the chroma-frequency spectrogram,and reduces the dimensionality via PCA whitening.The second stage applies the denoising autoencoder to the reduced feature in an unsupervised manner,and aggregates a new feature vector by max-pooling function and averaging.The last stage maps the feature vector to song labels by pre-trained multilayer perceptron (MLP) in a supervised manner.The result based on the Magnatagatune and GTZAN datasets shows that our algorithm improves the accuracy of music auto-tagging to some degree.
deep learning; music auto-tagging; denoising autoencoder; multilayer perceptron
1006-3080(2017)02-0241-07
10.14135/j.cnki.1006-3080.2017.02.014
2016-09-05
国家自然科学基金(61271349)
黎 鹏(1992-),男,四川人,硕士生,主要研究方向为音频信号处理和机器学习。
陈 宁,E-mail:chenning_750210@163.com
TP391
A
