藏汉跨语言话题模型构建及对齐方法研究
2017-04-25孙媛,赵倩
孙 媛,赵 倩
(1.中央民族大学 信息工程学院,北京 100081;2.国家语言资源监测与研究中心少数民族语言分中心,北京 100081)
藏汉跨语言话题模型构建及对齐方法研究
孙 媛1,2,赵 倩1,2
(1.中央民族大学 信息工程学院,北京 100081;2.国家语言资源监测与研究中心少数民族语言分中心,北京 100081)
如何获取藏文话题在其他语种中的相关信息,对于促进少数民族地区的社会管理科学化水平、维护民族团结和国家统一、构建和谐社会具有重要意义。目前大多数研究集中在英汉跨语言信息处理方面,针对藏汉跨语言研究较少。如何根据藏语、汉语的特点,并结合目前藏语信息处理的研究现状,实现藏汉多角度的社会网络关系关联,同步发现关注话题并进行数据比较,是迫切需要解决的问题。该文在藏汉可比语料的基础上,利用词向量对文本词语进行语义扩展,进而构建LDA话题模型,并利用Gibbs sampling进行模型参数的估计,抽取出藏语和汉语话题。在LDA话题模型生成的文档-话题分布的基础上,提出一种基于余弦相似度、欧氏距离、Hellinger距离和KL距离四种相似度算法的投票方法,来实现藏汉话题的对齐。
藏汉跨语言;话题抽取;LDA;话题对齐
1 引言
我国是一个统一的多民族国家,由56个民族组成,有着丰富的语言资源。随着互联网在少数民族地区的普及,越来越多少数民族民众开始认识网络、利用网络,并通过网络了解外界知识和信息。随着少数民族地区人民网络使用率的飞速增加,少数民族新闻网站每天有大量的新闻发布,巨大的信息量使得人们无法快速、准确地获取有价值的信息。而且,网络信息对民众认识、了解社会起了一定的导向作用,其准确性也会对社会稳定乃至国家政策的制定产生影响。通过跨语言话题抽取和对齐的研究,可以提高各民族不同语言之间的知识共享,增强民族地区网络信息安全,推进民族地区经济文化发展,促进民族团结,为构建“和谐社会”和“科学发展”的社会环境提供重要的条件支撑。藏汉话题抽取和对齐作为藏汉跨语言话题检测与跟踪的基础,对其相关研究起着重要的作用。
本文首先对话题模型的发展进行了研究,分析了LSI和pLSI的不足,并将继承两者优点的LDA模型作为新闻文本表示模型。然后基于藏汉可比语料库来构建藏、汉LDA话题模型,在构建过程中利用词向量对文本词语进行语义扩展,分别抽取出藏语和汉语话题,然后基于相似度计算进行投票,将同一话题的藏语和汉语描述联系起来,实现藏汉话题的对齐,从而构建起跨语言LDA话题模型。
2 相关研究
随着藏文信息处理技术的发展,藏文信息处理无论是在藏字信息处理研究及其相关标准制定方面,还是在藏语信息处理应用开发方面,众多科研人员进行了不懈的努力和有益的探索,并取得了不少成绩。藏文的字处理技术研究是最早的[1-2],也是取得成效较好的。在基本完成以“字”为单位的研究内容后,以“词”、“句”、“段”、“篇”为主的研究也逐步开展起来。藏语分词、词类研究、语料库建设、机器翻译等都取得了一定的进展。但与国内外语言文字信息处理技术的总体发展水平和研究状况相比较,藏文信息处理的相关研究都还只是一些初步的探讨,发展得还不够完善,有待深入研究。
话题(Topic)[3]就是一个核心事件以及与之直接相关的事件。通常情况下,可以简单地认为话题就是对特定事件相关报道的集合,如果新闻报道的内容与某一话题的核心事件相关,那么可以认为此报道与这个话题相关。传统的向量空间模型(Vector Space Model,VSM)使用关键字来表示话题,但偏重于对文档贡献度较大的词语,有时候这些词语中会存在一些有二义性的词,描述文档的效果往往不太理想,为了弥补向量空间模型的这些不足,隐性语义索引(Latent Semantic Indexing,LSI)[4]被提了出来,利用奇异值分解(Singular Value Decomposition,SVD)技术,实现对文本的降维。LSI并不属于概率模型,也算不上一个话题模型,但它是话题模型发展的基础。Hofmann[5]在LSI的基础上提出了概率隐性语义索引(probabilistic Latent Semantic Indexing,pLSI),该模型假设每篇文档是由多个话题组合而成的,文档中的每一个词是由一个话题产生,因此文档中不同的词可以由不同的话题生成。Blei等人[6]又在pLSI的基础上进行了扩展,得到一个更为完全的概率生成模型——隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)。
2.1 LSI话题模型
LSI,又称为潜在语义分析(Latent Semantic Analysis,LSA)。它使用SVD来分解词语—文档矩阵。SVD可以从词语—文档矩阵中发现不相关的索引变量,将原本的数据映射到语义空间。
LSI方法的引入可以减轻一义多词和一词多义的问题。基于SVD分解,我们可以基于原始向量矩阵构造一个低秩逼近矩阵,把原本的向量转化到一个低维隐含语义空间中,实现对特征的降维。奇异值与语义维度的权重相对应,将不太重要的权重置为0,只保留最重要的维度信息,这样可以去掉一些噪音,因此可以得到文档的一种更好的表示方式。
2.2 pLSI话题模型
虽然基于奇异值分解的LSI取得了一定的成效,但是没有严谨的数理统计基础作支撑,并且SVD的分解十分耗时。Hofmann就在此基础上提出了基于概率统计的pLSI模型,用期望最大化算法(Expectation Maximization Algorithm,EM)算法学习模型参数。该模型假定文档d、特征词w、话题z三者间的条件概率相互独立,那么特征词w和文档d之间的关系如式(1)所示。
p(d,w)=p(d)∑p(w|z)p(z|d)
(1)
2.3LDA话题模型
LDA 模型[7-8],也称为三层贝叶斯概率模型,是一种文档话题生成模型,包含词语、话题和文档三层结构。文档到话题服从多项式分布,话题到词也服从多项式分布。由于pLSI模型的参数数量会由于文档数量的增加而线性增加,不能很好地预测没有观测到的文本。LDA克服了这些缺点并继承了pLSI的所有优点,可以很好地产生话题分布,而且参数的数量不会随文档数量的增加而线性增加。
LDA是一种无监督的机器学习方法[9-10],用来识别大规模文档集或语料库中隐藏的话题信息。它采用词袋的方法,将每一篇文档视为一个用词频表示的向量,从而将文本信息转化为计算机可以处理的数字信息。词袋的方法忽略了词的先后顺序,使问题的处理变得简单。
3 藏汉LDA话题模型的构建
3.1 模型构建过程
LDA生成过程可以如图1所示。

图1 LDA话题模型
虽然LDA模型采用的词袋的方法简化了问题的复杂度,但同时也带了一个问题。词袋方法认为,一个文档中的所有的词是等价的,并没有重要性的区分。而在现实中,不同的词对一篇新闻文档的贡献程度有时也是不同的。例如,位于标题的词比位于正文中的词要重要,名词比修饰词的贡献度要强。基于这种考虑,我们在进行文档输入的时候,加入了词性选择和位置重要性,根据词性和位置对输入的词进行筛选。在词性选择方面,我们认为名词、动词以及包括人名、地名、组织机构名在内的命名实体对一个话题的标识性更强。对于位置的影响,我们按照新闻文本中词语出现的位置来说,分为三类:在标题和正文中都存在的词、只存在于标题中的词和只存在于正文中的词。对网络新闻来说,标题具有举足轻重的作用,因此标题中的词应有较高的权重,所以这三类词的权重依次降低。
通过语料库训练,按照式(2)计算得到每个词的IDF值,根据式(3)中词的位置不同赋予不同的重要性,得到新的权重IDF′。
(2)
D为语料中的文档总数,Di为包含词语i的文档数。

(3)
3.2 词向量
我们采用词向量对文本关键词进行语义扩展,利用跨语言文本相似度匹配藏语和汉语文本,从而获得藏汉可比资料。
1.词向量训练的过程
(1) 从训练文件读入词汇;
(2) 统计词频,初始化词向量,放入哈希表中;
(3) 构建哈夫曼树,得到每个词汇的哈夫曼树中的路径;
(4) 从训练文件读入一行语句,去除停用词,获得该行语句中每一个中心词的上下文,词向量求和Xw。获得中心词的路径,使用路径上所有节点的目标函数对Xw的偏导数的和优化中心词词向量;
(5) 统计已训练词汇数目,大于10 000时更新学习率;
(6) 保存词向量。
2.词语语义距离
当计算词语语义的距离时,首先需要加载存储词向量的二进制文件。将文件中词向量读入到哈希表中。在加载过程中,为了后续词义距离计算的方便,对词语的每个向量做了除以它向量长度的计算,如式(4)所示。
(4)
获得训练语料词语的词向量之后,采用余弦值法计算词语与词语之间的语义距离。假设词语A的向量表示为(Va1,Va2,…,Van),词语B的向量表示为(Vb1,Vb2,…,Vbn),则词语A和词语B的语义计算如式(5)所示。
(5)
之前已经完成了对向量距离的除运算,所以上述公式的计算转化如式(6)所示。
(6)
3.3 参数估计
本文采用吉布斯抽样法[11-12](Gibbs sampling)对LDA模型进行参数估计。Gibbs sampling是马尔科夫链蒙特卡洛(Markov-Chain Monte Carlo,MCMC)算法的一种简单实现,主要思想是构造出收敛于目标概率分布函数的马尔科夫链,并且从中抽取最接近目标概率的样本。利用Gibbs sampling对LDA模型进行参数估计的过程[13-14]如图2所示。
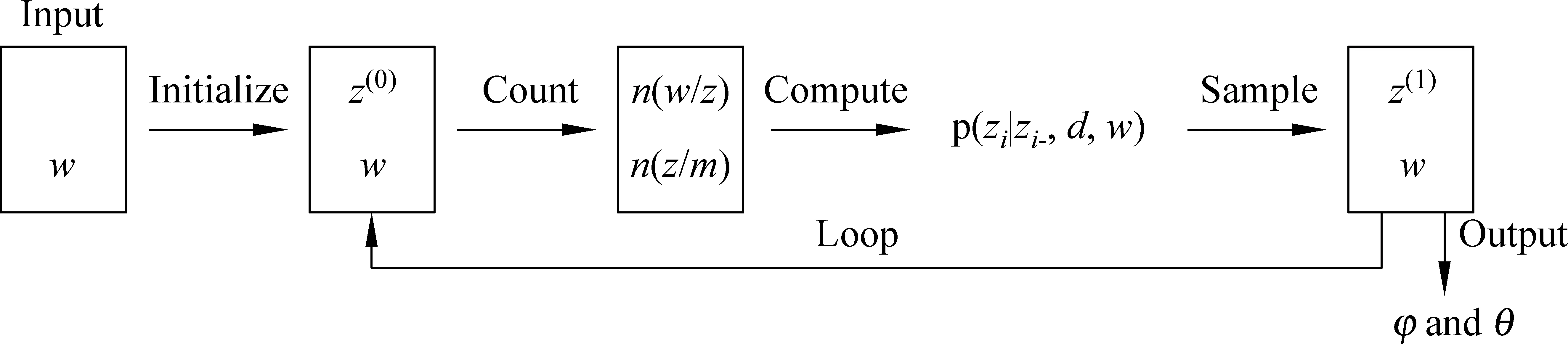
图2 Gibbs sampling 进行LDA参数估计的过程
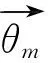
事先人为设置迭代次数,参数α和β通常分别设为50/K、0.01。根据式(7)训练产生话题—词汇分布φk,v,即出现在话题k中的词语v的概率。
(7)
针对文档集中每篇文档,根据式(8)计算文档的文档—话题分布θm,k,即文档m中话题k所占的概率。
(8)
4 藏汉话题对齐
在构建出LDA话题模型后,在生成的话题—文档概率分布中,每一个话题在每一篇文档中都会以一定的概率出现。因此,对每个话题来说,可以表示成文档上的空间向量。通过向量之间的相似度来衡量藏汉话题的相关性,将藏汉话题对齐。话题对齐的过程如图3所示。

图3 藏汉话题对齐过程
此算法不需要藏汉词典,也不需要机器翻译,只需要我们之前已经建立起的可比语料库。
对于藏语话题ti和汉语话题tj,计算两者的相关性的步骤如下:
(1) 将事先已经构建出的m对藏汉可比新闻文档,作为概念空间索引文档集;
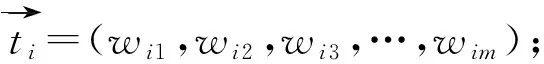

a.余弦相似度,利用向量的余弦夹角来计算相似度,余弦值越大,相关性越大,如式(9)所示。
(9)
b.欧氏距离,用来描述空间中两个点的常规距离。计算的值越小,两点之间的距离就越近,相似度就越大,如式(10)所示。
(10)
c.Hellinger距离,度量两个分布之间差异的一种方法。由于话题可以表示成离散的概率分布,因此,Hellinger距离可以用来计算话题之间的相似度。计算值越大,话题之间的差异度就越大,相似度就越小;计算值越小,话题之间的相似度就越大,如式(1)所示。
(11)
DKL(P||Q)=P*log(P/Q)
(12)
Q到P的KL距离如式(13)所示。
DKL(Q||P)=Q*log(Q/P)
(13)
KL距离是非对称的,而事实上,藏语话题ti到汉语话题tj的距离与tj到ti的距离是相等的。因此,我们使用对称的KL距离来计算话题的距离,如式(14)所示。
(14)
将式(14)代入,得到式(15) 。
(15)
整理得到式(16)。
(16)
(5) 比较上述四种常用方法并尝试将四种方法结合起来来观察效果,我们基于以上四种方法对结果进行投票,第n种方法methodn在藏语话题ti上对汉语话题tj的投票值为1或者0,记为Vote(methodn,ti,tj)∈{1,0},当投票结果Votes(ti,tj)≥3时为有效投票;否则,为无效投票。当投票无效时,投票方法一以余弦计算的结果为最终的投票结果,投票方法二将Hellinger距离作为最终结果,两种方法进行对比,选择合适的计算方法。
5 实验结果及分析
5.1 词向量扩展实验
1.实验数据来源
利用网络爬虫,从有藏汉双语链接的新闻网站爬取语料。具体网站网址如表1所示,语料统计信息如表2所示。

表1 藏汉双语网站

表2 语料统计信息
2.根据Word2Vec扩展关键词
利用获得的语料,训练出词向量。总计训练出365 428个汉语词的词向量,382 022个藏语词的词向量。对于每篇文本,计算每个词词义距离最近的三个词,加入到文本表示中。每次计算的词义距离都保存下来,避免之后进行重复计算。汉语词义扩展示例如表3所示,藏语词义扩展示例如表4所示。

表3 汉语词义扩展

表4 藏语词义扩展
5.2 藏汉LDA话题模型构建实验
本文采用java编程来构建LDA话题模型,主要包括四个阶段:文档输入、话题建模、话题预测、话题输出。
在话题建模之前,我们要事先设置好先验参数,以便于后续的话题预测。
(1) 话题数量K:通过经验,人工设置找到合适的值;
(2) 迭代次数:本文设为800;
(3)α:默认设为50/K;
(4)β:通常设为0.01;
(5) 话题词的数量:设为20。
话题模型构建训练语料是从中国西藏新闻网汉语版和藏语版下载的语料,得到132篇藏汉可比新闻文本对。将训练语料中的文本进行分词标注、去除停用词,通过调试,选择出合适的话题数量。通过实验获得汉语话题70个,藏语话题65个。对每个话题类选取概率最大的二十个词语来展现该话题。我们从藏语话题出发,寻找与藏语话题相对应的汉语话题,实现藏汉话题的对齐,由此建立起跨语言LDA话题模型。
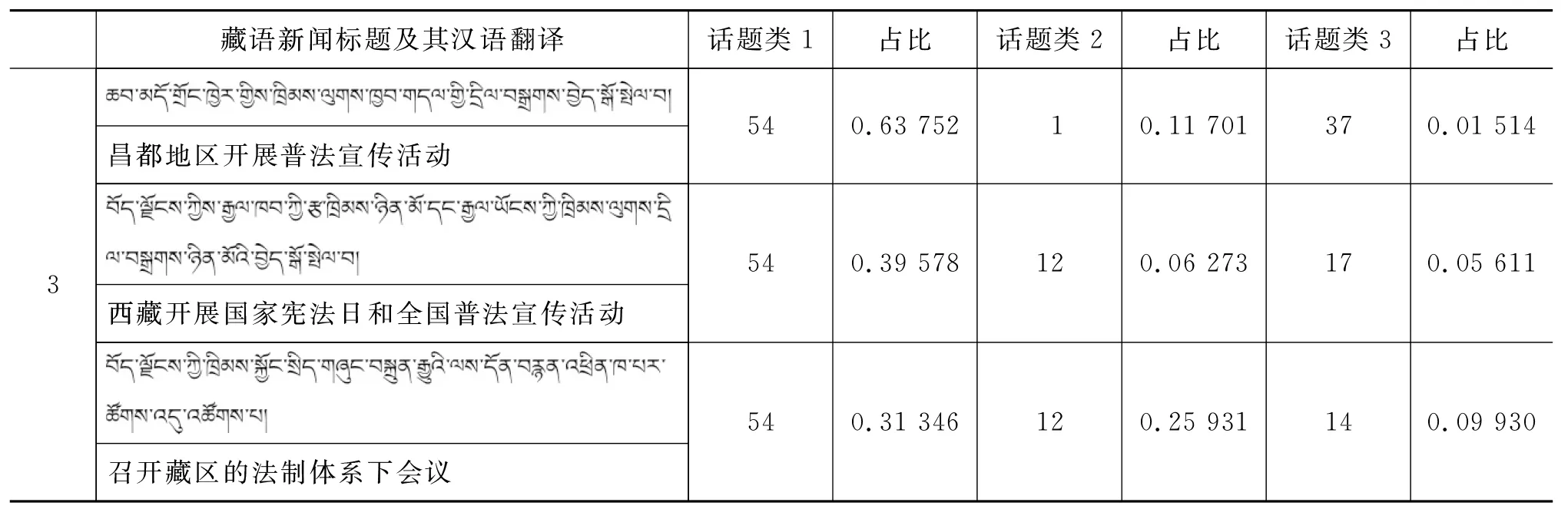
我们从训练集中随机抽取出新闻文本,来检验话题模型的同话题聚类效果,列出这些新闻文本的主要话题分布(按照比重选取前三个话题),如表5和表6所示,分别列出了汉语和藏语同话题新闻聚类。
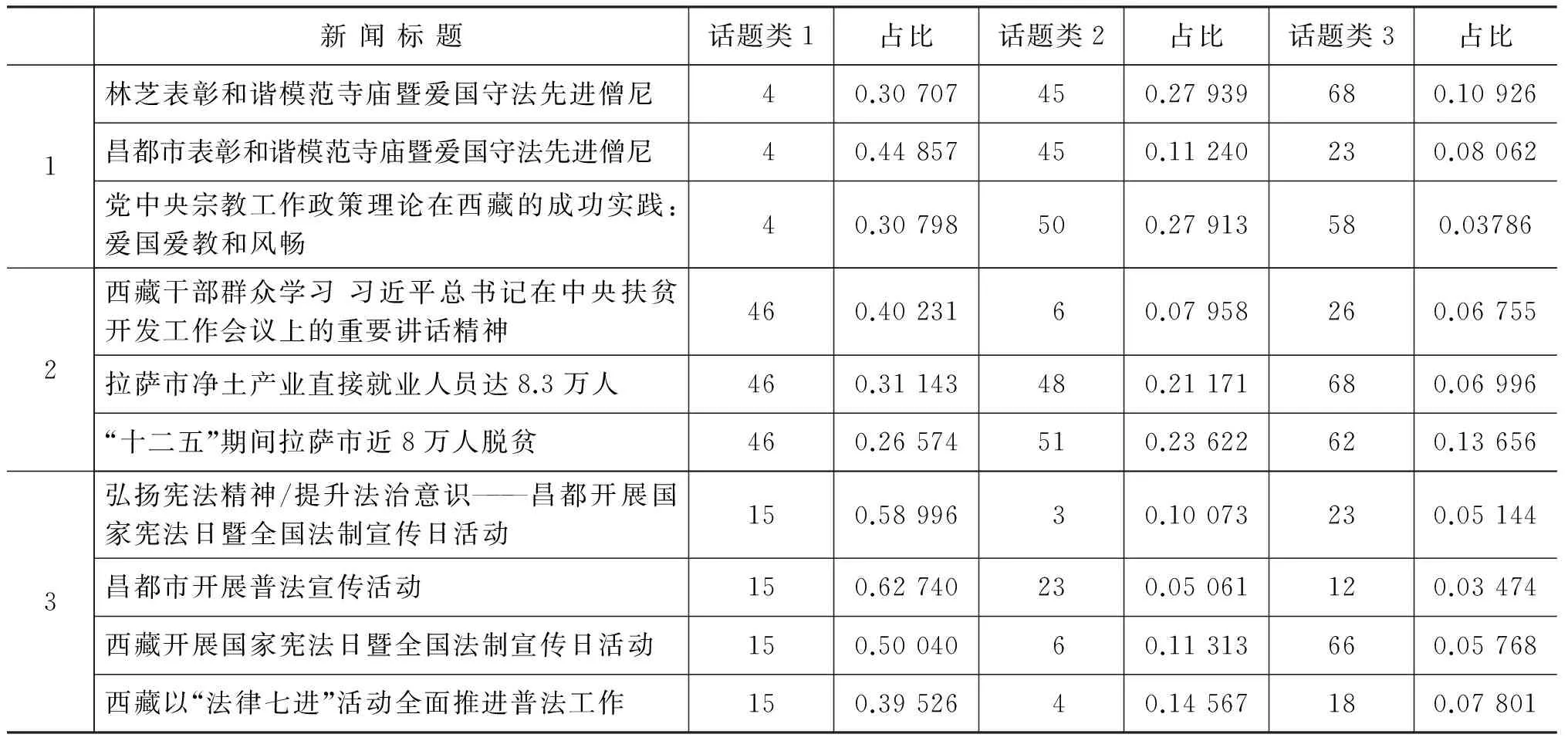
表5 汉语新闻报道中同话题新闻聚类
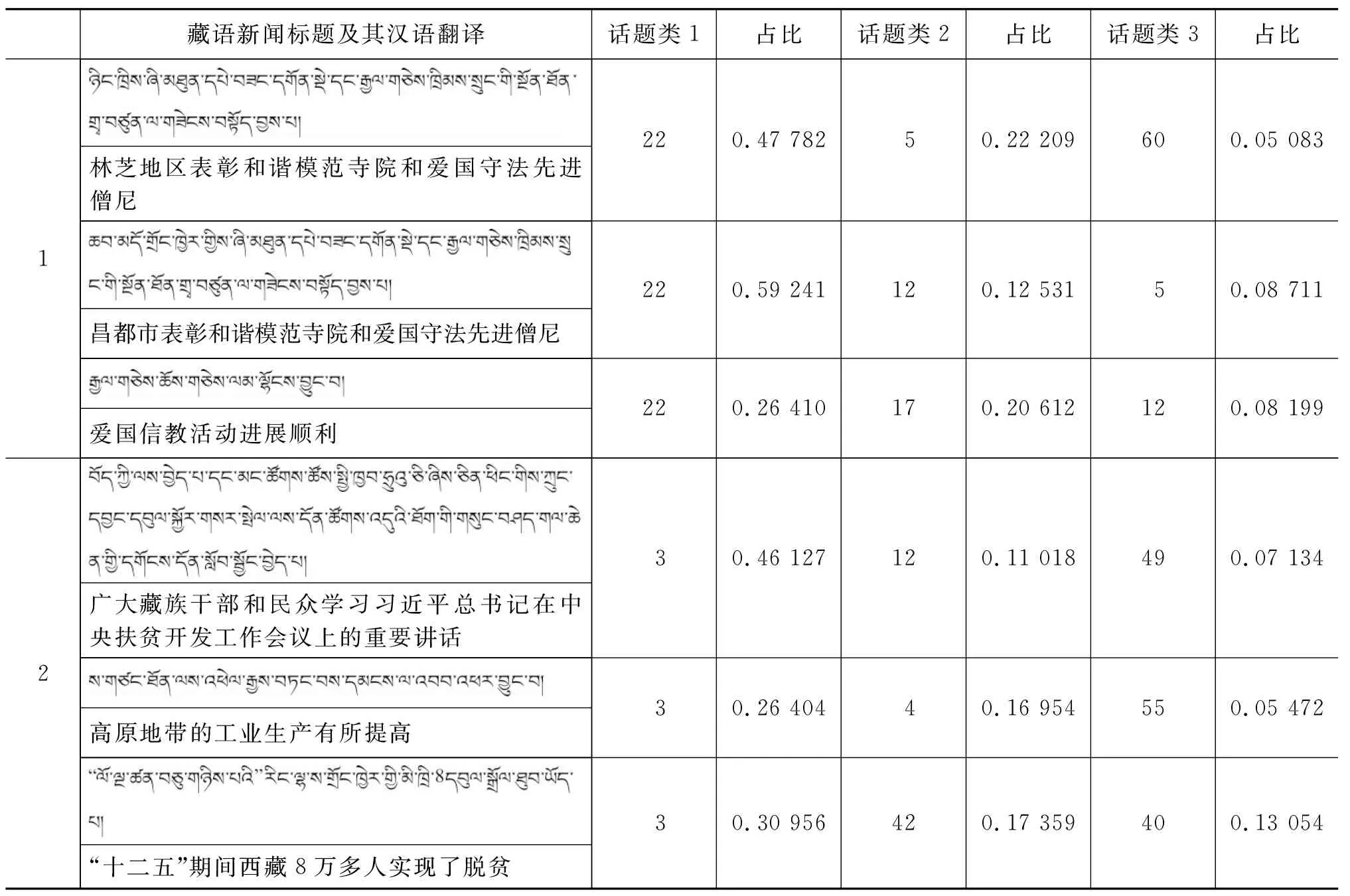
表6 藏语新闻报道中同话题新闻聚类
续表
由表5和表6可以看出,具有相似报道内容的新闻文本被聚集在一个话题类中,接下来要进行话题的对齐,话题对齐之后能够将有关于同一话题的藏语和汉语新闻报道联系起来。
5.2 话题对齐实验
抽取出藏语话题和汉语话题之后,需要进行藏汉话题的对齐。将话题映射到文档概念空间,计算藏语话题和汉语话题的相似度,四种方法以及投票方法实验结果的准确率如表7所示。

表7 多种方法准确率比较

图4 各方法准确率比较柱状图/%
由表7和图4可以看出,在余弦距离、欧式距离、Hellinger距离和KL距离四种相似度计算算法中,余弦距离和Hellinger距离在本文的工作中较有优势,因此在投票过程中,当产生无效投票时,考虑分别将余弦距离和Hellinger距离作为最终的投票结果,并将这两种投票方法进行比较。从实验结果可以看出,投票无效时将余弦距离作为最终投票结果的方法即投票1有较好的效果。投票过程示例如表8所示。
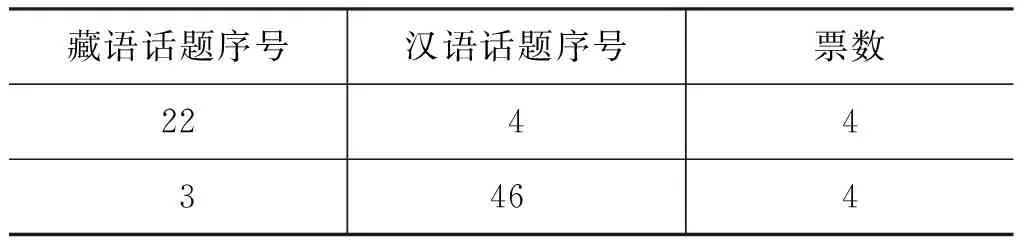
表8 话题对齐票数
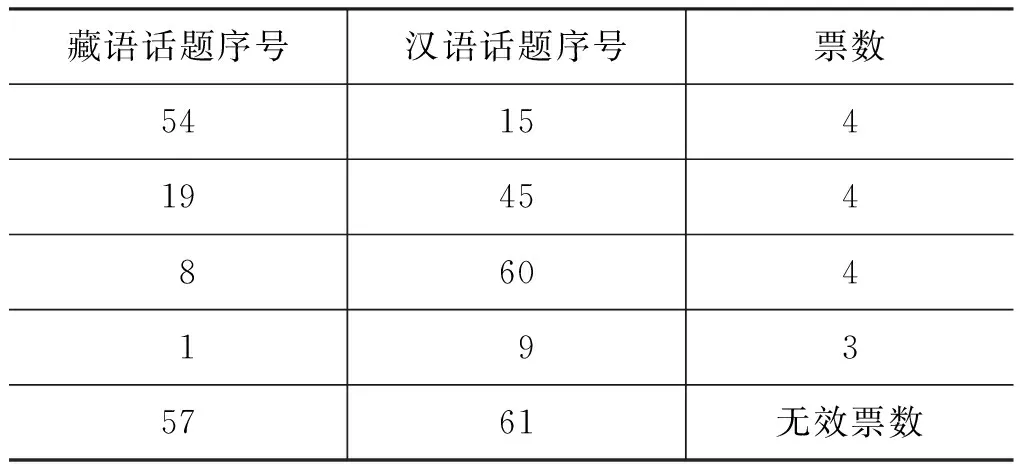
续表
以表8中数据为例,每种方法对藏语话题22在汉语话题4上都投出了一票,表明对于藏语话题22与汉语话题4对齐,四种方法都表示赞成。四种方法中有三种方法对藏语话题1和汉语话题9对齐投出了赞成票。少于三种方法对藏语话题57与汉语话题61对齐表示赞成,因此,这时依据余弦相似度的计算结果,作为最终的投票结果。对齐的藏汉话题示例如表9所示。
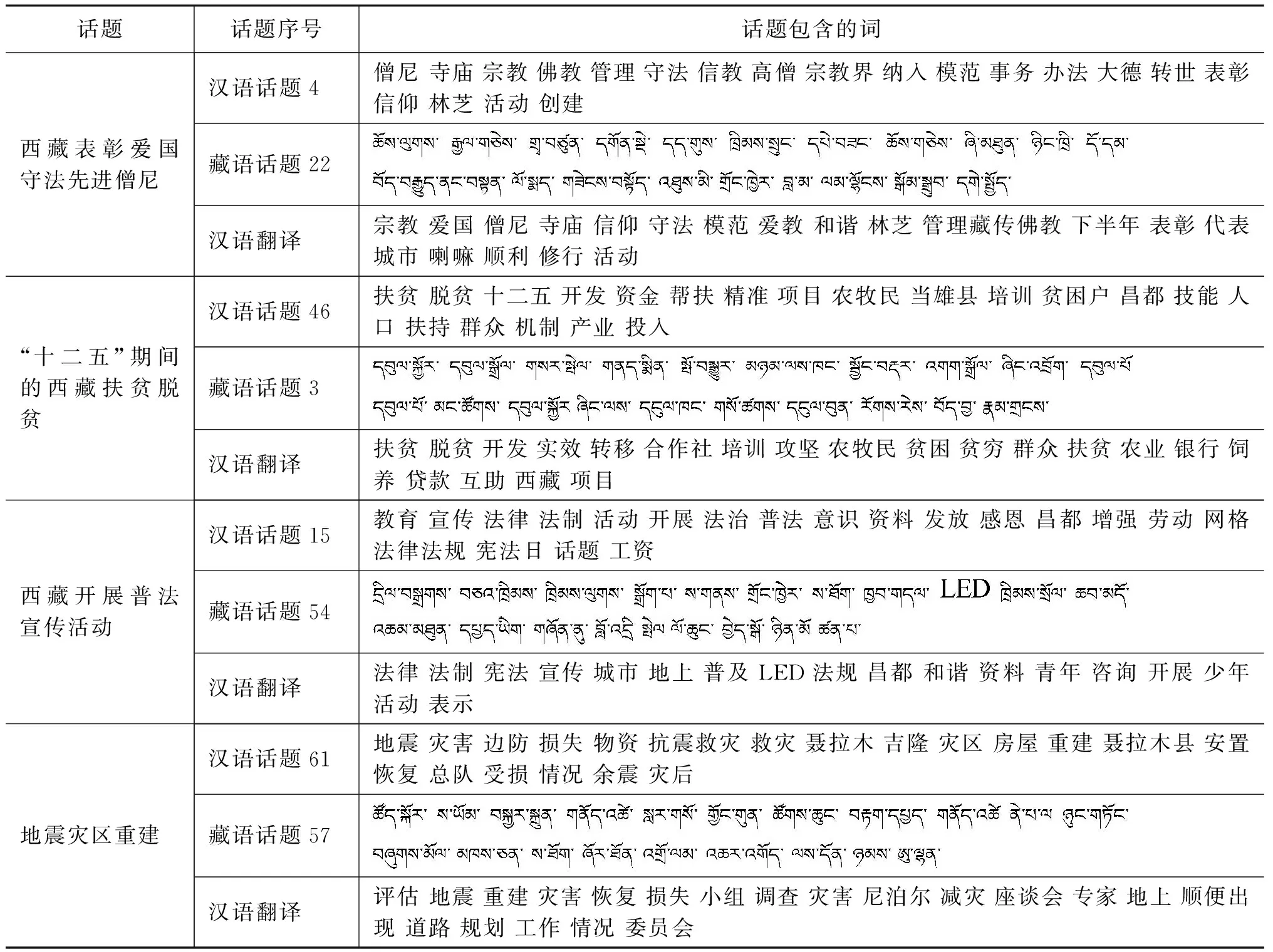
表9 藏汉对齐话题列表
由表9可以看出,通过话题对齐,描述同一话题的藏语和汉语基本能够对应。但由于相比于汉语的分词,藏语分词在准确度和效果上还是有所欠缺,因此,对于同一话题的藏语和汉语描述词只是大致能够对应上,还不能准确到具体的每一个词。
6 结论与展望
伴随互联网的飞速发展和广泛应用,人类步入网络时代,互联网成了人们获取信息的主要途径。跨语言话题抽取和对齐可以帮助人们从杂乱无章的网络信息中快速地获取到所需的关键信息,并且可以了解不同语种的相关信息。本文在可比语料的基础上构建出LDA话题模型,分别抽取出藏语和汉语话题,并提出了一种基于投票机制的话题对齐方法,该方法跨越了语言的障碍,能够很好地实现不同语言同话题的聚集。
本文也存在一些不足:
1.用于实验的新闻语料规模还不够大,后续将会扩大语料库规模,并在此基础上对提出的方法进行完善;
2.相比于汉语分词,藏语分词准确率还有待提高,分词的准确性对计算的效果有着至关重要的作用,这也是进行后续研究的基础;
3.词向量训练语料的好坏直接影响到语义距离的计算,相比于汉语,由于网络上藏语语料环境的复杂性和藏语语料的缺乏,常常会导致藏语词向量使用效果不佳,今后,需要寻求相对规范化的藏语语料,并对藏语词向量训练语料规模进行扩大。
[1] 高定国,关白.回顾藏文信息处理技术的发展[J].西藏大学学报:社会科学版,2009(3):18-27.
[2] 何明华.当代藏文信息处理的现状与展望[J].科技资讯,2014,12(23):249-249.
[3] J Allan,J Carbonell,G Doddington,et al.Topic Detection and Tracking Pilot Study:Final Report[C]//Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop,Virginia:Lansdowne,1998:194-218.
[4] Deerwester S C,Dumais S T,Landauer T K,et al.Indexing by latent semantic analysis[J].JASIS,1990,41(6):391-407.
[5] Hofmann T.Probabilistic latent semantic indexing[C]//Proceedings of SIGIR.ACM,1999:50-57.
[6] Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].The Journal of machine learning research,2003(3):993-1022.
[7] Connell M,Feng A,Kumaran G,et al.UMass at TDT 2004[C]//Proceedings of the Topic Detection and Tracking Workshop Report.2004.
[8] Allan J,Papka R,Lavrenko V.On-line New Event Detection and Tracking[C]//Proceedings of SIGIR,1998:37-45.
[9] 洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):71-87.
[10] Yang Y,Pierce T,Carbonell J.A Study of Retrospective and On-line Event Detection[C]//Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval.ACM,1998:28-36.
[11] Wei X,Croft W B.LDA-based document models for ad-hoc retrieval[C]//Proceedings of the SIGIR.ACM,2006:178-185.
[12] 徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[13] 陆前.英、汉跨语言话题检测与跟踪技术研究[D].中央民族大学博士学位论文,2013.
[14] 石杰.中泰跨语言话题检测方法与技术研究[D].昆明理工大学硕士学位论文,2015.
Research on the Extraction and Alignment of Tibetan-Chinese Cross-language Topics
SUN Yuan1,2,ZHAO Qian1,2
(1.School of Information Engineering,Minzu University of China,Beijing,100081,China;2.Minority Languages Branch,National Language Resource and Monitoring Research Center,Beijing,100081,China)
In contrast to the,To discover synchronication topics associated in Tibetan and Chinese social networking,we build LDA topic model on the basis of Tibetan-Chinese comparable corpus,with word2vec as the input and Gibbs sampling to estimate model parameters.To align Tibetan topics and Chinese topics,we calculate the similarity between Tibetan and Chinese topics according to the distribution of text-topic disctrbution via a voting method based on cosine distance,Euclidean distance,Hellinger distance and KL distance.
topic extraction; LDA model; topic alignment

孙媛(1979—),博士,副教授,硕士生导师,主要研究领域为自然语言处理和知识工程。E-mail:173701102@qq.com赵倩(1990—),硕士研究生,主要研究领域为自然语言处理。E-mail:393984725@qq.com
1003-0077(2017)01-0102-10
2016-05-18 定稿日期:2016-08-05
国家自然科学基金(61501529,61331013);国家语委项目(ZDI125-36,YB125-139)
TP391
A
