基于用户行为特征的动态权重混合推荐算法
2017-04-24刘沛文陈华锋
刘沛文 陈华锋
(武汉大学国家多媒体软件工程技术研究中心 湖北 武汉 430072)(武汉大学计算机学院 湖北 武汉 430072)
基于用户行为特征的动态权重混合推荐算法
刘沛文 陈华锋
(武汉大学国家多媒体软件工程技术研究中心 湖北 武汉 430072)(武汉大学计算机学院 湖北 武汉 430072)
推荐系统可以为不同的用户定制个性化的网络服务,如何提供准确的推荐则成为其最大难点。针对传统推荐算法的稀疏性问题,提出基于用户行为特征的动态权重混合推荐算法。通过对数据集中的数据进行预处理,计算出不同用户对于不同物品的个性化行为特征指数,并将其引入相似度的计算中。依据用户评分数据稀疏性的差异计算出动态权重,并依此将基于用户内容的推荐和协同过滤推荐进行动态混合。实验结果表明,该算法在稀疏数据集中能有效降低推荐误差,提高推荐精度。
行为特征 动态权重 混合推荐算法
0 引 言
为了能够提供更好的产品设计和用户服务,电子商务和社交网络始终致力于提高对用户兴趣的理解和预测。2013年下半年,Twitter通过监测用户关注和转发等操作,设计了一个向个人推荐推文和账户的新功能。推荐系统开始大范围的应用于Amazon、Netflix和LinkedIn等网站。
在推荐系统中,推荐算法是其核心。传统的推荐算法主要包括基于内容的过滤算法CBF(Content-based Filtering)、协同过滤算法CF(Collaborative Filtering)和混合过滤算法HR(Hybrid Recommendation)等[1]。
基于内容的过滤算法使用对象的自身信息来进行推荐,核心思想是针对待推荐的目标用户,其将来很可能对与该用户相似的用户以往感兴趣的物品或在内容上与该用户以往感兴趣的物品相似的物品仍然感兴趣[2]。针对算法的计算对象,基于内容的推荐算法可分为基于用户内容的过滤算法和基于项目内容的过滤算法[3]。两种算法分别从用户和物品的角度,分析目标用户或物品与其他用户或物品之间因自身内容或属性的不同所存在的内在联系,例如用户资料、物品描述等,利用相似度计算公式计算用户或物品间的相似程度,最终加权计算出推荐预测值,并按预测值的大小来决定目标用户的推荐物品。
协同过滤算法分为两种,基于用户的协同过滤算法UBCF(User-based Collaborative Filtering)和基于项目的协同过滤算法IBCF(Item-based Collaborative Filtering)[4],其依据用户对物品的历史评分,分别计算用户或物品间的相似度,找到与目标用户或目标物品相似的对象,并根据相似对象的历史评分信息计算目标用户对目标物品的推荐预测值,以此来进行推荐。
混合过滤算法是将上述提到了多种推荐算法进行不同方式的融合,进而衍生出的一种推荐算法[5]。大多是引入一个平衡因子,通过线性公式将推荐算法进行混合,并通过在特定测试数据集上对特定用户的反复实验来确定平衡因子的值。
虽然以上推荐算法在目前的推荐系统中已经得到了较为广泛的应用,但还存在以下几个问题:
(1) 推荐效果强烈依赖于用户和项目的历史数据,受数据集稀疏性的干扰[6];
(2) 传统的混合推荐算法不能灵活感知用户在不同时期、不同用户所产生的动态的个性化偏好[7];
(3) 在实际应用中,混合推荐的固定权重不能适应数据集中不同用户数据稀疏性的个性化差异。
针对上述问题,本文提出一种基于用户行为特征的动态权重混合推荐算法DWHR(Dynamic-Weighted Hybrid Recommendation),其核心思想是根据用户在不同的时期所产生的行为操作,例如评分、浏览记录等,自适应地将多种推荐算法进行动态加权,预测用户对于该物品的喜好程度。在MovieLens公共电影评分数据集上的实验结果表明,该算法可以针对不同用户的个性化差异,有效提高在稀疏数据集下的推荐精度。
1 本文提出的算法
1.1 相关定义
1.1.1 评分矩阵
在推荐系统中,定义U={u1,u2,…,um}为系统中所有m个用户的集合,I={i1,i2,…,in}为所有n个项目的集合。则评分矩阵R[m×n]可用表1表示。其中,用户i对项目j的评分表示为rij。若rij=0,则表示用户i对项目j未进行评分。另外,针对MovieLens数据集,定义X={x1,x2,…,x19}为所有19种电影类型,而每种电影类型中又包含了多部电影,即xa={ii},ii∈I,xa∈X。
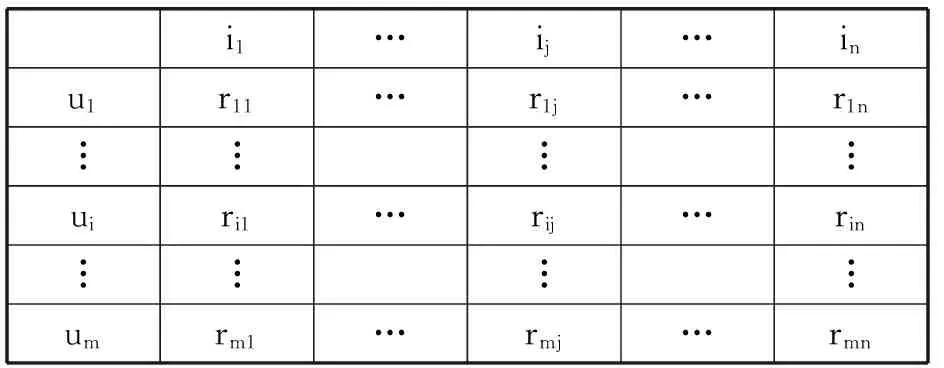
表1 评分矩阵R[m×n]
1.1.2 相似度定义
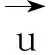
(1)
(2)
(3)
(4)其中,T={i|ui≠0∧vi≠0}。从以上公式中可以看出,相对于余弦相似度和皮尔逊相似度,欧氏距离强调在向量中每个维度在数值特征上的绝对差异;而余弦相似度关注的是向量每个维度间的相对差异;修正余弦相似度在余弦相似度的基础上,修正了其可能在度量标准上存在的不统一的问题;而皮尔逊相似度进一步将向量的计算维度缩小至两向量共有数据的维度上。
针对MovieLens数据集,评分矩阵可以被看作是针对用户的n维或是针对项目的m维向量,然后根据上述公式即可针对不同情况计算出用户或物品之间的相似度。
1.1.3 用户行为特征定义及提取
一些早期的推荐模型常常假定用户的兴趣爱好是固定的,以至于在任何情况下系统总是推荐同一类型的项目给用户。但事实上,用户的兴趣经常随着时间及周围环境的影响而改变。比如,用户在不同的季节或不同的年龄段喜欢穿不同款式的衣服,看不同类型的电影等。所以,行为特征是用户由外界环境影响所引发的一系列行为表现。
为了量化行为特征,选取MovieLens数据集中用户在不同时间和不同年龄段对不同类型电影的评分情况作为量化指标。在通常情况下,用户如果喜欢一部电影,其评分往往会高于均分。由于MovieLens数据集的评分范围是1~5,因此定义3分为用户的评分喜好点,即如果用户对一部电影的评分大于等于3分,则说明用户是喜欢此部电影的。本文定义时间特征指数monthlike(m,xa)为用户在m月对xa类型电影的喜好程度;年龄特征指数agelike(i,xa)为用户i所在的年龄段xa类型电影的喜好程度,其中年龄段依据数据集中的标示进行划分。二者的计算公式如下:
(5)
(6)
其中,Lm,xa表示用户在m月中喜欢xa类型电影的评分数据集合,Li,xa表示用户i所对应的年龄段喜欢xa类型电影的评分数据集合,Lxa表示评分数据中所有喜欢xa类型电影的评分集合。
依据上述公式对MovieLens数据集中的数据进行预处理,计算出每个月份和每个年龄段的用户对不同类型电影的特征指数,结果如图1和图2所示。从图1可看出,用户随着其年龄的增长,观看电影的数量总体上呈先上升再下降的趋势。而针对不同的年龄段的用户,其对不同类型的电影也有着较为明显的区别,例如25岁以下的用户最喜爱动画片,而25~45岁的用户喜欢纪录片的居多。从图2可看出,用户在8月和11月最喜欢看电影。而在1月用户最喜欢看纪录片,在8月喜欢看恐怖片,最不喜欢看纪录片。
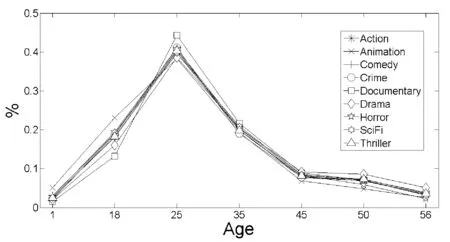
图1 不同年龄段对不同类型电影的喜好程度
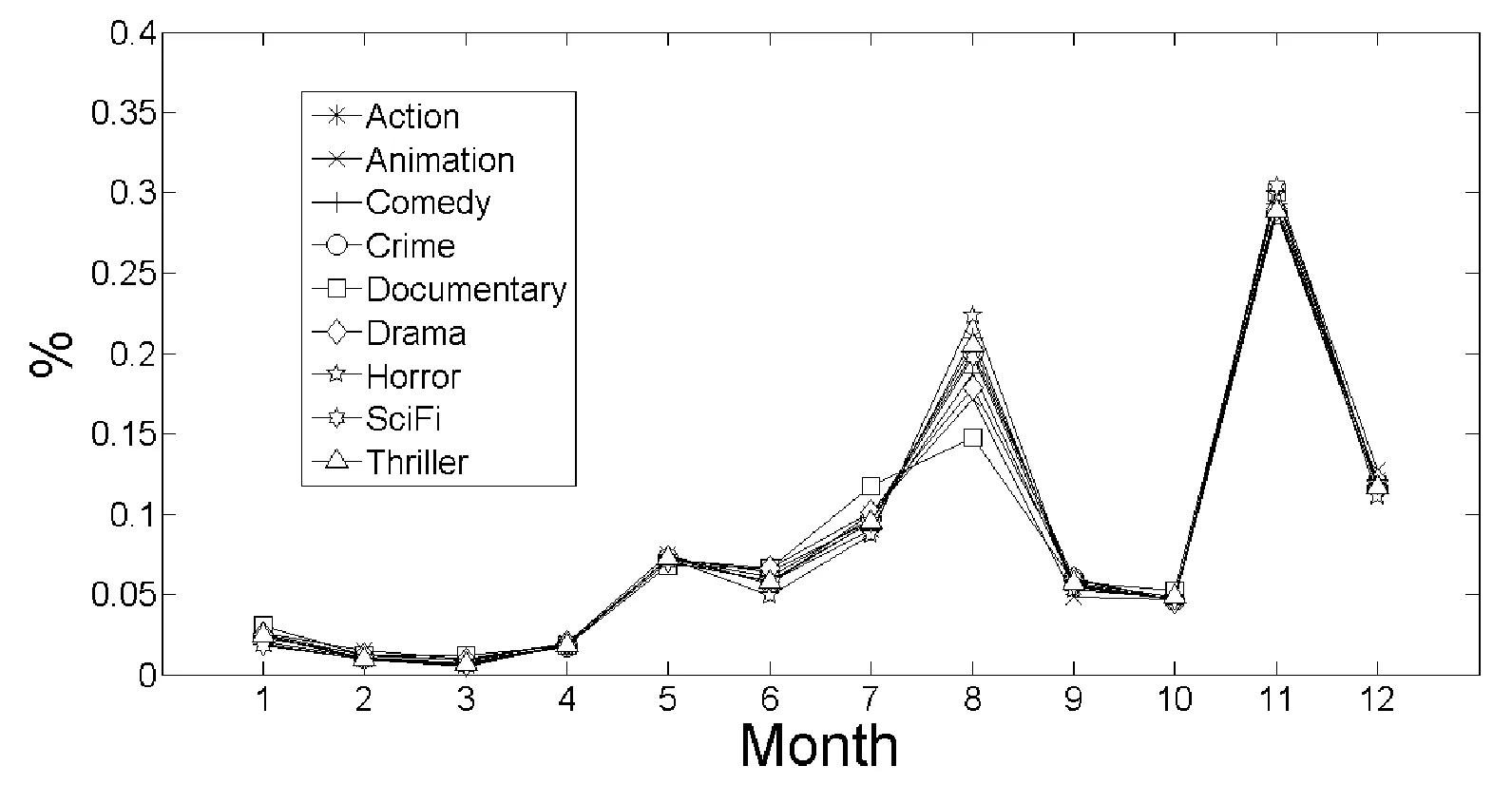
图2 不同时间段对不同类型电影的喜好程度
因此,行为特征指数越大,则此用户所代表的这类人对该类型的电影越感兴趣,则其喜欢对应类型电影的可能性越大。
1.1.4 动态权重
当一个新用户或新项目进入到系统中时,其必然会面对“冷启动”问题[8-10]。在这种情况下,推荐系统无法利用协同过滤等基于历史数据的推荐算法进行推荐,只有利用基于内容的过滤算法,根据用户或项目自身特定的属性和信息来进行粗粒推荐;而当用户和项目的历史数据积累到一定数量之后,基于内容的过滤算法过于粗糙的弊端暴露,协同过滤算法依据历史数据精确推荐的优势逐渐突出。所以,混合推荐将两种算法进行不同方式的融合,目的在于使单一的推荐算法在不同使用场景中能够扬长避短,提升推荐精度。
传统的混合推荐算法大多引入一个平衡因子,通过线性公式将两种或多种推荐算法混合而来[11-14]。其中,平衡因子的取值往往需要在特定的测试数据集上反复实验,才能找到一个特定的值,来达到最好的推荐效果。然而,在实际应用中,由于项目数量远大于用户数量[15],评分数据矩阵对总体而言十分稀疏,但对于不同的用户和项目个体来说其稀疏性差别巨大。所以,固定权重值的混合推荐算法只能针对特定的数据集在宏观上平衡每个个体的推荐误差,不能很好地满足用户的个性差异。
为了解决上述问题,针对不同用户评分数据稀疏性的个性化差异,将用户已评分的物品数量占物品集总数量的比值作为动态权重平衡因子引入进混合推荐中,即依据用户评分的多少来动态决定权重大小,以此来动态平衡混合推荐算法中两种推荐算法所占比重,提出如下计算公式:
(7)
其中,λ为引入的线性因子,用来控制在一定物品数量下已评分物品数据量的线性增长快慢对动态权重影响的大小;Tr为用户i已评分的项目集合,即Tr={r|rij≠0,1≤j≤n},I表示物品集。
1.2 基于用户行为特征的动态权重混合推荐算法
基于用户行为特征的动态权重混合推荐算法主要分为基于内容的过滤算法和协同过滤两大部分。
首先是基于内容过滤算法部分的计算。由上文可知,基于内容的过滤算法分为基于用户和项目两种。但由于用户社会网络信息的丰富程度远高于物品,所以基于用户内容的推荐计算维度更广,精确度更高。另一方面,在大部分数据集中,物品数量极大于用户数量,且物品增长速度远高于用户增长速度,所以基于用户内容信息推荐的计算复杂度远低于基于项目信息内容过滤算法。因此,基于内容的过滤算法部分采用基于用户内容的推荐算法进行计算,可分为以下3个步骤:
1) 计算用户内容相似度并组成相似用户数据集
2) 计算用户行为特征指数
确定待推荐电影j的电影类型为xj,并遍历用户集Ua中每一个用户和其看过的所有xj类型的电影,根据式(5)、式(6)分别计算出其对应的时间特征指数monthlike(m,xj)和年龄特征指数agelike(i,xj)。
3) 计算基于用户内容推荐预测值
利用加权平均公式,计算出相似用户对同类型电影的评分和其特征指数的基于用户内容推荐的预测值,即:
PDBR(i,j)=
(8)
其中Ui表示用户i的基于用户内容推荐的相邻用户集,xj表示与电影j相同类型的电影集合,rbk表示用户b对电影k的评分。
其次进行协同过滤部分的算法计算。由于物品数量极大于用户数量,所以计算物品之间相似度的准确性会大大优于计算用户之间的。因此,协同过滤部分的算法采用基于项目的协同过滤算法。正如上文所述,基于评分矩阵计算相似度更加关注两个向量在不同维度之间的相对差异。并且,在评分向量单个维度数据稀疏的情况下,皮尔逊相似度可以有效规避向量之间因线性独立所带来的计算误差。因此本文采用皮尔逊相似度作为用户相似度计算的主要方法,相似度计算公式可由式(4)转变为:
PCC(i,j) =simPCC(i,j)
(9)
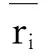
因此,协同过滤部分的算法概括为以下2个步骤:
1) 计算物品之间的相似度并组成相似物品数据集
根据式(9)计算出待推荐物品i与任意其他物品j之间的相似度集合SPCC。将SPCC中的相似度按大小进行降序排列,并选取前θ个组成相邻物品数据集IPCC。
2) 计算协同过滤预测值
针对目标用户,利用IPCC中相似物品的评分数据进行加权,计算出目标用户i对于待推荐物品j的基于项目的协同过滤的加权预测值,即:
(10)
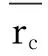
最后,利用式(7)计算出的动态权重,将上述基于用户内容的推荐和协同过滤的推荐算法分别计算出来的预测值进行线性组合,计算出本文提出的基于用户行为特征的动态权重混合推荐算法的预测结果,即:
P(i,j)=DynamicWeight(i)·PPCC(i,j)+
(1-DynamicWeight(i))PDBR(i,j)
(11)
2 数据实验及结果分析
2.1 实验设计

实验采用平均绝对误差MAN(MeanAbsoluteDifference)作为衡量算法准确性的标准,其通过统计算法计算出来的预测评分与用户的实际评分之间的绝对距离的均值来实现精确性的度量。介于MAE的计算和实现都非常简单,所以其已经成为绝大多数文献中使用的标准[2]。对于n个用户的实际评分R={r1,r2,…,rn},推荐算法计算出的预测评分P={p1,p2,…,pn},则MAE计算公式如下:
(12)
其中pi为预测评分,ri为实际评分。
实验方案为10折交叉验证法(10-FoldCross-Validation)[2,3]。此方案将MovieLens数据集随机分为10个互不相交的数据集,轮流选择其中的一份作为测试数据集,其他9份作为训练集,重复执行10次测试算法,保证每个子数据集有且仅有一次作为训练集,最后取十次计算结果的平均值作为实验的整体结果。
2.2 实验结果及分析
2.2.1 动态权重线性因子λ的影响
在式(7)中,动态权重线性因子λ起着非常重要的作用,如果λ的取值不当,会造成动态权重DynamicWeight(i)的值过大或者过小,进而改变基于用户内容的推荐和协同过滤两种推荐算法在混合推荐中所占比重大小,极大影响算法的推荐精度。所以,本次实验针对在不同线性因子λ下,对本文提出算法的推荐结果进行测试,并对不同的相邻用户数量θ之间的实验结果进行了对比,实验结果如图3所示。

图3 不同线性因子λ的实验结果对比
从式(7)中可以发现,随着λ的增加,在最终的预测评分中协同过滤部分所占比重增加。而从图中的曲线变化可知,针对同一相邻用户数量,MAE总体呈下降趋势,说明相对较大的λ值所提高的协同过滤比重可以在一定程度上提高推荐的准确性。特别是当λ=4时,算法可以达到最佳的推荐质量。但随着λ继续增大,MAE的数值并没有显著减小,反而略微开始增加,这说明此时协同过滤预测所带来的误差对结果的影响增大,而基于用户内容部分在稀疏数据中所展现出来的优势在低权值下无法对结果产生影响,从而降低了算法的推荐精度。
2.2.2 常见推荐算法推荐效果对比
为了验证本文算法在提高推荐预测准确性方面的有效性,本次实验选用同是混合推荐算法但采用固定权重推荐的文献[16]。优化混合推荐算法作为主要对比算法。而在传统的推荐算法中,相邻用户是目标用户预测评分的关键依据,邻居规模的大小都有可能影响推荐算法的准确度。所以,本次实验分别对传统的基于用户的协同过滤、基于项目的协同过滤、优化混合推荐算法[16]。以及本文提出的算法等四种算法在不同的相邻用户数量θ下的推荐精度进行对比。实验结果如图4所示。

图4 不同相邻用户数量θ的实验结果对比
由图可知,不论是文献[16]算法还是本文的算法,其核心都是将多种推荐算法进行组合,减小传统单一推荐算法在不同使用场景下的计算误差,所以混合算法的推荐精度都远高于传统单一推荐算法。而针对混合推荐算法,由于文献[16]算法在计算相似度的过程中采用固定权重的方式将物品属性相似性和修正余弦相似度线性组合,忽略了相邻用户个体评分数据稀疏性差异以及用户评分数据受外界条件等因素的影响。因此,从实验结果可以看出,本文所提出的推荐算法在不同数量的相邻用户下其MAE均小于文献[16]中的混合推荐算法,推荐效果一直处于较高的优势,并随着相邻用户数量的增加,优势也逐渐增加。就本文提出的算法而言,随着相邻用户数量的增加,MAE总体呈下降趋势,特别是当50<θ<60,即相邻用户数量取到所有训练集用户数量的50%~60%时,MAE值取最小,推荐效果最好。而当相邻用户数量超过60%时,由于过多的邻居评分引入了更多相似度不高的噪声数据,从而降低了推荐精度,影响了算法的推荐效果。
3 结 语
本文对传统的混合推荐算法进行了优化,将用户行为特征进行量化并引入到用户相似度的计算中来,并根据用户数据稀疏性的个性化差异,自适应地将多种推荐算法动态连接并进行推荐预测。实验结果表明,该算法从多方面缩小因单一推荐算法所带来的推荐误差,极大地提高了传统单一推荐算法在稀疏数据集中推荐的准确性。相较于其他的混合过滤算法,引入动态权重的概念来调整不同推荐算法所占的比重,有效平衡因用户历史数据集稀疏性的个性差异所带来的推荐误差,提高推荐质量。从实验中发现,算法在相邻用户数量较低的情况下推荐精度下降,并且混合推荐自身存在的计算量大、耗时长等问题,下一步该算法还需在以上两个方面进行深入研究。
[1]AdomaviciusG,TuzhilinA.Towardthenextgenerationofrecommendersystems:Asurveyofthestate-of-the-artandpossibleextensions[J].IEEETransactionsonKnowledgeandDataEngineering,2005,17(6):734-749.
[2] 任磊.推荐系统关键技术研究[D].上海:华东师范大学,2012.
[3] 朱文奇.推荐系统用户相似度计算方法研究[D].重庆:重庆大学,2014.
[4]GuptaJ,GadgeJ.Performanceanalysisofrecommendationsystembasedoncollaborativefilteringanddemographics[C]//Communication,Information&ComputingTechnology(ICCICT),2015InternationalConferenceon.IEEE,2015:1-6.
[5] 赵伟明.基于用户行为分析和混合推荐策略的个性化推荐方法研究[D].北京:北京工业大学,2014.
[6]AbhishekK,KulkarniS,ArchanaVKN,etal.AReviewonPersonalizedInformationRecommendationSystemUsingCollaborativeFiltering[J].InternationalJournalofComputerScienceandInformationTechnologies(IJCSIT),2011,2(3):1272-1278.
[7]ScheinAI,PopesculA,UngarLH,etal.Methodsandmetricsforcold-startrecommendations[C]//Proceedingsofthe25thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM,2002:253-260.
[8]BaoH,LiQ,LiaoSS,etal.AnewtemporalandsocialPMF-basedmethodtopredictusers’interestsinmicro-blogging[J].DecisionSupportSystems,2013,55(3):698-709.
[9]LeeTQ,ParkY,ParkYT.Atime-basedapproachtoeffectiverecommendersystemsusingimplicitfeedback[J].ExpertSystemswithApplications,2008,34(4):3055-3062.
[10]KoenigsteinN,DrorG,KorenY.Yahoo!musicrecommendations:modelingmusicratingswithtemporaldynamicsanditemtaxonomy[C]//ProceedingsoftheFifthACMConferenceonRecommenderSystems.ACM,2011:165-172.
[11] 张腾季.个性化混合推荐算法的研究[D].杭州:浙江大学,2013.
[12] 张新猛,蒋盛益,李霞,等.基于网络和标签的混合推荐算法[J].计算机工程与应用,2015,51(1):119-124.
[13]PazzaniMJ,BillsusD.Content-basedrecommendationsystems[M]//TheAdaptiveWeb.Springer,2007:325-341.
[14]ChenW,NiuZ,ZhaoX,etal.Ahybridrecommendationalgorithmadaptedine-learningenvironments[J].WorldWideWeb,2014,17(2):271-284.
[15]TangX,ZhouJ.Dynamicpersonalizedrecommendationonsparsedata[J].IEEETransactionsonKnowledgeandDataEngineering,2013,25(12):2895-2899.
[16] 李鹏飞,吴为民.基于混合模型推荐算法的优化[J].计算机科学,2014,41(2):68-71,98.
A DYNAMIC-WEIGHTED HYBRID RECOMMENDATION ALGORITHM BASED ON USER BEHAVIOR CHARACTERISTICS
Liu Peiwen Chen Huafeng
(NationalEngineeringResearchCenterforMultimediaSoftware,WuhanUniversity,Wuhan430072,Hubei,China)(CollegeofComputer,WuhanUniversity,Wuhan430072,Hubei,China)
A recommendation system can personalize website service for different users, and how to provide accurate recommendations has become the biggest difficulty. Aiming at the sparsity problem of traditional recommendation algorithm, dynamic-weighted hybrid recommendation algorithm based on user behavior characteristics is proposed. Through the data preprocessing in dataset, the personalized behavior characteristic index of different users for different items is calculated and introduced into the similarity calculation. The dynamic weight is calculated according to the difference of the user’s rate data sparseness, and the user’s content recommendation and collaborative filtering recommendation are dynamically mixed. Experimental results show that the proposed algorithm can reduce the recommendation error effectively and improve the recommendation accuracy in the sparse data set.
User behavior characteristics Dynamic-weighted Hybrid recommendation algorithm
2016-03-19。刘沛文,硕士生,主研领域:模式识别与智能系统。陈华锋,博士生。
TP301.6
A
10.3969/j.issn.1000-386x.2017.04.054
