引入层次成分分析的依存句法分析
2017-04-20周俏丽张桂平
张 丹,周俏丽,张桂平
(沈阳航空航天大学 人机智能中心,沈阳 110136)
引入层次成分分析的依存句法分析
张 丹,周俏丽,张桂平
(沈阳航空航天大学 人机智能中心,沈阳 110136)
长距离依存分析准确率低是依存句法分析中很重要的问题,针对该问题,提出了一种引入层次成分分析的依存句法分析方法,在依存分析之前进行包括非核心成分和核心成分的成分识别,对成分内部和成分之间进行依存分析,该方法能避免产生长距离依存关系。同时,针对不同成分训练不同模型。在CoNLL 2009评测语料中,UAS值在develop数据集上提升了2.53%,在test数据集上提升了1.39%。实验结果表明,结合语言学知识,引入层次成分分析,能够有效地改善依存分析效果。
层次成分分析;成分识别;依存句法分析
近年来,依存句法分析一直是自然语言处理领域的热点和难点问题之一,受到了越来越多的关注,目前主流的依存句法分析技术是基于依存树库的统计依存句法分析。但统计的依存句法分析存在数据稀疏、长距离分析准确率低等问题,因此,针对汉语句子的句法结构,利用语法、语义、语用等语言学知识对其进行多方面、多角度的分析已成为汉语语言学界的共识。
层次分析法是分析句子结构的一种方法,层次分析法认为任何一个复杂的语言单位都是由较小的语言单位组成的,但不是一次组成的,而是由小到大逐层组织起来的[1]。而依存句法是通过分析语言单位内成分之间的依存关系揭示其句法结构的[2],依存句法表现的只是词与词之间的依存关系,没有层次关系。因此,可以结合层次分析方法,将依存句法关系转化成带有层次的句法结构关系。
针对长距离依存关系分析准确率低的问题,本文结合层次分析法提出了一种面向依存结构的句子层次成分分析方法,该方法在依存分析之前提取分析单元,对分析单元内部和分析单元之间进行依存句法分析,从而缩短分析单元,消除长距离依存关系。并且,按照结构特点将具有相似结构分析单元划分成一类,针对不同分析单元训练不同的分析模型,其句法特征更明显,分析的复杂度降低,训练速度和分析的准确率都能够得到有效提升。
1 相关研究
句法分析在自然语言处理领域中依然存在很多困难,许多研究人员将语言学知识应用到句法分析,在进行完整句法分析之前进行预处理,降低了句法分析的难度。将组块分析、层次分析等手段应用到句法分析中取得了很好的效果。
一些研究者尝试将一些语言学知识应用到句法分析中,Collins[3]提出了中心词驱动的句法分析模型,其主要思想就是在上下文无关文法规则中引入词汇化信息和短语的中心词信息。林颖[4]提出了一个基于统计模型的自顶向下的汉语句法分析器。在树库提取的基础上利用Inside-Outside算法进行迭代获得句法规则参数;针对汉语虚词的特点,引入了句法结构共现概率。引入信息增强了句法分析模型的消歧能力,但却带来了严重的数据稀疏问题。
有一些研究者在进行完整句法分析之前进行预处理,利用了组块分析、层次分析等手段。其中,一些方法使用标点分割句子,李幸[5]提出了一种新的面向汉语长句的层次化句法分析方法,这种方法利用“分割”标点将复杂长句分割成子句序列,首先对每个子句进行第一级分析即单句句法分析,然后对分析后的子树根结点标记进行第二级分析。李正华[6]提出了一种基于标点符号的快速依存句法分析方法,当使用逗号、分号等标点符号将长句切割,分析子句内部和子句间的结构,再得到整个句子的依存句法结构。利用标点分割句子,得到的分句可能不是单根节点,在判断时存在一定难度。
另一些方法对句子进行组块识别及分析,周俏丽[7]针对短语结构句法分析提出了一种基于分治策略的组块分析方法,对句子进行最长名词短语识别,针对不同分析单元选用不同模型加以分析,再将分析结果进行整合。Li[8]提出了层次句法分析模型,该模型先对输入句子进行词性标注和基本组块识别,循环多次进行复杂组块识别直至得到根结点,该方法本质上属于一种基于移进-归约序列的句法分析模型。Geng[9]提出了一个基于历史信息的多层次中文句法分析方法,采用最大熵模型进行参数学习,每层处理过程中优先识别出容易识别的组块,在此基础上根据更丰富的上下文信息循环进行复杂组块的识别,直至识别出根结点。该类方法主要是针对短语结构句法分析,其训练语料短语边界是已知的。
在进行多层次的识别及分析时有可能会产生级联错误,因此一些研究者提出了利用信息约束或纠错的多层分析系统。蒋志鹏[10]提出了一种基于多层协同纠错的中文层次句法分析,将句法分析分解为词性标注、组块分析和构建句法树3个阶段。将其中的组块分析细分为基本块分析和复杂块分析,并提出了一种简单可行的错误预判及协同纠错算法,跟踪本层预判的错误标注结果进入下一层,利用2层预测分数相结合的方式协同纠错。赵羿欧[11]提出了层次化的汉语功能成分的分步分析方法,分别从从句级别、基本功能层级和功能名词短语结构层级3个部分依次进行分析,在依存句法分析过程中用功能信息来进行约束。
还有一些研究者将分析划分阶段,通过多阶段的分析减少搜索空间来实现整体效率和准确率的提升。Wenjing Lang[12]提出一种基于依存方向的多阶段依存分析方法,引入了依存方向概念,对于汉语句子,在做依存句法分析之前,先判断其每一个词的依存方向,可有效地预测其核心词在句中的相对位置。
本文针对长距离依存分析,利用层次成分分析提取分析单元,得到具有相似结构的依存分析单元,消除长距离依存关系,并针对不同分析单元训练不同模型进行依存分析,利用更明显的语言特征改善分析的效果。
2 面向依存树的句子层次成分分析
2.1 依存句法树的层次成分分析
本文面向依存树提出了一种改进的层次成分分析方法,将依存树转化成有层次的句法结构。传统的层次分析法对句子进行逐层顺次的分析,反应了句子语法结构的自然层次,体现了语言结构的层次性[13]。利用层次分析法分析句法结构时,同时要说明结构关系,所得到的分析结果可以用图解法表示,图1为一个句子的层次分析结果。
为简化句子结构,消除长距离依存关系,本文提出了一种改进的层次分析法。一般句子的结构是“主谓宾”结构,句子中还可能包括一些状语、补语来修饰谓语,一些定语来修饰主语和宾语。本文对层次分析法做了改进,在保证句子的完整程度和合理性的前提下,有效地缩短句子,当句法成分为主语、宾语、状语时不再进行下一步的层次分析,但存在一种特殊情况,即当句法成分为主语或宾语时是一个带有谓语的子句时,要进行下一步的层次分析,只保留句子的顶层分析结果,并且将每一层的每一块按照句法成分进行标注,得到的层次成分分析结果如图2所示。

图1 句子层次分析结果

图2 层次成分分析结果
可以表示为:SUB[两个银行的负责人]ADV[在签字仪式上]ADV[一致]PRE[表示]SUB[协议的续签]ADV[将]PRE[促进]OBJ[合作]改进后的层次成分分析法面向依存结构,可根据词与词之间的依存关系,将依存结构转化成有层次的句法结构,如图3所示。

图3 依存句法树的层次成分分析结果
句子中有4种成分,对成分进行分类,由于句子中的主语和宾语具有相似的结构,且是组成句子完整结构的成分,因此将主语和宾语成分划分为核心成分,将状语成分划分为非核心成分,将核心成分和非核心成分的核心词与谓语组成句子框架。为消除长距离依存关系,将词数大于1的核心成分和非核心成分单独从依存句法树中提取出来,用其核心词代替整个成分,将一棵依存句法树分解成为3种子树,在此称其为核心成分子树、非核心成分子树和句子框架子树,该方法既保证3种子树的语义完整程度,又使每种子树的句法特征更明显。图3的依存句法树被分解成的3种子树如图4所示,其中非核心成分子树和核心成分子树可能有多个,句子框架子树只能有一个。
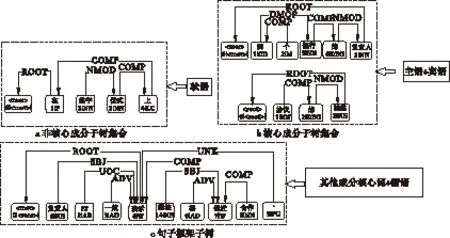
图4 分解后形成的3种子树
为消除长距离依存关系,在进行依存分析之前,首先要进行成分识别,训练成分识别的模型需要对训练语料进行成分标记,因此,本文制定了针对训练语料的成分子树标记规则。
2.2 成分子树标记规则
实验语料为CoNLL 2009 shared task依存句法分析评测语料,该语料描述的只有词与词之间的依存关系,没有层次结构,因此,本文为了得到依存树中的层次成分结构,制定了成分子树标记规则。
该语料中,依存关系共有30种,其中充当状语成分的关系有DIR、ADV、TMP、BNF、LGS、LOC、MNR、PRP,这些成分一般都是介词短语;充当主语成分的有SBJ、VOC、FOC等,充当宾语成分的有COMP、OBJ、EXT等。
根据词与词之间依存关系,标记核心成分和非核心成分的边界,并将其抽取出来。针对CoNLL语料,本文制定的成分标记规则如下,其算法如图5所示。
(1)非核心成分子树标记规则
由于非核心成分主要是介词短语,本文认为介词短语都是非核心成分,非核心成分的左边界是介词,找依存于介词的最右子节点,判断该子节点右侧是否还有子节点,循环此过程,找到非核心成分的右边界。
(2)核心成分子树标记规则
1)从根节点出发,寻找根节点的子节点,判断该节点与根节点的依存关系。
2)若该节点与根节点的依存关系为CJTN或cCJTN,且依存于CJTN或cCJTN的词与其依存关系为CJT,则把依存于CJTN或cCJTN的词当作根节点处理。
3)若与该节点依存关系是SBJ、VOC、COMP、OBJ等时,判断该节点的词性,若词性是名词,则直接寻找该节点的左右边界;若该节点词性为动词,则将该节点当作根节点处理并重复以上过程。
(3)句子框架子树生成规则
分别将非核心成分子树和核心成分子树从句子中抽取出来,其中将核心成分子树的核心词留在句子中代替整棵子树,由于非核心成分起到修饰作用,其核心词是介词,所以非核心成分子树整体用“PP”代替,与句子中的谓语成分形成句子框架,如图4(c)中所示,这种方法形成的句子框架保证了完整的语义。

图5 成分子树标记算法
3 实验流程
本文为简化句子结构以消除长距离依存关
系,提出了一种引入层次成分分析法的依存句法分析。具体实验过程如图6所示。
对于训练语料,使用成分子树标记算法得到3种语料:带非核心成分标记的训练语料、带核心成分标记的语料、带所有成分标记的语料。其中带非核心成分标记的训练语料用来训练非核心成分识别模型和抽取非核心成分子树,带核心成分标记的训练语料用来训练核心成分识别模型和抽取核心成分子树,带所有成分标记的语料用来生成句子框架子树,3种子树语料分别用来训练其内部的依存分析模型。
其中,非核心成分识别系统的模型使用的是基于层叠条件随机场的汉语介词短语识别系统[14],核心成分识别系统的模型是使用的是带核心成分标记的训练语料生成的模型,其特征模板参考郎文静[12]的最长名词短语识别实验中的模板。

图6 实验过程图
对于输入的测试语料分4步处理。
第一步,进行非核心成分识别,将识别出的非核心成分使用非核心成分依存分析模型进行测试,经过解码后生成非核心成分内部的一棵依存树,将其根节点留在句子中,进行下一步的分析。
第二步,对经过第一步的句子进行核心成分识别,将识别出的核心成分使用核心成分依存分析模型进行测试,经过解码后生成核心成分内部的一棵依存树,将其根节点留在句子中,进行下一步的分析。
第三步,将第一步和第二步生成非核心成分子树和核心成分子树的根节点与句子中其他词形成句子框架,使用句子框架依存分析模型进行测试,经过解码后生成句子框架的一棵依存树。
第四步,整合3种子树的分析结果,生成一棵完整的依存树。
4 实验结果及分析
实验数据来自CoNLL2009 Share Task评测语料,训练集数据包含22 277 个句子,句子平均长度为27.34 个单词,develop数据集包含1 762个句子,句子平均长度为28.16个单词,test数据集包含2 530个句子,句子平均长度28.47个单词。develop数据集没有参与训练。
训练语料使用成分子树标记算法后,训练语料中包括非核心成分子树22 457个,核心成分子树56 563个,形成句子框架的平均长度为13.88个单词。
4.1 成分识别结果
经过成分识别后,开发集共提取非核心成分1 916个,核心成分4 774个,句子框架的平均长度为14.01个单词;测试集共提取非核心成分2 828个,核心成分6 804个,句子框架的平均长度为14.48个单词。
成分识别的评价标准采用准确率(P)、召回率(R)和F值。本文的非核心成分和核心成分识别的结果如表1、表2所示,非核心成分识别的准
确率较核心成分识别的准确率高,其原因是非核心成分的左边界是已知的。

表1 非核心成分识别准确率 %
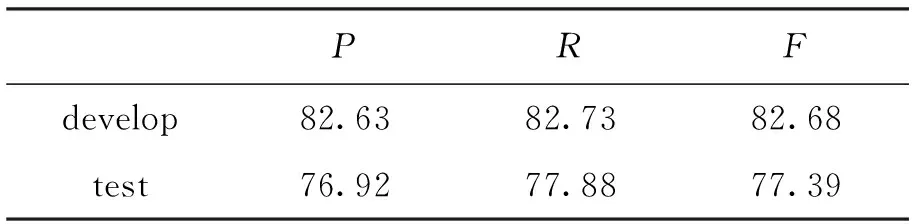
表2 核心成分识别准确率 %
4.2 依存分析结果
依存分析的最终结果采用依存弧准确率UAS(Unlabeled Attachment Score)和依存关系准确率LAS(Labeled Attachment Score)进行评价。
LAS=
本文的baseline系统是基于依存方向的依存句法分析系统[12],依存方向和依存弧实验的特征模板参考该系统,但解码算法与其不同,本文使用的解码算法是Eisner算法[16]。
经过内部依存分析后,整合3部分的分析结果,得到的实验结果如表3所示。本文做了对比实验,其中Non-core代表的是只识别非核心成分,不识别核心成分;Core代表的是只识别核心成分,不识别非核心成分;Non-core+Core代表的是先识别非核心成分,再识别核心成分。

表3 依存分析结果 %
经过成分识别后的系统UAS值在develop数据集上提升了2.53%,在test数据集上提升了1.39%;LAS值在develop数据集上提升了2.82%,在test数据集上提升了1.69%。本文还做了一组在成分识别完全正确情况下进行依存分析的实验,如表4所示,UAS的最高值在develop数据集上达到88.22%,在test数据集上达到86.48%;LAS的最高值在develop数据集上达到83.42%,在test数据集上达到81.88%。实验结果表明,尽管在非核心成分识别和核心成分识别时可能产生级联错误,但是能很好地改善依存分析的效果。因此,如果改善成分识别效果,依存分析结果依然有提升空间。

表4 成分识别完全正确情况下依存分析结果 %
针对不同类型成分单独分析,句子得到了简化,特征更明显,能够改善依存分析效果,表5是develop数据集上3种子树采用多模型单独分析后的UAS实验结果。
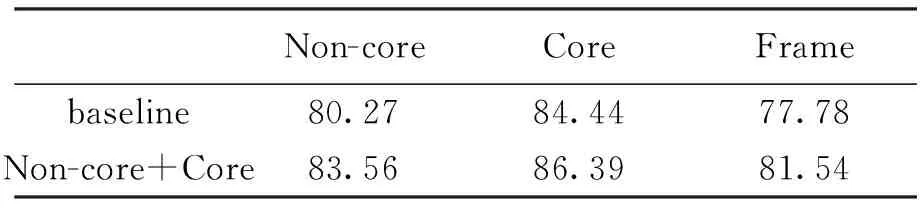
表5 各子树内部依存分析结果 %
本文还做了单模型的依存句法分析系统的实验,即将非核心成分子树、核心成分子树、句子框架子树形成一个训练语料,只生成一个模型,实验结果如表6所示。多模型的依存句法分析系统,训练速度较单模型的依存句法分析系统快,耗费时间短,并且分析效果较单模型的稍好一点。多模型的依存句法分析系统训练速度仅是baseline系统训练时间的四分之一,大大提升了模型训练速度。

表6 模型训练时间
5 结论
本文的主要工作是针对长距离依存问题,结合层次分析法提出了一种面向依存结构的层次成分分析方法,该方法能有效地消除长距离依存关系。根据层次成分结构将训练语料依存句法树分解成非核心成分子树、核心成分子树和句子框架子树,针对不同分析单元训练不同模型进行依存分析,使其语言特征更明显、分析复杂程度降低、分析效率提高。尽管成分识别会引起级联错误,但整合结果后的系统UAS值在develop数据集上提升了2.53%,在test数据集上提升了1.39%,仍然取得了很好的效果。实验表明,结合语言学知识并引入层次成分分析,能够提升依存分析的准确率。今后,将进一步深入研究如何能更好地将语言学知识融合到依存句法分析中。
[1]张斌,陈昌来.现代汉语句子[M].上海:华东师范大学出版社,2000.
[2]刘海涛.依存语法和机器翻译[J].语言文字应用,1997,23(3):89-93.
[3]COLLINS M.Head-driven statistical models for natural language parsing[D].Pennsylvania:The University of Pennsylvania,1999:65-78.
[4]林颖,史晓东,郭锋.一种基于概率上下文无关文法的汉语句法分析[J].中文信息报,2006,20(2):1-8.
[5]李幸,宗成庆.引入标点处理的层次化汉语长句句法分析方法[J].中文信息学报,2006,20(4):8-15.
[6]李正华.汉语依存句法分析关键技术研究[D].哈尔滨:哈尔滨工业大学,2013.
[7]周俏丽,刘新,郎文静,等.基于分治策略的组块分析[J].中文信息学报,2012,26(5):121-127.
[8]JUNHUI LI,GUODONG ZHOU,QIAOMING ZHU,et al.Syntactic parsing with hierarchical modeling[C].Proceedings of the 4th Asia Information Retrieval Conference on Information Retrieval Technology,2008,4993:561-566.
[9]XIANGHAO GENG,JUNHUI LI,GUODONG ZHOU,et al.A history-based hierarchical Chinese parsing[J].Computer Applications and Software,2009,26(6):45-51.
[10]蒋志鹏,关毅,董喜双.基于多层协同纠错的中文层次句法分析[J].中文信息学报,2014,28(4):30-35.
[11]赵羿欧.面向层次化的汉语功能成分识别研究[D].哈尔滨:哈尔滨工业大学,2015.
[12]WENJING LANG,QIAOLI ZHOU,GUIPING ZHANG,et al.Multi-stage Chinese dependency parsing based on dependency direction[C].Proceedings of the 13th Machine Translation Summit(MT Summit).Xiamen,2011:64-71.
[13]崔婉星.《汉语层次分析录》与句法分析[D].武汉:华中科技大学,2012.
[14]张灵.基于层叠条件随机场的汉语介词短语识别研究[D].沈阳:沈阳航空航天大学,2012.
[15]EISNER J.Three new probabilistic models for dependency parsing[C].An Exploration Proceedings of COLING 1996.Copenhagen,1996:340-345.
[16]李正华,车万翔,刘挺.基于柱搜索的高阶依存句法分析[J].中文信息学报,2010,24(1):37-41.
(责任编辑:刘划 英文审校:赵亮)
Using hierarchical component analysis for dependency parsing
ZHANG Dan,ZHOU Qiao-li,ZHANG Gui-ping
(Research Center for Human-computer Intelligence,Shenyang Aerospace University,Shenyang 110136,China)
At present,the low accuracy of long-distance dependency analysis is a vital problem in dependency parsing.To address this problem,this paper proposes a hierarchical component analysis method for dependency parsing.This method performed component identification before the process of dependency analysis.The components included core components and non-core components.The dependency analysis was performed within components and among components.In this context,the method can avoid generating the long-distance dependency relationships.At the same time,different models were trained for different components.On CoNLL 2009′s evaluation corpus,the UAS is increased by 2.53% on the develop data set and by 1.39% on the test data set.Experimental results show that using hierarchical component analysis based on linguistic knowledge can improve the dependency parsing performance effectively.
hierarchical component analysis;component identification;dependency parsing
2016-11-28
国家自然科学基金项目(项目编号:691403262);教育部社科青年基金项目(项目编号:14YJC740216)
张 丹(1992-),女,辽宁葫芦岛人,硕士研究生,主要研究方向:知识工程与知识管理,E-mail:630029794@qq.com;张桂平(1962-),女,辽宁本溪人,教授,主要研究方向:自然语言处理、机器翻译,E-mail:zgp@ge-soft.com。
2095-1248(2017)01-0076-07
TP391.1
A
10.3969/j.issn.2095-1248.2017.01.012
