南极平均温度的聚类分析及预测
2017-04-19尹修草厉珍珠方晓静
尹修草,厉珍珠,方晓静
(华南农业大学 数学与信息学院,广州,510642)
南极平均温度的聚类分析及预测
尹修草,厉珍珠,方晓静
(华南农业大学 数学与信息学院,广州,510642)
南极是研究全球变暖问题的典型地区,由于南极所处的纬度以及其特殊的地理风貌、自然气候,所以研究南极以往的实测资料就显得尤为重要。本文利用英国南极调查局网站,得到2000-2015年的实测温度资料。由于观测点的温度可能受不同因素的影响,我们通过聚类分析,把观测点进行分类。然后建立时间序列模型,对不同类别的观测点进行温度变化规律的探讨,得到南极的平均气温。最后我们应用时间序列分析方法,研究南极地表温度与时间之间的变化规律。
聚类分析; 时间序列; ARIMA模型;南极温度预测
南极洲是一个极其特殊的地方:它的气候在地球上是最干燥、多风和寒冷的地方。覆盖南极洲的冰川平均厚度达2000米,覆盖面积达到1400万平方千米。南极洲的气候以及地理位置决定了那里人际罕至、与世隔绝。直到2007年,科学家都一直认为全球变暖并未影响到南极洲的气候。
2007年,联合国政府间气候变化专门委员会在其《第四份分析报告》中提到:南极洲是唯一未探察到人类所致温度变化的大陆[1]。这份报告还得出结论,南极与北极不同,南极的冰川并未像北极那样经历惊人的大面积融化。一些数据甚至显示,南极大陆的温度正在温和的下降.这份报告成为那些怀疑全球变暖的人的证据。然而,事实是,科学界对南极洲以前的气候了解甚少。针对未来的研究,我们需要了解到冰川融化的数量以及海平面上升速度的快慢。而想要对这些问题做出比较精准的估计,南极洲将是我们主要研究的对象[2]。
南极平均温度的问题如下:
地球陆地表面平均温度是气候变化和全球变暖的一个重要指标。但是,以前的估计,一些如何定义地表温度的方法也有差别。为简单起见,我们只考虑南极洲。根据气象站温度计测量的数据,建立数学模型,估算表面平均温度,并描述南极温度随时间变化的情况。
现将上述问题具体分析成如下:
(1)给出一个平均地表温度的定义模型。
(2)根据气象站观察的数据建立一个数学模型预测南极洲地表平均温度,并预测南极洲的温度变化。
要定义平均地表温度,得考虑平均地表温度受各类因素的影响的轻重程度,各个因素之间的关系,才能更加准确地给出相关的定义式子;只有确定了相关的影响因素并加以结合,得到的数学模型才能预测南极洲的平均地表温度,根据预测得到南极洲温度随时间的变化情况。
1 模型的建立
1.1 符 号

符号含义xt时刻的过程值B后移算子
1.2 资料处理以及假设
根据英国南极调查局网站所得数据,我们只选用2000-2015年期间,累计资料在180个月以上的42个气象站的逐月平均温度。
假设:(1)南极洲地表的平均温度不受高空风速的影响;
(2)南极洲地表的平均温度不受高空风向的影响;
(3)所用的气象站给的数据是准确度非常高的;
(4)南极洲地表的平均温度是由2000年之后的变化是显著的,2000年之前的变化不是显著的;
(5)所选气象站的具体地理位置是准确无误的.
1.3 模型一:聚类分析
聚类分析是指一批样品的很多观测的指标,按照一定的数学公式计算一些样品或一些参数(指标)的相似程度,把相似的样品或指标归为一类,把非相似的归为一类[3]。聚类分析步骤:
1.3.1 选择变量
(1)根据聚类分析的目的选定适当的变量
(2)给出需要分类的变量所具有的特征
(3)保证不同的研究对象所对应的值有显著的差异
(4)变量之间的相关度不能很高
1.3.2 计算相似性
相似性是指研究对象之间的亲疏度,聚类分析是根据对象之间的亲疏程度(相似性)来分类的。用来描述相似性的测度有很多。
1.3.3 聚 类
在选定了聚类的变量,计算出样品(指标)之间的相似度后,可以写出一个相似度的矩阵。这主要涉及两个方面的问题:
(1)如何选择聚类分析的方法
(2)如何确定类别数
1.3.4 聚类结果的解释和证实
对聚类分析的结果进行说明是对各个类别的特征的准确的刻画,给每类确定一个适合的名称。这一步可以利用描述性的统计量来分析,一般是通过计算各类在聚类变量上的均值,通过对均值比较,来解释各类差别的原因。
1.3.5 对南极各站点进行聚类分析
在南极,各地温度变化的特征差异性较大,为了对南极以及邻近地区的温度变化的空间分布有客观的区域划分,我们根据各站点的温度、经纬度以及气象站的高度进行标准化的聚类分析。
根据分类的原理和现有数据,我们运用SPSS软件对所选的气象站点进行分类。分类结果见下表:
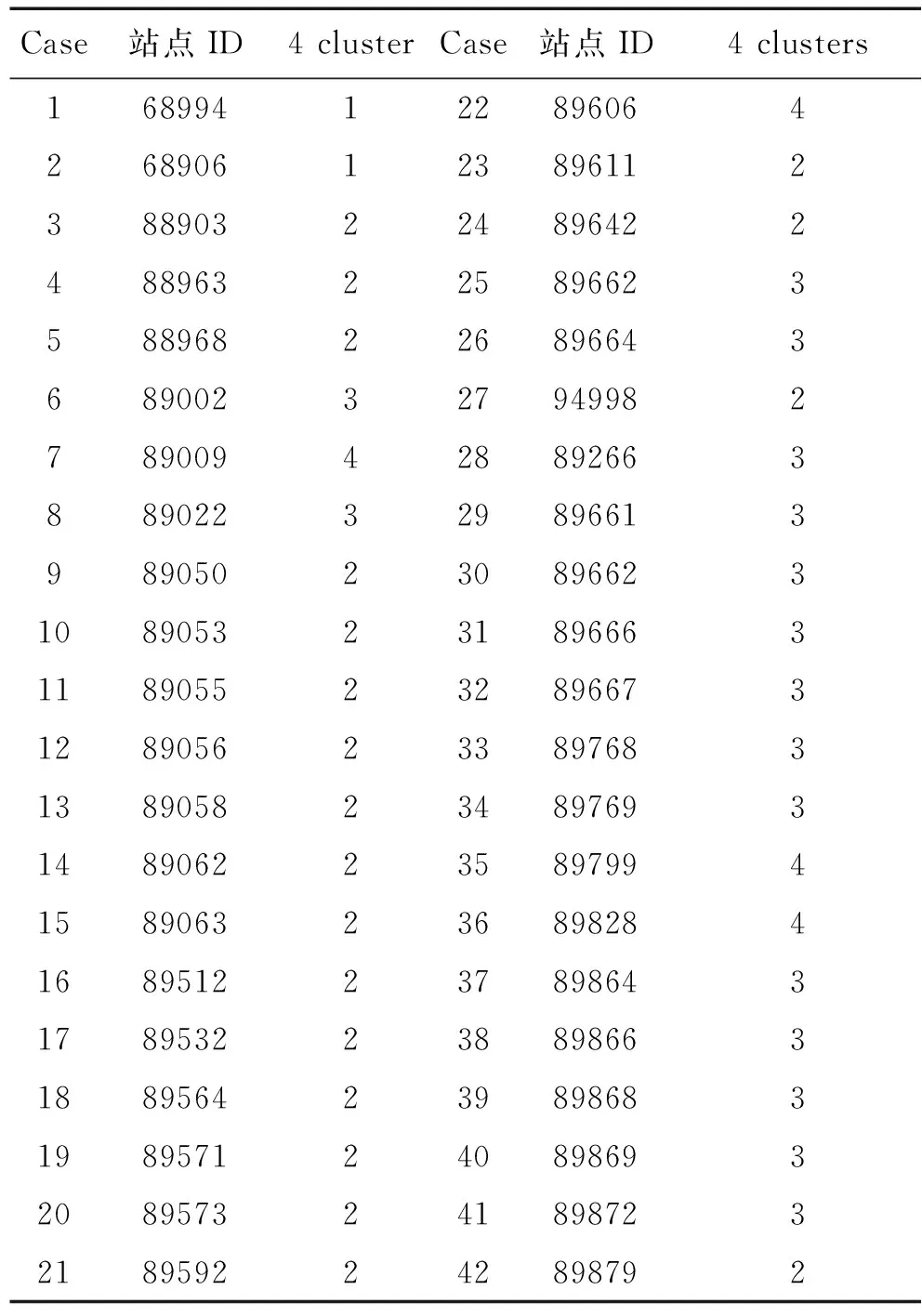
表1 聚类分析观测点Table 1 The observation point of cluster analysis
由上表可知,选取的气象站可分为4大类进行分析,建立模型和预测。
1.4 模型二:时间序列模型
时间序列所需要的模型实际上就是随机模型,观测到的时间序列就被看作是随机过程所生成的时间序列无穷总体的一个样本实现。时间序列的变量内部的机理一般也不是很清楚,因此一般用的分析方法是拟合分析法。
常用的时间序列随机模型有:求和自回归滑动平均模型(AutoRegressiveInterated MovingAverage,缩写ARIMA)、季节模型、传递函数模型和干预模型。本文主要用到ARIMA模型、季节模型和传递函数模型。在分别介绍它们之前,先简单介绍自回归模型(AR)和滑动平均模型(MA),它们是ARIMA模型的特殊形式[4]。
AR模型定义:
AR(p)模型有三个限制条件:
1:∅p≠0这个条件,确保了模型的最高阶数为p。

3:Exsεt=0,∀s MA模型的定义: 使用MA(q)模型需要满足两个限制条件: 1:θq≠0这个限制条件,确保模型的最高阶数为p。 ARMA(p,d,q)的模型称为求和自回归移动平均模型,结构如下: (1) 之所以命名为求和自回归移动平均模型是因为d阶差分分后序列表示为: ARMA(p,q)模型的一般表示方法为: Φ(B)(1-B)dxt=Θ(B)εt (2) 上式和ARMA模型一样,也可以用随机扰动项的线性函数表示: xt=εt+Ψ1εt-1+Ψ2εt-2+…+Ψ(B)εt 此式中的值满足如下递推公式: 式中: 那么 xt+l=(εt+l+Ψ1εt+l-1+…+Ψl-1εt+1)+(Ψlεt+Ψl+1εt-1+…) 由于εt+l,εt+l-1的不可获得性,所以xt+l的估计值只能为真实值与预报值之间的均方误差: 所以在均方误差最小原则下,l期预报值为: l期预报误差为: et(l)=εt+l+Ψ1εt+l-1+…+Ψl-1εt-1 真实值等于预报值加上预报误差 l期预报误差的方差为: 由式(2)容易看出,ARIMA模型的本质是差分与和ARMA模型的组合。这个组合的关系意义重大。这表明任何非平稳序列若能通过适当阶数的差分从而得到差分后的平稳,则就能对差分后序列进行ARMA模型拟合。而ARMA模型的分析方法已经成熟,这说明差分平稳序列的分析也将是简单、便捷以及普遍的。 1.5 数据分析 在掌握了ARMA模型的建模方法之后,尝试使用ARIMA模型对观察序列建模是比较简单的事情。它遵循如下操作流程如下: 图1 时间序列模型建模步骤流程Fig.1 Modeling step flow of time series model 1.5.1 第一类站点的时间序列模型 利用以上图过程,通过SPSS对第一类站点的温度进行分析结果如下: 图2 第一类站点的温度波动Fig.2 The temperature fluctuation of the first kind of site 由上图看出聚类分析表中第一类站点的温度波动程度较大,但是呈现出上下均衡变化,有可能存在季节因素的影响所以我们做波形分解得到数据如下: 图3 波动序列图Fig.3 Fluctuation sequence diagram 季节性因素波动序列图显然是围绕一个值上下波动的,因此猜测受季节性影响。 从以下SAF序列图,季节的温度变化序列图,可见季节对原始数据的序列图造成了波动影响: 图4 季节的温度变化序列图Fig.4 Temperature variation of the seasons sequence diagram 所以我们需要通过SPSS排除了季节和随机干扰后,对原始数据做自相关系数和偏自相关系数分析,得到用SPSS建立ARIMA(1,0,2)(1,0,0)用SPSS做出拟合模型以及拟合图像结果如下: 表2 第一类站点SPSS时间序列拟合结果Table 2 The fitting results of spss time series of the first kind of site 根据上表我们可得第一类站点的拟合模型为: Yt=235.154+0.662Yt-1+0.827-0.38εt-1-0.092εt-2 由以上拟合模型得到的拟合曲线与原曲线的图形如下: 图5 拟合曲线与原曲线的对比Fig.5 Comparison of fitting curve and original curve 拟合曲线以及拟合值上下限区间图像如下: 图6 拟合曲线以及拟合值上下限区间Fig.6 Fitting curves and the upper and lower bounds of the fitted values 所以我们由SPSS软件得到的拟合数据,根据拟合数据预测第一类站点的温度如下。 下面对2016年进行预测值如下(年平均温度:6.094158)。 表3 第一类站点2016年温度预测值Table 3 The temperature prediction of the first kind of site in 2016 根据以上步骤并且通过SPSS进行分析分别得到其他三类站点的模型和温度预测值如下; 1.5.2 第二类站点模型以及温度预测值 Yt=0.972Xt+0.827-0.028εt+44.061 对2016年进行预测值如下(年平均温度:-6.03656)。 表4 第二类站点2016年温度预测值Table 4 The temperature prediction of the Secondkind of site in 2016 1.5.3 第三类站点的模型和数据 Yt=0.963Xt+6.535+0.987εt-1+0.094 对2016年进行预测值如下(年平均温度:-17.7387)。 表5 第三类站点2016年温度预测值Table 5 The temperature prediction of the thirdkind of site in 2016 1.5.4 第四类站点的模型以及温度预测 Yt=-1000.239+0.078Yt-1+0.927Xt-0.538εt-1-0.265εt-2+15.729 对2016年进行预测值如下(年平均温度:-43.5851)。 表6 第四类站点2016年温度预测值Table 6 The temperature prediction of the fourth kind of site in 2016 以上所用模型经自相关性检验建模成功。 该模型将聚类分析与时间序列相结合分别对南极的地表温度进行分区域讨论和拟合,从以上结论可以看出拟合出来的温度与实际温度波动序列图极为接近,所以该模型是有效。并且用时间序列可以较为精确的预测短期内温度的变化值,将南极地表温度分为四个区域来讨论,排除了纬度以及观测点的高度对地表温度所造成的客观影响,同时时间序列模型中加入了季节性因素的,以及随机波动性因素的影响,使得预测值更为精确。从以上模型可以看出全球变暖对南极地表温度是有季节性的影响的,如果就全年平均温度而言,全球变暖对南极地表温度的变化影响也是波动性的。该模型是聚类分析以及时间序列,SPSS的有效结合。 [1]IPCC.气候变化 2007:联合国政府间气候变化专门委员会第四次评估报告[EB/OL]:[2007-04-23].http://www.ipcc.ch. [2]Metzler,R Klafter J.The random walk’s guide to anomalous diffusion:a fractional dynamics approach[J].Phys.Rep.2000,339(1):1-77. [3]Saichev A I,Zaslavsky G M.Fractional kinetic equations:solutions and applications[J].Chaos,1997, 7(4):753-764. [4]Rossilihin Y,Shitikova M.Applications of fractional calculus to dynamic problems of linear and nonlinear hereditary mechanics of solids[J].Applied Mechanics Reviews,1997,50:15-67. [5]Metzler R,Klafter J.Boundary value problems for fractional diffusion equations[J].Physical A:Stat.Mech.Appl.2000,278(1-2):107-125. Cluster analysis and prediction for the average temperature in Antarctica YIN Xiucao,LI Zhenzhu,FANG Xiaojing (College of Mathematics and Information,South China Agricultural University,Guangzhou 510642,China) Antarctica is a sensitive area of global change,because of the special geographic location of the Antarctic and unique natural environment.Analysis of the data observed in the Antarctic also has a very important significance.We get the 2000-2015 measured temperature data from the British Antarctic survey site.Because the observation point temperature may be affected by the impact of different factors,we use cluster analysis and then classify the observation points.Then we establish the time series model to search the temperature variations of observation points for different categories,to get the Antarctica’s average temperature.At last,we use time series analysis method to study the Antarctic surface temperature and time variations. cluster analysis;time series;the modeling of ARIMA;the temperature prediction of Antarctica 1672-7010(2017)01-0016-07 2016-08-10 国家自然科学基金资助项目(61672356) 尹修草(1985-),湖南邵阳人,讲师,博士生,从事微分方程数值解研究,E-mail:tanzhen2856@163.com O414.2 < class="emphasis_bold">文献标志码:A A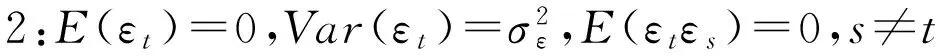
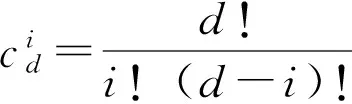
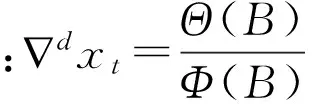

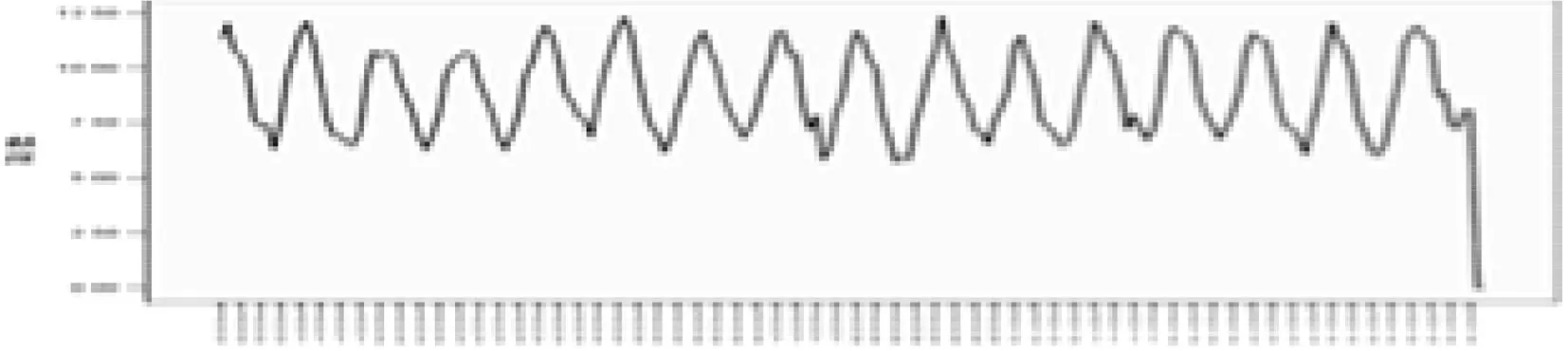


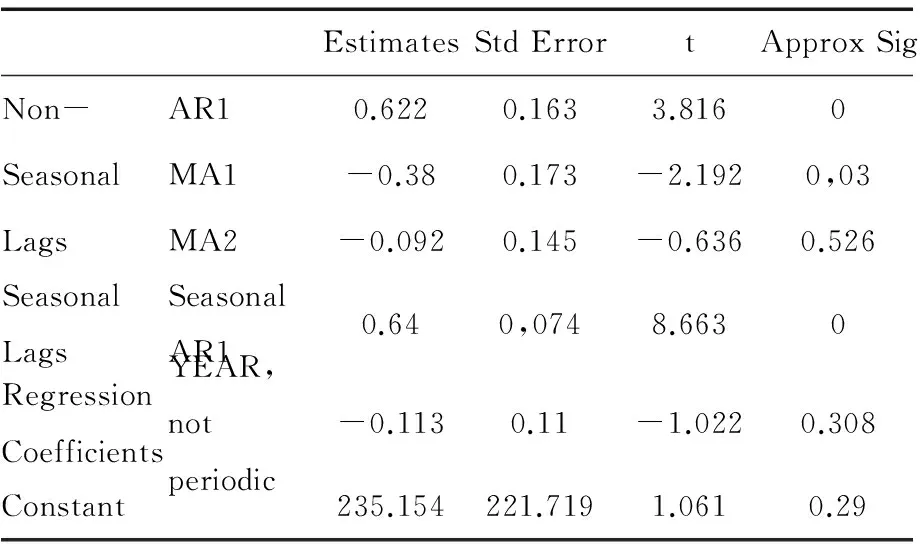

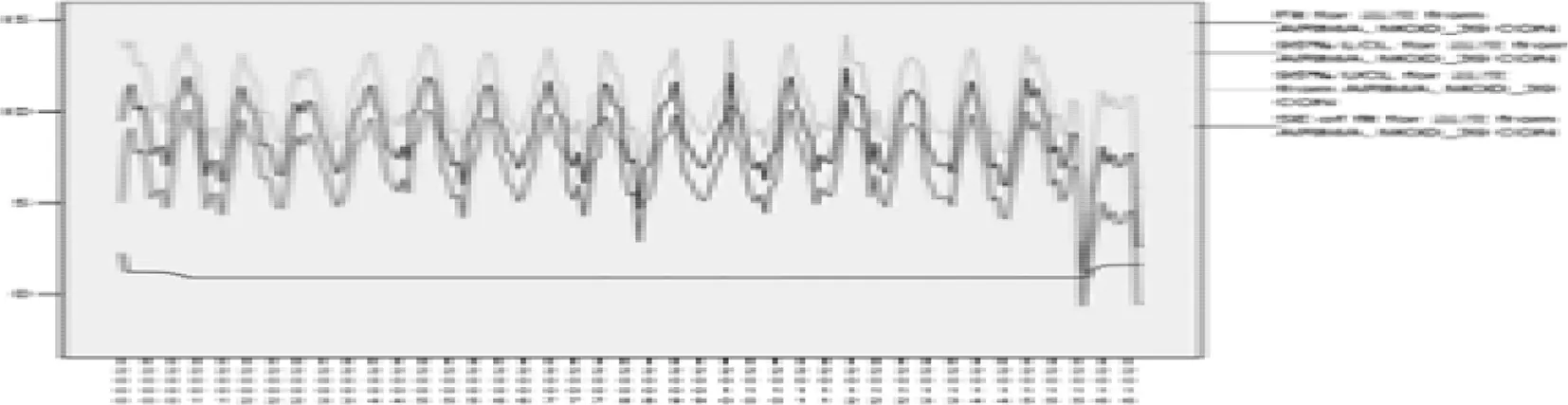




2 总 结
