发布订阅系统中压缩感知匹配算法研究
2017-04-18同济大学饶卫雄
同济大学 陶 金 饶卫雄
发布订阅系统中压缩感知匹配算法研究
同济大学 陶 金 饶卫雄
布尔表达式常用于表达发布订阅系统中的订阅条件及发布内容。由于海量信息的多样性,系统经常表现出高维的特征。如何对海量数据进行有效索引并快速找出有用信息对当前研究提出巨大挑战。本文提出一个压缩感知的匹配算法从时间和空间两方面来优化系统性能。通过编码压缩降低空间开销,然后设计压缩感知的匹配算法加速匹配过程。本文最后与相关工作进行对比实验验证本文方案的性能。
发布/订阅系统;高维稀疏;压缩感知;匹配算法
1.引言
布尔表达式(BE)目前已广泛用于表示发布/订阅系统中应用的订阅条件和发布信息,比如定向广告系统、信息过滤应用和财政新闻简讯[1],[2],[4]。由于需求目标及数据特征的多样性,系统经常面临高维稀疏语义空间的挑战。计算机一方面面临大批量数据存储压力的同时还面临着快速从海量数据中找出有用信息的挑战,这一点对于某些时效性非常高的应用如在线广告推荐系统尤为重要。
当前许多方案在解决小批量低维数据时,可以通过构建多维树形结构[6],[7],[8]来实现很好的性能。但是当系统中数据维度急剧增加时,大多数方案中索引结构空间开销急剧增加,同时匹配效率大大降低,不具备处理高维稀疏数据的能力。本文在研究数据特征的基础上提出通过编码压缩降低数据存储开销,同时基于压缩后的数据进行快速的匹配处理,表现出良好的适应性。
2.基础数据模型
布尔表达式中的谓词:一个谓词由属性A,操作符以及操作数O组成。订阅条件S的布尔表达式由一系列谓词的合取组成:。为方便将订阅与布尔表达式等价转换,需要对范围操作符按一定粒度划分到多个离散取值情况当中。发布事件E:。
布尔表达式匹配:当任何出现在订阅S中的属性A都出现在事件E中,并且事件E中属性A的取值都满足订阅S中相应约束,则称订阅S与事件E匹配。给定一个订阅的集合和一个发布事件E,发布/订阅系统的匹配处理目标就是找到所有的满足的订阅S使得S与E匹配。
设,每个元素表示某属性和一个取值的复合变量,A表示整个属性取值空间。表示订阅条件向量。关系矩阵为订阅条件的布尔矩阵表达。为方便后续匹配处理,此处将订阅条件按谓词数量分组,每组再构建布尔矩阵。由此得到个布尔矩阵,表示所有订阅条件中谓词数量的最大值。
3.编码压缩
为降低上述高维稀疏布尔矩阵的存储开销,本文将矩阵中元素视为数据的二进制表达,每行元素按机器字长划分为组,每组编码为一个数据(表示为),同时不存储编码后为0的数据。该方案可将空间开销降低到原始矩阵空间开销的至少分之一。
4.索引结构
本文设计的索引结构主要分为两大部分:属性空间和编码列表。属性空间对应布尔矩阵中的A,A中每条记录指向编码列表中的一行数据。编码列表对应布尔矩阵的一行行数据,其中,。每个编码项中表示每组数据最左边订阅的id,表示编码后的数据。通过加偏移量即可还原出每个原始数据。
5.压缩感知匹配算法
给定上述索引结构,本文提出一个基于压缩感知的匹配算法。给定一个事件e和布尔索引(大小为,)。由布尔表达式匹配定义可知,当事件e的大小|e|小于订阅S的大小|S|时,不存在匹配。由于构造索引时对订阅按大小进行分组,所以可以首先筛选出的索引,再分两步进行匹配处理。
第一步,给定大小为的索引,对事件e中的多个,可以根据属性空间查找对应的编码列表,若找出的编码列表数量(第1行),则该事件e在当前索引中不存在匹配。否则进入第二步。
第二步,给定当前索引大小和第一步选出的个编码列表集合(表示为)。算法将遍历编码列表,利用快速的按位与或操作进行元素检测(第8-11行)并记录,最后输出一个由组成的集合S。S中的键值对可以解码并还原出压缩前成功匹配的订阅id。

整个算法的思路是:用一个有序列表H记录候选列表中的当前位置的编码项数据,将H中数据按排序,每次循环过程中,若到间的编码项数量不小于,就对这些编码项中的,分别判断第位上的元素1数量是否大于等于,若是则保存到最终结果S中。若数量低于(第7行),则将后移,进入下一次循环。
6.实验对比
为了验证本方案性能,决定与当前最新研究成果BETree[3],[4]进行对比。在同一台服务器上本文使用BE-Tree的数据生成器,通过调参生成发布事件和BE订阅数据。
大多数实际的pub/sub应用[5,3,4]都表明用户兴趣即系统中出现的订阅条件通常都会服从倾斜的幂律分布:一小部分属性和相关的取值在大量的订阅条件中会频繁出现;而大量属性和取值只会在少量订阅条件中出现。给定这样的数据分布,相关矩阵中元素1的分布同样偏斜。因此除了订阅数据总量,我们还将数据分布作为变量验证数据分布对实验结果的影响。
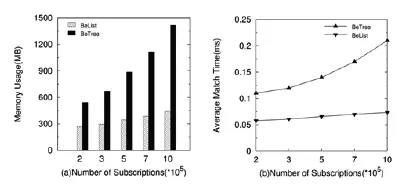
图1 订阅数量对空间和时间的影响趋势
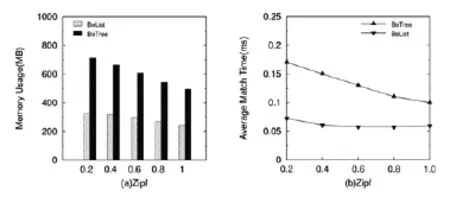
图2 参数对空间和时间的影响趋势
从图1中我们可以看到:随着订阅数量的增加二者都需要更多存储空间来存储索引结构,平均匹配时间也随需要处理的数据量增加而上升。从图2,我们可以看到随着参数增大,二者的储存空间都逐渐降低,匹配时间也依次减少,原因在于随着参数增大,数据分布变得更加紧密,索引结构开销和匹配处理开销都因此逐渐减低。需要注意的是,同等条件下本文方案性能都优于BE-Tree。
7.结论
本文针对发布/订阅系统中的高维稀疏数据,提出了有效的编码压缩方案降低索引结构空间开销,并在此基础上提出压缩感知的匹配算法实现高效匹配性能。后续将针对分布式环境中索引结构及算法进行研究。
[1]A.Machanavajjhala,E.Vee,M.N.Garofalakis,and J. Shanmugasundaram.Scalable ranked publish/subscribe.PVLDB, 1(1):451–462,2008.
[2]M.Sadoghi and H.Jacobsen. Be-tree: an index structure to efficiently match boolean expressions over high-dimensional discrete space. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2011, Athens, Greece, June 12-16,2011,pages 637–648,2011.
[3]M.Sadoghi and H.Jacobsen. Analysis and optimization for Boolean expression indexing. ACM Trans. Database Syst., 38(2):8, 2013.
[4]S.Whang,C.Brower,J.Shanmugasundaram,S.Vassilvitskii, E.Vee, R.Yerneni,and H.Garcia-Molina. Indexing boolean expressions.PVLDB, 2(1):37–48, 2009.
[5]H.Liu,V.Ramasubramanian, and E. G.Sirer. Client behavior and feed characteristics of rss, a publish-subscribe system for web micronews.In Internet Measurment Conference, pages 29–34,2005.
[6]S.Bianchi,P.Felber,M.Gradinariu Potop-Butucaru: Stabilizing Distributed R-Trees for Peer-to-Peer Content Routing. IEEE Trans. Parallel Distributed System (TPDS) 21(8): 1175-1187 (2010).
[7]A.Riabov,Z.Liu,JL.Wolf, PS.Yu,L Zhang:New Algorithms for Content-Based Publication-Subscription Systems. ICDCS 2003: 678-686.
[8]W.Rao,L.Chen,Ada WC.Fu,H.Chen,F.Zou:On Efficient Content Matching in Distributed Pub/Sub Systems.INFOCOM 2009:756-764.
