一种改进K—means聚类算法的MapReduce并行化实现
2017-04-15栗国保韩青菊
栗国保++韩青菊


摘要:针对K-means聚类算法对初始聚类中心点的选择较敏感的问题,本文借鉴最大最小距离的思想,提出了一种改进的K-means聚类算法。该算法通过优化初始聚类中心点来减少算法的迭代次数,提高聚类的性能。采用MapReduce编程模型,将改进的K-means聚类算法并行化设计,使用局部和全局的方法处理数据集,改变了传统分布式K-means聚类算法的工作方式,有效的降低了算法执行过程中的通信开销。实验结果表明改进K-means算法的并行化实现具有良好的加速比。
关键词:MapReduce模型 K-means 分布式聚类
中图分类号:TP301 文献标识码:A 文章编号:1007-9416(2016)12-0134-01
1 引言
聚类分析是一种无监督的机器学习方法,不需要预先对数据集进行训练和测试等操作,是数据挖掘中对数据进行分析处理的重要工具和方法[1]。由于聚类分析算法的简单、高效和易用等特点,其应用范围十分广泛,针对各个领域的聚类算法也不尽相同。其中K-means聚类算法是聚类分析算法中最典型的算法,该算法的优点是简单且易于实现,但随着信息产业的快速发展,需处理数据的规模越来越大,其串行计算的处理能力的局限性更加明显,于是分布式聚类的思想被广泛关注[2-3]。但现有的分布式聚类算法在聚类过程中大多数需传递大量的数据,效率较低。为克服上述缺点,本文使用MapReduce编程模型实现了一种改进K-means算法的分布式聚类。该算法在执行过程中只需要传递各个聚簇信息,就能实现分布式聚类,降低了整个执行过程的通信开销。
2 K-means聚类算法的MapReduce并行化
2.1 算法基本思想
从K-means聚类算法的特点不难看出,其并行化也是一个不断迭代的计算算法,每次迭代都需要消耗大量的时间和通信量,所以本文对K-means聚类算法在初始中心点的确定上进行了改进,借鉴最大最小距离的思想计算出初次聚类的中心点,避免了该算法在随机选择中心点时中心点过于邻近的情况发生,也降低了并行算法的迭代次数。同时,根据MapReduce模型的特点,在算法执行的Map端,使用Combiner类对Map端生成的相同簇ID的数据点信息进行归并,减少了从Map端向Reduce端传输的数据量,从而降低了传输开销。
2.2 算法描述
输入:数据集,聚类中心点个数
输出:个聚类中心点
将原始数据集切块后,存储在HDFS中,Hadoop负责管理切分后的数据块。
Stage1.初始聚类中心的计算。
1)各个Map节点读取存放在本地的数据集,采用最大最小距离算法生成多个聚类集合。
2)在Reduce阶段将Map阶段生成的若干聚类集合采用K-means聚类算法生成个聚类中心点。
3)将生成的聚类中心点信息写入cluster目录中,并将该目录中的文件加入到Hadoop的分布式缓存(DistributedCache)中用来作为下一阶段聚类迭代时的全局共享信息。
Stage2.K-means算法的MapReduce实现。
1)每个Map节点在setup()方法中读入分布式缓存中上一轮迭代产生的簇中心信息。
2)通过Map方法计算每个数据点与各簇中心点距离,找到离其最近的簇中心点,将该簇中心的ID作为key,该数据点信息作为value传输出去。
3)在Map端利用Combiner类将每个Map节点的相同簇ID的键值对分别进行合并,以此减轻数据的网络传输开销。
5)若最近两次临时中心点的变化小于指定值时,则转6),否则转1)。
6)结束。
3 实验结果与分析
3.1 实验环境
该实验利用VMware Workstation虚拟机,在其上虚拟出6台机器,1台作为NameNode和JobTracker服务节点,其他5台作为DataNode和TaskTracker服务节点,每台机器的配置为:Intel i3双核处理器,内存1G,操作系统是CentOS 6.4,Hadoop版本是0.20.2。
3.2单机处理实验分析
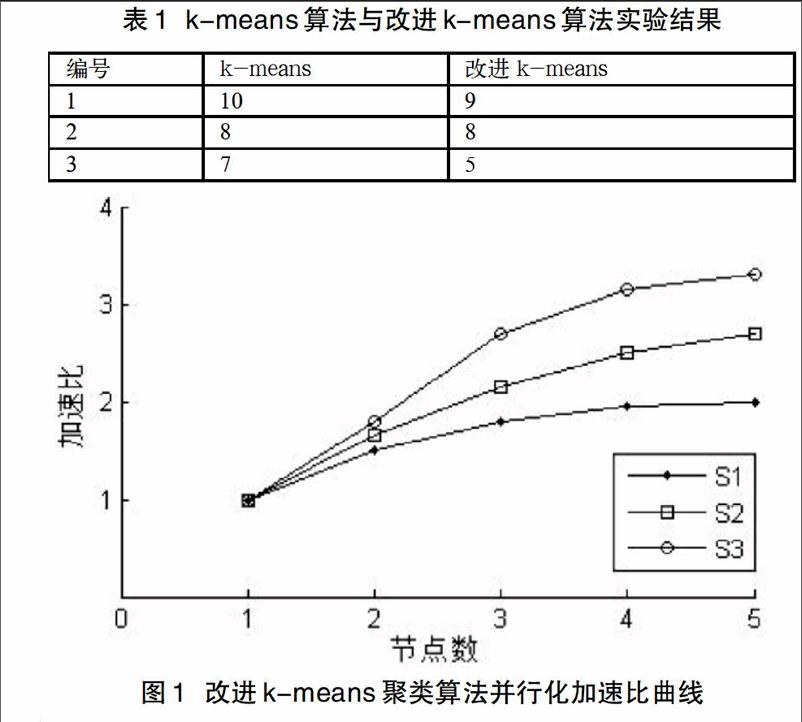
本实验使用UCI机器学习库上的OULAD数据集,由于该数据集数据量大,故从中抽取3组数据作为独立的数据集,编号分别为1、2、3,每个数据集包含2000条记录。在相同数据集的条件下,比较K-means和本文改进算法的迭代次数,实验数据如表1所示。从表中可看出,本文改进的聚类算法较传统K-means聚类算法有更好的收敛速度。
3.3 集群加速比性能实验分析
加速比是用来衡量并行系统或并行程序扩展性的重要指标[4],是指一个任务在单处理器系统中运行所消耗的时间与并行处理系统中运行所消耗时间的比值。通过程序生成S1、S2、S3三个实验数据集,其数据量大小分别为:1G、2G、4G,利用改进算法的MapReduce实现对每个数据集进行聚类,分别选择1、2、3、4、5个TaskTracker节点参与实验,考察节点数与加速比之间的关系。实验结果如图1所示,从图1可以看出:当节点数逐渐增加时,加速比也随之增加,但逐渐变慢,这是由于增加节点导致通信开销变大;当数据量逐渐增大时,加速比的值也逐渐增大,这表明该并行算法在处理大数据集时,具有较高的效率。该实验数据表明本文改进的聚类算法在MapReduce 上执行具有良好的加速比。
4 结语
本文借鉴最大最小距离算法的思想,改进了K-means聚类算法存在对初始聚类中心点的选择敏感的缺陷,为提高改进算法的计算效率,将该改进算法并行化设计,使其能够较好的运行在Hadoop平台上。实验表明该改进算法的并行化设计具有较好的聚类性能。
参考文献
[1]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[2]宋玲,戚云枫,齐东阳.分布式k-means聚類算法的改进[J].广西大学学报(自然科学版),2014(5):1060-1065.
[3]王恺.基于MapReduce的聚类算法并行化研究[D].南京师范大学,2014.
[4]江小平,李成华,向文,等.k-means聚类算法的MapReduce并行化实现[J].华中科技大学学报(自然科学版), 2011,39(s1):120-124.
