不平衡数据集的混合采样方法
2017-04-15尚旭
尚旭

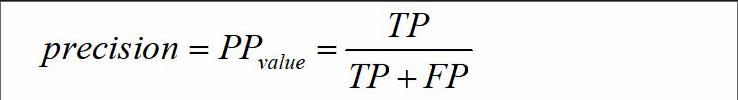
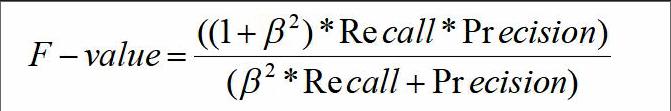
摘要:不平衡数据集中,由于某类别数量的不平衡,使得类别数量少的容易被误分,导致其分类准确率不高。处理不平衡數据集的方法,可以分为算法方面和数据方面,在数据方面中,主要分为两种方法:过采样和欠采样,但是对于将这两种方法结合的研究不是很多,过采样和欠采样都具有一定的优势,因此设想将这两种方法结合起来,希望可以找到更好的方法。提出两种混合采样方法:Random-SMOTE+ENN和Random-SMOTE+TNS,并与几种典型的抽样方法在数据集上进行实验对比,实验结果表明提出的两种方法是可行有效的。
关键词:不平衡数据集 过采样 欠采样
中图分类号:TP181 文献标识码:A 文章编号:1007-9416(2016)12-0068-04
引言
不平衡数据集[1-2]是指在一个数据集中,有些类别的样本数量很多,有些类别的样本数量很少,这就形成了数据集各类别样本的不均衡,一般称样本数量少的一类为少数类,有时也可称为正类,样本数量多的一类为多数类,有时也称为负类[3]。在许多不平衡数据集的实际分类中,样本数量少的一类往往对分类来说更重要。在现实生活中,存在着许多数据不平衡的例子,如医疗诊断[4],垃圾信息的识别,客户信誉识别[5]。例如在医疗诊断中,一个没有病的人被医生诊断为有病,这会使人承受精神的压力,然而假如医生把一个有病的患者诊断为没有病可能就会耽误治疗,有可能会危及病人的生命。正如这些实例,少类数据所拥有的信息往往是所需要的,因此怎样能在分类过程中正确识别这些数据是应该关注和解决的问题。
目前,已经有很多这方面的处理方法[6]可以从两方面考虑:算法方面和数据处理方面。算法方面就是不断完善已有的算法和提出新的分类算法[7],如代价敏感学习、Bagging算法[8]等。数据方面的方法有两种[9]:过采样方法和欠采样方法[10-11]。常用的采样方法是随机过采样、随机欠采样、Tomeklinks[12]、压缩最近邻(CNN)[13]、邻域清理(NCL)[14]、(Synthetic Minority Over-Sampling Techique)SMOTE[15]、Borderline-Smote(BSM)[16]、one-sided selection(OSS)[17]等,还有一些组合算法,如Gustavo[18]等人提出的SMOTE+ENN和SMOTE+Tomeklink。
文中主要研究了过采样和欠采样相结合的方法,分别将过采样方法Random-SMOTE和欠采样ENN方法、(Total under sampling)TNS方法结合,即Random-SMOTE+ENN方法和Random-SMOTE+TNS方法。将过采样和欠采样这两种方法相结合是因为在样本数较少的数据集,这两种方法都有不足,过采样或欠采样的效果不好,过采样会使样本数据集的少数类过拟合,而欠采样方法会丢许多样本的信息,组合方法能够有效的解决这两种问题,其次,已经有人研究过将这两种采样方法结合,实验结果表现出良好的效果,最后,这几种方法在单独执行时就表现出了较好的效果,所以将这两种采样方法组合起来,希望会使不平衡数据集的分类效果好。
在预处理阶段采用了6种采样方法,其中包括文章提出的两种对不平衡数据预处理的方法,在选取的9种不同程度数据集上进行预处理及分类实验,最后给出6种采样方法预处理后的分类结果以及实验结论。
1 相关介绍
目前,在已有的处理不平衡数据分类问题的数据处理方法有两方面,一方面是过采样方法,另一方面欠采样方法。随机过采样是对少数类样本进行复制,这会引起样本数据的重叠和过拟合现象,而随机欠采样方法,是随机的删除一些多数类的数据,使各类别的样本数量平衡,然而这会使一些重要样本数据信息丢失,会影响分类时的判断。2002年Chawla N V等人提出了一种启发式方法:(Synthetic Minority Over-Sampling Techique)SMOTE,这种方法与随机过采样方法不同,人为的在同类近邻样本间线性插值来生成新的样本,有效的解决了数据重叠现象。针对SMOTE方法的提出,研究者们对SMOTE进行了许多的改进工作,取得了非常好的效果。
下面介绍几种采样方法:
1.1 SMOTE
SMOTE方法的基本思路是在近邻少数类样本之间进行线性插值,合成新的少数类样本。具体方案是:对数据集中少数类的每一个样本寻找其(通常取5)个同类最近邻样本,根据采样倍率,在其个同类最近邻样本中随机选择个同类样本,记作,在少数类样本,之间连线上进行随机线性插值,生成少数类样本。
其中 是(0,1)内一个随机数,表示为新的生成的样本。
1.2 (edited nearest neighbor)ENN
ENN[19]的基本意思是若样本的3个最近邻样本中2个或以上的样本类别和它不一样,则删除此样本。ENN方法是一种欠采样算法,首先搜索多数类样本的3个最近邻样本,若该样本的3个最近邻样本中有两个或以上和该样本类别不一样则删除这个样本,此算法意在删除多数类样本,然而多数类样本附近往往都是多数类样本,因此ENN去掉的样本非常有限的。
1.3 (Neighborhood Cleaning Rule)NCL
NCL方法是在ENN方法的基础上提出的,以能够删除更多的多数类样本。其基本方案如下:对训练集中的每个样本找出它的最近邻的3个样本,若该样本是多数类,且3个最近邻样本中有2个或以上与其类别不一样,则删除;若属于少数类,且3个最近邻样本中有2个或以上与其类别不同,则删除3个最近邻样本中的多数类样本。
1.4 Random-SMOTE
Random-SMOTE[20]采样方法的基本思想是:对于每个少数类样本,找其个同类最近邻样本,从最近邻少数类样本集中随机选出两个样本、;以、、三点围成一个三角形区域;若向上采样倍率在该三角形区域内随机生成个新的少数类样本。
生成新的少数类样本具体步骤如下:
a)在两个最近邻样本、之间生成个临时样本
b)然后在臨时样本之间进行随机线性插值,生成新的少数类样本
其中:其中表示为(0,1)内一个随机数。
以上是基于数据采样的几种处理不平衡数据的基本方法,近几年研究者们在这些方法的基础上提出了新的处理方法。如Gustaro等人将提出了两种组合方法:SMOTE+Tomeklink和SMOTE+ENN方法,取得了不错的效果,但对于其他的算法组合研究的很少,所以文章就Random-SMOTE与ENN和TNS组合并验证此方法的可行性,通过研究工作发现将过采样和欠采样结合是可行的有意义的。
文中提出的两种组合方法Random-SMOTE+ENN:首先利用Random-SMOTE对少数类样本进行过采样,然后利用ENN方法对多数类数据进行欠采样处理,Random-SMOTE+TNS:首先利用Random-SMOTE对少数类数据进行过采样,然后对少数类样本和多数类样本均实行欠采样处理,方法:对数据集中的每个样本,寻找其最近邻的3个样本,比较若3个最近邻样本中有两个或以上的样本和该样本的类别不同,则删除该样本,称之为Total under sampling(TNS)。并且通过实验和其他几种方法对比验证文中提出的方法是有效的。
2 评价标准度量
评价标准对分类器的性能好坏和指导分类器做出判断有着重要的作用。对于不平衡数据分类来说,常用评价标准包括ROC曲线、基于混淆矩阵的若干度量,如查全率、查准率、和等。
在两分类的情形下。将少数类称为正类。多数类称为负类。经过分类以后,数据的分类为混淆矩阵中表示的4种情况[21](见表1)。
利用混淆矩阵,可以派生出以下度量:
在信息检索领域,将真实正类率定义为查全率,表示在检索到的相关对象所占的比例:
将正类预测值定义为查准率,表示相关对象占检索出的所有对象的比例:
另一种评价标准是查全率和查准率的调和均值:
上式中,表示和之间的相对重要程度,大于1时表示更重要,小于1时表示更重要。通常为1,表示两者都重要。
是一个衡量整体分类性能的评价指标,为少数类的分类精度, 是多数类的分类精度,只有当二者的值都大时,的值才会大,因此,能衡量不平衡数据集的整体分类性能。
3 仿真实验
3.1 数据集
实验验证的数据集来自UCI数据库中的9个数据集,每个数据集的基本信息如表2所示。
3.2 实验结果分析
不平衡数据的分类学习中,标准的分类精度准则不适合评估不平衡数据集的分类效果,本实验选取F-value准则,G-mean准则和少数类的分类准确率acc+来对实验结果综合分析。
在实验中,选择了近邻算法作为分类算法,然后对选取6种不同的采样方法进行实验对比,分别是:随机过采样、SMOTE、Random-SMOTE、SMOTE+ENN、Random-SMOTE+ENN、Random-SMOTE+TNS,上述不平衡分类方法所使用近邻算法的近邻选取5,在各个数据集上所有采样方法所设置的采样率相同,为实验客观公正,实验通过五折交叉验证得到实验结果。
表3、表4列出个不平衡分类方法在9个UCI数据集上的G-mean和F-value值。
从表3、表4给出的F-value值和G-mean值可以看出,对于组合方法的分类效果在大多数数据集上优于过采样方法的分类效果,尤其在于不平衡度较小的数据集上组合方法的效果更明显,组合方法先通过过采样对于少类数据处理,然后对于多类数据进行欠采样处理,不仅增加了少类数据数目,而且尽可能的删除处于边界的多类数据,大大提高了少类分类正确率,分类效果明显更好。文中提出的两种分类方法也具有很好的分类效果,其中Random-smote+TNS的分类效果在9个数据集上的表现均好于其他几种分类方法的表现。另一种组合方法Random-SMOTE+ENN的分类效果低于SMOTE+ENN的分类效果,但和其他三种方法分类效果对比具有一定的优势,只在数据集glass-I比SMOTE和Random-SMOTE低,在数据集Balance-II上比随机过采样低。文中提出的分类方法分类效果良好。
不平衡数据集中,少数类往往是我们感兴趣的类别,因此对于少数类的分类准确率acc+是衡量不平衡分类性能的重要指标,图1给出了各采样方法的acc+图,由图可知,除了数据集Feritilty和Balance-II上,Random-smote+TNS的acc+值低于随机过采样,在其他数据集上Random-smote+TNS的acc+值均大于其他采样方法,特别在Pima数据集和blood数据上,acc+值明显高于其他采样方法。另一种组合方法Random-smote+ENN的acc+和Somte+ENN表现持平,但好于过采样方法Random-smote,可见组合方法的分类率好于单纯的过采样方法。从整个实验数据的分析得出文中的两种组合方法是可行有效的。
4 结语
文章通过在多个数据上使用多种数据采样方法,进行仿真实验对比得到两种较好混合采样方法和有效的结果,通过实验数据分析得出这两种混合采样方法在试验中大多数据集上具有良好的分类效果,然而也可以看出所提出的方法并不是在所有的数据集上具有好的效果。其次,没有研究其他采样方法组合的合理性,希望在下一步研究中能将过采样和欠采样方法进行不同的组合尝试,希望能够找到更好的处理方法在保证整体正确率的前提下提高少数类的分类正确率。
参考文献
[1]Han Jiawei, KAMBER M.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版,2001.
[2]杨明,尹军梅,吉银林.不平衡数据分类方法综述[J].南京师范大学学报:工程技术版,2008,8(4):7-12.
[3]Paolo S. A multi-objective optimization approach for class imbalance learning [J]. Pattern Recognition, 2011, 44(8):1801-1810.
[4]Li DC,Liu CW,Susan CH.A learning method for the class imbalance problem with medical data sets [J]. Computers in biology and medicine, 2010, 40(5):509-518.
[5]徐丽丽,闫德勤,高晴.基于聚类欠采样的极端学习机[J].微型机与应用,2015(17):81-84.
[6]王和勇,范泓坤,姚正安,等.不平衡数据集分类方法研究[J]计算机应用研究,2008,25(5):1301-1308.
[7]胡小生,张润晶,钟勇.一种基于聚类提升的不平衡数据分类算法[J].集成技术,2014(2):35-41.
[8]李明方,张华祥.针对不平衡数据的Bagging改进算法[J].计算机工程应用,2013,49(2):40-42.
[9]吴磊,房斌,刁丽萍,等.融合过抽样和欠抽样的不平衡数据重抽样方法[J].计算机工程与应用,2013,49(21):172-176.
[10]丁福利,孙立民.处理不平衡样本集的欠采样算法[J].计算机工程与设计,2013,34(12):4345-4350.
[11]林舒杨,李翠华,江戈,等.不平衡数据的降采样方法研究[J].计算机研究与发展,2011,48(2):47-53.
[12]TOMEK I. Two modifications of CNN[J].IEEE Trans on Systems, Man and Communications, 1976, 6:769-772.
[13]HART P E. The condensed nearest neighbor rule[J]. IEEE Trans on Information Theory, 1968,14(3):515-516.
[14]LAURIKKALA J. Improving identification of difficult small classes by balancing class distribution[C]. Proc of the 8th Conference on AI in Medicine. Europe, Artificial Intelligence Medicine, 2001:63-66.
[15]Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic Minority Over-sampling Technique[J]. Journal of Artificial Intelligence Research, 2002, 16:321-357.
[16]Han H, Want W Y, Mao B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C]//LNCS 3644:ICIC 2005,Part I,2005:878-887.
[17]KUBAT M, MATWIN S. Addressing the course of imbalanced training sets: one-sided selection[C]. Proc of the 14th International Conference on Machine learning. San Francisco, Morgan Kaufmann, 1997:179-186.
[18]Gustavo E A, Batista P A, Ronaldo C,et al A study of the behavior of several methods for balancing machine learning training data[J]. SIGKDD Explorations, 2004,6(1):20-29.
[19]WISON D L. Asymptotic properties of nearest neighbor rules using edited data [J].IEEE Trans on Systems, Man and Communications, 1972,2(3):408-421.
[20]Dong Yanjie,WangXuehua. A new over-sampling approach:Random-SMOTE for learning from imbalanced data sets [C]//LNCS 7091: Proceedings of the 5th International Conference on Knowledge Science, Engineering and Management(KSEM11). Berlin,Heidelberg:Springer-Verlag 2011:343-352.
[21]董元方,李雄飛,李军.一种不平衡数据渐进学习算法[J].计算机工程,2010,36(24):161-163.
