面向中文微博命名实体识别的对比研究
2017-04-13朱颢东杨立志丁温雪冯嘉美
朱颢东,杨立志,丁温雪,冯嘉美
(郑州轻工业学院计算机与通信工程学院,河南郑州450002)
面向中文微博命名实体识别的对比研究
朱颢东,杨立志,丁温雪,冯嘉美
(郑州轻工业学院计算机与通信工程学院,河南郑州450002)
命名实体识别是自然语言处理的重要基础,同时也是信息抽取,机器翻译等应用的关键技术.近年来,网络媒体微博的迅速发展,为命名实体识别研究提供了全新的载体.针对中文微博文本短、表达不清、网络化严重等特点,对目前命名实体识别两种应用比较广泛的方法,基于最大熵模型的识别方法和基于条件随机场模型的识别,进行对比研究.在真实的微博数据上进行对比实验.通过实验结果的对比得出这两种方法在中文微博命名实体识别上的优缺点.
命名实体;最大熵;条件随机场
随着现代社会信息化的迅速发展,信息处理已经变得非常重要.在互联网中,语言文本是信息的基本表现形式.而命名实体是语言文本信息的基本组成元素,是信息的主要载体.命名实体是指识文本中以名称为标识的实体名词,主要包括人名,地方名,组织名,时间等名词.命名实体的识别是指对命名实体进行筛选并加以分类.命名实体识别是多领域发展和研究的基础,如信息抽取和机器翻译等.因此,命名实体识别的发展关系着其他领域的进步与发展.
目前,国内外对命名实体识别的研究已趋于成熟,主要是针对正式文本.但是随着社交网络的发展,微博已成为新的信息载体,而国内外针对微博文本的命名实体识别研究还处于起步阶段,尤其是中文微博(如新浪、QQ等).美国的Twitter是互联网的第一家微博平台,自2006年上线以来受到了许多网民的青睐.随后国内各大互联网公司也相继推出了各自的中文微博平台,其中最具代表性的是新浪微博(weibo.com).早在2013年,新浪微博的注册用户已经超过5亿,最新统计,2015年第四季度新浪微博月活跃用户达到2.36亿,日活跃用户达到1.06亿,每天产生的微博文本达上亿条[1].由于微博的即时性,信息在微博上的传播速度较快,与人们的日常生活息息相关.因此,对微博文本内容进行命名实体识别,从而挖掘出社交网络中包含的重要信息是一项很有意义的研究.
与其他正式文本(如新闻、公告等)相比,微博具有其独有的结构与特点.每条微博文本的长度限制在140字以内,据相关统计,每条微博文本的平均长度约为50字.由于微博的原创性和无标准性,在表达形式上较为随意,表达不清楚,口语化,网络化较为严重.这些特点与结构使得微博命名实体识别更加的困难.
因此,本文为了去除这些结构和特点为研究带来的困难,在中科院汉语分词系统ICTCLAS 2016的分词基础上,对微博数据进行规范化处理,选取合适的特征,分别应用最大熵模型和条件随机场模型进行中文微博命名实体识别,对分析结果进行对比研究.
1 相关工作
MUC-6(第六届Message Understanding Conference)在1996年第一次提出将命名实体识别作为信息抽取的一个子任务[2].随后在众多国际会议上,命名实体识别都作为其中一项重要的指定任务被广泛提及[3].目前,对于传统文本的识别研究已经较为成熟,国内外的研究方法主要分为三类:以ANNIE系统、FACILE系统、OKI系统等为代表的基于规则的方法[4],以马尔科夫模型(Hidden Markov Models,HMM)[5]、最大熵马尔科夫模型(Maximum Entropy Markov Models,MEMM)、n元模型、决策树[6-8]等为代表基于统计的方法,规则与统计相结合的方法[9-11].基于规则的方法往往依赖于具体语言,领域和文本风格,系统可移植性差,代价较大[12-13].基于统计的方法的性能比基于规则的方法低,且对语料库的依赖较大[14].规则与统计相结合的方法是目前使用较多,性能也较为理想[15].
2 微博命名实体识别方法
2.1 最大熵模型的定义
假设训练数据集是由n个(x,y)数据组成的数据集合,对于命名实体来说,x代表输入序列,一般表示文本的字或者词语等,y代表的是标注类别.数据集分布如下所示:
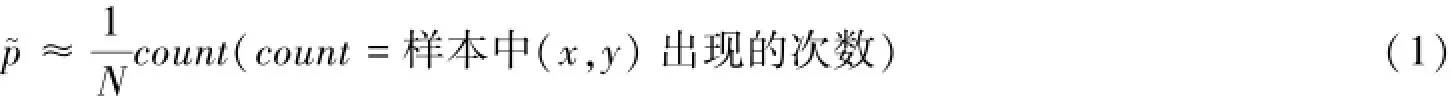
式(1)表示将n个(x,y)组成的数据集作为训练样本,从而建立模型.f(x,y)为一个二值特征函数,取值为0或者1,在文本对比研究中,选取词性为特征.N个特征函数的期望分布如下:

特征的经验概率为:

对每个特征都进行一定的条件限制,期望概率和经验概率相等.若要选取最优的p(y x )值,就需要选择熵值最大的表达式:
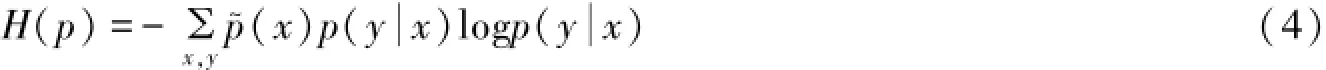
最大熵模型就是在所有满足限制条件的模型中,选取熵最大的那个,即:

2.2 条件随机场模型
设G=(V,E)是一个无向图,Y={Yv|v∈V}是以G中节点v为索引的随机变量Yv构成的集合.在已知X的条件下,如果每个随机变量Yv具有马尔可夫属性(离目标元素比较远的元素对目标元素的性质影响可以忽略),即P(Yv|X,Yu,u≠v)=P(Yv|X,Yu,u~v),其中u~v表示两个定点之间有连接边,则(X,Y)就构成一个条件随机场.最常用且最简单的CRF是一阶链式结构,即线性结构(Linear-chain CRFs),如图1所示.
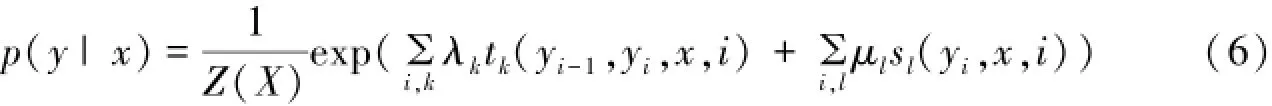
其中:
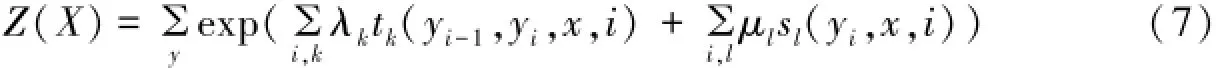
式(6)表示给定给定观察序列x,对状态序列Y的条件概率,式(7)为规范化因子.两式中tk(yi-1,yi,x,i)是序列i-1和i之间的特征转移函数,sl(yi,x,i)是观察序列i位置的状态特征函数,λk和μl是通过参数估计确定的参数.
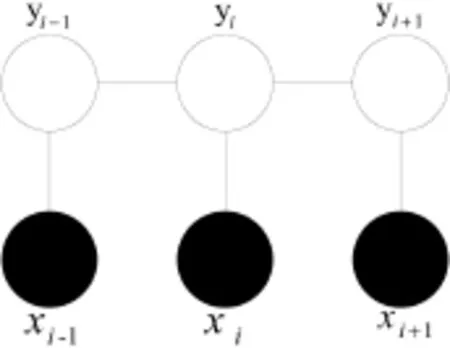
图1 线性结构的CRF模型图Fig.1 Linear structure of CRF
3 实验
3.1 实验语料
1)北京大学收集并且已标注过的1998年1月的《人名日报》语料库,该部分语料主要用于提取指示词和常用组织名,生成相对应的数据字典,不参与本文的模型训练.
2)新浪微博数据.本文使用的实验数据是新浪微博2014-05-03至2014-05-11的84168条微博数据.由于数据量较大,为避免微博之间由于发布时间过近而造成某些实体重复率过高,故从收集的数据中,按照时间平均的选取8000条微博数据.首先使用中科院的ICTCLAS2016系统进行分词和词性标注,然后人工标注微博语料的实体信息.
3.2 特征模板的选取
为了充分反映语言文本规律,可以通过选取合适的特征模板来建立模型.通过特征可以对特征进行配置,得到特征函数.选取合适的特征模板,对试验的识别率非常的重要.针对微博命名实体识别任务,本文选取的特征模板如图2所示.括号中的数字表示与当前词的距离,负数表示在目标词的左侧,正数表示目标词的右侧.
3.3 评价标准
命名实体识别的评价指标主要有准确率Pr(Precision)、召回率Re(Recall).为了防止准确率和召回率的片面性,还采用F值(F-Measure)进行评价,F值综合了准确率和召回率.三者在命名实体识别中的具体定义如下:

3.4 实验结果及对比分析
3.4.1 基于最大熵模型的微博命名实体识别.利用最大熵模型,对微博预料分别进行训练和测试,得到的命名实体识别结果,如表1所示.
3.4.2 基于CRF模型的微博命名实体识别.对微博文本数据利用条件随机场模型进行试验,实验结果如表2所示.
3.4.3 对比分析.由表1和表2的实验结果对比分析可知,CRF模型在中文微博数据上的命名实体识别效果均高于最大熵模型.所以,在未来对中文微博数据的命名实体识别研究中,可优先选择条件随机场模型,再在其识别基础上进行改进优化,从而达到希望的效果.

图2 特征模板Fig.2 Feature template
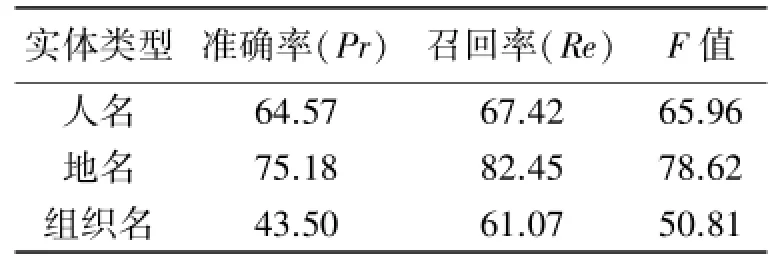
表1 最大熵模型实验结果%Tab.1 Result of Maximum Entropy%
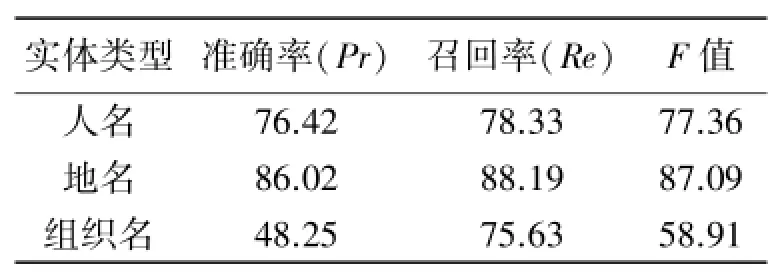
表2 条件随机场实验结果%Tab.2 Result of CRF%
4 结束语
本文对目前命名实体识别方面应用较为广泛的两种识别方法,基于最大熵模型和基于条件随机场模型,分别在中文微博文本上进行试验.在对数据进行规范化处理后,选取相同的特征模板,对试验结果进行分析对比,从而得出结论.但是由于中文微博的特殊性,两种方法对组织名的识别率都远不如任命和地名,还有着较大的研究空间,因此,将来的重点研究方向应该偏向于提高组织名的识别率.
参考文献:
[1] 第37次中国互联网络发展状况统计报告[R].北京:中国互联网络信息中心,2016.
[2] 刘建晶.基于新浪微博开放平台的iPhone手机SDK的研究[D].厦门:厦门大学,2012.
[3] 郭家清.基于条件随机场的命名实体识别研究[D].沈阳:沈阳航空工业学院,2007.
[4] AARON L,DEREK F.Chinese Named Entity Recognition with Conditional Random Fields in the Light of Chinese Characteristics[M].Berlin: Springer,2013.
[5] 陆铭,康雨洁,俞能海.简约语法规则和最大熵模型相结合的混合实体识别[J].小型微型计算机系统,2012,33(3):537-541.
[6] 张晓艳,王挺,陈火旺.命名实体识别研究[J].计算机科学,2005,32(4):44-48.
[7] EkT,KIRKEGAARD C,JONSSONH,et al.Named entity recognition for short text messages[J].Procedia-Social and Behavioral Sciences,2011,27 (5):178-187.
[8] 尚志刚.基于自然语言理解的中文自动问答系统研究[D].天津:天津工业大学,2007.
[9] LAFFERTY J,MCCALLUM A,PEREIRA F.Conditional random fields:probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 8th International Conference of Machine Learning,USA:IEEE,2001:282-289.
[10] 唐钊.条件随机场模型在中文人名识别中的研究与实现[J].现代计算机,2012,14(7):3-7.
[11] ZHANG Y,XUZ,ZHANG T.Fusion of Multiple Features for Chinese Named Entity Recognition Based on CRF Model[C]//Proceedings of 4th A-sia Infomation Retrieval Symposium,China:Haerbin,2008:95-106.
[12] 何静,郭进利.微博用户行为统计特性及其动力学分析[J].情报分析与研究,2013,7(1):21-23.
[13] 钮焱.基于马尔科夫模型的词序因子的文本相似度研究[D].武汉:湖北工业大学,2012.
[14] HAVELIWALA T H.Topic-sensitive pagerank:A context-sensitive ranking algorithm for web search[J].Knowledge and Data Engineering,2003,15(4):784-796.
[15] WENG J,LIM E P,JIANG J,et al.Twitterrank:finding topic-sensitive influential twitterers[C]//Proceedings of the third ACM international conference on Web search and data mining,ACM,2010:261-270.
责任编辑:高 山
Comparison of Named Entity Recognition for Chinese Microblogs
ZHU Haodong,YANG Lizhi,DING Wenxue,FENG Jiamei
(School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450002,China)
Named entity recognition is an important basis for natural language processing,and it is also the key technology of information extraction,machine translation and other applications.In recent years,the rapid development of network media micro-blogs provides a new carrier for the research of named entity recognition.Considering the Chinese micro-blog text is short,the expression is not clear,the networking trend is serious and so on,the paper,based on maximum entropy model and conditional random field model,contrasts two methods widely used in named entity recognition.The advantages and disadvantages of the two methods are compared through experiments.
named entity recognition;maximum entropy;conditional random fields(CRF)
TP301
A
1008-8423(2017)01-0019-04
10.13501/j.cnki.42-1569/n.2017.03.005
2016-12-06.
国家自然科学基金青年科学基金项目(61201447);河南省科技计划项目(152102210149,152102210357);河南省高等学校青年骨干教师资助计划项目(2014GGJS-084);河南省高等学校重点科研项目(16A520030);郑州轻工业学院校级青年骨干教师培养对象资助计划项目(XGGJS02);郑州轻工业学院博士科研基金项目(2010BSJJ038).
朱颢东(1980-),男,博士,副教授,主要从事智能信息处理、智能计算的研究.
