初始信息素筛选的蚁群优化算法在HDFS副本选择中的研究*
2017-04-12段效琛李英娜贾会玲赵振刚
段效琛, 李英娜, 贾会玲, 赵振刚, 李 川
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
初始信息素筛选的蚁群优化算法在HDFS副本选择中的研究*
段效琛, 李英娜, 贾会玲, 赵振刚, 李 川
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
随着社会信息化程度的不断提高,各种形式的数据急剧膨胀。HDFS成为解决海量数据存储问题的一个分布式文件系统,而副本技术是云存储系统的关键。提出了一种基于初始信息素筛选的蚁群优化算法(InitPh_ACO)的副本选择策略,通过将遗传算法(GA)与蚁群优化算法(ACO)算法相结合,将它们进行动态衔接。提出基于初始信息素筛选的ACO算法,既克服了ACO算法初始搜索速度慢,又充分利用GA的快速随机全局搜索能力。利用云计算仿真工具CloudSim来验证此策略的效果,结果表明:InitPh_ACO策略在作业执行时间、副本读取响应时间和副本负载均衡性三个方面的性能均优于基于ACO算法的副本选择策略和基于GA的副本选择策略。
Hadoop分布式文件系统(HDFS); 副本选择; 初始信息素筛选; 蚁群优化算法; 遗传算法
0 引 言
副本技术是云存储系统中的关键技术,它能大大减少传输延迟,提高数据访问和处理效率[1]。2012年,徐骁勇等人针对现有的副本选择策略无法根据环境的变化选择最合适副本这一问题,提出了一种综合考虑网络带宽、节点I/O性能以及节点存储空间等因素,基于灰色马尔可夫链预测模型的副本选择策略,以此在系统可用性和负载均衡性之间寻求一个平衡[2]。2015年,张雨等人针对云计算的编程模型框架,提出了一种融合遗传算法(GA)与蚁群优化(ant colony optimization,ACO)算法的混合调度算法,经实验证明,此算法是一种云计算环境下有效的任务调度算法[3]。
本文提出并实现了一种Hadoop分布式文件系统(HDFS)环境下的基于初始信息筛选的蚁群算法的副本选择策略,经过仿真验证,结果表明基于初始信息素筛选的ACO(InitPh_ACO)策略在作业执行时间、副本读取响应时间和副本负载均衡性3个方面的性能均优于ACO策略和GA策略。
1 基本原理
本文将GA与ACO算法两种算法结合使用,利用GA获得较优解组合,然后将其用于信息素的初始化工作,最后通过ACO算法获得最优解。这样使其求解最优解的效率优于GA,时间效率也好于ACO算法。而GA和ACO算法的衔接时间点变得尤为重要,本文参考了一种动态衔接方法,保证GA与ACO算法能够在最佳时间点进行衔接。具体实现方法如下:首先在GA中设定最大遗传迭代次数Genemax和最小遗传迭代次数Genemin;然后设定子代群体的最小进化率Genemin-impro-ratio,并在GA迭代的过程中统计子代群体的进化率;最后判断在设置的迭代次数的范围内,若GA连续迭代Genedie次,子代群体的进化率均小于最小进化率Genemin-impro-ratio,则表明GA在此时向最优解收敛的速度比较缓慢,此刻即是两种算法进行衔接的最佳时机。因此,可在此时结束GA的运行,开始ACO算法的相关操作;若迭代次数达到最大遗传迭代次数Genemax,则可在此时结束GA的运行,开始ACO算法的相关操作。
2 算法设计
GA运行终止后,获得若干组优化解,将该算法求解出的最优解用于信息素的初始化操作。采用GA获得了一些路径上的信息素浓度,故这里把信息素浓度初始化为
(1)
式中 Tj(O)为初始信息素浓度,Filesize为副本大小,r为磁盘的读取速度,TG为由遗传算法求解出的最优解所转换的信息素值,这里,TG=αf1(x)+(1-α)f3(x)。
本文采用ACO算法设计出一种Hadoop集群环境下的副本选择策略,对于客户端来说,信息素浓度越高副本越佳。副本的信息素浓度会随着情况的不同做出相应的改变,变化规律如下
Tnewi=ρ·Toldi+ΔTi
(2)

当副本的信息素浓度有所改变时,该副本被选择的概率也会随之增减,可利用式(3)计算每一个副本被选择的概率
(3)
式中 Ti(t)为副本所在节点i的当前信息素浓度;ηi为该节点的初始信息素浓度,α和β的值均设定为0.5。
为了使副本节点的负载情况保持平衡,这里将式(3)计算出的选择概率与该副本所在节点的负载完成率进行结合运算,使得每次被选中的副本节点不一定是选择概率最大的节点
(4)
式中 f,fmax分别为访问同一个数据节点上的相同数据副本的任务的个数和最大个数。
基于初始信息素筛选的ACO算法的副本选择流程图如图1所示。

图1 基于初始信息素筛选的ACO算法的副本选择流程图
3 副本选择策略仿真与评估
为了验证基于初始信息素筛选的ACO算法在HDFS中进行副本选择中的可行性和有效性,本文选用cloudsim-3.0作为仿真工具。仿真实验通过比较基于ACO算法的副本选择策略、基于GA的副本选择策略和本文提出的基于初始信息素筛选的ACO算法的副本选择策略来验证InitPh_ACO策略的有效性。
云应用程序在CloudSim 中仿真的流程如图2所示。
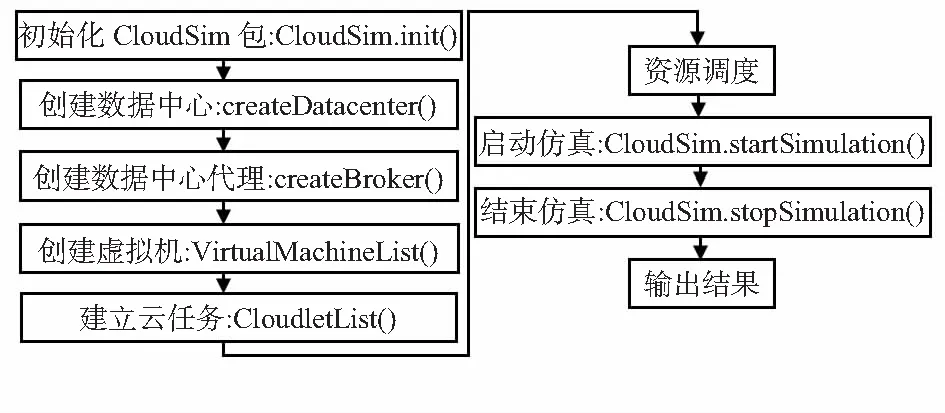
图2 CloudSim的仿真流程图
实验环境模拟客户端的访问请求是随机的,并且有100个存储能力均为90 GB的数据节点,网络带宽为1 000 Mbps,副本所在的数据节点的CPU、带宽、内存等资源的使用率通过随机函数获取,随机函数产生的数据为[0,1]之间的随机数。文件大小为128 MB。此外,数据块大小为64 MB,且副本数目为3。
图3所示的为本文所提出的InitPh_ACO策略与ACO策略、GA策略的作业执行时间对比图,作业的执行时间为当前作业数量下进行100次实验所得的作业执行时间的均值。
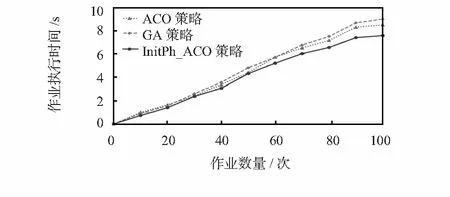
图3 作业执行时间对比图
从图3中可以看出,本文所提出的InitPh_ACO策略在作业执行时间上都优于其他两种副本选择策略,故本文所提出的InitPh_ACO策略在作业执行时间上性能更佳。
图4为某一客户端在本文所提出的InitPh_ACO策略、ACO策略和GA策略的副本读取响应时间方面的变化图。
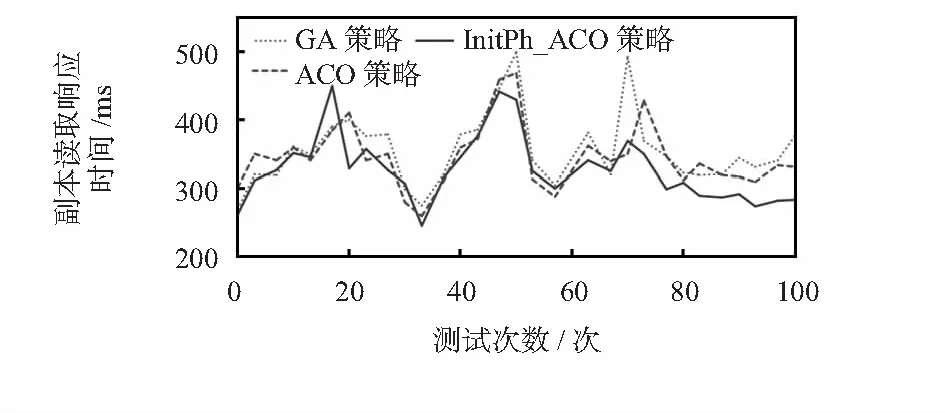
图4 副本读取响应时间变化图
从图4可以看出,采用InitPh_ACO策略的响应时间在读取操作的初始阶段的响应时间略微比其他两种策略的响应时间低些,但随着客户端对副本读取请求的增加,其响应时间基本趋于稳定,且显著比其他两种策略的响应时间短。因此,在系统可用性方面,InitPh_ACO策略比其他两种策略更有优势。
副本的负载是指副本所在的Datanode 接收客户端读取请求的次数,每隔10 min记录一次某个数据块的3个副本所在的DataNode节点在该10 min内的负载总量。测试2 h后,图5、图6、图7分别表示采用ACO策略、GA策略、InitPh_ACO策略的副本节点负载变化情况。再将100个数据节点的负载标准差作为系统负载均衡性评估的标准,每个作业数量所对应的负载标准差,是通过对100个数据节点进行反复测试100次所得副本负载标准差均值,然后通过计算获得全部的标准差均值,仿真结果如图8所示,为截取第100~1 000次作业区间的副本负载标准差曲线。
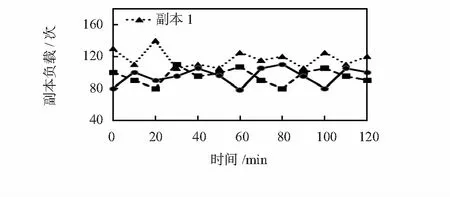
图5 采用ACO策略时副本负载情况

图6 采用GA策略时副本负载情况

图7 采用InitPh_ACO策略时副本负载情况
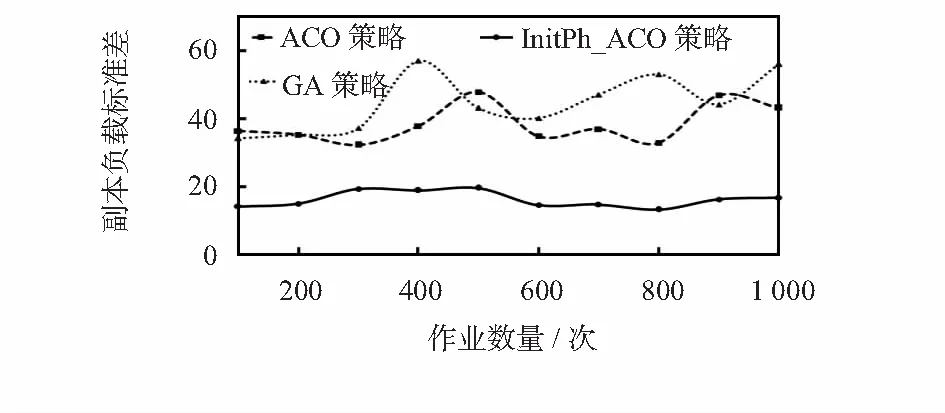
图8 副本负载标准差
从图8可以看出,采用ACO策略时副本的负载标准差在32~47.7范围内波动,副本的负载标准差均值为38.216;采用GA策略时副本的负载标准差在25.0~56.0范围内波动,副本负载标准差均值为42.6;而采用InitPh_ACO策略时副本的负载标准差在13.1~19.5范围内波动,副本负载标准差均值为16.121。由此可见,采用ACO策略和GA策略时副本负载标准差均值较大,且波动比较大,本文所提出的InitPh_ACO策略的副本标准差均值最小,且波动范围比较小。综合图5~图7的仿真结果可知,本文提出的InitPh_ACO策略在保持副本负载均衡性方面优于其他2种算法。
由以上3种算法的仿真结果可以看出:基于初始信息素筛选的ACO算法的副本选择策略在作业执行时间、系统可用性和负载平衡性等方面均具有显著的优势。
4 结 论
本文通过对ACO算法的副本选择策略和GA的选择策略进行比较分析,提出了初始信息素筛选的ACO算法的HDFS副本选择模型。并使用云计算仿真工具CloudSim验证该策略的效果,仿真结果证明:ACO策略、GA策略的副本选择性能相近,而新提出的InitPh_ACO策略在作业执行时间、副本读取响应时间和副本负载均衡性三个方面的性能均优于ACO策略和GA策略,初始信息素筛选的蚁群算法可以较为迅速地获得最佳副本,提高了系统的负载均衡性,增强了系统的整体性能。
[1] 张继平.云存储解析[M].北京:人民邮电出版社,2013.
[2] 徐骁勇,潘 郁,丁燕艳.基于灰色马尔可夫链预测模型的HDFS云存储副本选择策略[J] .计算机应用, 2012,31(A02):39-42.
[3] 张 雨,李 芳,周 涛.云计算环境下基于遗传蚁群算法的任务调度研究[J].计算机工程与应用,2014,50(6):51-55.
[4] 多传感器数据融合技术研究进展[J].传感器与微系统,2010,29(3):5-8,12.
[5] 樊宽刚,么晓康,苏建华,等.基于蚁群算法的WSNs节点有障环境中部署优化研究[J].传感器与微系统,2015,34(5):29-32,37.
[6] 左 方,何 欣.一种基于蚁群算法的云存储副本动态选择机制研究[J].计算机应用研究,2015,32(11):3368-3370,3374.
[7] Zhong H,Zhang Z,Zhang X.A dynamic replica management strategy based on data grid[C]∥The 9th International Confe-rence on Grid and Cooperative Computing,Najing,China:IEEE,2010:18-23.
[8] 蒋丽丽,陈国彬,张广泉,等.基于蚁群算法优化SA的WMN路由设计与仿真[J].传感器与微系统,2015,34(5):112-114,126.
[9] 柏小虎.云环境下基于用户请求响应时间的副本管理策略研究[D] .武汉:华中科技大学,2013.
[10] 张宁宁.异构环境下云计算数据副本动态管理研究[D].郑州:郑州大学,2013.
Research on ACO algorithm initial pheromone screening in HDFS copy selection*
DUAN Xiao-chen, LI Ying-na, JIA Hui-ling, ZHAO Zhen-gang, LI Chuan
(Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China)
With the degree of social information continues to improve,various forms of data expand rapidly.Hadoop distributed file system(HDFS)has become a distributed file system solving mass data storage problem,and a copy of the technical is the key of cloud storage system.Present a copy selection strategy foundation on ant colony optimization algorithm based on initial pheromone screening(InitPh_ACO)strategy,by combining genetic algorithm (GA) and ant colony algorithm,link them dynamically and propose ant colony algorithm based on initial screening of pheromone.This algorithm not only overcome shortage of slow initial search of ant colony algorithm,and make full use of fast stochastic global search capability of GA.Using cloud computing simulation tools CloudSim to verify the effect of this strategy,the results show that InitPh_ACO strategy are prior to the selection strategy replica ACO strategy algorithm and a copy of the selection strategy based on GA policy in three aspects of performance which are job execution time,response time and the copy of load balancing.
hadoop distributed file system(HDFS); replica selection; initial pheromone screening; ant colony optimization(ACO)algorithm; genetic algorithm(GA)
10.13873/J.1000—9787(2017)04—0031—03
2016—04—28
国家自然科学基金资助项目(51567013)
TP 391
A
1000—9787(2017)04—0031—03
段效琛(1990-),女,硕士研究生,主要研究方向为变压器及光纤光栅传感领域的研究。
李 川(1971-),男,通讯作者,教授,博士生导师,从事光纤Bragg光栅传感器的应用研究工作,E—mail:boatriver@eyou,com。
