基于GPU的Spark大数据技术在实验室的开发应用
2017-04-10周情涛胡昭华
周情涛, 何 军, 胡昭华
(南京信息工程大学 电子与信息工程学院, 南京 210044)
·计算机技术应用·
基于GPU的Spark大数据技术在实验室的开发应用
周情涛, 何 军, 胡昭华
(南京信息工程大学 电子与信息工程学院, 南京 210044)

在大数据时代,兼顾大数据处理与高性能计算是目前对计算机系统的迫切需求。针对Spark大数据处理与基于GPU的高性能计算,分析了基于GPU的Spark技术。它主要通过构建CPU和GPU的异构并行,使计算机获得强大的计算能力,并在实验室环境下探讨了Spark-GPU技术的实现,阐述了算法实现的技术流程。在此基础上,通过仿真实验评估了Spark和Spark-GPU技术的性能。实验表明,Spark-GPU技术可以达到上百倍的加速比,这对图像处理以及信息检索等领域的发展都具有重要推动作用。
大数据处理; 异构计算; 图形处理器
0 引 言
近年来,移动设备、无线传感器等设备每时每刻都在产生数据,要处理的数据量非常大,而业务需求对数据处理的实时性、有效性又提出了更高要求,传统的常规技术根本无法应付。大数据技术就是这个高科技时代的产物。大型数据分析经常需要将任务分发给若干台机器同步执行,所以它往往与分布式计算互相联系[1]。
目前分布式计算框架主要有Hadoop和Spark,新生的Spark是一个基于内存计算的开源集群计算系统,更适合于迭代的机器学习和数据挖掘算法,据述,Spark在内存中的计算速度可比Hadoop提升100倍[2]。然而当数据规模极其庞大时,数据处理速度会随之变慢,与此同时分子动力学、数学建模、图像处理等数据密集型应用对计算效率提出了更高的要求,显然Spark不能满足当前的实时性需求。 随着GPU的发展和CUDA的成熟,GPU并行计算已成为极其热门的领域。Spark和CUDA拥有天然的并行处理能力,如何在Spark平台整合CPU和GPU计算资源也很快成为热门话题。因此很多中外学者都在研究Spark-GPU技术,以充分利用GPU计算资源,提高计算效率[3]。
1 国内外现状
1.1 Spark技术
Apache Spark是当今热门的大数据处理框架,它兼容任何Hadoop的文件存储系统,可以使用Standalone、Hadoop YARN或Apache Mesos进行资源管理与作业调度,支持Scala,Java、Python和R 4种程序设计语言的编程接口。弹性分布数据集(RDD)是Spark的最核心概念,它表示已被分区、不可变的并能够被并行操作的数据集合,而且要求可序列化[4]。Spark可以将特定的RDD缓存到内存中,这样下一个操作可以直接读取内存中的数据,节省了大量磁盘I/O操作[5]。RDD还具有容错特性,用变换(Lineage)记录粗颗粒度的特定数据的转换(Transformation)和动作(Action)行为,当部分数据分区丢失时,通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒度的数据模型相比细颗粒度的数据模型带来了性能的提升[6]。
1.2 CUDA架构
基于CPU与GPU混合并行计算系统已经逐渐成为国内外高性能计算领域的热点研究方向,CUDA 是NVIDIA发明的基于NVIDIA GPU并行计算的架构,利用GPU的处理能力,可大幅提升计算性能[7-8]。它支持C、C++,以及 Fortran、Java、Python等多种语言开发。图1为CUDA编程模式下处理数据的流程图。
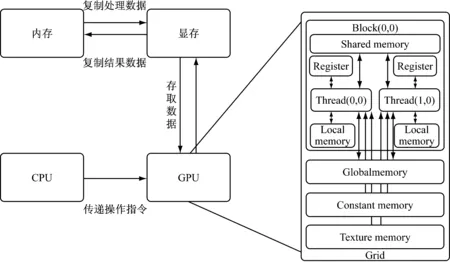
图1 CUDA架构工作流程
CUDA将CPU作为主机(Host),负责逻辑性较强的计算任务,将GPU作为设备(Device),负责高度线程化的并行处理任务。程序是由设备端的内核函数(Kernel)并行步骤和主机端的串行处理步骤组成,内核函数以网格(Grid)形式执行,网格由若干线程块(Block)组成,线程块由若干线程(Thread)组成。NVCC编译器可将程序分成在 GPU 上执行的部分及在CPU 上执行的部分,并对适当的程序进行编译动作。
1.3 Spark-GPU技术现状
近年来,随着Spark技术的迅速普及,很多学者都在努力整合Spark云平台上的CPU和GPU资源,并取得了许多突出的成果,cuSpark、 SparkCL是两个代表性的Spark-GPU项目,都实现了将GPU嵌入到Spark,在一定程度上实现了CPU和GPU的混合并行计算[9-10]。
cuSpark是一项CUDA和Spark相结合的技术。它抽象出管线(Pipeline),类似于Spark中的RDD,数据可分片,并可以存储在主机内存或显卡内存中。管线同样有转换和动作两种操作,转换包含Map(func),Map
与cuSpark不同,SparkCL则是将JavaCL与Spark结合[11]。JavaCL就是Java版本的OpenCL库。它使用了OpenCL,而没有使用CUDA,意味着可以在非NVIDIA显卡上运行代码。Aparapi由AMD Java实验室开发,2011年开放源代码,利用它可以编译Java代码到OpenCL,在GPU上运行。在这个项目中,如果试图设置内核运行在GPU,而GPU无法使用,则会切换运行在CPU上。可以通过运行示例程序,测试加速的效果,结果表明,用GPU获得了10~100倍左右的加速比。
以上现状分析表明,现阶段的Spark-GPU技术主要是将现有的GPU加速技术引入到Spark平台,本文则是将PyCUDA技术融进Spark,通过导入PyCUDA必要函数库的方式,在Spark平台调用GPU资源,因此二者融合配置较为有效、简便。
2 融合GPU的Spark并行机制
Spark-GPU技术可借助于GPU的并行能力提高运算性能,而这需要构建有效的CPU和GPU异构并行系统,保证分布式并行算法在系统上的稳定运行。下面详细分析Spark融合GPU的技术,并力图使系统达到最高计算效率,在此基础上着重探讨Kmeans聚类算法在Spark-GPU技术上的实现。
2.1 Spark云平台上混合GPU和CPU的技术流程
Spark由主节点(Master)和从节点或称工作机(Workers)组成。Spark程序称为驱动程序,驱动程序定义了对每个RDD的转换和动作。 将待处理数据上传到分布式存储系统HDFS,把应用程序提交到集群,通过CPU调控,将数据分片并发送到从节点。从节点收到对RDD的操作后,根据数据分片信息进行本地化数据操作。Spark提交应用程序的过程如图2所示。
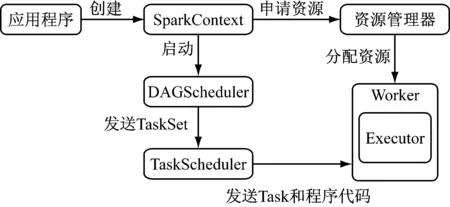
图2 Spark提交应用程序过程
Spark应用可分成任务调度和任务执行两部分,其中SparkContext为程序运行的总入口,由应用程序启动,可通过资源调度模块与执行器(Executor)通信。DAGScheduler作业调度模块可以把作业划分成若干阶段(stage),然后把阶段转化为相应的任务集(TaskSets),并交给TaskScheduler任务调度模块,任务调度模块主要负责具体启动任务以及监控和汇报任务运行情况。将任务(task)提交给执行器运行完之后,可以将结果返回给主程序或写入外部系统。
这里的每台工作机分别实现了CPU和GPU的异构并行计算[12],CPU控制程序的串行逻辑部分,GPU控制并行计算部分,计算过程中可能需要显存与内存频繁的数据交换,将计算结果先保存到显存,再由显存送回内存,再开始接下来的串行操作,或者等待下一次内核函数的调用[13]。GPU融入Spark技术流程图如图3所示。
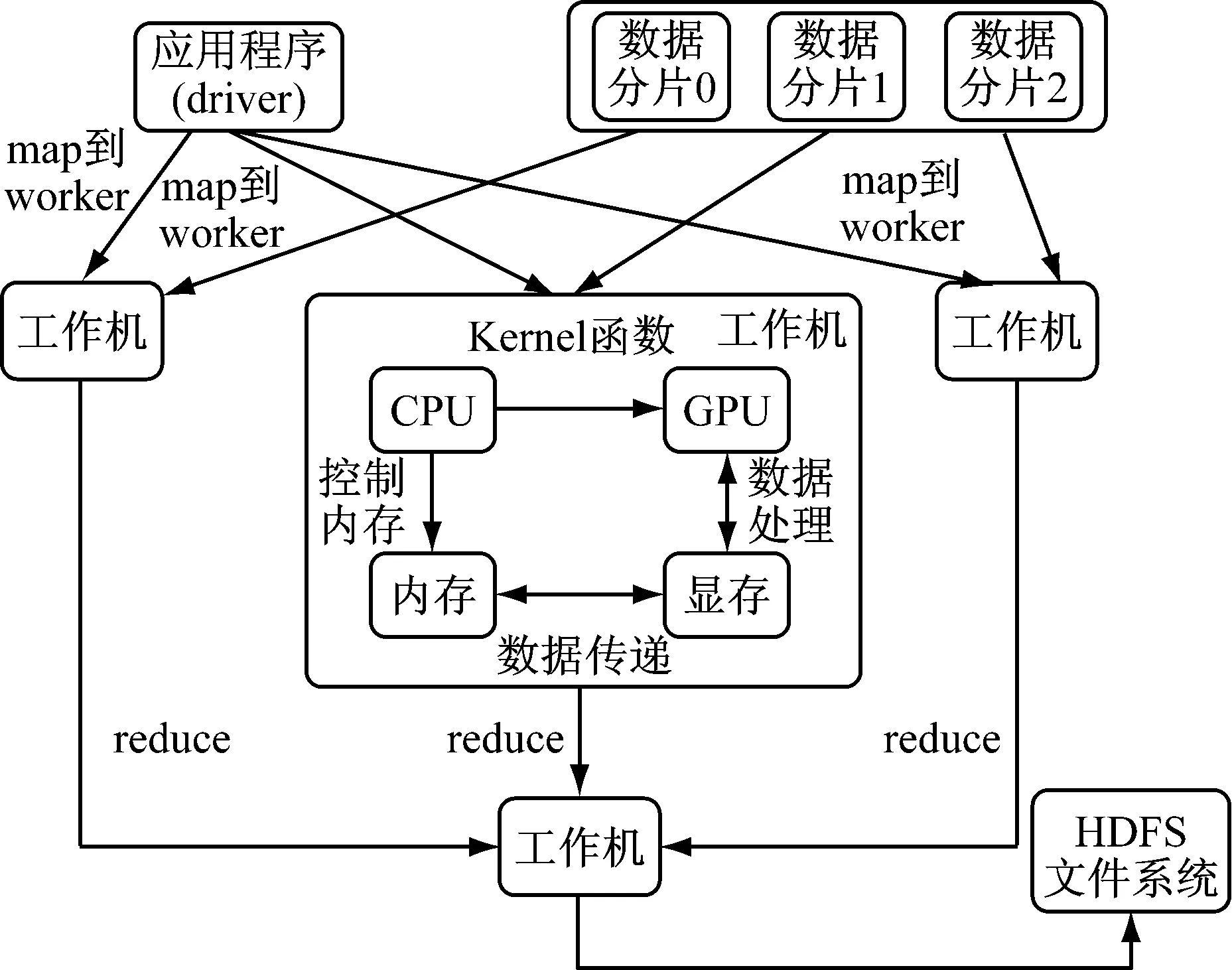
图3 GPU融入Spark技术流程
具体执行某项任务时,可以将一个阶段分成Map和Reduce两个操作步骤,每启动一次MapReduce,则为一次迭代,直到完成迭代的步数或者满足设定的阈值则终止迭代操作,以下为一个MapReduce阶段的详细描述:
(1) Map操作。根据计算资源可利用情况向工作机分配任务,工作机接收到程序指令和任务分配信息,由CPU控制内存读取分配到的待处理数据,并开始执行程序串行部分。当程序执行到内核函数,CPU将操作指令传送给GPU,数据从内存转移到显存,并对每个数据分配给相应的线程,并获取线程索引,同时可计算数据索引,以线程为单位,对数据进行函数操作。一般情况下,根据不同的作业情况会执行特定的函数任务,将计算后结果保存到显存,然后转移到内存,等待CPU的调用。
(2) Reduce操作。将GPU设备上计算的结果以特定的形式转化为RDD或者物化为文件,作为Reduce操作的输入,工作机按照一定的规则对数据进行运算,大多数情况下,数据都是以(key,value)的形式存在,因此主要是按key值对value进行操作,返回的结果联和其他特定类型的数据可作为Map操作的输入。有时候也根据Reduce结果的返回情况判断收敛与否。
实际上,虽然每个节点实现了CPU和GPU的异构并行,但由于集群异构化较复杂,在最大化集群计算能力的过程中也会遇到诸多问题:① 开发程序并应用到集群规模具有一定困难,尤其是应用到集群的CPU和GPU异构并行系统。② 通常情况下,CPU和芯片集数据传输速率在10~20 Gb/s之间,而GPU显存和内存间的数据交换速率在1~10 Gb/s之间,GPU提供了更快计算能力的同时,内存和显存间的数据传输速度也带来了性能瓶颈。③ 如何根据集群资源动态分配任务的问题,由于集群中的机器配置不一定均衡,主要包括CPU核数、有无显卡、显卡型号以及内显存大小等差异,故仍需要设计出一种策略,使得在任务分配时达到负载均衡。
2.2 Kmeans在Spark-GPU技术上的实现
Kmeans算法是比较典型的无监督聚类算法,广泛应用在数据挖掘、信息检索、市场营销等方面。其主要目标是最小化所有向量到其类簇中心的距离平方和。在Spark-GPU上实现的Kmeans算法是由CPU和GPU协同工作,工作流程如图4所示。
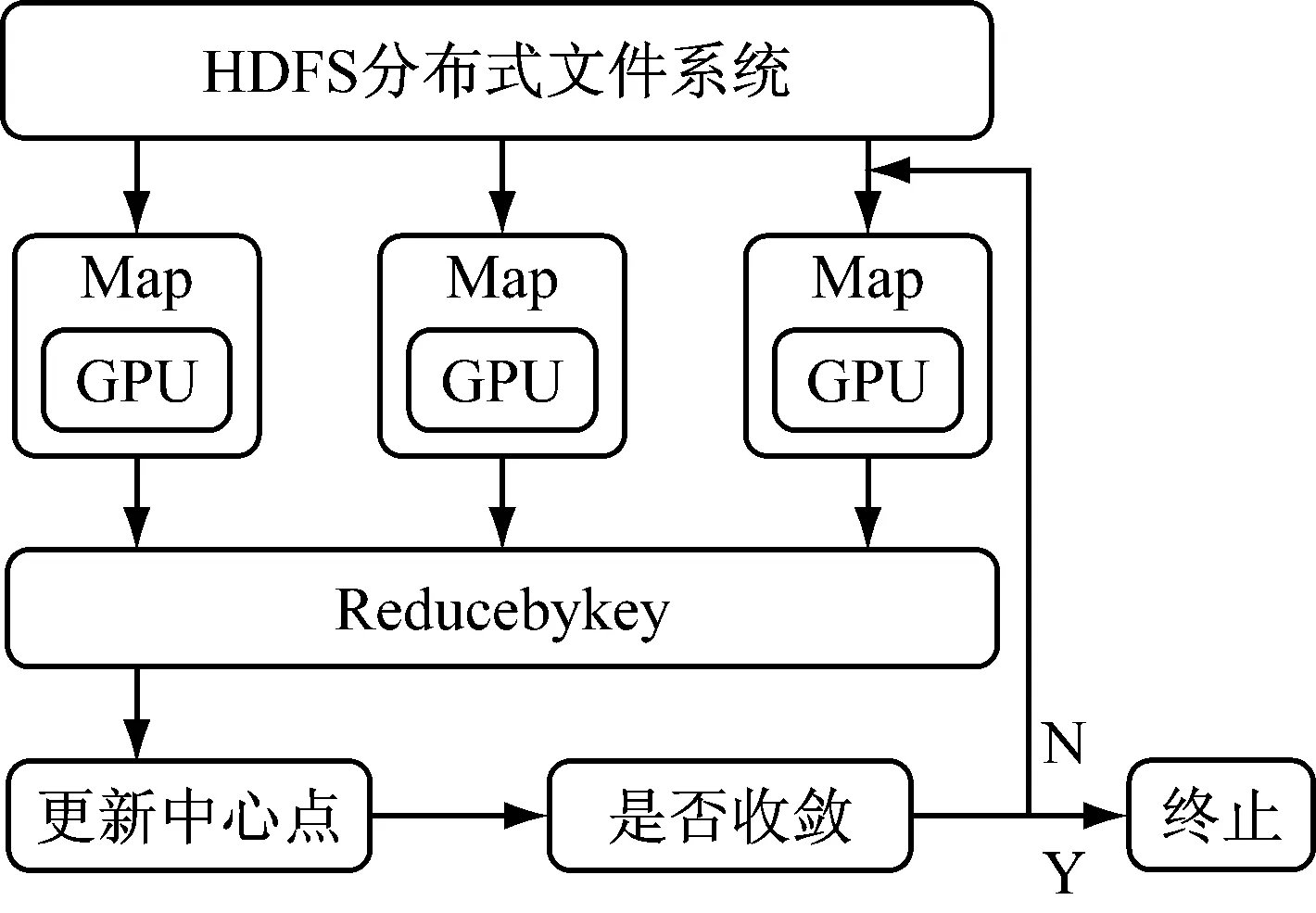
图4 Spark-GPU的Kmeans实现
Spark从HDFS文件系统读取待聚类的数据源,数据以块(block)的形式分布在集群机器硬盘,被程序解析成指定的向量格式后,根据集群资源情况将数据自动分片并分发给从节点,然后在CPU上初始化聚类中心,当程序执行到内核函数,将数据交给GPU,GPU计算出每个数据对象的类索引信息,将运算结果返回给CPU,再由CPU更新聚类中心,并判断收敛条件以决定程序是否终止,最终可以得出聚类中心的详细情况。具体地,可以将其分为Map和Reduce两个操作步骤。
(1) Map操作。输入为解析成数组形式的待聚类数据以及初始(或者上一次迭代)的类簇中心,形如(array),每一数组代表一个样本,调用内核函数时将所有数据由CPU内存传递给GPU显存,在GPU上计算样本到类簇中心的距离,内核函数输入为数据和类簇中心,将数据归属到拥有最小距离的簇类别,输出为(clusterID,array),使其转换为形如(clusterID,(array,1))的RDD,并返回CPU。
(2) Reduce操作。输入为形如(clusterID,(array,1))的数据列表,将数据中含有相同簇的(array,1)部分累加,得到一个形如(clusterID,(arraysum,arraynum))的RDD,通过元素arraysum与arraynum的求商计算可以得到新的类簇中心,输出形式为(clusterID,clustercenter)。
一个MapReduce阶段结束后,就可得到样本以及它的类簇归属信息的描述文件,以及类簇中心的描述文件,其中clusterID为类簇编号,clustercenter代表类簇中心。每启动一次MapReduce任务就执行一次迭代操作,一直迭代到目标函数收敛或者一个特定的步数。
3 实验配置情况
在实验室的局域网中挑选闲置的3台计算机,均配置有支持CUDA的显卡,并且装有Ubuntu14.04 64位的操作系统。如果有更多的机器满足要求,可以有选择地扩展Hadoop和Spark集群。3台机器配置情况如表1所示。

表1 实验器材配置
由于环境配置较繁琐,故详细配置流程在笔者博客上描述*.http://blog.csdn.net/zhouqingtaostudy/article/details/50916836。下面仅介绍其主要步骤。
选择在Spark云平台上使用PyCUDA技术开发GPU,这项基于Python开发语言的技术不但可以使用CUDA并行计算接口,而且由于许多库函数的加入,使得编程比基于C的CUDA更加方便[14]。而使用PyCUDA也需要配置好CUDA开发环境。因此,首先需要验证集群中的PC机有相应的支持CUDA的GPU、Linux系统版本以及gcc编译器,另外,系统中的内核头文件和开发包也需要与系统内核版本保持一致。本实验选择最新的CUDA-7.5进行配置。当CUDA安装成功,才可以安装PyCUDA开发环境,选择pycuda-2015.1.3版本。PyCUDA依赖于 Boost C++ 库,numpy库以及其他必要的库,条件满足后修改配置文件并编译安装。配置好GPU开发环境就可以使用GPU资源执行并行计算。
安装Spark有几种不同的方式,可以在计算机上将Spark作为一个独立的框架安装,或者从供应商处获取一个Spark虚拟机镜像直接使用,或者使用在云端环境安装并配置好的Spark。本文选择最新发布的Spark 1.6.0,把Spark作为一个独立的框架安装并启动[15]。为了让Spark能够在本机正常工作,需要安装Java开发工具包。为了能使用HDFS分布式文件系统,需要安装Hadoop软件。根据Hadoop版本,在Spark网站上下载特定版本的Spark安装包,根据实际资源修改配置文件。待全部安装成功,可通过自带程序示例验证安装[16]。
4 实验测试与结果分析
4.1 实验流程
实验中以Spark云平台上的Kmeans算法实现作为对比,评估Spark-GPU技术的性能,Spark和PyCUDA都可以使用Python语言开发,因此选择Python编写应用程序[17]。为了增加实验结果的可信度,准备了3组数据集,数据集的大小依次为41.9、209.7、419.4 Mb,分别在Spark和Spark-GPU上实现Kmeans聚类。首先在master节点启动Hadoop和Spark集群,然后将3个数据集上传到HDFS分布式文件系统,并修改程序中相关数据的路径,使其对应HDFS上的特定文件夹,将应用程序以及相应的聚类参数分别提交到集群中,如果环境配置和应用程序都正确,那么集群将开始计算。
4.2 结果分析
集群计算结束后,收集聚类的时间信息,为了使获得的时间数据更准确、更可视化,获取程序开始和结束时刻的时间戳,其差值作为实验运行时间,并修改程序使聚类中心和聚类时间显示在终端窗口,为增加实验结果的可信度,分别对3组数据集多次实验求平均值,时间统计结果如表2所示。
结果表明,Spark-GPU执行Kmeans的速度远快于Spark,究其原因:Spark云平台中的计算任务完全依靠CPU,而Spark-GPU项目中,集群中每个节点都实现了CPU与GPU的异构并行。CPU负责更新聚类中心,判断收敛条件,以及一些逻辑性任务,而距离计算等具有高度并行化的任务,则交给适合并行计算的GPU来完成。GPU含有成百上千的核心,虽然计算能力有限,但是在并行计算能力方面,比CPU更加强大,而Kmeans的距离计算部分任务比较简单,而且可分片执行,具有并行化处理的天然基础,若用CPU处理显然会耗费相当长的时间,但是若用GPU来协助计算,则会大幅提升运算速度。综上因素使得Spark-GPU获得了极高的效率。
5 结语
本文提出了GPU嵌入Spark云平台的构想,并构建了含有GPU开发环境的Spark云平台计算框架,在搭建Spark云平台的基础上,努力通过CPU和GPU的异步运算,最大化提升集群计算性能,通过无监督的Kmeans聚类实验,验证了本文构建的基于GPU开发环境的Spark计算框架,有效的提高了聚类的效率,这对图像检索、数据挖掘等领域有着极其深刻的意义,本框架对其他数据密集型或者计算密集型的任务,也明显会有加速的效果,还有待进一步的实现与验证。
在未来的工作中,仍需要了解并行计算的运行机制,将更多适合并行计算的新算法加以改进,使得在本文的框架中加以实现和优化,从而更加高效率的完成计算任务。
[1] 王 珊, 王会举, 覃雄派, 等. 架构大数据: 挑战, 现状与展望[J]. 计算机学报, 2011, 34(10): 1741-1752.
[2] 唐振坤. 基于 Spark 的机器学习平台设计与实现[D]. 厦门:厦门大学, 2014.
[3] Yang X, Wallom D, Waddington S,etal. Cloud computing in e-Science: research challenges and opportunities[J]. The Journal of Supercomputing, 2014, 70(1): 408-464.
[4] Zaharia M, Chowdhury M, Das T,etal. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012: 2-2.
[5] Ma Z, Hong K, Gu L. VOLUME: Enable large-scale in-memory computation on commodity clusters[C]//Cloud Computing Technology and Science (CloudCom), 2013 IEEE 5th International Conference on. IEEE, 2013, 1: 56-63.
[6] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[7] Spiechowicz J, Kostur M, Machura L. GPU accelerated Monte Carlo simulation of Brownian motors dynamics with CUDA[J]. Computer Physics Communications, 2014, 191(1):140-149.
[8] Zhang H, Garcia J. GPU Acceleration of a cloud resolving model using CUDA[J]. Procedia Computer Science, 2012, 9(11):1030-1038.
[9] 曾青华, 袁家斌. 基于MapReduce和GPU双重并行计算的云计算模型[J]. 计算机与数字工程, 2013, 41(3):333-336.
[10] Boubela R N, Kalcher K, Huf W,etal. Big data approaches for the analysis of large-scale fMRI data using apache spark and GPU processing: A demonstration on resting-state fMRI data from the human connectome project[J]. Frontiers in neuroscience, 2014, 9: 492-492.
[11] Segal O, Colangelo P, Nasiri N,etal. SparkCL: A unified programming framework for accelerators on heterogeneous clusters[J]. arXiv preprint arXiv:1505.01120, 2015.
[12] Stuart J A, Owens J D. Multi-GPU MapReduce on GPU clusters[C]//Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International. IEEE, 2011: 1068-1079.
[13] Zhang J, You S, Gruenwald L. Large-scale spatial data processing on GPUs and GPU-accelerated clusters[J]. SIGSPATIAL Special, 2015, 6(3): 27-34.
[14] Klöckner A, Pinto N, Lee Y,etal. PyCUDA: GPU run-time code generation for high-performance computing[J]. Parallel Computing, 2009, 38(3):157-174.
[15] 付 伟, 严 博, 吴晓平. 云计算实验平台建设关键技术研究[J]. 实验室研究与探索, 2013, 32(11):78-81.
[16] 薛志云, 何 军, 张丹阳, 等. Hadoop 和 Spark 在实验室中部署与性能评估[J]. 实验室研究与探索, 2015, 34(11):77-81.
[17] 李佳佳, 胡新明, 吴百锋. 基于异构 GPU 集群的并行分布式编程解决方案[J]. 计算机应用与软件, 2014, 31(9):28-31.
Department and Application of the GPU-based Spark Big Data Technology in Laboratory
ZHOUQing-tao,HEJun,HUZhao-hua
(School of Electronic and Information Engineering,Nanjing University of Information Science and Technology, Nanjing 210044, China)
In the era of big data, both big data processing and high performance computing are of the urgent needs of a computer system. Specific to Spark big data processing and high performance computing based on GPU, this paper analyzes the Spark technology based on GPU proposed by industry. It is mainly by constructing heterogeneous parallel of CPU and GPU, making computer to obtain a powerful computing capability. Then we discuss the implementation of the Spark-GPU technology in laboratory environment, and expound the technical process of algorithm realization in detail. On this basis, we assess the performance of the Spark and Spark - GPU technology through simulation experiment. Results show Spark-GPU technology can achieve hundredfold speedup, hence, it can play an important role in promoting the development of image processing and information retrieval and other areas.
big data processing; heterogeneous computing; graphics processing unit
2016-03-28
国家自然科学基金(NSFC61203273),江苏省自然科学基金(BK20141004)
周情涛(1990-),男,山东临沂人,硕士生,研究方向为大数据机器学习。
E-mail: 14751701086@163.com
何 军(1978-),男,河南郑州人,博士,副教授,研究方向为大数据机器学习,计算机视觉等。
E-mail: jhe@nuist.edu.cn
TP 302.1
A
1006-7167(2017)01-0112-05
