改进的支持向量机在微博热点话题预测中的应用
2017-04-07饶浩文海宁林育曼陈晓锋
饶浩++文海宁++林育曼++陈晓锋

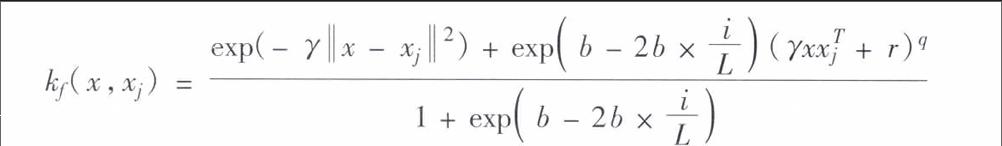

〔摘要〕为了提高微博舆情的预测精度,针对不同单一核函数的局限,用线性拟合确定两种核函数的权重提出改进的支持向量机模型。首先利用马尔科夫模型矩阵的稀疏程度提取影响因子指标,得到微博传播的增减趋势;然后用改进的支持向量机对实时数据按照4∶1的比例划分测试集和训练集,进行实时预测与警示。实验结果表明:应用马尔科夫模型进行微博舆情的主成分提取效果较佳,改进的支持向量机构造了新的组合核函数,比传统的预判效果更佳。
〔关键词〕马尔科夫模型;组合支持向量机;微博;舆情;热点话题;预测
DOI:10.3969/j.issn.1008-0821.2017.03.009
〔中图分类号〕G206〔文献标识码〕A〔文章编号〕1008-0821(2017)03-0046-06
〔Abstract〕In order to improve the prediction accuracy of Microblog public opinion and make up for performance deficiency of single kernel function,the weight coefficients of two kernel functions have been calculated by linear fitting.The Markov matrix was used to determine the weights of the impact factors and the trend of Microblog public opinion.Improved support vector machine was used to divide real time data into training set and test set according to the proportion of 4∶1.Experiment showed that the features which affected micro blogging publica opinion,had been mined better by using Markov model;Optimized SVM model constructed a new combined kernel function,and the forecasting results were better.
〔Key words〕Markov model;combination support vector machine;microblog;public opinion;hot topic;prediction
目前我国针对舆情分析指标的研究有很多,按照功能的完善程度分为告警和预警。告警模型如李纲等在突发公共事件大背景下,对突发公共事件、公共卫生事件、社会安全事件等指标进行分析,结合信息空间模型分析微博舆情传播的过程,构建微博舆情监测指标[1]。易臣何分析微博舆情的传播特点,在此基础上研究演化规律[2]。预警模型如朱卫红等采用离散的时间序列和地图定位做生态画像,根据标签特征进行提取、分析并提前一定的时间周期告警实现预警目标[3]。叶金印等建立了多条预判拟合函数进行分类和预测,用MAE等误差指标寻优[4]。
针对微博舆情预测算法的研究,不同算法有不同的业务场景的优点,例如局部最优、全局最优等的差别。例如杜智涛等用灰色预测方法,用微分方程解法做时间序列回归模型[5]。张华基于BP-神经网络算法对其经典模型进行优化,对输入层与隐含层的矩阵、隐含层与输出层的矩阵权值的稀疏性处理较好[6]。魏德志提出用混沌理论解决非线性的函数,一改用线性函数进行拟合的前提假设,并且改进了径向基核函数,使得神经网络发挥了在具体舆情预测中的优点以提高数据准确性[7]。
微博话题的影响因子与权值矩阵的处理是预测准确度提升的保证。虽然微博话题的影响因子有很多,但是许多学者的研究主要在于确定影响因子之间内在逻辑,往往难以分离各个指标确定各自的权重而进行定量分析。也有一些学者涉及定量的研究,但是用户能获取到的微博指标权限有限,实际操作无法进行。因此,本文基于容易获取到的一些指标,进行两个算法过程的预测与验证,分别从不同角度预测趋势,得到较好的预测效果,供舆情部门参考。
1马尔科夫模型的增减趋势预判
马尔科夫区别于回归模型,在于将问题看作是离散随机过程,并非连续函数,且强调下一个时间节点的状态与上一个无关(即相邻两个时间节点的数据无法互相影响)[8]。而这恰恰更适合预测随机波动大的动态过程,可弥补灰色预测的局限[9]。
马爾科夫模型要求数据具有马尔科夫链和平稳过程等均值的特点,而现实生活的预测问题大都是随时间变化或呈某种变化趋势的非平稳过程。若用灰色GM(1,1)模型对满足时间序列的数据进行拟合,可用变化趋势弥补马尔科夫链预测的局限;而在灰色预测的基础上进行马尔科夫预测,又可弥补灰色预测对随机波动大的数据预测准确度低的缺陷。从而得出两种模型结合,能较准确地预测微博热点话题。
图1是从MySQL主表界面得到的随着时间分段不同获取的单位时间内中文分词的关键词出现的时间段的情况(其中“Null”代表空)。
从MySQL里获取的分词数据,将3月上旬的时间划分为30个等距时间间隔,及8个小时为1个获取时间周期。以每个时间点检测获取到的关键词不同作为划分标准,没有出现的地方显示为“Null”,以选取的16条记录为例,计算每项出现关键词的时间段个数,作为马尔科夫模型中每种关键词的词频。
2改进的支持向量机的热点话题预测
21算法实现伪代码
Step 1:数据的提取和预处理
1)将半年微博数据用Java提取四列数据,即:时间节点、点赞数、评论数、转发数。
2)将原始数据进行归一化(mapminmax为matlab自带的映射函数,对点赞数、评论数、转发数进行归一化处理,公式为:y=(ymax-ymin)*(x-xmin)/(xmax-xmin)+ymin;并对点赞数、评论数、转发数进行转置,以符合libsvm工具箱数据格式要求。
Step 2:确定核函数的各项参数:
1)写调用函数kernel(ker,x,y)。
2)对比各个经典核函数模型的误差率,确定各自的优缺点。
3)确定怎样分配比例使得组合模型能实现最佳预测。
Step 3:利用回归预测分析最佳的参数进行SVM网络训练
22多项式核、高斯核、线性与非线性核函数的对比使用支持向量机算法要从常用的3种函数模型中选择最优的作改进,经过对比分析确定一种核函数为指标的最佳核函数[10-11],目的是将高维空间的内积运算转化为低维空间的函数运算。
对核函数的选择,目前没有成熟完善的指导原则,必须根据各种测试数据的观察结果来确定[12-13]。某些问题用某些核函数效果很好,用另一些很差。多项式核是典型的全局核函数,相距很远的点对核函数的值均有影响,不论函数中的阶数从1~5增加,其周边的数据点都对多项式核函数的值产生影响;而高斯核函数是典型的局部核函数,只有当落在某个宽度之间时才会对核函数值有影响,只有在一定的范围内取值对高斯核函数有效。
23组合核函数的确定
24结果与分析
241改进的马尔科夫模型
列举16个中文分词得到的关键词,以及统计的出现时间段次数,T1~T15表示15个等距时间段,表中数字代表增长速率,使得快速上升(≥03)在程序中用“2”表示;缓慢上升(0,003),用“1”表示;相对不变用“0”表示;缓慢下降(-003,0)用“-1”表示;快速下降(≤-003)用“-2”表示,从而得到各个关键词在不同时段的相对值Ai(i=1,2,…,30)。
以第一个关键词“以后”为例,T1~T15这15个等距时间段中,取前14个等距时间段的增长率参加计算,第15个增长率与模型的预测率进行比对,从而验证模型的准确性。
先算出增长率,使用概率转移矩阵完成马尔科夫预测。由于微博爆发趋势受到多重因素的影响,若笼统地采用拟合计算分析,会使误差率增加;而用概率矩阵转移,则是根据下一次的爆发趋势所出现的状态的最大可能概率进行预测,可靠性高。
Key1:“以后”
10200010200010102000104000110212210216710087210236710247211024181021981009801024351019691102432102238101030102481101818110245310224010104610248810177311024571022431010501024911017591102458102243101052102492101755用1个关键词为例,可知:列数表示5个状态下对应的概率,行数表示预测的时段个数,输出数据的每一行的最大的概率值表示相应时间段最可能出现的增长状态。下面为关键词1:“以后”的算法数值,其中D1~D5分别表示“先迅速增长”、“先缓慢增长”、“先相对不变”、“先缓慢下降”、“先快速下降”。如表3:
如果目前微博热点预测的话题处于状态Bi(i=1,2,3,4,5),这时Eij描述目前状态Bi在将来转移状态Bj(j=1,2,3,4,5)的可能性。按照最大概率原则,即选{Ei1,Ei2,Ei3,Ei4,Ei5}中最大者对应的状态即为预测结果。
由于通过计算得到的关键词“以后”的增长率状态为E3,即相对稳定。由上面的转移矩阵可知:由一次转移到5种状态的概率分别为:E31=0833,E32=02083,E33=06250,E34=00833,E35=0,Max={Ei1,Ei2,Ei3,Ei4,Ei5}=E33=06250,且E31、E32、E34、E35比E33对比,均差距很大。
因此,预测的结果显示:在T11~T30时间段内的微博热点话题的热度将继续保持稳定,且增长幅度为1,将预测结果与实际结果表对比可知:实际微博继续保持缓慢上升,因预测结果是准确的。
改进的支持向量机模型综合了两个经典核函数的优点,对实际数据出现的稀疏矩阵问题采用核函数映射,归一化处理后将其映射到[0,1]区间,解决误差大造成的预测影响。最后反归一化回去,得到实际预测数值。
由此可以得出,改进的支持向量机模型可以解决局部样本最优问题,得到的趨势误差较小,可以代替全局最优函数用逼近法逼近,逐步减小误差。
242组合核函数模型
新构造的组合核函数,即加入各种核函数的权重,构建组合核函数来适应数据的特点。其近期样本重要性远大于前期样本,体现最近时间样本点最重要的原则,增强预测准确度。
由于采集的是点赞数、评论数、转发数,分别记为y1、y2、y3,对其一一进行训练与测试,得到拟合与预测曲线。表4以预测部分的10分钟为例:
其中4058759664-4058760602是2016/3/15 15∶00~2016/3/15 15∶10的10分钟数据,Matlab中调用函数将标准时间(时间格式)转为时间戳(字符格式),预测数据(蓝色)与真实数据(黑色)的对比,每分钟获取一次数据,经过测试寻优,确定训练集与测试集的比例为4∶1时最佳的数据。后面1/5的数据即为表4所示。图3中是50分钟的数据,分为40分钟实际数据与10分钟预测数据。蓝色实际值的离散点与拟合、预测红色曲线很接近,走向趋势也保持一致,表明拟合与预测效果较佳。
其中程序展示最优化正则参数与最优核参数的检验结果,省略展示R2、MSE、MAE、MAPE等误差类的统计验证,且采用快速留一的交叉验证方法,不断迭代降低误差。得到组合模型预测效果较佳。
3结束语
本研究结合马尔科夫与改进的支持向量机来构建微博话题预测趋势预测,通过实例来验证模型的准确性。此外,该模型也会存在着一些缺点。首先是获取到的指标参数有限,后选取时间序列和转发数、评论数、点赞数的指标用于预测。另外,获取到的是2015年上半年的数据训练,用4∶1的比例做训练预测,和实时情况中组合模型取最近的权重最大,没有进行历史数据按天同期的统计,不可避免地存在特定日期等情况时舆情暴增带来的误差。因此需要人工处理这种趋势带来的例外。该模型的预测结果的准确性依赖于数据的逻辑联系与误差的迭代。研究所得到的结果可以为舆情的管理提供有效的指导。
参考文献
[1]李纲,陈璟浩.突发公共事件网络舆情研究综述[J].图书情报知识,2014,(3):117-123.
[2]易臣何.突发事件网络舆情的演化规律与政府监控[D].湘潭:湘潭大学,2014.
[3]朱卫红,苗承玉,郑小军.基于3S技术的图们江流域湿地生态安全评价与预警研究[J].生态学报,2014,(1):119-121.
[4]叶金印,李致家,常露.基于动态临界雨量的山洪预警方法研究与应用[J].气象杂志,2014,(1):114-116.
[5]杜智涛,谢新洲.利用灰色预测与模式识别方法构建网络舆情预测与预警模型[J].图书情报工作,2013,(8):76-81.
[6]张华.基于优化BP神经网络的微博舆情预测模型研究[D].武汉:华中师范大学,2014.
[7]魏德志,陈福集,郑小雪.基于混沌理论和改进径向基函数神经网络的网络舆情预测方法[J].物理学报,2015,(4):93-95.
[8]徐扬,孟文霞,李广建.基于灰色预测模型的情报学热点主题发展预测[J].情报科学,2016,(7):3-6.
[9]杨怡.销量的多因素灰色预测和马尔柯夫链模糊修正模型研究[J].工业工程与管理,2014,(5):90-93.
[10]王和勇,崔蓉.在线用户评论的主题发现研究[J].現代情报,2015,(9):63-69.
[11]商丽媛,谭清美.基于支持向量机的突发事件分级研究[J].管理工程学报,2014,(1):119-123.
[12]曹云忠,邵培基,李良强.微博网络中用户关注行为预测[J].系统工程,2015,(7):146-152.
[13]章成志,李蕾.社会化标签质量自动评估研究[J].现代图书情报技术,2015,(10):2-12.
(本文责任编辑:孙国雷)
