基于大数据存储区域自动筛选的数据库优化
2017-03-31郑倩倩刘静静
郑倩倩+刘静静


摘 要:提出一种基于大数据存储区域自动筛选的数据库优化存储和访问技术,首先进行数据库中数据分布存储模型设计和数据结构分析,采用模糊C均值聚类算法进行大数据的存储区域优化聚类,提高数据聚敛能力。采用滤波算法进行数据库中的干扰滤波处理,对滤波输出的数据进行存储区域的自动筛选控制,实现数据库存储空间优化,提高数据库访问的指向性和配准性。仿真结果表明,利用该方法进行数据库优化设计,对大数据的存储和调度性能都有较大改善。
关键词关键词:大数据存储;数据库优化;聚类;滤波
DOIDOI:10.11907/rjdk.161795
中图分类号:TP392
文献标识码:A 文章编号:1672-7800(2016)008-0165-03
0 引言
近年来,随着大数据处理技术的快速发展,对大数据的存储和调度成为大数据信息处理的关键。随着人们对分布式数据库的逐步关注、深入研究与常态化应用,采用分布式级联数据库进行大数据存储成为大数据处理应用的重要方向。研究大数据的分布式级联数据库优化设计,将在云存储和大数据智能信息处理等领域具有较高的应用价值[1]。
通过对数据库存储结构和数据访问技术的优化设计,提高数据库对大数据的存储和调度控制能力。传统的数据库存储采用堆栈列表控制方法进行大数据存储,随着存储量和干扰的增大,导致数据库的调度和访问准确性不高。在数据库访问中,目前主要有基于语义信息特征提取的数据库访问技术、基于词频特征分布的数据库访问技术和基于关键字的数据库访问技术等[2,3]。其中,文献[4]提出一种基于语义数据集特征提取的数据库优化设计方法,以实现数据库的优化存储和大数据处理。首先找出两个最不相关的语义数据集合,考查词频准确性和样本记录数量之间的关系,通过有向图模型设计方法,提高数据库的调度和访问指向性能力。但是该方法计算开销较大,收敛性不好[5]。针对上述问题,本文提出一种基于大数据存储区域自动筛选的数据库优化存储和访问技术,首先进行数据库中数据分布存储模型设计和数据结构分析,采用模糊C均值聚类算法进行大数据的存储区域优化聚类,提高数据聚敛能力。采用滤波算法进行数据库中的干扰滤波处理,对滤波输出的数据进行存储区域的自动筛选控制,实现数据库存储空间优化,提高數据库访问的指向性和配准性。最后通过仿真实验进行了性能测试,得出有效性结论,展示了较高的应用价值。
1 预备知识及数据库中大数据存储数据结构分析
1.1 数据库中数据分布存储模型设计
为了实现对大型网络级联数据库的优化设计和存储访问控制,首先采用分布式存储调度方法,对大型网络级联数据库的存储数据采集结构进行存储数据的数据结构分析,再用有向图表示云计算环境下大型网络级联数据库的数据分布存储模型,如图1所示,以此为基础进行数据的存储结构优化设计[6]。
1.2 数据结构分析与信息流时间序列分析
在上述构建了数据库中数据分布存储模型的基础上,为了实现对数据存储区域的自动筛选和访问控制,进行数据库结构和数据信息流时间序列分析及信号模型构建。求大型网络级联数据库存储数据每类样本的模糊神经网络控制的隶属度函数,先求得隶属度函数的特征采样均值Ej=∑FijKj(i∈Kj,j=1,2,…,N),Kj为第j类样本符合K个分配因子的带宽,并抽取数据库访问特征序列的相空间模糊度点集作为数据库访问控制训练集的聚类中心S,取其最大值si作为资源带宽差值控制的第一个聚类中心,采用自适应波束形成进行特征采样和资源访问控制,假设访问控制函数为:
在数据库访问过程中,假设时间函数为一个非线性的时间序列,得到数据库访问过程的不确定干扰项为:
其中,U为数据库访问控制中的特征采样数据论域。这里采用粒子群算法进行数据库的访问时间序列分析,粒子群在搜索过程中经常会陷入局部最优解,采用混沌映射方法,带领粒子逃离局部最优解,混沌映射的状态空间更新迭代过程为:
依据混沌映射搜索的最小积分准则,当粒子群在搜索过程中簇的中心点收敛到数据库的资源聚类中心时,求得数据库的资源聚类训练集的功率谱密度函数作为特征,进行特征提取和时间序列分析,得到数据的特征向量为:
通过上述处理,实现对大型数据库数据结构和信息流时间序列的分析,为实现数据库的优化设计奠定基础。
2 大数据存储区域自动筛选及数据库优化
在上述进行了数据结构分析和信息流时间序列分析的基础上,进行数据库优化设计改进。提出一种基于大数据存储区域自动筛选的数据库优化存储和访问技术,采用模糊C均值聚类算法进行大数据的存储区域优化聚类,提高数据聚敛能力。模糊C均值聚类算法的实现过程如下,对大型网络级联数据库存储数据的结构特征优选的C均值聚类中心为:
通过上述算法改进设计,实现数据库优化存储的调度控制。
3 仿真实验与结果分析
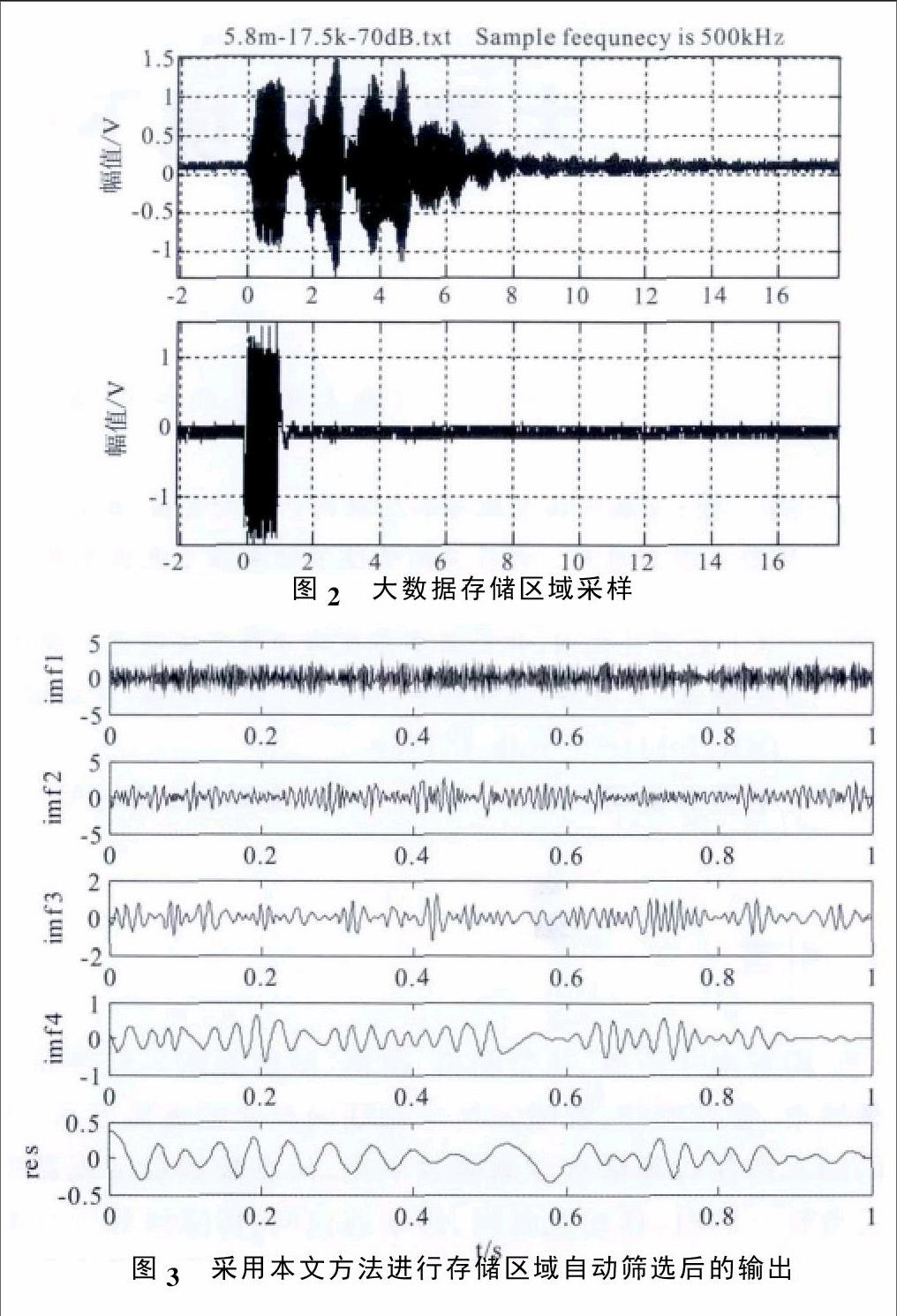
为了测试本文算法在实现数据库优化存储中的性能,进行仿真实验。仿真的硬件CPU为Intel CoreTM i7-2600,采用Matlab仿真工具进行数学仿真。大型网络级联数据库存储数据的云存储节点分布在均匀线列阵存储区域,存储数据的数据格式为vmdk、exe等。进行大型网络级联数据库存储数据的原始信息采集,大数据特征采样频率为21kHz,存储数据的频率范围为12~24kHz。根据上述仿真环境和参数设定,得到大数据存储区域的采样输出如图2所示,采用本文方法进行存储区域自动筛选后的输出如图3所示。
由图3可见,采用本文方法实现数据库存储空间优化,可提高数据库访问的指向性和配准性。仿真结果表明,利用该方法进行数据库优化设计,对大数据的存储和调度性能都有较大改善。
参考文献:
[1] 周涛.基于改进神经网络的电力系统中长期负荷预测研究[J].电气应用,2013,32(4):26-29.
[2] 耿忠,刘三阳,齐小刚.基于非合作博弈的无线传感器网络功率控制研究[J].控制与决策,2011,26(7):1014-1018.
[3] 张磊,王鹏,黄焱,等.基于相空间的云计算仿真系统研究与设计[J].计算机科学,2013,40(2):84-86.
[4] 文天柱,许爱强,程恭.基于改进ENN2 聚类算法的多故障诊断方法[J].控制与决策,2015,30(6):1021-1026.
[5] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015 (5):74-80.
[6] 关学忠,皇甫旭,李欣,等.基于正态云模型的自适应变异量子粒子群优化算法[J].电子设计工程,2016(8):64-67.
(责任编辑:黄 健)
