基于HBase的车联网传感数据管理系统设计
2017-03-31孙旭束晓敏叶润武史昇钟艳高亚红
孙旭+束晓敏+叶润武+史昇+钟艳+高亚红


摘 要:关系型数据库由于面向行存储以及无法扩展等原因,已很难满足大规模车联网传感数据的存储与查询要求。针对该问题,设计了一个基于非关系型数据库HBase存储的车联网传感数据管理系统。该系统采用Hadoop与HBase搭建分布式实验平台,采用C#语言开发Web网页端。通过与传统关系型数据库SQL Server的存储与查询效率进行对比分析,表明HBase在处理大规模车联网传感数据方面具有明显优势。
关键词关键词:HBase;车联网;Thrift;C#.Net
DOIDOI:10.11907/rjdk.161481
中图分类号:TP319
文献标识码:A 文章编号:1672-7800(2016)008-0071-03
0 引言
随着车联网技术的迅速发展,车联网终端传感器数量不断增多,分布范围也越来越广,从而使传感器采集的数据量飞速增长[1]。例如,一个车联网传感器大约10秒采集一次数据,一辆车大约有100个传感器,则一辆车一天采集到的数据量大概有90万条,一辆车一年产生的数据量大约是3亿多条。然而,传统关系型数据库存储这么庞大的数据量是非常困难的,虽然Oracle等也曾提出过针对大数据存储的解决方案,但是这些方案没有脱离传统,都是基于关系和面向对象模型的,其虽然能够处理相对复杂的数据,存储数据的代价却非常大[2]。
近年来,云计算技术发展迅速,源自谷歌BigTable的HBase分布式存储数据库很好地解决了大数据存储问题[3]。由于采用分布式列存储形式,所以相对于关系型数据库MySql、SQLServer等具有查询效率高、所需存储空间小等优势[4]。车联网数据管理系统采用C#开发网页端,通过C#连接HBase数据库并实现对HBase数据库中数据的查询和显示。由于HBase是Java开发的,所以HBase提供了丰富的Java接口,对于其它语言,需要采用HBase中内置的Thrift组件来实现C#接口的转换以及与HBase的连接[5]。
1 车联网数据管理系统相关原理
1.1 HBase
HBase是一个面向列的分布式数据库,可以随时读写大规模数据,弥补了HDFS不支持随机读写的不足。它的表结构由行键、时间戳和列族组成[6]。HBase以HDFS分布式文件系统为底层支撑,HBase中的数据文件存储在分布式文件系统中。HBase可以简单地通过增加节点达到线性扩展,能够在廉价硬件构成的集群上管理超大规模的稀疏表[7]。
HBase系统主要由HBase Master服務器和Hregion服务器群构成。它遵循简单的主从服务器体系结构模型。不管是HBase Master服务器还是HRegion服务器都由Zookeeper协调分配,并且由其处理HBase运行之间出现的问题。而HRegion服务器则由HBase Master服务器调度和管理,并且所有数据都存储在HRegion服务器中,主服务器不存储任何数据[8]。HBase当中的一张数据表在逻辑上可以被划分为多个分区,然后由主服务器进行分配,将数据存储到HRegion服务器中,而主服务器仅存储逻辑分区与实际存储数据的映射关系[9]。
HBase是一个系数的长期存储、多维度、排序的映射表,其表的索引是行关键字(RowKey)、列关键字(Column Family)和时间戳(TimeStamp)。HBase中的数据都是字符串类型,没有其它数据类型。
如表1所示,该表由两行组成:R1和R2,有两个列族:C1和C2。在第一行中,列族C1有3条数据,列族C2有1条数据;在第二行中,列族C1有1条数据,列族C2有1条数据。每一条数据对应的时间戳都用数字来表示,根据时间戳来区分不同版本的数据。
1.2 车联网
车辆通过GPS、RFID、传感器等设备完成自身环境和状态信息的采集;通过各种无线通信技术,车辆将采集到的自身传输数据汇集到中央处理器;信息处理平台根据不同的功能需求,将这些信息进行拆分和处理,从而实现车辆导航、车辆状态和位置监控、车辆控制和引导等,为用户提供安全、环保、便利的服务。
车联网数据具有数据规模大、种类多样、工作环境比较复杂、数据处理时效性要求高等特点,所以借助Hadoop大数据处理平台和HBase分布式数据库对车联网数据进行有效管理显得非常重要。
1.3 C#.Net网页端
系统采用B/S结构,利用C#.Net技术结合HBase非关系型分布式数据库构建一个车联网数据查询系统,该网页可以读取Hadoop平台HBase数据表中的数据在前台显示,并供用户查询。涉及到的基本数据包括用户信息、工况参数、监控配置信息等,其中用户信息包括用户名和密码等基本信息,工况参数记录车辆运行的数据和状态,监控配置信息是对工况参数的描述。
HBase可完美地支持原生态Java API,但是其它非Java原生态语言不能直接访问HBase。C#如果要访问HBase数据库,必须使用HBase内置的Thrift接口来操作HBase数据表中的数据。
2 车联网数据管理系统总体架构
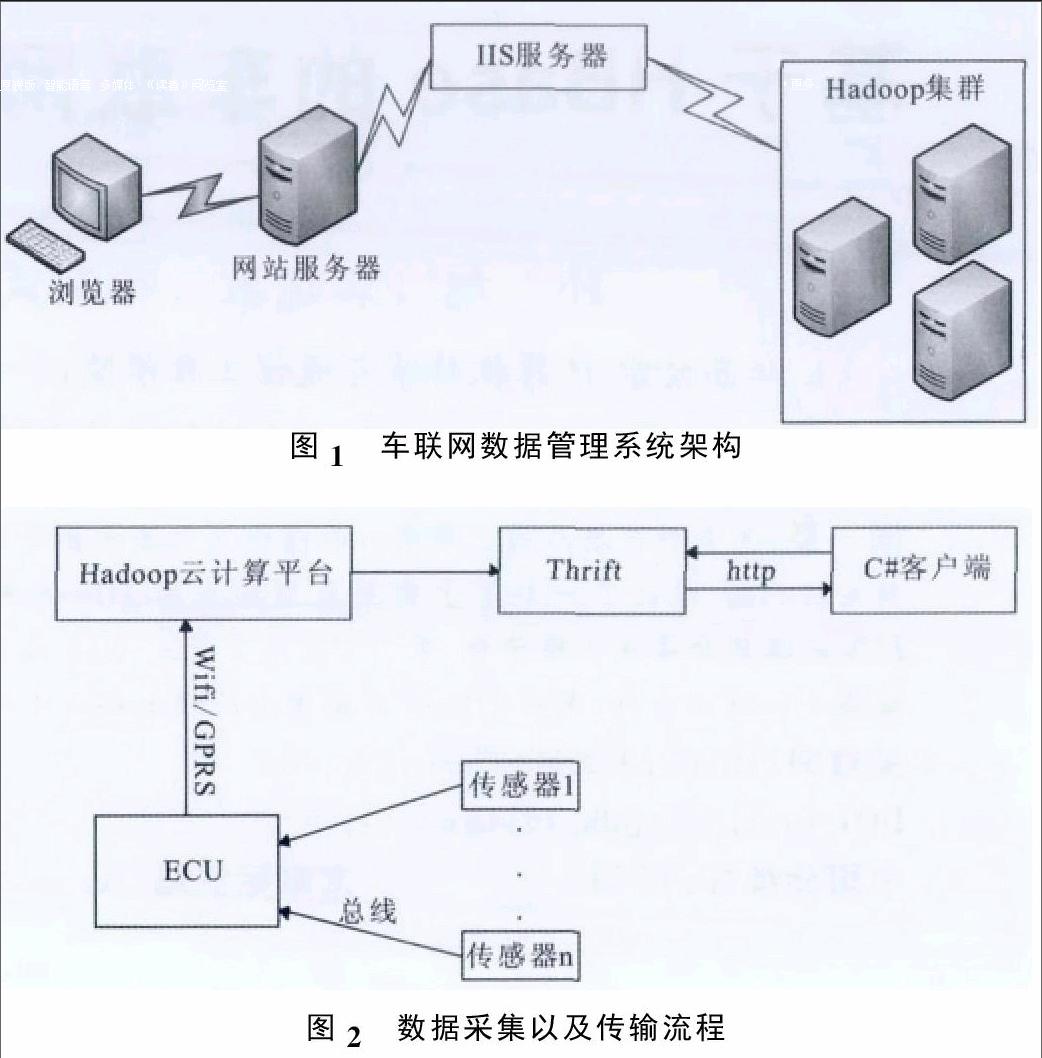
系统采用浏览器/服务器模式,用Hadoop集群代替传统服务器,在Hadoop集群之上搭建分布式数据库HBase来存储数据。如图1所示,部署在网站服务器上IIS的C#网页端通过IIS服务器访问Hadoop集群。
图2显示了整个系统的数据流。首先,通过车内传感器采集车联网传感数据,然后传感器将采集到的数据通过CAN总线传送到每辆车内的电控系统ECU,ECU通过集成在芯片内的WiFi或GPRS模块将数据发送到Hadoop集群,集群对数据进行简单处理并插入到HBase数据库,最后,C#网页端通过Thrift插件访问HBase并将数据展现给用户。
3 系统实现与结果分析
3.1 平台搭建与数据库设计
由于Zookeeper运行在奇数个节点上更稳定,本系统的Hadoop集群采用5个节点(一主四从)为例搭建完成。节点操作系统采用CentOS6.5-64位系统,jdk(Java Development Kit)采用jdk7,Hadoop采用hadoop-1.2.1稳定版本,HBase采用hbase-0.94.18版本,Zookeeper不使用HBase内置zookeeper,而采用单独的zookeeper-3.4.5版本,Thrift采用HBase内置的版本。
本系统数据库主要包括用户、ECU、工况参数以及工况参数描述等信息。
User表:该表用来存放用户信息,主要包括用户名、密码、用户权限等。把UserID作为行键RowKey,UserInfo作为列族,UserName、Password、RoleName分别作为列族UserInfo的3列,概念视图如表2所示。
ECU表:该表用来存放ECU信息,主要包括ECU位置以及车主信息。把ECUID作为RowKey,ECUInfo作为列族,ECUInfo分别包括location和owner两列,概念视图如表3所示。
Data表:Data表用来存放工况参数,主要包括发动机转速、电压、电流、踏板开度等参数。ECUID将作为行键RowKey,新建DataInfo列族,列族中包括speed、voltage、current、open等列,概念视图如表4所示。
3.2 C#网页端设计
系统采用B/S架构,通过C# API读取HBase中的数据,并将获取的数据通过浏览器显示到网页上供用户查看,使用户能实时了解自己车辆的状态并及时采取相关措施。在B/S模型中,客户通过客户端的浏览器软件向B/S服务器端发送访问请求;B/S服务器端接到访问请求,对接收到的请求进行处理;服务器端将访问请求生成SQL语句,向数据库验证该语句的合法性并进行数据处理;处理完后的数据返回B/S服务器,由服务器将结果返回浏览器;最终浏览器以Web网页样式展现出结果。
整个C#网页端采用MVC的设计模式,即Model(数据模型)、View(视图)、Controller(控制器)模式。通过业务逻辑、数据、界面显示分离的方法将繁多的代码组织起来。其中Model提供要展示的数据,包含数据和业务,提供了模型数据查询和模型数据的状态更新等功能;View负责进行模型展示,即一般见到的用户界面;Controller接收用户请求,委托给模型进行处理,处理完后把返回的模型数据返回视图,由视图负责展示,控制器起到了调度作用。
C#网页端通过Thrift插件访問HBase数据库,通过HBaseAdmin和HTable类设计C#访问HBase数据库接口。系统通过网页将车联网各项数据显示出来,使用户能够实时查看自己车辆的状态信息。
3.3 HBase与SQL Server查询效率对比分析
HBase与SQL Server分别是传统非关系型数据库和关系型数据库的代表,它们之间存在着许多不同。HBase运行在分布式Hadoop集群上,SQL Server运行在单节点上;HBase面向列存储,SQL Server面向行存储;它们在底层的存储形式、数据库概念模型与逻辑模型也有很大不同。
在C#网页端数据代码查询处添加秒表,分别连接HBase数据库,以及原有的SQL Server数据库。用get方法查询HBase数据库,用select方法查询SQL Server数据库。查询相同的数据,分别记录查询所用的时间,执行多次查询取平均值,如表5所示。
由表5可以看出,随着数据量增加,查询时间也相应增加,但都不是线性增加。当数据量很小时,两者查询效率差别并不明显,HBase消耗的时间甚至比SQL Server更多;但随着数据量增加到10 000条时,SQL Server消耗的时间是HBase的4倍;当数据量增加到100 000条时,SQL Server消耗的时间是HBase的8倍。数据量越大,两者消耗时间的时间差越大,所以HBase更适合大规模数据的管理。在本系统中,HBase查询效率之所以能达到SQL Server查询效率的4~8倍,是因为HBase是分布式列存储结构,由整个集群共同工作,并且不需要查询整行,只需要查询相应的列即可。
4 结语
本文设计了一种基于HBase的车联网数据管理系统,采用Hadoop与HBase搭建数据处理平台,设计了HBase数据库,采用B/S架构与MVC设计模型开发C#.NET网页端。最后,将HBase数据库与SQL Server数据库作查询效率对比测试。结果表明,HBase相对于传统关系型数据库SQL Server具有更高的效率和实时性。
参考文献:
[1]LARS,GEORGE.Hadoop权威指南[M].北京:人民邮电出版社,2013: 68-70.
[2]NICK,DIMIDUK.HBase实战[M].北京:人民邮电出版社,2013: 23-26.
[3]冯晓普.HBase存储的研究与应用[D].北京:北京邮电大学,2014: 24-25.
[4]李青云.基于HBase的应用平台的研究与实现[D].北京:北京邮电大学,2015:9-10.
[5]魏巍.基于HBase的移动统计平台的研究[D].青岛:中国海洋大学,2014:50-51.
[6]陈庆奎.基于HBase的大规模无线传感网络数据存储系统[J].计算机应用,2012,32(7):1920-1921.
[7]李坚.基于HBase的地震大数据存储研究[J].大地测量与地球动力学,2015,35(5): 891-891.
[8]张智.分布式存储系统HBase关键技术研究[J].现代计算机,2014,32(5):33-34.
[9]王蒙.基于HBase的农业微博数据存储与处理策略[J].中国农机化学报,2014,35(3): 221-222.
(责任编辑:黄 健)
