面向开源社区的Web数据抽取方法研究
2017-03-29张方尹刚王涛余跃
张方,尹刚,王涛,余跃
(国防科学技术大学计算机学院,长沙 410073)
面向开源社区的Web数据抽取方法研究
张方,尹刚,王涛,余跃
(国防科学技术大学计算机学院,长沙 410073)
由协同开发社区和知识分享社区所组成的开源社区中汇集海量的开源数据资源。如何从数量众多,页面结构各异的开源社区中准确、高效地获取这些数据是对开源数据资源进行全面分析,深度关联的前提。阐述面向开源社区的Web数据抽取方法研究过程,实现对开源社区中Web数据的精确抽取。
开源社区;Web数据抽取;协同开发社区;知识共享社区
0 引言
面向开源社区的Web数据抽取是指从各类开源社区的Web页面中抽取出我们所感兴趣的数据,并将其以结构化的格式导入数据库中供进一步分析处理的过程。通常情况下,在开源社区中我们获取信息的方法是通过页面浏览和关键词搜索。然而,页面浏览和搜索的结果都是粗粒度的网页,我们虽然能查看具体内容,但却无法精准地获得网页中自己所感兴趣的数据。此外,即使我们获得了这些网页,也无法直接进行数据分析和应用。如何从源自不同开源社区站点且表现形式复杂,结构各异的Web页面中准确的抽取有价值的数据,并将其集成并转化为结构和语义清晰的格式,存储到数据库中,以满足后续数据的深加工需求进而形成开源资源知识库已经成为一个亟待解决的问题。
1 研究意义及研究目标
近年来,互联网技术的迅速发展聚合了分散在全球各地的开发人员,促使国内外开源社区蓬勃发展,开源也成为了软件开发的趋势,各个开源社区互相关联形成了一个完整的开源生态系统。在这个生态系统中,开源数据资源规模巨大、增长迅速且分布广泛。为了能够更加高效地利用开源社区中的数据资源,首先要实现对开源社区用户所感兴趣的开源数据的精确抽取,因此,开展面向开源社区的Web数据抽取方法的相关研究工作迫在眉睫。本文着力研究面向开源社区的Web数据抽取技术,目标是构建一个抽取准确率高,并能够适应不同开源社区站点的通用、健壮的Web数据抽取框架,从而实现对开源社区中众多的协同开发社区和知识共享社区所包含的海量的开源数据资源的精确抽取。
2 主要研究内容
本文研究的是对开源社区中海量开源数据资源进行有效抽取的方法,在此过程中主要涉及以下几个方面的问题:如何构建一个适用于不同开源站点的通用的、健壮的Web数据抽取框架;如何表达待抽取数据元素的抽取规则;对于抽取得到的数据,如何进行有效的验证和处理。
2.1 构建面向开源社区的Web数据抽取框架
开源社区中众多的开源社区站点在网页结构和内容上都呈现出很大的差异,面向开源社区的Web数据抽取框架对大量不同开源社区站点的通用性,即对不同开源站点的适应性和健壮性是面向开源社区的Web数据抽取方法能够得到大规模应用的前提。
2.2 抽取规则的制定
抽取规则的制定是对面向开源社区的Web数据抽取的核心,在对HTML文件中的页面元素进行抽取时,我们是通过有效的抽取规则实现对文件中待抽取页面元素的准确导航、定位和抽取的。
2.3 数据验证和处理
为了保证数据抽取的质量,尽量减少“脏数据”,抽取到的数据还需要完成数据验证和处理的过程。在这个过程中首先要确保的是抽取数据本身的正确性和完整性,其次当从多个开源社区站点抽取并集成数据时,不同的站点对于相同数据可能采取不同的命名规范和不同的计量单位,因此需要将数据命名和和数据格式统一化然后映射到一个标准数据库表中,从而改善抽取数据的质量。
3 面向开源社区的Web数据抽取的技术路线及实施方案
3.1 数据采集
开源社区既包含如GitHub,OpenHub,SourceForge等协同开发社区,又包含如Stackoverflow,ESDN,Slashdot等知识共享社区,在对这些社区中的开源数据资源进行抽取之前,首先我们需要通过网络爬虫来爬取这些开源社区的Web页面,并以HTML文件的形式存入源数据库中,作为待抽取的原始数据。
3.2 Web数据抽取框架业务流程
经过实验研究,我们确定了面向开源社区的Web数据抽取框架的业务流程:首先,页面下载模块从目标站点源数据库中下载原始数据,即待抽取的HTML网页,然后数据抽取模块根据待抽取页面的抽取规则对HTML网页进行抽取,抽取到的数据经数据持久化模块存储到数据库中,同时抽取出错的页面由错误处理模块转存到抽取失败数据库中。该抽取框架具备通用性和可移植性的特点。一方面能够实现对形态各异的不同开源社区的数据抽取,另一方面该抽取框架提供了一个通用的抽取模板,当对一个新的开源社区进行抽取时,能够复用其他社区抽取程序的大部分代码,只需要改动抽取模板中的部分抽取规则和变量名称即可。
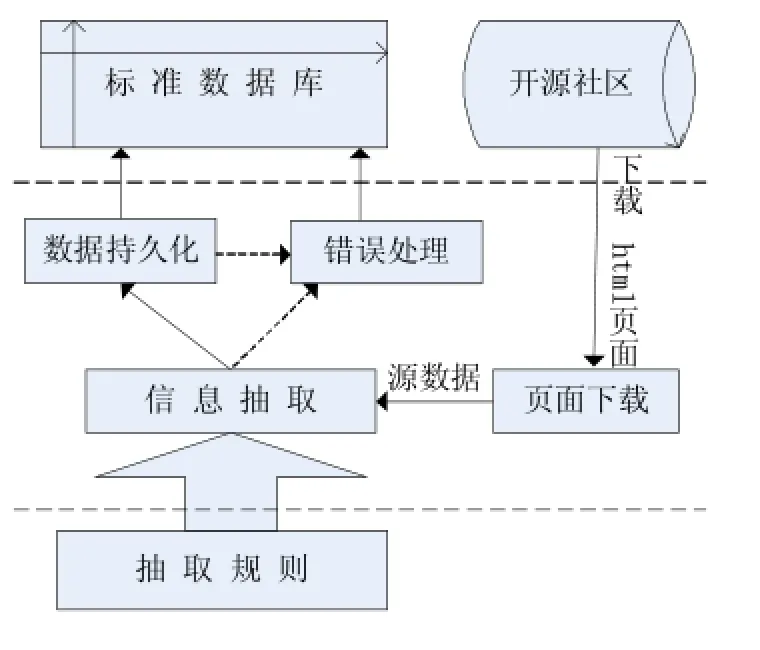
图1 Web数据抽取框架业务流程图
在框架搭建的过程中复用了一些成熟的开源软件技术,例如MYBatist和Xsoup,提高了开发的效率。MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架,它消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。Xsoup是基于Jsoup开发的HTML抽取器,提供了XPath支持,Xsoup具有解析时间和抽取时间快,XPath解析错误提示全面的优点。
3.3 XPath定位路径的选取
抽取规则是对应于待抽取数据的一个位置路径表达式,通过这个路径表达式我们可以在HTML页面中定位到待抽取数据对其进行抽取。通过实验对比,我们选定XPath定位路径作为Web数据的抽取规则。XPath是可扩展路径语言XML Path Language的简称,它是一个W3C标准,主要用于标识XML文档的各个部分,它将一个XML文档看作一棵树,我们可以称之为“节点树”。XML文档中的元素、属性、文本、注释、处理指令、命名空间等都是这棵树的节点,分别称为元素节点、属性节点、文本节点、注释节点、处理指令节点、命名空间节点。XPath可以使用简明的、基于字符串的语法对XML文档的各个组成部分进行定位,这种语法就是位置路径表达式,通过XPath,我们可以精确地查找到XML元素节点的位置。
3.4 数据一致性与完整性验证
为了保证数据抽取的质量,抽取到的数据还需要经过进一步的验证和处理。。通过抽取规则的定位从不同开源社区抽取到的数据信息,若其数据格式不符合我们的存储格式规范,必须处理成规范的格式,才能存入到数据库中。另外一个开源社区的待抽取页面中通常含有众多的待抽取元素,例如在协同开发社区OpenHub中需要抽取的数据项有:项目源码、项目名称、项目描述、项目标签、相似项目、活跃时间、最后提交时间等几十项,对于抽取结果的完整性必须加以验证。我们在面向开源社区的Web数据抽取框架中集成了数据验证模块,实现了对抽取数据的一致性与完整性的验证和处理。
4 结语
通过对面向开源社区的Web数据抽取方法研究,我们构建了一个通用的,健壮的,可移植性良好的Web数据抽取框架,实现了对不同开源社区中开源数据资源的准确抽取,为下一步开展基于开源社区中海量Web数据的全面分析,科学评估,深度关联等相关研究工作提供了强有力的数据支撑。
[1]吴共庆.基于标签路径特征融合的在线Web新闻内容抽取[J].软件学报,2016,(3):714-727.
[2]丁晓梅.Web信息抽取规则的设计和实现探讨[J].教育,2015,(33):247.
[3]W Wei,S Shi,Y Liu,H Wang.Extraction Rule Language for Web Information Extraction and Intergration.Web Information System& Application Conference,2013:65-70.
[4]Y Kim,J Park,T Kim,J Choi.Web Information Extraction by HTML Tree Edit Distance Matching.ICCIT,2007:2455-2460.
[5]Fei Sun,Dan-dan Song,Le-jian Liao.DOM Based Content Extraction Via Text Density Proceeding of the 34th International ACM SIGIR conference on Research and Development in Information Retrieval,2011:245-254.
[6]L S Zhang,P Shi.An Effective Wrapper for Web Data Extraction and Its Application.International Conference on Cumputer Science&Education.2009:1245-1250.
[7]Suhit Gupta,Gail Kaiser,David Neistadt,Peter Grimm.DOM-Based Content Extraction of HTML Documents Proceedings of the 12th International Conference on World Wide Web,207-214.
[8]张丽娜,陈俊杰,赵丽欣.基于HTML Parser的BT种子网页信息抽取[J].电脑开发及应用,1010,(03):59-61.
[9]隋玉航.基于WebHarvest的中文财经新闻搜索引擎的设计与实现[D].华中科技大学,2011.
[10]欧健文,董守斌,蔡斌.模板化网页主题信息的提取方法.清华大学学报(自然科学版),2005,45(S1):1743-1747.
Research on the Method of Web Data Extraction from Open Source Communities
ZHANG Fang,YIN Gang,WANG Tao,YU Yue
(College of Computer Science,National University of Defense Technology,Changsha 410073)
Open source community,which consists of collaborative development community and knowledge sharing community,assembles a huge amount of open-source data resources together.How to obtain these data precisely and efficiently from numerous open source communities with various page structures is a prerequisite for comprehensive analysis and deep correlation.Describes the research process of web data extraction method and achieves the accurate extraction of Web data from open source communities.
Open Source Community;Web Data Extraction;Collaborative Development Community;Knowledge Sharing Community
1007-1423(2017)04-0027-04
10.3969/j.issn.1007-1423.2017.04.006
张方(1990-),男,河南南阳人,硕士研究生,研究方向为数据挖掘
尹刚(1975-),男,博士,副研究员,研究方向为可信软件、分布式计算与信息安全
王涛(1984-),男,博士,助理研究员,研究方向为数据挖掘技术
余跃(1988-),男,博士,助理研究员,研究方向为软件工程
2016-12-01
2017-01-20
