基于大数据的通信信息诈骗治理模式研究
2017-03-27
(中国移动通信集团上海有限公司,上海 200060)
基于大数据的通信信息诈骗治理模式研究
罗汉斌,薛峥
(中国移动通信集团上海有限公司,上海 200060)
鉴于当前通信信息诈骗形势严峻,需要提供行之有效的治理模式,通过建立基于大数据挖掘分析的治理平台,研究分析各类诈骗电话特征,建立有效的分析模型,实现对通信信息诈骗有效治理。
诈骗电话;号码资源库;行为分析
1 引言
近年来欺诈电话在整个骚扰诈骗类电话的比例逐年上升,且危害程度远远大于普通的骚扰电话。
根据互联网公司、公安部门统计数据显示2015年诈骗电话超过3亿次,电信诈骗发案59万余起,涉案金额222亿元。境内单案件平均损失为1.85万元,境外案件平均损失为11.12万元;跨境电话诈骗形式呈现案件数量快速增长,单案件平均损失大的趋势。
2015年,上海因电信诈骗犯罪导致群众经济损失15.1亿元。全市共破获电信诈骗案件4209起,同比上升64.8%;抓获犯罪嫌疑人1393名,同比上升20.2%;捣毁平台、窝点共计197个,同比上升18.7%。但是,电信诈骗案的破案率和赃款追回率却极低。
2 研究目标
鉴于目前的形势,中国移动上海公司项目组开展了基于大数据的通信信息诈骗治理模式研究与应用试点工作,主要包括以下几方面工作。
充分利用内外部资源优势,建立相关数据资源库,完善并丰富违规电话应用场景,以用于违规电话建模及治理;围绕违规电话治理,主要开展基于主被叫号码的机器学习、以及基于被叫号码的诈骗事件场景模型研究与试点,并做好违规电话号码的验证,以及可视化呈现等工作;梳理通信信息诈骗整体流程分析,基于海量信令数据,结合公安、互联网等相关数据,实施等多环节联动分析。
为实现研究与试点工作的相关内容,项目组制定了如下具体的项目目标:
建立完善敏感号码库及黑名单库,通过搜集整理分析,获取并建立基于公检法号码、银行客服、运营商客服、电商号码的敏感号码库,通过系统分析公安等反馈建立黑名单号码库。
欺诈电话识别提高精准度,疑似欺诈电话识别如何验证,并通过验证的结果改进识别方法和手段。同时分析定位出危害性高的欺诈电话作为重点打击对象尤为必要。
理清欺诈流程,便于有效治理,欺诈分子在实施欺诈过程中,往往采用预先编辑好的欺诈剧本,逐步诱骗用户上当,且剧本往往随着外界事件环境变化和时间的推移而发生变化,需要采用有效的方法,识别出其欺诈流程,根据欺诈所发生的不同阶段采用对应的手段加以治理。
3 研究方法
3.1 号码资源库研究
在各类欺诈电话中,仿冒类欺诈电话往往占有比较大的比例,且此类电话一旦用户上当,往往损失惨重。在诈骗过程中,此类欺诈电话一般都会涉及到仿冒公安、银行、客服的情况,因此针对此类号码建立号码资源库,对后续的数据分析会起到很大的帮助。项目组将号码资源库划分为两大类,分别是黑名单号码库以及敏感号码库。
3.1.1 黑名单库
黑名单号码是已经经过确认存在欺诈呼叫行为的号码。涉及仿冒各省市公安局、派出所号码,仿冒各类电商、银行、证券公司客服号码,冒充各类警官、银行工作人员等手机号码。
3.1.1.1 特征及来源
黑名单号码,包含各类已被确认的欺诈号码,同时根据黑名单号码的危害程度,将黑名单号码建立欺诈级别加以区分。黑名单号码的认定主要包括以下来源:公安提供的涉案号码;互联网公司确认的涉及欺诈的号码;系统识别并经过公安反馈确认的号码。
3.1.1.2 黑名单号码库的优缺点
通过对黑名单号码库在实际分析中的应用,项目组发现,黑名单号码库房具有明显的优缺点。
优点:识别效率高,仅需将待查信令数据与黑名单号码进行简单比对,即可确认是否为欺诈呼叫,操作简单;且一点号码被标记,对于假冒警察、银行工作人员等有可能不具备其他欺诈特征的号码也能高效识别。
缺点1:生命周期短,此类欺诈使用的主叫号码一般生命周期都非常短,绝大部分欺诈号码活跃周期较短,超过90%的号码仅活跃1-5天,仅有个别号码,其活跃周期达到10天以上。说明欺诈分子在实施欺诈的过程中,为了逃避管控,选择在很短的时间内更换号码的的方式,因此高效的抓取号码特征,可以迅速分析、有效筛出不断变化的号码。
缺点2:号码容易变异,黑名单号码库目前主要包括两大类,仿冒类号码及普通的手机号码,其中仅有用于冒充警官、银行工作人员等等的手机号码,基本不存在变异情况,其他仿冒类号码很容易出现变异情况, 该号码一旦变异,其黑名单号码本身就失去了比对的意义。
鉴于上述缺点的存在,仅仅基于黑名单库进行号码特征分析以及诈骗治理模式研究势必存在很大的局限性,为解决这种局限性,项目组引入了敏感号码库做黑名单号码库的必要补充。
3.1.2 敏感号码库
3.1.2.1 敏感号码库建立的机制
项目组针对敏感号码采用模糊匹配方式,通过此方法可有效的解决号码变异快和生命周期短的问题。而实现模糊匹配的基础即需要一个全面的基础敏感号码库作为模糊匹配模板。
3.1.2.2 敏感号码分类
为了便于后续模型建立,项目组将敏感号码依据其特征,进行分类,划分为公检法号码类、金融号码类、运营商号码类、电商号码类以及其他公众号码类等多个类型。
公检法号码:包括110、公安局、检察院、法院、派出所等职能部门号码。
金融号码:包括各大银行5位客服号码,信用卡中心,证券基金公司等对外提供客户服务的相关号码。
运营商号码:包括移动、联通、电信客服号码、充值平台号码以及其他对外提供服务的相关号码。
电商号码:包括阿里、腾讯、京东等对外提供服务的号码。
其他公众号码:包括社保、医保、各类保险公司、电力、燃气等相关部门对外提供服务的号码。
3.2 治理模型研究
3.2.1 基于敏感号码库的分析模型
3.2.1.1 模型建立依据
敏感号码库的模型主要应用于主叫号码变异,修改的情况,此类呼叫主叫号码进行了伪装,显示为(或接近)公检法、客服等公众号码,使得被叫容易上当受骗;为了躲避现网系统的防范,犯罪分子往往对相关号码进行修改与变异,增加其隐蔽性。为识别此类呼叫,项目组采用主叫号码与敏感号码及黑名单号码库模糊匹配的方式进行识别。
3.2.1.2 基于敏感号码库的模糊匹配分析模型建立流程
该流程主要通过对信令数据中主被叫号码与敏感号码库中的号码进行模糊匹配计算获得匹配度,并根据匹配度确定号码的欺诈可能性。具体匹配方式如下:
号码匹配比对:系统将呼叫记录的主叫号码分别与敏感号码库和黑名单号码库中的号码进行匹配。
匹配度计算:考虑到欺诈号码的伪装性及变异性,在进行匹配时不是简单进行全号码匹配,而是对号码进行模糊匹配并进行匹配度计算,对号码相对应的每一位的匹配程度进行累加,匹配度越高的号码,其欺诈可能性也越高。
变异度计算:对于个别号码位置发生移位和变异的主叫号码,也能够标记出来,即通过变异度匹配计算公式,计算出号码的变异程度。
特征评估:根据匹配度及变异度建立号码分级,达到高匹配度的即认为疑似欺诈号码,因此通过此方法可以有效的识别出各类变异欺诈号码,提供系统的准确率和覆盖率。
3.2.1.3 匹配度计算
模糊匹配模型准确性的基础是基于敏感号码库的匹配度计算,即通过公式算法计算出目标号码与敏感号码的差异情况,作为是否为欺诈号码的判别标准之一。
本次研究对于号码匹配度计算主要运用了以下算法。
Karp-Rabin(KR)算法:利用hash函数的特性进行字符串匹配的。 KR算法对模式串和循环中每一次要匹配的子串按一定的hash函数求值,如果hash值相同,才进一步比较这两个串是否真正相等。
Horspool算法:将主串中匹配窗口的最后一个字符跟模式串中的最后一个字符比较。如果相等,继续从后向前对主串和模式串进行比较,直到完全相等或者在某个字符处不匹配为止(如图1中的α与σ失配) 。如果不匹配,则根据主串匹配窗口中的最后一个字符β在模式串中的下一个出现位置将窗口向右移动。
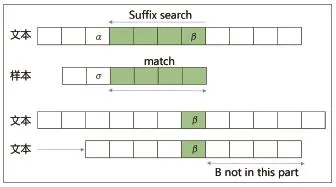
图1 Horspool算法示意图
基于以上匹配度算法,项目组确立了如下的匹配度范围:
全匹配计算(高匹配) :判断目标号码是否与敏感号码所有位置完全匹配。
尾匹配计算(高匹配):判断目标号码是否尾部与敏感号码匹配,头部不计算。
中间匹配计算(中匹配) :判断目标号码是否中间部分与敏感号码匹配,头部和尾部不计算。
变异匹配计算(高匹配) :判断目标号码是否通过去位可以与敏感号码匹配。
变异+尾部匹配计算(中高匹配) :判断目标号码尾部是否通过去位可以与敏感号码匹配。
变异+中部匹配计算(中匹配) :判断目标号码中部是否通过去位可以与敏感号码匹配。
图2为模糊化匹配示例。
3.2.2 基于欺诈流程的关联度分析模型
3.2.2.1 模型建立依据
从海量系统数据分析以及公安相关报案涉案号码上可以看出,欺诈电话基本都不是孤立存在的,在大量的电信诈骗案件中,往往一个被叫号码(被骗用户)会涉及到1个以上的主叫号码(欺诈号码),而这些欺诈号码又会涉及到更多其他被叫号码。
就诈骗流程上讲,对公安报案数据进行分析,一般涉及到“透支”、“洗钱”的诈骗,会遵循派出所、警官、银行、警官等来电的流程;涉及到“快递”、 “中奖”的诈骗,会遵循快递客服、电商、银行等来电的流程,即诈骗过程涉及多次通话。因此,项目组判定诈骗电话基本不是孤立存在的,在大量的电信诈骗案件中,被害用户在被骗过程中,一般都会涉及到多个主叫号码(诈骗号码)的呼入,而这些诈骗号码又会扮演不同的“角色”。
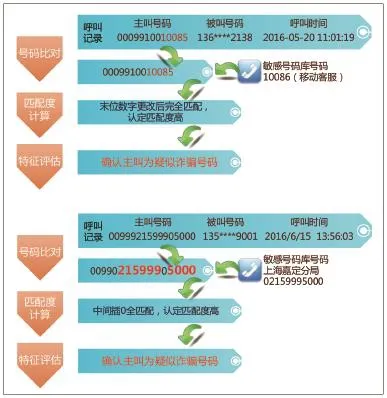
图2 模糊化匹配示例
此外,就诈骗者本身而言,也不会仅针对单个用户进行欺诈,而是采取广撒网的方式,即同一个诈骗号码会涉及多个被叫用户。
鉴于图3中展现的欺诈流程单一被叫(被骗用户)涉及多个主叫号码以及单一主叫(欺诈号码)涉及多个被叫的特征,项目组认为建立一套欺诈流程的关联度分析模型尤为必要。其中,建模依据来自公安等反馈的案例信息以及海量数据分析形成的特征样本。
3.2.2.2 欺诈流程关联分析模型的建立流程
欺诈流程关联分析模型的建立流程如下:
(1)被叫号码呼叫提取:系统根据模糊匹配模型筛选出对应的被叫号码,将该被叫号码在周期内全量呼叫信息从原始信令数据中提取处理;
(2) 呼叫关联分析:通过聚类分析及交叉关联分析关联相关主叫号码;
(3) 欺诈流程模型匹配:结合关联后主叫号码与欺诈流程模型进行匹配;
(4) 关联评估:根据匹配程度,判断是否存在欺诈可能。
3.2.2.3 欺诈流程关联分析算法FP增长算法
欺诈流程关联分析模型建立的关键是关联分析,即如何从多样的欺诈案例中查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。本次研究主要采用了FP增长算法以实现相关需求。
FP增长算法原理是将事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度。建立 FPTree树之后,再遍历整棵树获取满足一定置信度的关联规则。
在实际建模过程中,项目组将大量欺诈案例作为分析事务,并根据涉案内容将类似案件划分相同的事务集合,同时将涉案环节提取出作为事务项,利用算法,计算支持度和置信度,从而发掘频繁项集。

图3 诈骗流程示例
3.2.2.4 欺诈流程关联算法(聚类算法) k-means算法
通过对大量欺诈电话大数据分析研究发现,欺诈电话在行为上往往具备其独有的特征,通过聚类分析方法可以抽象出其同质性及区别与普通呼叫的异质性,从而获得欺诈电话的特征性描述。
k-means算法原理:接受输入量k;然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k-means 算法基本步骤如下:
(1) 从n个数据对象任意选择k个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象);
(4) 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2)。
项目组提取了主叫号码原始信令数据集合X1-Xn的相关属性C(振铃时长,拨打时间,呼叫间隔,被叫号码特征,呼叫频次,通话时长等指标),从中提取质心,并计算各主叫号我们提取到原始数据的集合为码属性相异度,重复该步骤直至聚类结果不在发生变化。由此可以得出欺诈呼叫区别于其他呼叫的行为特征。

图4 k-means 算法示例
3.2.3 基于各模型的组合处理提高分析精准性
上述所建立的各类分析模型并不是孤立存在,而是相互关联,彼此组合,在完成建模的基础上,项目组通过各模型间的组合处理,有效提高了数据筛选的准确性。
对各类模型筛选出的黑名单号码或欺诈号码进行统计学统计预测分析,可获得此类号码呼叫中统计学特征,并且由于号码的不断更新,此类特征可准实时反映现网实际情况,可有效分析出更多欺诈呼叫。
此外,根据聚类分析算法,如图5所示,在筛选出疑似被骗用户的同时,还可根据对关键事件的综合判断,确定被骗用户的级别,即高危用户(深度诈骗:即该用户被诈骗的可能性极大,很可能马上或已经造成了财产损失)、中低危险用户(浅度诈骗:即该用户可能仅仅是接到过诈骗电话,目前被骗并造成财产损失的可能性不大,但不排除后续随着诈骗流程推进,受骗上当的可能)。
3.3 总体分析流程
结合上述的分析方法项目组建立了一套有效的数据分析模型体系,其处理流程如下:
针对单一的呼叫记录,进行号码特征分析(模糊匹配分析)计算该呼叫的敏感号码或黑名单号码匹配度;
若属于高匹配度呼叫,则本别针对主被叫号码建立关联索引表,寻找与主被叫号码相关联的其他呼叫;
对关联后的呼叫中的主叫号码进行主叫呼叫行为分析及号码匹配分析,并标记出疑似号码;
对关联后的呼叫中的被叫号码进行被叫呼叫行为分析,并标记是否为高危被叫号码;
完成以上流程,标记并输出疑似欺诈呼叫、疑似欺诈号码、疑似高危被叫号码,同时完成号码去重。
相关流程示例见图6所示。
4 研究验证
为了验证研究模型的准确性,目前项目组已在上海移动开展了欺诈电话分析系统试点,其中原始数据主要采集了信令监控系统获取的呼叫事件信令,结合从上海公安、互联网公司等相关数据进行系统分析。
通过数据分析模型的运行,每日可输出疑似欺诈呼叫、疑似高危用户号码及相关报表。同时向上海公安提供疑似高危用户号码及呼叫列表,并获取上海公安反馈结果。
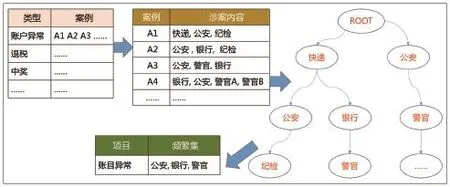
图5 聚类分析算法示例
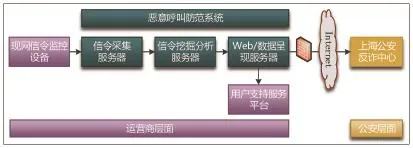
图6 试点组网示例
4.1 试点组网
试点系统由采集服务器,挖掘分析服务器,Web/数据呈现服务器及用支持服务平台等几部分组成,如图6所示。
4.2 数据准备
为保证治理模式研究的准确性,数据准备阶段需要做到数据全面、准确,因此本次研究收集了多方面的数据作为研究基础,并对数据做了必要的有效性筛选和规整。
4.2.1 数据来源
数据来源主要考虑包括以下内容:
从信令监控系统获取的A口呼叫事件信令;从省公司采集互联互通关口局呼叫事件信令;从公安获取的黑名单数据;互联网数据;敏感号码库;黑名单库。
4.2.2 信令数据采集
原始信令数据经过数据采集器,传输到采集服务器,通过过滤、筛选、规整、合成、输出统一格式数据表表单。
4.3 阶段成果
根据上海公安反馈,2016年5-7月上海境内诈骗案件数量同比下降12.1%, 冒充公检法号码诈骗案件同比下降47.2%,案值同比下降34.9%。
5 后续工作
防范打击通讯信息诈骗是一项系统性、持续性的工程,基于前期成果,后续本项目将继续不断充实号码资源库,并持续完善诈骗流程模型,继续分析整理相关案例,完善已有诈骗流程关联模型,不断发掘新的诈骗流程并建立相关模型,以期进一步提升疑似诈骗通话的识别率。
Research on the management mode of communication information fraud based on big data
LUO Han-bin, XUE Zheng
(China Moblie Group Design Institute Co., Ltd. Shanghai Branch, Shanghai 200060, China)
View of the current form of communication information fraud is serious, need to provide effective governance model, based on the analysis of large data mining management platform, research and analysis of various types of telephone fraud characteristics, establish the analysis model effectively, realize the effective governance of telecommunications fraud information.
telephone fraud; number library; behavior analysis
TN929.5
A
1008-5599(2017)03-0071-06
2016-11-24
