数据融合方法在医疗案例检索中的应用
2017-03-27周新科邬艳艳
周新科,邬艳艳
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
数据融合方法在医疗案例检索中的应用
周新科,邬艳艳
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
针对当前医学检索领域中依据医疗案例进行搜索时准确率较低的问题,从数据融合的角度来考虑提升医疗案例检索的性能。在公共有效数据集上的实验表明,采用数据融合算法能够有效提升医疗案例检索的有效性。其中在RP指标上基于多元线性回归的线性组合法与倒数规范化组合的策略取得了最佳结果,且超过了原有的最佳结果2.85%。
医疗案例检索;数据融合;线性组合法
医生所做临床决策的主要依据是个人的经验以及相关病情的案例资料。相对于需要长期的积累个人经验,相关病情的案例资料可从已有的医学资料中寻找到。然而从海量的医学资料中找到医生所需的信息较为困难。这就需要一个能为临床医生提供快速检索医学资源的检索系统了。医疗案例检索系统(Medical Case-based Retrieval,MCR)正是为此而设计的。
自2009年以来,ImageCLEF[1]评价活动每年举办一次基于医疗案例的检索任务,其是属于跨语言评价论坛中图像检索研究部分的。该任务允许研究人员使用常见的大型数据集来评估他们的系统。这是一个比较接近临床工作流程的任务。在2013年的医疗案例检索任务[2]中使用的案例数据集包含了7.5万个能在生物医学文献的出版期刊中找到证据的案例描述,其中包括了约30万张与医疗案例相关的图像文件。2013年参加该任务的小组中共有7个小组提交了结果。在这7个小组提交的42个结果中,表现最优的是文本检索,多模式结合的检索方式次之,图像检索的结果表现最差。以下是2013年在该任务中提交的最优结果(括号中的是2012年[3]的最优结果,MAP代表平均精度值[4]):
通过文本检索的最优结果是MAP=24.29%(17%);通过多模式结合的检索方式的最优结果是MAP=16.08%(10%);通过图像检索的最优结果是MAP=2.81%(3.7%)。
1 数据融合技术
在上述结果中可看到,文本检索作为传统信息检索领域的主体,其性能表现是最好的,这是因其是发展历史最久,技术最成熟的;而图像检索的性能表现最差是因为图像检索的发展并不像文本检索一样有着相对成熟的技术。检索性能居中的多模式结合的检索方式则主要指的是数据融合方式了。
数据融合在信息检索领域中的又称为信息融合或元搜索,原本应用于多传感器处理,其主要目的就是融合多个信息源来提高检索性能[5]。在近年来,数据融合被普遍应用于诸多的领域例如:神经网络,多用传感器,分类等,以此来提高系统的性能。依据融合的等级不同,数据融合又可分为:信号级,特征级以及决策级[6]。信号和特征级融合属于早期融合,决策级融合属于后期融合。在过去的多年中,许多融合方法被提了出来,例如:combSUM,combMNZ以及线性组合法等。
在医疗案例检索任务中,其允许文本检索系统间的融合,图像检索系统间的融合,以及文本和图像检索系统的多模式融合。
Zhou等人研究并概括了经典的分数融合方法combMAX,combSUM和combMNZ,其的结论是对数logsitic模型是比较稳定的得分归一化的策略[7]。Gkoufas等人用线性组合法对2009和2010年的ImageCLEF的医疗案例检索数据研究评价后得出结论:在该数据集上融合文本和图像的检索结果不能提升检索结果在MAP指标上的性能[8]。
2 算法原理
实验中选用了3种后期融合方法及两种分数规范化方法来进行试验,以测试不同的融合方法和不同的分数规范化方法的组合中哪一种策略能够更好地提升医疗案例检索的性能
2.1 数据融合算法
假设现在有一组文档集合D和一组检索系统IR={iri}(1 ≤i≤n)每个检索系统为查询q检索文档集合D,从而每个系统都针对每个查询q检索出一个排好序的文档列表Li=
combSUM[9]
(1)
式中,si(d)表示在每个检索系统中文档d的得分;n表示需要融合的系统个数;g(d)表示,文档d通过融合后获得的全局分值,此外,如果在某个系统中文档d未被检索到,则si(d)设置为0。
combMNZ[10]
(2)
此处m表示的是检索到该文档d的检索系统的数量。
线性组合法[11-13]
(3)
其中,wi是分配给检索系统iri的权重。线性组合法较为灵活,其可给不同的检索系统设置不同的融合权重。其是combSUM一个更通用的形式,当wi设置为1时,线性组合法就变成combSUM方法了。如何分配权重是重点。实验中采用多元线性回归的技术来获取每个系统的权重[14]。该方法需要在一组数据上训练并建立一个多元线性回归模型。训练数据中包含各个参与融合系统提供的检索到的文档的有效分数信息,以及所有文档的相关评价信息。通过使用最小二乘法来尽可能缩小文档的得分与真实相关性之间的差值,最后建立的回归模型的系数就是分配给参与融合的系统的权重。
2.2 得分规范化方法
不同的检索系统对返回的文档列表中文档相关性打分的标准往往不同。有的检索系统给相关文档分配的得分是介于0~1之间的,有的则是-1 000~0之间的,各个系统的得分评价标准不同,因此有必要将各个系统之间的得分统一,在实验中使用的是两种常用的得分规范化方法。
0~1规范化方法[15]
(4)
其中,mini和maxi表示该检索系统中对于某个query检索出所有的文档中的最低得分和的最高得分;si(d)是系统分配给文档d的得分;scorei就是文档d规范化后的得分。
倒数规范化[16]
(5)
其中,ri(d)表示文档d在检索系统返回的结果列表中的排名;k是常数,一般设置为60。
3 实验设置与结果
实验中将3种融合方法和两种规范化方法进行组合使用。选用的数据是2013年ImageCLEF中医疗案例检索任务里提交的检索结果。其中,5个文本检索的结果由5个排名靠前的小组所提供。图像检索仅有3个小组提交了结果,因此实验选用了这3个小组提交的全部5个结果。实验中使用Treceval 9.0版本的评价程序来进行评价,选用的评价指标有4个:平均精度值(MAP)、召回率(RP)、前10个文档的平均精度(P@10)和前30个文档的平均精度(P@30)。实验选用的文本检索结果和图像检索结果数据如表1和表2所示。表3~表5所示为不同数据在使用不同融合策略情况下的融合结果,其中MR-Fusion表示基于多元线性回归的线性组合法,粗体字表示在某指标下的最大值。

表1 实验使用的文本检索的结果

表2 实验使用的图像检索的结果
表3所示,在不同融合策略下文本融合的结果。从表中可观察到采用基于多元线性回归的线性组合法与0-1规范化组合的策略能够有效提升MAP和RP的指标,提升效果分别为4.94%和1.09%。而相对于其他融合策略,使用基于多元线性回归的线性组合法与倒数规范化组合的策略对P@10和P@30指标的提升效果较好,其提升效果分别为10.53%和0.50%。此外,combSUM与combMNZ在使用0-1规范化的情况下,其融合结果的MAP指标也超过了原始最佳的检索结果。在P@10指标上,除了combSUM与0-1规范化组合的策略以外,其余融合策略都超过了原始最佳检索结果。
表4所示,使用不同融合策略融合图像检索的结果。在MAP和P@10指标上,只有基于多元线性回归的线性组合法与0-1规范化组合的策略能够在原有最佳结果的基础上有所提升,提升效果分别为3.57%和2.27%。在RP指标上基于多元线性回归的线性组合法与倒数规范化组合的策略取得了最佳结果,且超过了原有的最佳结果2.85%;在P@10指标上该融合策略与原有最佳结果持平;在P@30指标上,该融合策略虽然取得了最佳的结果,但未超过原有最佳结果。
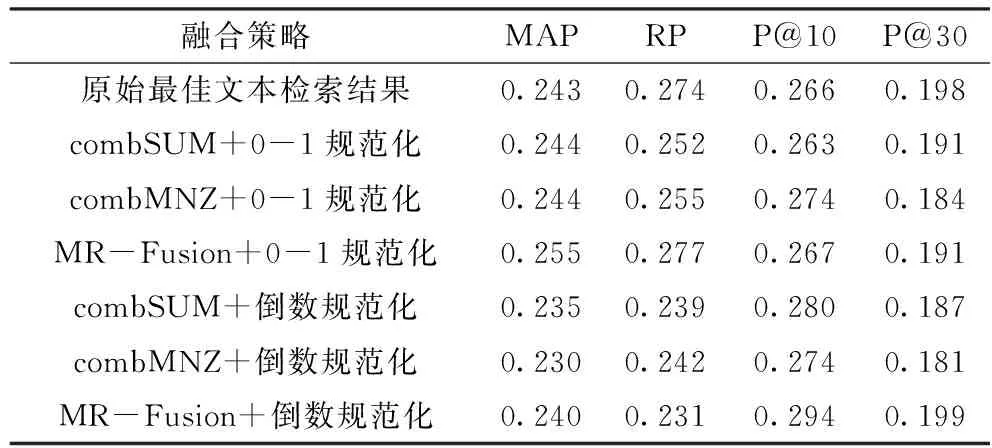
表3 文本检索融合结果

表4 图像检索融合结果
表5所示,使用不同融合策略同时融合文本与图像检索的结果。表中结果显示,在MAP和RP指标上,只有基于多元线性回归的线性组合法与倒数规范化组合的策略超过了原始最佳结果,其提升效果分别为3.95%和1.82%。在P@10指标上,只有基于多元线性回归的线性组合法超过了原始最佳检索结果,在使用0-1规范化和倒数规范化的时候,该方法在P@10指标上的提升效果分别为4.14%和4.89%。而在P@30指标上,只有combMNZ与0~1规范化组合的融合策略超过了原有最佳结果,提升效果为2.53%。

表5 文本+图像检索融合结果
4 结束语
数据融合方法是在原有检索结果的基础上,使用融合算法将多个检索结果组合,以得到一个新的更有效的结果。而使用了不同的数据融合的方法与不同分数规范化方法对2013年医疗案例检索任务中提交的结果进行融合实验后,其结果表明使用数据融合方法提升医疗案例检索的性能是可行的。且从实验结果来看,使用多元线性回归来优化融合权重的线性组合法对医疗案例检索的提升效果较好。同时,在融合过程中,对分数规范化方法的选择也会影响最终融合的效果。相信随着医疗案例检索研究的深入,数据融合能够发挥更大的作用。
[1] Caputo B, Muller H, Thomee B, et al. ImageCLEF 2013: the vision, the data and the open challenges[C].Korea:Information Access Evaluation, Multilinguality, Multimodality, and Visualization,2013.
[2] Herrera A G S D, Kalpathy-Cramer J, Demner-Fushman D, et al. Overview of the Image CLEF 2013 medical tasks[C].Korea:Clef Working Notes,2013.
[3] Müller H, Herrera A G S, Kalpathy-Cramer J, et al. Overview of the ImageCLEF 2012 medical image retrieval and classiFIcation tasks[C].Istanbul:CLEF 2012 Working Notes,2012.
[4] Singhal A. Modern information retrieval: a brief overview[J].Bulletin of the IEEE Computer Society Technical Committee on Data Engineering,2001,24(24):35-43.
[5] Wu S,Mcclean S. Performance prediction of data fusion for information retrieval[J]. Information Processing & Management,2006, 42(4):899-915.
[6] Valet L, Mauris G, Bolon P. A statistical overview of recent literature in information fusion[J].Aerospace & Electronic Systems Magazine IEEE,2001,1(3):7-14.
[7] Zhou X,Depeursinge A,Muller H. Information fusion for combining visual and textual image retrieval[C].Beijing:20th International Conference on Pattern Recognition (ICPR),2010.
[8] Gkoufas Y,Morou A,Kalamboukis T. Combining textual and visual information for image retrieval in the medical domain[J]. Open Medical Informatics Journal,2011(5):50-7.
[9] Fox E A, Shaw J A. Combination of multiple searches[C].Japan:Text Retrieval Conference,1993.
[10] Fox E A, Koushik M P, Shaw J A, et al. Combining evidence from multiple searches[C].CA,USA:Text Retrieval Conference,1992.
[11] Vogt C C, Cottrell G W.Predicting the performance of linearly combined IR systems[C].Itaty:International ACM SIGIR Conference on Research and Development in Information Retrieval,ACM,1998.
[12] Vogt C C,Cottrell G W.Fusion via a linear combination of scores[J].Information Retrieval,1999,1(3):151-173.
[13] Wu S. Linear combination of component results in information retrieval[J].Data & Knowledge Engineering,2012,71(1):114-126.
[14] Wu S,Mcclean S.Improving high accuracy retrieval by eliminating the uneven correlation effect in data fusion[J].Journal of the American Society for Information Science & Technology, 2006, 57(14):1962-1973.
[15] Lee J H. Analyses of multiple evidence combination[J].Acm Sigir Forum,1996, 31(SI):267-276.
[16] Cormack G V, Clarke C L A, Buettcher S. Reciprocal rank fusion outperforms condorcet and individual rank learning methods[C].Boston, MA, USA:International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR,2009.
Research on Application of Data Fusion Methods in Medical Case-based Retrieval
ZHOU Xinke,WU Yanyan
(School of Computer Science and communications Engineering, Jiangsu University, Zhenjiang 212013, China)
In today’s society, with the growth of the medical data, how to quickly find the needed information in the massive medical data is a challenge. To improve the low performance of medical cased-based retrieval in medical field, data fusion technology is considered in this paper. This method can consider the characteristics of documents in different information retrieval systems and re-calculate their scores according to the fusion algorithm. Finally it will re-rank all the documents. Experiments on the public data sets show that data fusion can effectively improve the performance of medical case retrieval. And using the linear combination method can achieve a better improvement.
medical case-based retrieval; data fusion; linear combination
2016- 05- 05
周新科 (1990-) ,男,硕士研究生。研究方向:信息检索,数据融合。邬艳艳(1989-),女,硕士研究生。研究方向:信息检索,数据融合。
10.16180/j.cnki.issn1007-7820.2017.03.013
TP391.3
A
1007-7820(2017)03-045-04
