软件工程关联数据的自动构建
2017-03-27韩雨豪
摘 要 本文主要基于语义网的引入,对多源异构数据进行语义关联,探讨本体构建、关联抽取、数据发现的方法,以此实现软件工程关联数据的自动构建。
【关键词】软件工程本体 关联数据 本体构建
软件工程数据对软件工程的开发至关重要,但软件工程数据具有多样性,在群体软件开发过程中,为知晓信息、挖掘数据,需要对软件工程关联数据进行构建。本文基于本体的自动构建方法,对软件工程关联数据的自动构建进行探讨,旨在为语义的检索、数据的挖掘提供依据。
1 相关概念
1.1 关联数据
关联数据主要以网络本体语言(OWL)、资源描述框架(RDF)对无序数据、大规模异构进行构建,使其具有语义化和结构化,从而方面计算机进行理解。近年来,软件工程领域中关联数据的应用越来越广泛,使复杂软件工程的数据开发更为简便。在软件工程的开发中,一个团队容易对另一个团队的项目开发构建产生依赖,与此同时,团队之间的协作是确保相关项目顺利完成的重要基础。微软建立的Codebook平台可以借助连接图的建立,连接软件元件及相关团队信息。Iqbal在Kiefer等研究的基础上,通过资源标识符(URI)的统一,从源代码、版本控制系统中对数据进行抽取,以PDF文件格式对关联数据进行构建,利用SPARQL引擎可以完成查询操作。因此,引入关联数据,可以方便处理软件工程的复杂数据。但国内现有研究仅局限于缺陷跟踪、源代码等内容,并未涉及文档、邮件及开发人员信息等数据。
1.2 数据的抽取
目前,国内研究主要是针对关系型数据库-本体概念和关联数据的映射。一般都是基于关系型数据库,对本体概念和关联数据进行构建。此类方法的自动化程度较高,但容易抽取出冗余的关联数据。本研究主要采用定制映射的方式,在关系型数据库中对软件工程关联数据进行抽取。
1.3 数据的发现
数据源信息具有多样性,现有研究主要通过获取已有关联数据的特征,针对特定关联,发现更多软件工程的数据关联。ReLink利用文本相似度、人员身份匹配、时间间隔发现软件变更和缺陷之间的关联;也有开发者借助追踪链图以文本和结构分析的方式发现文档与源代码的关联。由于信息语义分析的不足,借助信息检索技术发现关联数据依然会存在漏洞。本文基于信息检索技术(IR)和语言处理技术(NLP),通过文本和结构的分析,来发现关联数据。
2 本体概念的构建
2.1 构建初始本体概念
基于规则的映射方法,根据关系型数据库元数据对初始本体概念进行构建,构建步骤分为两步:
(1)在关系型数据库中抽取元数据信息;
(2)利用关系映射规则对新概念及概念属性、层次、关系等进行创建。
2.2 本体融合
融合不同数据源中的初始本体概念,识别出相似的初始本体概念,对其进行合并,统一软件工程领域本体。如在开发软件工程的过程中,不同团队的缺陷数据会出现在不同的跟踪工作中。在Bugzilla中,抽取的初始本体Bug概念会表示为“SoftwareEngineering#Bug”。利用本体融合方法,借助概念命名、属性及关系对概念间的相似度进行计算,可以有效合并相同概念。
3 数据的抽取
3.1 关联数据映射
初始本体概念的生成过程中,关系型数据库的表、列、键等元数据均与本体概念建立了相应关系,借助这些关系可以直接对映射文件进行创建,随后通过映射规则可以完成领域本体与结构化数据之间的映射。
3.2 实例消解
对不同关系型数据库的关联数据进行融合,需要合并各结构化元数据中的本体概念,同时,本体实例需要对齐。如Bugzilla中的“Katharina@gmail.com”与Bugfree中的“katrin@hotmail.com”两个实例指的是同一人。另外,在本体实例消解和本体融合中,相似度计算及合并的方法基本相同。
3.3 实例属性消歧
实例消解可以消除实例间的歧义,实例属性消歧能够处理实例合并中属性值的不一致问题。多值属性出现不一致的情况时,可以保留所有属性值。单值属性出现不一致的情况时,需要基于属性出现次数的“投票”方式及其所在实例的度决定属性值。
4 数据的发现
4.1 关联数据的特征
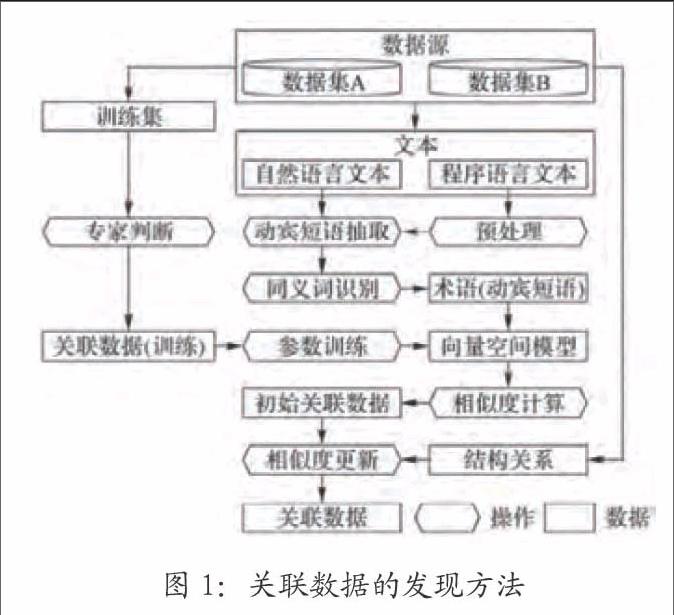
关联数据具有同义词、动宾短语、结构关系三个特征。同义词:软件开发的不同的参与者对同一事物的描述存在差异,但各自的用词用语存在近义或同义的关系。动宾短语:非结构化数据的信息主要采用自然语言进行描述,动宾短语结构含有语句的关键信息,故借助动宾短语可以替代语句表示数据信息。结构关系:同一概念下的实例数据往往存在结构关系,连接实例可以得到结构关系的表达方式。两个实例关联为一个实例时,它们的结构关系一般都是相连的。
4.2 数据关联的重建
参照关联数据的重建方法(见图1),对数据集的非结构化文本数据进行预处理、动宾短语抽取、同义词识别,随后建立向量空间模型,借助机器学习方法计算模型参数的相似度,之后结合数据集中的结构关系数据更新相似度结果,即可发现关联数据。
5 结语
本文探讨了软件工程关联数据的自动构建方法,以便群体软件开发中,信息知晓和协同开发的问题能够得到解决。该方法主要通过领域本体的构建在软件仓库结构化数据中对关联数据进行抽取,同时根据关联数据的三个特征,利用NLP技术IR技术发现软件仓库中潜在的关联数据。后续将采取实验来验证这一方法的自动化程度与有效性,从而证实这一构建方法的可行性。
参考文献
[1]陈兰兰.基于社会网络分析和共词分析的国内关联数据研究[J].图书与情报,2013(05):129-132.
[2]张明卫,朱志良,刘莹等.一种大数据环境中分布式辅助关联分类算法[J].软件学报,2015,26(11):2795-2810.
[3]毛宇星,陈彤兵,施伯乐等.一种高效的多层和概化关联规则挖掘方法[J].软件学报,2011,22(12):2965-2980.
[4]张永娟,陈涛,张珅等.基于Sesame及Rdfizer扩展工具的关联数据应用平台[J].图书情报工作,2013,57(16):135-139.
[5]夏立新,李成龍.基于关联数据的科技报告语义共享框架设计与实现[J].数字图书馆论坛,2015(09):2-9.
作者简介
韩雨豪(1999-),山东省济宁县人。高中学历。现为山东梦巴克网络科技有限公司高级电脑技师,主要从事电脑应用与翻译方面工作。
作者单位
山东梦巴克网络科技有限公司 山东省济宁市 272000
