基于端口识别的网络流量分类模式的改进
2017-03-27王倪
王倪

摘要:随着因特网规模的逐渐扩大,用户对网络提供的服务有了更高的要求,在此背景下流量分类方法的改进与优化得到了计算机网络领域的广泛关注。以往的流量分类往往是根据不同用户和不同端口号来识别,虽然能够准确地定位到某站点中的具体的通信进程,但并不能够对该类数据进行准确的描述,即只能实现在运输层的端口分类,而无法提供应用层的数据分类,从而也就无法实现针对性的网络通信服务。该文针对这一情况展开研究,在传统的端口分类方式的基础上,引入了目前较流行的自适应深度学习机制,采用自组织映射网络算法实现网络流量合理分类,具有一定的参考借鉴价值。
關键词:网络流量;分类模式;端口识别;统计特征
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)03-0052-02
1 概述
随着信息化时代的到来,计算机网络以飞快的速度发展起来,用户规模呈现出爆炸式的增长趋势,且对网络的通信质量要求越来越高;与此同时,基于网络的各种软件也层出不穷,大量不同类型的应用软件导致了在网络中传输的数据类型的差异性较之以往大大增加了,传输的复杂性也随之提高。在此情况下,如何提供一种更加符合网络现状的管理方法,向用户提供更加符合其需求的通信服务成为了当前计算机网络领域研究的重点内容。在诸多的研究课题中,对网络流量的科学分类受到了广泛的关注,通过高质量的流量分类,可以追溯用户的活动情况,从而在一定范围内判断当前数据的传输状况,并可在此基础上实现对网络资源的QoS(Quality of Service)调度,进而为网络的维护和后续扩张提供可靠的依据。除此之外,流量分类还可在网络安全、用户识别、宽带流量计费等方面发挥重要的作用。
传统的流量分类方式是由IANA提出的基于端口号的识别方式,该方式在以往应用服务种类不多的情况下是较为实用的,即根据熟知端口号识别有限数量的不同类型的应用服务进程,但随着网络规模的飞速增长,尤其是随着P2P对等网络的大发展,使得用户数据的类型与日俱增,众多的进程启用了大量的随机端口号,这对数据流量的识别是非常不利的,未来必须加以改进。
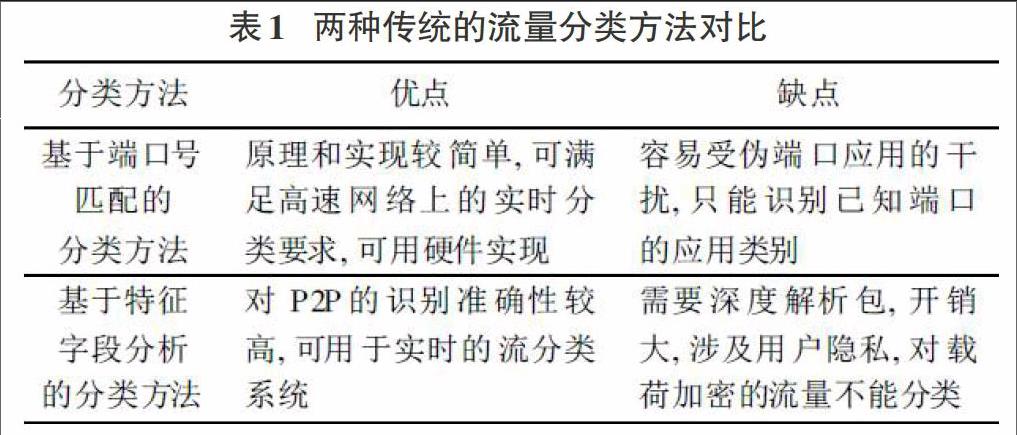
第二种方式是基于特征字段识别的,在早期该字段并没有得到充分的利用,而目前随着数据类型识别需求的不断提高,该字段也被越来越多的通信服务所采用,但随之而来的问题是该字段位于IP数据报的首部,这意味着需要在网络层解决数据类型的差异问题,在通信过程中该数据报经过的路由器将不得不花费大量的资源和时间来解析和识别该字段,这势必会拖慢网络通信效率,同时增加网络拥塞的风险。目前在P2P对等网络中此方法使用较多,但对于实时性要求较高的通信服务而言,此方法导致的通信时延过高,并且会随着应用层服务的改变而失效,表1给出了这两种流量分类方式的对比分析。
表1 两种传统的流量分类方法对比
2 基于机器学习方法的流量分类
随着网络的发展,传统方式已经无法胜任对数据流量进行合理的分类工作,这导致了数据冲突、资源耗费、通信延迟、通信效率不断降低等一系列问题。因此,有研究人员将人工智能领域内的机器学习机制引入到流量分类工作中,针对网络流一些属性的统计信息进行识别,以提高流量分类的准确性和快捷性,效果较为显著,其算法过程如图1所示:
图1 基于机器学习方法的流量分类流程
算法步骤如下:
1)通过统计方法获取流量的特征属性最优组合集
流量属性集通过统计形成网络流的数据包的包头信息得到。在进行统计分析之前,为了减少计算量,提高分析精确度,应对数据包信息进行筛选的预操作,其目的是将与分类需求相关的属性尽可能的保留下来,反之则筛除,从而形成所谓的最有属性集合,随后在针对此集合进行分析,实现事半功倍的效果。在此特征选择的过程中可以采用多种优化算法,如快速统计过滤法FCBF、顺序前进法SFS、相关性特征选择CFS和遗传算法GA等。
2)采用机器学习方法进行分类
机器学习属于人工智能领域内的一个分支,也存在多种不同的优化算法,目前在流量分类工作中得到应用的优化算法有K-近邻K-NN、朴素贝叶斯方法NB、支持向量机SVM等。其中K-NN方法是最早得到应用的一种优化算法,分析结果较为准确,但缺点是计算量偏大,且鲁棒性较低,受干扰影响较大,这对实时性和稳定性要求都很高的网络通信而言无疑是一大障碍,因此其应用规模相对有限;NB算法也是早期在网络流量分类得到应用的机器学习方法,其缺点在于算法得出的分析结果的质量高低存在一定的不可知性,若样本选取的合理,则该算法相对可靠,若样本分布质量不高,则该算法得出的分类结果往往也偏离真实情况;SVM可取得较高的分类准确率,但必须事先标记流量的应用类型,因此不能适应完全意义上的实时分类。
基于流统计特征的机器学习分类方法收到的外界干扰较小,且不需要执行繁琐耗时的数据报首部解析工作,对于P2P网络中出现的大量端口号也可以不受其影响,平均准确率比以上其他算法都要好,能够准确的识别多个不同类型的数据流量,同时对于异常流量(如非法的数据流量)也可以实现一定程度的识别和判断。但其缺点是敏感度过高,对于网络的动态变化往往会出现过度响应,将原先正常的数据流量标注为异常点,从而导致系统的误判,另一方面,该算法实现起来也相对复杂,需要进一步改进。
3 混合模式的流量分类方案
3.1 方案流程分析
本设计将传统的分类方法和机器学习机制有机结合,对端口识别的流量分类模式进行改进,形成了一种新型的混合型流量分类方法,既保留了基于端口号识别模式的简单、低开销的优点,又有效地利用了机器学习机制的自适应性强、准确性高的优势,明显地改善了网络流量分类的效率和可靠性,算法流程如图2所示。
图2 改进后的流量分类算法流程
混合模式的流量分类方案具体实现过程如下。
1)对流量样本采用属性选择方法选出最优属性集,降低算法输入向量维数。
2)与常用协议的默认端口号匹配,实现粗分。若匹配成功则可不必启用机器学习机制进行后续的分类,节约了工作量。
3)进入细分环节,此环节是为了进一步提高对流量分类的精确性而设定,主要采用基于自组织映射网络的分类方法来完成。根据输出标签确定某一流量类别分布在port flow映射图或non-port flow映射图上。结合训练样本,确定输出映射图中相应区域的流量类型。
3.2 自组织映射
在本环节,采用深度学习算法中著名的神经网络算法来实现进一步的优化,该算法具有识别能力强、自适应度高等优点,非常适合用来对数据流量进行准确分类,可以很好地解决对非线性曲面的逼近,其收敛速度远高于传统分类方法。
自组织映射SOM网络是神经网络中的一种常用算法,属于无人监督的竞争型神经网络,该网络中的各个节点模拟为神经元节点,而在该网络中传输的各个信息状态则模拟为神经信号;该算法最大的特点就是将高维的输入流量样本以拓扑有序的方式变换到二维的离散空间上,其输出分类结果可以直观的以棋盘状的二维平面阵显示。根据此规律,可将SOM网络用于对输入的数据包特征信息的分类工作中,实现样本的自动聚类,同时可方便的识别新的数据类型和异常数据类型,其具体过程如下:
设输入样本[X=(x1,x2,…,xn)T],权向量为[Wj=(wj1,wj2,…,wjn)T(j=1,2,…m)],
其中n为输入样本的维数,m为映射图神经元数量。对样本和权向量进行归一化处理,得到[X]和[Wj],通过SOM神经网络执行以下两个步骤
1)选择竞争占优的神经元
[dj*=minj∈1,2,…,mX-Wj] (1)
2)计算该类神经元和与之相邻的其他节点的网络权值
[Wj*(t+1)=Wj*(t)+η(t)N(t)(X-Wj*(t))] (2)
式(2)中,t为学习次数,[η(t)]为学习成功率,[N(t)]为获胜的邻域。
做完了准备工作后,SOM网络就可将所有权值W转化为在[-1,1]区间的随机数,并根据此选择一个流量样本n,解析其特征属性并送至神经网络的输入接口,设置初始t=0,因此有N(0)和[η(0)]。输出层各神经元通过式(1)全局搜索最接近的优胜神经元j*。按式(2),对j*及其邻域内的所有神经元调整权值,然后缩小邻域[N(t)],减小学习率[η(t)],重新调整邻域内神经元的权值直到学习率衰减为0。当算法运行到这一步时,若流量样本集合不为空集,则可继续执行下去,在非空集合内随机选择一样本,重新执行本轮的学习过程,直至所有样本均完成训练,此时就可生成一张完整的流量类别映射图,最后根据样本激活神经元的位置可判断流量类别,实现数据流量的精确分类。
4 结束语
目前,在网络流量分类的研究工作中,更多地倾向于将优秀的智能算法同以往传统的分类方法相结合的研究路线,其中
很多优化算法仍旧处于起步阶段,从理论上看,基于流统计特征的机器学习的方法自适应性强,可扩展性好,可靠性也有足够的保障,应用在流量分类领域内是非常合适的,但其计算量较大仍旧是该算法推广过程中遇到的主要障碍,相信随着人工智能领域研究的不断突破,会出现更多的优秀方法应用在网络流量分类工作中,进一步增强流量分类的工作效率,为广大用户提供更高質量的数据通信服务。
参考文献:
[1] 徐鹏,刘琼,林森.基于支持向量机的Internet流量分类研究[J].计算机研究与发展,2009,46(3): 407-414.
[2] 王琳.面向高速网络的智能化应用分类的研究[D].济南:济南大学,2008.
[3] WITTEN I H,FRANKE.DATA MINING:practical machine learning tools and techniques[M].New York: SF Morgan Kaufman,2005:168-171.
[4] 韩家新,何华灿.SVMDT分类器及其在文本分类中的应用研究[J].计算机应用研究,2004(1): 23-24,43.
[5] ERMAN J,ARLITT M,MAHANTI A.Traffic classificationusing clustering algorithms[C].Proceedings of the2006 SIGCOMM Workshop on Mining Network Data,Pisa,Italy,2006:281-286.
