基于MapReduce的Canopy-Kmeans算法的并行化
2017-03-23张友海李锋刚
张友海,李锋刚
(1.安徽职业技术学院,安徽 合肥 230011;2.合肥工业大学,安徽 合肥 230009)
基于MapReduce的Canopy-Kmeans算法的并行化
张友海1,李锋刚2
(1.安徽职业技术学院,安徽 合肥 230011;2.合肥工业大学,安徽 合肥 230009)
数据挖掘的聚类算法Canopy-Kmeans是分析数据内在价值的常用工具之一,传统的基于集中控制的方式算法执行效率,在今天大数据环境下,有待改进。文章数据源为某省运营商在2014年7月经过脱敏后的话单信令数据,通过传统的集中控制方式和基于MapReduce的方式。通过实验,我们可以看出使用MapReduce方式具有良好的可行性,而且执行效率也得到明显改善〔1〕。
聚类算法;Canopy-kmeans ;MapReduce
Hadoop是一个开源的分布式大数据解决方案,它实现对海量数据高效,可伸缩的存储和分析功能。Hadoop架构的核心包含三个部分,分布式文件存储系统HDFS,DFS是一个设计用于在低成本硬件上运行的高度容错的分布式文件系统,适合存储大文件。YARN是有Hadoop提供的一个资源调度系统,用于为上层应用提供统一的资源调度和管理功能,提高资源利用率。MapReduce,一个并行计算编程框架,可以用于编写处理海量数据的应用。
1 Canopy-Kmeans算法
Kmeans算法简单且易于实现,是运用非常广泛的聚类算法。但存在很多缺点,如需事先确定初始聚类数目,另外聚类中心的选择具有较大差异,易受主观因素影响而使得结果陷入局部最优。而Canopy-Kmeans算法是一种Kmeans的优化算法,其思想是对特定数据集,设置一个Canopy初始中心点与范围半径,将数据集快速地划分成若干可重叠的Canopy,使得所有记录均分布在Canopy所覆盖范围内,并对发布同一范围内的记录,重新计算得出新中心点指标并根据记录坐标与新中心点之间的距离值重新划分记录所属区域。循环执行上述过程,直到k个中心点的不再发生变化为止。传统的Kmeans算法计算复杂性是O(dkt),其中d为记录数量,t为算法迭代次数,k为类的数量。在运用Canopy方法对Kmeans算法进行优化的条件下,由于在划分Canopies时是可重复划分的,在忽略某些记录属于多个Canopy情况,聚类需比较dkt/c次,其中c是Canopies的数量。可见Canopy方法可以显著提高算法效率。
2 Canopy-Kmeans的MapReduce并行化〔2〕实现
Canopy-Kmeans的MapReduce并行化实现〔3〕思路如下:首先将所有数据集合按特定特征划分为每类的成员的特征相同的K个类。初始数据会根据数据存储的节点位置及数据分块个数将其划分为划分成N个数据集,每个数据集可由一个Mapper独立处理完成,并且Mapper可以重复利用,多个数据集可以在同一个Mapper上进行处理。Canopy-Kmeans的聚类过程分两个阶段执行:第一步:近似和快速地将数据分成若干的Canopy,然后对每个Canopy内的记录再进行聚类。在这两个阶段过程中,使用不同的相似距离的度量方法,最终创建好可重叠的Canopy。第二步:对于Canopy 内的记录,这里使用Kmeans 算法进行聚类。由于这里只要对Canopy内的点完成精确地聚类,从而避免了像传统kmeans算法那样要对数据集合中所有的记录进行迭代精确计算,另外由于算法允许有重叠Canopy,这起到了消除孤立点作用,提高了算法的容错性。在MapReduce编程模型下,Canopy-Kmeans算法的并行化实现可分解为若干子Job,流程如图1所示,每个方框均表示一个完整的MapReduce任务。
其实现步骤说明如下:
1)Canopy中心点生成过程:针对于大数据量,生成Canopy中心点的过程会很耗时。这里同样利用MapRduce进行优化这个过程。首先由单节点程序对小量的记录生成Canopy中心点,再由分布式的Map程序过滤其他记录,去除掉落在已有Canopy范围内的记录。对于剩下的记录迭代执行这个过程,直到所有记录都被处理。该步骤将产生所有Canopy中心点的集合。
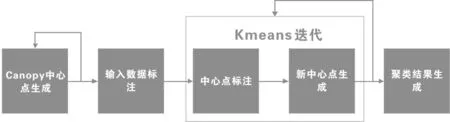
图1 Canopy-Kmeans 算法流程
2)输入向量标注:这个步骤的目的是标注Canopy的记录文本,这个步骤只需要Mapper过程,不需要reduce过程,Mapper的功能是将待聚类的记录与所有Canopy中心点比较,输出记录及其对应的Canopy中心点信息。
3)Kmeans算法MapReduce并行化思路如下:
(1)Map每读取一条数据就与中心做对比,求出该条记录对应的中心,然后以中心的id为Key,该条数据为value将数据输出。
(2)利用Reduce的归并功能将相同的Key归并到一起,集中与该Key对应的数据,再求出这些数据的平均值,输出平均值。
(3)对比Reduce求出的平均值与原来的中心,如果不相同,这将清空原中心的数据文件,将Reduce的结果写到中心文件中。(中心的值存在一个HDFS的文件中)删掉Reduce的输出目录以便下次输出。继续运行任务。
(4)对比Reduce求出的平均值与原来的中心,如果相同。则删掉Reduce的输出目录,运行一个没有Reduce的任务将中心ID与值对应输出。
3 实验分析与总结
本文采用的实验数据是某省运营商在2014年7月经过脱敏后的话单信令数据,数据包含内容有:源标识,源运营商标识,目的标识,目的运营标识,源区域标识,目的区域标识,时间戳,持续时间等34个字段,涉及用户量4215.9万。
接下来将对Canopy-Kmeans的MapReduce的聚类效果、并行化加速比,分别设计实验进行验证。
1)聚类效果分析
在这里我们引入最小误差平方即:
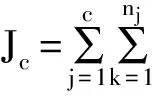
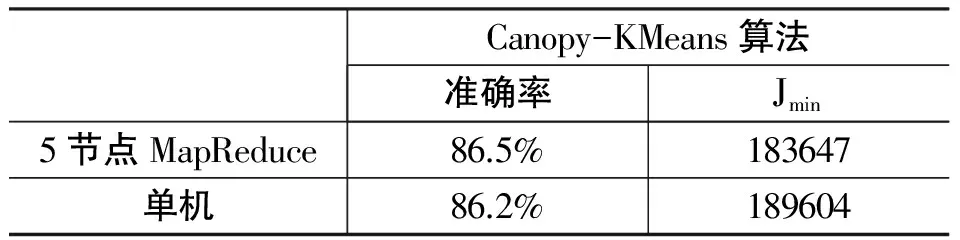
表1 聚类效果实验结果数据
由表1可知,并行化实现的聚类算法和单机实现的聚类算法在聚类效果方面差异不大。
2)实验二:并行加速比分析
加速比描述在集群中实现并行化通过减少运行时间而获得的性能提升,其定义为性能相同的节点并行运算所耗费的时间除以单节点进行运算所耗费的时间。本实验将从3个节点增加节点8个节点的分别计算加速比差异如图2所示。
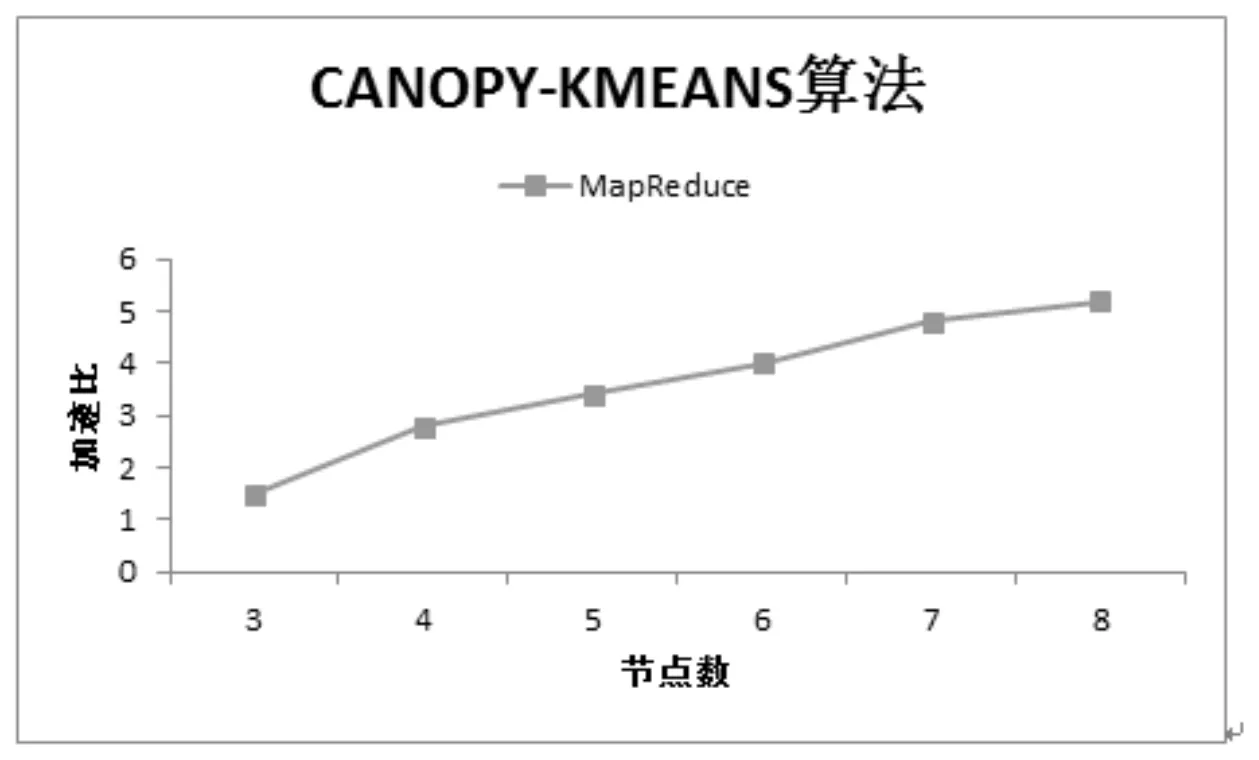
图 2 Canopy-KMeans算法加速比实验结果
从图2可以看出随着节点的增加性能均有所提升,证明基于MapReduce实现的算法具有提高执行效率的作用。
可以看出,利用MapReduce并行计算框架来实现聚类算法Canopy-Kmeans,具有良好的可行性,在集群环境下,随着业务节点的增加,执行性能将有较大提高〔4〕。
〔1〕赵庆.基于Hadoop 平台下的 Canopy-Kmeans 高效算法〔J〕.电子科技,2014.27(2):29-31.
〔2〕毛嘉莉.聚类K-means算法及并行化研究〔D〕.重庆:重庆大学,2003.
〔3〕霍可栋.基于Hadoop平台下的Canopy-Kmeans算法实现〔J〕.科技展望,2015, (33):12.
〔4〕张石磊,武装.一种基于Hadoop云计算平台的聚类算法优化的研究〔J〕.计算机科学2012.39.
Parallelized Canopy-kmeans algorithm based on MapReduce
ZHANG You-hai1, LI Feng-gang2
(1.AnhuiVocationalandtechnicalCollegeHefei23001; 2.HefeiUniversityoftechnology,Anhui,hefei230009,China)
The Canopy-kmeans clustering algorithm for data mining is one of the common tools which we usually used to analyze the intrinsic value of data. Under current big data environment, the traditional algorithm based on centralized control need to be improved. In this paper, the data source is gathered July 2014 from the desensitized signal data, and billed by traditional centralized control and the method based on MapReduce. Through the experiment we know it has good feasibility to use the MapReduce way, and the executive efficiency has been improved.
Clustering algorithm; Canopy-kmeans; MapReduce
10.3969/j.issn.1008-3723.2017.01.002
(j)cnki 1008-3723 2017.01.002
2016-11-26
张友海(1980-),男,皖寿县人,安徽职业技术学院讲师,合肥工业大学在职工程硕士.研究方向:计算机应用技术.
TP311.13
A
