基于三角聚集度的社区发现标准在汽车消费人群分析的适用性研究
2017-03-13中国汽车技术研究中心王文斌
中国汽车技术研究中心 王文斌 白 辰 田 源
基于三角聚集度的社区发现标准在汽车消费人群分析的适用性研究
中国汽车技术研究中心 王文斌 白 辰 田 源
为解决汽车企业对于不同类型汽车消费人群的分析调研需求,本文研究了关系网络中消费人群的社区发现问题,根据图数据挖掘中三角型的特性,提出基于三角聚集度的社区发现标准。研究发现该方法对于车企的消费人群划分判别具有很好的适用性。
汽车消费人群分析;社区发现;三角聚集度
1 引言
近年来,随着网络和各种电子设备的日益普及,越来越多人都参与到互联网的信息交流中去。在众多的网站中,Twitter、Facebook、微博、人人网、以及微信朋友圈等一系列社交网络作为近年来广泛使用的交流平台,如雨后春笋般纷纷涌现出来,面向各个领域拓展自己的用户。而那些现实生活中的人们因为各自的兴趣爱好、地理位置、工作性质等原因所组成不同的“真实”群体,如何在这一“虚拟”的社交网络中将其群体(或称其为“社区”)标注提取出来,并挖掘这些群体的共同特点,发现知识、创造价值,已经成为社交网络数据挖掘领域的一项研究热点,“社区发现”作为一个新兴的研究领域,也就因此成为研究者广泛关注的问题。
2 社区发现
社交网络反映了现实生活中的这样一个特点:人们都会因为各自的兴趣爱好,或所在地理位置、工作性质等原因而形成各种各样的群体。而在社交网络中,这些群体都会因为彼此的熟识或共同关注了某人或某物而有着较其他陌生人相比,更为频繁的交流。那么利用这种关系,是否可以在社交平台中复杂而庞大的用户群体中找出这些现实的群体呢?因为若找出这些群体,必能通过这些群体的特征,利用数据挖掘的思想,找出类似“啤酒—尿布”的规律或知识,从而产生价值。
面对这个问题,学者们纷纷展开研究,“社交网络挖掘”便成为数据挖掘领域一个新的重要分支,而社区发现是社交网络挖掘的重点研究问题。例如在著名社交网站Facebook中截取的斯坦福大学学生之间的部分好友关系图,就可以通过这种关系划分出他们之间的关系:或同毕业于一个高中,或一同参加了一个暑期夏令营,或属于不同的社团。
当然,社交网络这一概念不仅仅指互联网上的交友网站,它可以看作是由图表示的异构关系数据集。现实世界中,在科技、商业、经济和生物等方面,都有社交网络的存在,比如汽车企业与客户间的购买关系,汽车论坛中车友间信息的交流,以至万维网、电力网格、计算机病毒传播、电话交互图以及科学家的合著关系、论文的引用网络;生物学领域中的流行病学网络,细胞与新陈代谢网络和食物网络等,都是社区发现的研究对象[4]。
但在这一社区发现这一新兴领域进行算法的提出、对比和研究前,首先要确定一种合适的判别标准来确定这种划分方法的好坏。现在使用最多的方法是2004年由M. Newman[1]提出的计算划分社区的modularity (模块性),但这一划分标准的缺点也很明显,它对于小型的社区并不适用。其他标准比如R. Kannan[2]提出的连通度(conductance),也存在对于一些聚集度极佳的特殊图形,不能准确体现其聚集性质的缺点。
3 三角聚集度
3.1 图数据中的三角形
图中三角形的查找和统计在图数据领域有着广泛的研究意义和价值。因为三角形存在两个重要特性——同质和传递,这两个性质在社交网络的图数据挖掘中就起到了跟重要的作用:社交网络的用户倾向于与有用相似爱好和兴趣的人建立朋友关系(在数据的角度,用户之间拥有相似的三角形模式),这种倾向性在社交网络中,主要表现在用户更愿意与拥有相同朋友圈子的人成为朋友。同时,统计三角形也被应用于挖掘隐藏的网页主题、彭谷聚类参数,以及检测垃圾邮件。
3.2 聚集系数
其实最早在1949年R. D. Luce和A. D. Perry的一篇论文[3]中,图中三角形的聚集度已经在图论中被提出并定义这一系数为图的聚集系数,描述的是图中的若干点倾向于集聚在一起的程度的一种度量。
而图中的某一个节点,聚集系数表示了它相连的点抱成团(完全子图)的程度。为方便说明,这里定义在G = (V, E)中包含一系列节点V和连接它们的边E。表示的第i个相邻节点。表示的相邻节点的数量。一个顶点的聚集系数等于所有与它相连的顶点之间所连的边的数量,除以这些顶点之间可以连出的最大边数。在无向图中的最大边数为,所以某一点的聚集系数公式表示为:

那么整个网络的所有点聚集系数就可以定义为所有节点n的局部聚集系数的均值:

那么若一个图的平均聚集系数比相同节点集生成的随机图有显著提高,但平均最短距离却与相应随机生成的随机图十分相近,那么这个图被认为是小世界的社交网络图。有着更高平均聚集系数的社交网络被发现有着模块结构,同时在不同节点中还有更小的平均距离。
3.3 三角聚集度
根据三角形在图数据中的性质以及聚集系数这一指标,提出一种新的社区发现的度量标准——三角聚集度(Triangular-Clustering Coeffcient)
其公式定义如下:
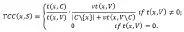
在定义了节点对于社区的归属度的计算方法后,根据式(3.1)的思路,将这个社区内所有点的归属度取其平均值,得到计算这个社区C的整体的凝聚程度的表达式:
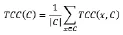
而后便可通过式(3.2)的思路确定该划分对于整张图来说划分优劣的的一个指标即将各个社区根据其大小加权后平均即可:
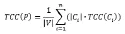
3.4 度量标准分析
一个好的社区发现度量标准需要能很好的反映出根据此标准评判出的优秀社区的一些特点和属性,这些属性可以保证所划分出的社区内节点的稠密性和结构特点。下面简单对一个优秀社区的四个属性进行简单说明及分析:
属性1:有良好的内部结构
在M. Newman等人之前的研究中已经表明,一个优秀社区的一个最主要的特征就是有一个数值非常大的聚集系数。社交网络构成的图数据与普通的随机生成的图的一个最大的不同也就是拥有非常多的三角形结构。因此,三角聚集度将计算三角形的个数作为计算一个社区聚集程度的一个最重要的评判标准。
属性2:社区的凝聚力应随节点增多而增长
在一个优秀的度量标准中,当一个新的节点被计算应当加入这个社区时,这个社区整体的凝聚程度应该是能够得到增强的。放到实际情景中,若想加入一个社区,这个节点需要与这个社区内部很多的节点有联系,这个社区越大,需要联系的节点也就越多,它与这个社区的联系才能体现出越强,越应该属于这个社区,否则,这个社区整体的凝聚力将会因为它而降低。用函数形式表示,若节点x应属于社区C,则。
属性3:社区中不存在桥结构
在一个社区中若存在桥结构,则该社区的凝聚程度将会非常弱,因为除了这条边之外,两个节点集之间没有任何的联系。因此,一个优秀的社区中不应存在桥结构。
属性4:社区中不存在割点
与桥结构类似,当在一个社区中存在若干个割点的话,若将此割点以及与之相连的边删除,则该社区立刻回分解成两个互不关联的子图。所以割点也是一个社区中弱连接的体现,一个优秀的社区中,是不应该存在割点这一结构的。
可见,三角聚集度满足以上的四种性质,同时用虚拟的小型社区数据计算其三角聚集度。如图2所示,构建了从简单稀疏的社区到复杂稠密的不同8个社区(从a到h),其三角聚集度的值由低至高,体现了这一度量标准能很好的体现社区的稠密程度。

4 总结
通过建立汽车消费人群的图数据关系模型,研究了关系网络中消费人群的社区发现问题以及图数据挖掘中三角型的特性,并通过三角形的聚集系数的定义,提出基于三角聚集度的社区发现标准,并验证了该标准对于车企的消费人群划分判别的适用性。
本文中提出的标准对于大数据下的汽车社区网络还没有针对性其的成型算法实现,设计构思一种高效的使用三角聚集度计算的算法是今后的研究方向。
[1]M.Newman and M.Girvan.Finding and evaluating community structure in networks. Phy. Rev. E, 69(2):026113, 2004.
[2]R.Kannan et al.On clusterings:Good,bad and spectral.JACM, 51(3):497{515,2004.
[3]李晓佳,张鹏,狄增如等.复杂网络中的社团结构[J].复杂系统与复杂性科学,2008,5(3):19-42
[4]谷峪,于戈,鲍玉斌.大规模图数据的分布式处理2015,ISBN-9787302420729.
