基于极限学习机的仿真机器鱼动作策略
2017-03-13广东工业大学自动化学院彭泽荣张学习王建桦
广东工业大学自动化学院 彭泽荣 张学习 王建桦
基于极限学习机的仿真机器鱼动作策略
广东工业大学自动化学院 彭泽荣 张学习 王建桦
针对URWPGSim2D仿真平台,为实现机器鱼快速、准确的调整,本文将机器鱼的状态定义为“调整”和“推球”,并提出基于极限学习机的动作决策模型,利用此模型自主选择相应的动作策略。动作决策模型根据当前时刻周围的环境信息,利用极限学习机确定机器鱼的状态,自主选择当前时刻的最优击球点,并确定机器鱼速度和角速度档位的最优组合。经URWPGSim2D仿真平台验证结果表明:机器鱼可根据策略调整路径,选择合适的动作策略,以更少的时间代价完成比赛。这说明基于极限学习机的动作决策策略能充分考虑机器鱼和水球的实时信息,在不同情况下选择不同的策略,具有很强的适应能力,满足仿真机器鱼对于动作决策的要求。
URWPGSim2D仿真;机器鱼;极限学习机;动作决策
1 引言
随着海洋科技的长足发展,水中机器人的应用变得越来越广泛,关于仿真水中机器人的研究也成为该领域的研究热点之一[1]。近年来,国内外争相举办各类机器人大赛,以期在比赛中交流机器人研究领域的新思想和新进展,其中,北京大学联合多所高校和科研所建立的URWPGSim2D仿真平台就是一个很好的水中机器人研究平台。该平台以鱼作为仿真对象,以充满扰动的仿生水作为仿真环境,提供了一种仿真水中机器人水球比赛实时仿真系统,旨在通过各种比赛项目[2],研究多仿真体的协作性和智能性[3]。
为了使机器鱼在动态变化环境中完成指定的任务,必须让机器鱼精确地运动到指定位置,换句话说,点对点控制效果决定了机器鱼的控制效果。机器鱼点对点(PTP)控制算法是喻俊志、陈尔奎等人提出来的,该算法的目的是消除机器鱼在初始方向、位置与目标点之间的方向误差和距离误差[4]。由于机器鱼所处环境因素的不确定性,以及机器鱼在游动的过程中水对机器鱼的干扰,导致机器鱼点对点控制效果不理想。
针对上述不足,本文提出了基于极限学习机的动作控制算法,根据实验数据设计控制模型。实验结果表明,基于极限学习机的动作控制算法能优化机器鱼的游动路径,提高机器鱼的控制效果。
本文将基于该平台,针对“水中搬运”项目,对其比赛策略进行研究。
2 极限学习机
在2006年,黄广斌教授提出了前馈神经网络的极限学习概念,并详细介绍了基本原理[5]。极限学习机(Extreme Learning Machine,ELM)是一种特殊类型的单隐藏层前馈神经网络,它仅有一个隐藏节点层。后来将它扩展到通用的单隐藏层前馈神经网络,它的隐结点类似神经元[6]。极限学习机的基本组成如下:

图1 极限学习机网络结构图
通常,描述标准的SLFNs模型能够零误差地逼近上述N个样本,表示的是:

即存在w、β和b,使得:

利用矩阵表示时,(2)可以紧凑地写成:

当w和b固定时,等价于求线性系统(3)的最小二乘解,即:

得到:

其中H†是H的Moore-Penrose广义逆[8]。而最小范数的最小平方解具有唯一性,使其训练误差达到最小。也就是说,对于随机赋值的输入权值和偏置向量,只要设置合适的隐含层神经元个数,可以通过求取线性方程的最小二乘解来得到隐含层的权值。
3 极限学习机(ELM)与机器鱼动作决策
3.1 击球点的确定
本文根据机器鱼当前时刻周围的环境信息来选择击球点,并采取相应的动作策略。如图2所示,连接地标中心点与水球球心,连线交水球远端处为P点,过水球球心作此连线的垂线,此时将场地划分为I、II、III、IV四个区域;然后以P点为圆心,水球直径为半径作圆,此圆与垂线相交于A、B两点。则:若机器鱼处于I区域,以A点为击球点;若机器鱼处于II区域,以B点为击球点;若机器鱼处于III、IV区域,以P点为击球点。这样做的好处是,当机器鱼处于“调整”状态时,通过A点(或者B点)不仅可以达到调整的目的,而且能够保证机器鱼在整个调整过程中尽量靠近水球,从而缩短进入“推球”状态时机器鱼与水球的距离。
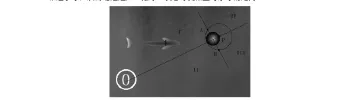
图2 击球点确定示意图
3.2 机器鱼位置的确定


图3 机器鱼位置确定示意图
利用θ和D确定机器鱼位置的过程如下:
通过抽象出θ和D,不仅能更精确的描述机器鱼的位置,而且只有两个特征参数,降低了计算复杂度,减少了运算时间。
4 仿真结果及其分析
本文基于URWPGSim2D平台,针对“水中搬运”项目,分别建立了基于BP神经网络和基于极限学习机的仿真机器鱼动作决策模型,并讨论这两个模型的优劣。
本文通过MATLAB仿真实验来获取机器鱼动作控制模型中极限学习机和单隐含层BP神经网络的最优隐含层神经元个数。实验中使用500个训练样本数据,100个测试数据,测试的隐结点个数分别为100、150、200、250、300、350、400,测试结果如图4所示。最终得到:当极限学习机的隐含层神经元个数为250,单隐含层BP神经网络的隐含层神经元个数为160时,两种模型的学习精度比较高,能够准确定位机器鱼,为机器鱼的动作决策提供良好的基础。

图4 隐结点个数测试结果
综合上述分析,分别对BP神经网络、极限学习机进行建模。两个模型均采用三层拓扑结构,输入层的神经元个数为2,隐藏层的神经元个数分别为160、250,输出层神经元个数为1。所得结果见表1:

表1 两种算法的性能比较
从表1可以看出,BP算法搜索最优解的偏差过大,而极限学习机能以更短的时间,以及更高的精确度对全局最优解进行搜索,换言之,极限学习机在时间和精度方面都要优于BP算法。实验结果表明,极限学习机具有更好的性能。
5 结束语
基于极限学习机的仿真机器鱼策略综合考虑了水下环境的复杂性及机器鱼自身结构和运动的特点,首次提出以地标为坐标原心,通过水球、机器鱼的斜率θ与距离D来判断三者的相对位置,从而正确的确定机器鱼的状态。并根据机器鱼在顶球过程中的连贯性,利用极限学习机让机器鱼自主选择击球点,使得顶球更加平稳快速。经过在URWPGSim2D平台上运行该算法编写的程序,效果明显。由实验结果可知:该优化策略能够很好地完成比赛,不但提高了策略的稳定性,而且具有很强的适应能力,满足仿真机器鱼对于动作决策的要求,说明这种方法是可靠、可行的。
[1]谢广明.机器人水球比赛项目推介书[M].北京:北京大学工学院,2009:1-5.
[2]黄永安,马路,刘惠敏.Matlab7.0/simulink 6.0建模仿真开发与高级工程应用[M].北京:清华大学出版社,2007:1-75.
[3]喻俊志,陈尔奎,王硕,等.仿生机器鱼研究的进展与分析[J].控制理论与应用,2003,4(4):485-491.
[4]J.Liu,I.Dukes,and H.Hu.Novel mechatronics design for a robotic fish.In Proc.IEEE/RSJ International Conference on Intelligent Robots and Systems,pages 2077-2082,2005
[5]G.B.Huang,Q.Y.Zhu,C.K.Siew.Extreme learning machine:theory and applications[J].Neurocom-puting,2006,70:489-501.
[6]G.B.Huang,L.Chen.Convex incremental extreme learning niachine[J].Neurocomputing,2007,70:3056-3062.
[7]P.L.Bartlett.The sample complexity of patteni classification with neural networks;the size of the weights is more important than the size of the network[J].IEEE Transactions on Information Theory,1998,44:525-536.
[8]K.S.Baneijee.Generalized inverse of matrices and its applications[J].Technometrics,1973,15:197-202.
The Simulation Robotic Fish Action Strategy Based on Extreme Learning Machine
Peng Zerong Zhang Xuexi Wang Jianhua
Aiming at URWPGSim2D simulation platform,in order to realize rapid and accurate adjustment of simulation robotic fsh,this paper defned the state of robotic fsh for"adjustment"and"push ball",and action decision model based on extreme learning machine is put forward.By using this model,the corresponding action strategies are selected.In the action decision model,according to the current environment information around the robotic fsh,the state of the robotic fsh is determined by the extreme learning machine.Then the fsh can independently choose the optimal hitting point of the current time,and determine the optimal combination of velocity and angular velocity.Verifed by URWPGSim2D simulation platform show that:the robotic fsh can choose the appropriate action strategy to adjust its path by using the action decision model,and complete the competition with less time.This shows that action decision-making strategy based on extreme learning machine can fully consider the real-time information of robotic fsh and water polo,choose a different strategy in different cases,have a strong ability to adapt,meet the requirements of simulation robotic fsh for the action decisions.
URWPGSim2D;robotic fsh;extreme learning machine;action decision-making
国家自然科学基金(61573108)。
彭泽荣,男,广东汕头人,研究生,主要研究方向:智能控制与信息处理技术。
张学习,男,江苏徐州人,博士,副教授,主要研究方向:智能控制与信息处理技术。
