基于Scrapy的工业漏洞爬虫设计
2017-03-10孙歆戴桦孔晓昀赵明明
孙歆++戴桦++孔晓昀++赵明明
【 摘 要 】 工业控制系统的漏洞是工业安全中极其重要的资源信息,也是对工控系统进行威胁分析和安全等级鉴定的重要依据。论文设计实现了一个基于Scrapy的工业漏洞网络爬虫,能对工控系统安全漏洞网站上的漏洞信息进行抓取和分析,并进行结构化处理,为实际项目开发提供重要的漏洞数据信息。
【 关键词 】 工业控制系统;工控漏洞;爬虫;Scrapy
Design of Industrial Vulnerabilities Web Crawler Based on Scrapy
Sun Xin 1 Dai Hua 1 Kong Xiao-yun 2 Zhao Ming-ming 3
(1.Electric Power Research Institute of State Grid Zhejiang Electric Power Company ZhejiangHangzhou 310014;
2.State Grid Zhejiang Electric Power Company ZhejiangHangzhou 310008;
3. Beijing China-power Information Technology Co., Ltd. Beijing 100192)
【 Abstract 】 Industrial control system vulnerabilities are extremely resource information of industrial activities on industrial safety, and they are also an important basis for the threat analysis and safety identification of industrial control system. This paper designed and implemented a web crawler for industrial vulnerabilities that based scrapy framework. The crawler can crawl and analyze vulnerability information on web sites, and provide structured vulnerability imformation for actual projects.
【 Keywords 】 industrial control system;industrial vulnerabilities;web crawler;scrapy
1 引言
互联网信息资源的极速增长使得基于传统搜索引擎获取信息的方式越来越难以满足人们对有效信息的获取要求。而当所需的信息体量大时,采用纯人工采集数据信息更是无法满足生产需求。针对这样的情况,使用某种自动化技术实现从互联网上自动采集符合需求的结构化信息是非常有必要的。
网络爬虫是一种能够实现对互联网信息资源进行自动采集整理的程序,它弥补了人工采集的缺陷。通过网络爬虫不仅能够为搜索引擎采集网络信息,而且可以作为定向信息采集器,采集定制网站下的特定信息,如商品信息,漏洞信息等。
2 网络爬虫
2.1 爬虫概述
网络爬虫[1] (Web Crawler)通常又被称为网络蜘蛛(Web Spider),是一个能够自动在互联网上漫游并可以自动下载网页进行信息结构化提取的程序或者脚本。网络爬虫的特征鲜明[2],主要体现在三个方面。
(1)强壮性好,网络爬虫的程序具备超强的执行力。
(2)智能性好,主要体现在获取和分析Web页面以及利用URL链接进行爬行等方面。
(3)能够将Web信息进行过滤存储等。
网络爬虫按照系统结构及其实现技术,大致可分成四种[3]类型:通用网络爬蟲[4](General Purpose Web Crawler)、聚焦网络爬虫[5](Focused Web Crawler)、增量式网络爬虫[6](Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用过程中爬虫系统通常是由几种爬虫技术相结合实现的。
2.2 Python与爬虫
当前主流的编程语言都有自己的爬虫框架,如Java有Nutch、C++有Larbin,Python有Scrapy等。由于本文设计的爬虫是基于Python语言的,所以在这里主要讨论运用Python语言来设计实现爬虫系统。
2.2.1 Urllib与爬虫
Urllib是python语言的一个模块,在编写爬虫程序时主要功能是利用该模块提供的方法(Urlopen、Urlretrieve)进行网页下载,再结合正则表达式re模块以及Beautifulsoup模块对网页上的信息进行结构化提取。
2.3.2 Scrapy与爬虫
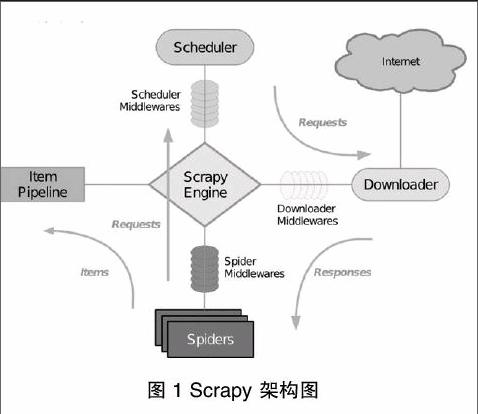
Scrapy[7]是一个基于Twisted[8],可以爬取并结构性提取网站数据的异步爬虫应用框架。它用途广泛,常被应用于数据挖掘、信息处理等场景。Scrapy 设计理念先进而简单,效率高、可扩展性好,可移植性佳(在主流的操作系统平台上都具备良好的性能)Scrapy由引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、蜘蛛(Spiders)和数据管道(Item Pipeline)五大部分组成,其中还包括各种辅助中间件(Middlewares)协同实现爬虫的精细功能。
(1)引擎:Scrapy Engine 是用来控制整个爬虫系统的数据处理流程,并进行事务处理的触发,负责接收和转发其他各个模块间的请求和相应。
(2)调度器:Scheduler维护着爬虫的爬取优先级队列,决定着下一个要爬取的URL,从Scrapy引擎接收请求并排序加入队列,并在引擎发出请求之后返回响应。爬虫的爬取优先级队列是一个简单的内存队列,爬虫之间不能共享队列,也无法固化到磁盘,如果发生错误或者程序崩溃,队列中的所有信息都将丢失,因此每一个爬虫都维护着一个属于自己的内存队列。
(3)下载器:Downloader 主要功能是从引擎处获取要下载的URL ,然后向服务器发送下载请求下载页面,通过下载器中间件(Downloader Middlewares)实现各种网络协议(如HTTP、FTP等)数据的下载,然后将所下载的网页内容传递给蜘蛛(Spiders)进行下一步的处理。
(4)蜘蛛:蜘蛛模块负责解析下载的网页,并抽取需要进一步爬取的超链接,它是由用户自己定义的,用户白定义的每个蜘蛛都能处理用户指定的一个或一组域名,也是说用户通过蜘蛛来定义特定网站的抓取和解析规则。蜘蛛在整个抓取过程中的处理流程如下:
首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法。该方法默认从start_urls中的Url中生成请求,并执行解析来调用回调函数。
在回调函数中,你可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也将包含一个回调,然后被Scrapy下载,然后有指定的回调处理。
在回调函数中,你解析网站的内容,同程使用的是Xpath选择器,并生成解析的数据项。
最后,从蜘蛛返回的项目通常会进驻到项目管道。
蜘蛛分析出来的结果有两种:一种是需要继续抓取的链接;另一种是需要保存的数据。两种结果是可以混杂在同一个结果列表里返回的,引擎会通过列表元素的数据类型进行区分,数据被封装成Item类型,请求则被封装成Request类型,Request类型的数据会转发给调度器进行调度,下载后通过指定的回调函数处理。
(1)项目管道:Item Pipeline的主要责任是负责处理有蜘蛛从网页中抽取的项目,其主要任务是分析、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据操作。数据管道中对数据的操作都是由开发人员自定义的函数方法,并可以在配置文件中指定其操作顺序。对数据信息的处理还包括判定是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有清洗HTML数据、验证解析到的数据(检查项目是否包含必要的字段)、检查是否是重复数据(如果重复就删除)、将解析到的数据存储到数据库等。
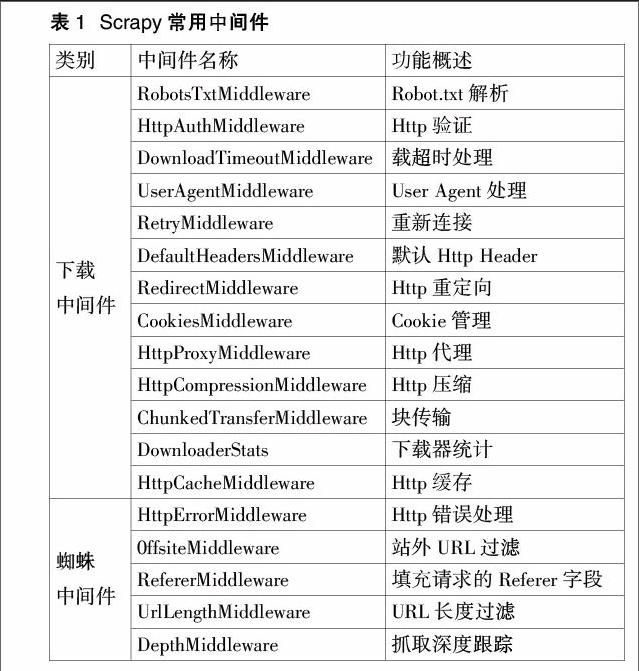
(2)中间件:Middlewares是位于Scrapy引擎和各个模块之间的钩子框架,主要是用来处理Scrapy引擎和各模块之间的请求及响应。它提供了一个自定义代码的方式来扩展Scrapy的功能。Scrapy的中间件有下载器中问件、蜘蛛中间件以及调度器中间件。其中,常用的下载器中间件和蜘蛛中间件如表1所示。
Scrapy处理数据的流程步骤。
(1)Scrapy引擎打开一个初始的域名,并定位到相应的蜘蛛处理属于这个域名的URL,然后让蜘蛛获取第一个要爬取的URL。
(2)Scrapy引擎从蜘蛛那里获得第一个需要爬取的URL,并将该URL包装成请求并指定响应该请求的回调函数,然后将其发送给调度器。
(3)Scrapy引擎向调度器请求下一步要进行爬取的页面。
(4)调度器将下一个要爬取的URL以请求的方式返回给Scrapy引擎,Scrapy引擎通过下载器中间件将请求发送给下载器。
(5)当下载器执行请求、下载完网页以后,下载的页面内容通过下载器中间件发送给Scrapy引擎。
(6)Scrapy引擎在收到下载器的返回的下载数据后,通过蜘蛛中问件将响应数据发送到蜘蛛进行数据处理。
(7)蜘蛛解析下载的页面并返回网页解析后的数据,然后将抽取出的要继续爬取的URL再次封装成请求发送给Scrapy引擎。
(8)Scrapy引擎将解析完成的数据发送至数据处理流水线,并将新的URL爬取請求继续转发给调度器。
(9)系统重复步骤2-8,直到调度器中没有新的请求时,关闭爬虫。
3 定制工业漏洞爬虫系统
在前面已经了解Scrapy原理的基础上,本节将要设计一个爬虫系统用于结构化提取工业控制系统漏洞信息。
3.1 工业漏洞爬虫的特点
与传统的网络爬虫不同,工业漏洞爬虫有着特定的爬取需求,其目标站点是明确已知的,而且在目标站点网页上需要提取的结构化信息也是明确的。因此,一般的爬虫相比,其具有三个特点。
(1)特定的需求:工业控制系统相关的漏洞(简称工控漏洞)主要包括工业控制系统中PLC、DCS、上位机软件等相关的漏洞信息。因此爬虫系统的需求定位非常明确,只关注工控方面的信息即可。
(2)明确的目标:工业漏洞爬虫的的目标站点是非常明确的。通过前期的调研工作,我们选择国家信息安全漏洞共享平台中工控系统专题(http://ics.cnvd.org.cn/)和美国国家漏洞库(https://web.nvd.nist.gov/)两个站点作为目标站点。
(4)明确的字段:在国家信息安全漏洞共享平台的工控专题站点的页面上,对于一个具体的漏洞新以表格的形式列出了和漏洞相关的基本信息。那么,对于此次的爬虫系统而言,只需要抓取网页上所列出的漏洞属性信息,比如漏洞名称、发布时间、漏洞描述等。
3.2 爬虫系统的架构流程
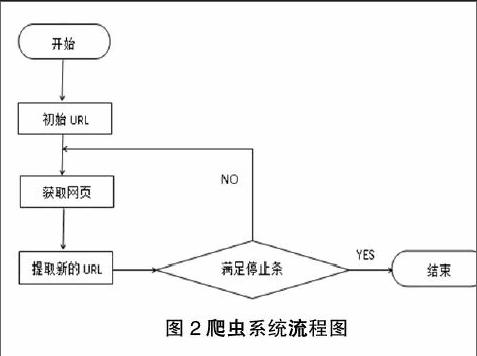
网络爬虫根据预先设定的一个或若干初始种子 URL开始,以此获得初始网页上的URL列表 ,在爬行过程中不断从 URL 队列中获一个的 URL,进而访问并下载该页面。页面下载后页面解析器去掉页面上的 HTML 标记后得到页面内容 , 将摘要、 URL 等信息保存到 Web数据库中, 同时抽取当前页面上新的 URL,保存到 URL队列, 直到满足系统停止条件 。其工作流程如图2所示。
3.3 爬虫系统详细设计
3.3.1 网页结构与数据分析
目标站点目标页面上的信息基本是以表格形式呈现,其中属性信息包括漏洞名称、CNVD编号、CVE编号、发布时间,危害级别、影响产品、漏洞描述、参考链接、解决方案、漏洞发现者等。根据实际项目需求,爬虫抓取信息时不会全部保存列表上的属性信息,只会保存项目所需数据信息。因此,将结构化的数据信息定义成如下格式:
{
“_id”:
“vulName”:
“vulDescription”:
“vulAdvisory”:
“refWebsite”:
“deviceName”:
“firmwareVersion”:
“integImpact”:
…
}。
3.3.2 数据定义
通过对Scrapy框架的学习研究以及前面对结构化数据的分析,利用Scrapy提供的Item类进行数据字段定义。对应item.py中主要的代码如下:
import scrapy
class VulItem(scrapy.Item):
vulName = scrapy.Field()
vulDescription= scrapy.Filed()
…
3.3.3 编写Spider
VulSpider是自定义编写的用于爬取漏洞信息的爬虫类,继承自scrapy.CrawlSpider类。类主体中定义了几种属性和方法。
(1)Name屬性,定义的是蜘蛛名字的字符串,具有唯一性,在Scrapy启动爬虫是使用。
(2)allowed_domains属性,包含了Spider允许爬取的域名(Domain)列表(List)。
(3)Start_urls属性,URL列表。当没有制定特定的URL时,Spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
(4)Rules属性,一个包含一个(或多个)Rule对象的集合(List)。每个Rule对爬取网站的动作定义了特定表现。Rule对象在下边会介绍。如果多Rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
(5)Parse_item方法,当Response指定的回调函数。
VulSpider主要的代码如下:
class VulSpider(CrawlSpider):
name = 'vul'
allowed_domains = ['cnvd.org.cn']
start_urls = ['http://ics.cnvd.org.cn/?max=20&offset=0']
rules = [Rule(SgmlLinkExtractor(allow=r'\?max=20&offset=\d+?'), callback='parse_url', follow=True)]
def parse_url(self, response):
sel = Selector(text=response.body)
for i in range(1, 21):
url = sel.xpath('//div[@class="list"]/table/tbody[@id="tr"]/tr[i]/td[i]/a/@href').extract()
Yield Request(url, callback=parse_item)
def parse_item(self, response):
……
3.3.4 数据存储
网络爬虫爬取的数据信息不仅量大,而且往往是结构化或者非结构化的数据。传统关系型数据库并不是很适合存储和处理这种数据信息,而NoSQL在处理文档类数据是有着非常良好的性能的。因而,爬虫系统选择分布式的非关系型数据库MongoDB对爬取的数据进行存储。
首先,在爬虫系统的setting.py文件中配置连接参数,其中包括数据处理的项目管道、连接的服务器、端口、数据库名、表名。然后,在 项目管道文件pipelines.py中定义数据库连接函数。定义的主要代码如下:
class VulPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(settings['MONGO_SERVER'],settings['MONGO_PORT'])
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
def process_item(self, item, spider):
……
return item
以上代码首先创建了一个VulPipeline类,其构造函数初始化该类并建立一个与数据库服务器的连接。process_item()函数解析后的数据项。
3.3.5 反爬措施
为了防止被网络爬虫爬取网页上的数据,很多网站都对网络爬虫进行了限制。工业漏洞爬虫利用Scrapy框架本身的优势并采取一定措施来避免被网站限制。采取的措施主要包括三种。
(1)设置延时:download_delay表示下载器在下载同一个站点下一个网页前需要等待的时间,这个时间如果太短,网络爬虫被Ban的概率则会大大增加。在settings.py中配置DOWNLOAD_DELAY = 3,3表示等待的秒数。
(2)禁止Cookies:可 以 防 止 使 用Cookies 识别爬虫轨迹的网站察觉,在settings.py 设置:COOKIES_ENABLES=False 。
(3)使用User Agent池:为了防止被服务器识别,可将 User Agent 池定义在 rotate_useragent.py文件中,每次访问服务器时,从User Agent列表中随机选择一个作为Request中头部信息的User Agent。
4 结束语
随着互联网信息的爆炸式增长,网络爬虫技术日渐成熟,通过网络爬虫来获取特定需求的信息数据必然会是信息需求的趋势。本文在各种成熟的爬虫框架中选擇Scrapy定制实现了一个工业漏洞网络爬虫,该爬虫能高效的抓取所需的漏洞信息,实现了自动化提取结构化的网络资源信息。
总之,利用网络爬虫来高效获取信息已经成为一个越来越受欢迎的手段。网络爬虫框架越来越多,便利越来越大,但是如何去提升爬虫的效率仍将是爬虫技术研究方向。
参考文献
[1] 董日壮, 郭曙超.网络爬虫的设计与实现[J].电脑知识与技术, 2014(6X): 3986-3988.
[2] 周德懋,李舟军.高性能网络爬虫: 研究综述[J].计算机科学, 2009,36(8): 26-29.
[3] 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术,2010(15): 4112-4115.
[4] 李盛韬,余智华,程学旗,等.Web 信息采集研究进展[J]. 计算机科学,2003,30(2): 151-157.
[5] Chakrabarti S,Van den Berg M,Dom B. Focused crawling: a new approach to topic-specific Web resource discovery[J]. Computer Networks,1999,31(11): 1623-1640.
[6] Cho J, Garcia-Molina H. The evolution of the web and implications for an incremental crawler[J]. 1999.
[7] Scrapy Document.Available at http://www.scrapy.org/.
[8] Twisted Document.Available at http://twistedmatrix.com/trac/.
作者简介:
孙歆(1981-),男,汉族,浙江杭州人,毕业于浙江大学,硕士研究生,高级工程师;主要研究方向和关注领域:信息安全、工控安全。
戴桦(1985-),男,汉族,浙江杭州人,毕业于南京邮电大学,硕士研究生,工程师;主要研究方向和关注领域:工控安全、渗透测试。
孔晓昀(1969-),女,汉族,浙江杭州人,硕士研究生,高级工程师;主要研究方向和关注领域:信息技术、信息化建设。
赵明明(1984-),男,汉族,内蒙古赤峰人,毕业于北京科技学院,本科,工程师;主要研究方向和关注领域:信息安全攻防。
