融合WK和CSK Co-word Model的共词分析法
2017-03-07王芙艳
王芙艳,邵 清
(上海理工大学 光电信息与计算机工程学院,上海 200093)
融合WK和CSK Co-word Model的共词分析法
王芙艳,邵 清
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于关键词的共词分析方法是利用关键词在文献中出现的频次高低来确定该领域研究热点的方法。传统的基于关键词的共词分析方法只是简单的统计关键词出现的绝对次数,忽略了关键词以及文献的内在特性以及关键词在概念上的重复性,造成结果的不准确性。文中提出了一种融合关键词加权模型(WK Co-word Model)和同义关键词合并模型(CSK Co-word Model)的共词分析法,该方法根据关键词自身的特征以及关键词所在载体文献的特征对关键词进行加权处理,同时以同义词词林为基础,计算关键词之间的词语相似度,合并同义关键词。该方法既强调了关键词之间权重的不同,又消除了同义词对结果准确性造成的影响。仿真实验表明,该方法提高了共词分析的准确性。
关键词;加权;共词分析;同义词;相似度
进入信息时代以来,各个学科领域的研究成果不断增加,文献的发表数量也呈指数级增长依靠各个领域专家对现有研究热点进行品评是不够全面和精准的[1]。但是与此同时,各个领域的科研人员又希望能够运用简单可靠的方法全面、直观地了解该学科的研究现状和研究热点,系统地掌握学科的发展状况,以及未来的发展趋势。
基于上述原因,许多国内外学者使用基于关键词的共词分析方法,对各个领域的热点和未来的发展趋势进行挖掘,加拿大蒙特利尔大学的Robert Dalpé教授,1997年完成了一份关于世界纳米科技研究状况的计量分析报告[2],该报告采用共词分析的方法,分析了世界各国纳米技术专利的分布。赵丽红以MEDLINE光盘数据库作为数据来源,对2001~2006年7月的与老年病学相关的1 261篇文献进行了共词分析,从而获得了老年病学研究活动的热点[3]。
传统的共词分析法(UWKWA )是直接统计文献中自引用关键词出现的绝对频率,即当文献中某一关键词出现一次,该关键的频次就增加1,以此累加,用此方法统计该关键字在所有文献中出现的总的次数。这种统计关键词的方法会影响之后的共词矩阵和聚类分析,造成结果失真[4]。原因如下:(1)关键词“同量不同权重[5]”,是指关键词在文中出现的位置,词性等不同,关键词的重要性就不同;(2)文献“同量不同权重[6]”,是指关键词所在的文献不同,关键词的重要性就不同;(3)关键词“同义不同词”,是指由于每篇文献的作者不同,每个作者有不同的描述习惯而造成的同一个关键词有不同表示。
目前,许多学者对基于关键词的共词分析提出了很多改进的方法,并取得了一些研究成果。比如钟伟金[7]提出在文献的自标引关键词中存在主要主题词和次要主题词的差别,提出共现频率计算时应对主要主题词进行加权计算(WKWA)。唐晓波和肖璐[8]指出自标引的关键词不能全面描述论文的主题内容,提出了依照一定的规则对关键词进行增补的思想。吴清强和赵亚娟[9]针对关键词所在的文献进行加权。Guo Chen, Lu Xiao, Chang-ping Hu, Xue-qin Zhao[10]从分析对象选择方面优化共词分析,作者认为分析一个研究领域热点时,不能只孤立地看它自身情况;而是要把它放在更大的背景内考察,国外学者Leydesdorff[11]也强调了关键词的差异性。以上这几种方法虽然对基于关键词的共词分析做了一定程度的改进,但是都仅仅对关键词的某一特性进行加权,并且以上方法均没有考虑由于各种客观原因造成的关键词的同义问题,没有对同义关键词进行合并。针对上述基于关键词的共词分析方法存在的问题,本文提出了一种融合加权思想和同义关键词合并的共词分析法,该方法根据关键词自身的特征以及关键词所在载体文献的特征对关键词进行加权处理,同时以同义词词林为基础,计算关键词之间的词语相似度,合并同义关键词。该方法既强调了关键词之间权重的不同,又消除了同义词对结果准确性造成的影响。
1 基于关键词加权的共词模型
正如本文前面叙述的,只是简单统计关键词在文献库中出现的次数,而不考虑关键词权重的共词分析方法,会对分析结果造成严重的失真。为此,本文提出了对关键词进行加权的共词模型( WK Co-word Model ),这种模型以键词自身特性为基础,并结合关键词的载体文献对关键词进行加权。
1.1 根据关键词自身特质加权
关键词的自身特性是指关键词所在文献中的位置、跨度、以及关键词的词性。根据关键词自身特质加权即根据关键词在文献中位置不同、跨度不同、词性不同赋予关键词不同的权重,从而解决关键词“同量不同权重”的问题。
1.1.1 关键词所处的位置加权
在一篇文献中不同位置的句子重要性有很大的差异。文献的标题、摘要毋庸置疑对于一篇文献的主题具有高度概括的作用。同样的,文献的首段、尾段、以及文献的每一段的第一句都有概括作用,都是文献主题的重要组成成分。由此可知,在关键词词频统计时候,关键词出现的位置不同,被赋予的权值也不一样。具体如下

1.1.2 关键词的词性加权
名词关键词相比于其他词性的关键词更能表达文献的主题,因此在设置权重时,将名词关键词的权重与其他关键词权重的词语区别对待,具体如表1所示。
1.1.3 关键词的跨度加权
一个词的跨段落情况表明了这个词是描述局部的还是描述全文的。跨段数越多,说明该词重要,全局性越强。
公式式(1)下所示,其中P表示词语出现的段落数;P表示文献总的段落,关键词的跨度Span为
Span=p/P
(1)
1.2 根据关键词载体加权
对不同被引用次数的文献,本文设定了不同的权值,关键词的载体是指关键词所在的文献,文献的重要程度不同,反映了该文献上的关键词的重要性不同。文献的重要程度主要体现在文献发表的期刊来源、文献发表时间、文献被引用的次数等,具体如表1所示。
另外,文献的被引用次数,代表着文献的被关注度,被引用次数高,说明文献所表达的内容是当前众多学者所关注的研究热点。具体如表1所示。

表1 关键词加权规则表
2 基于同义关键词合并的共词模型
2.1 根据词语相似度合并同义关键词
汉语博大精深,对概念的表达灵活、自由,使得不同的作者对相同的概念有不同的表达,这样就造成了关键词中存在许多同义不同词的表达,这些同义词如果不进行合并,那么统计得到关键词的频次就不准确。本文对同义关键词进行合并这将关键词统计从词语的层面上面提升到了概念的层面。首先计算关键词之间的相似度,目前,国内外计算词语之间的相似度的主要方法是根据语义词典计算词语相似度。基于同义词林的词语相似度算法得到的结果与人们思维习惯的词语相似度非常接近。因此需要先以同义词林为依据对关键词进行合并。
同义词林按照树状的层次结构把所有收录的词条组织在一起,把词汇分成大、中、小共3类,大类有12个,中类有97个,小类1 400个。每个小类都有很多词,这些词又根据词义的远近和相关性分成了若干个词群[12]。同义词林词典分类采用层次结构,一共5层层次结构如图1所示。
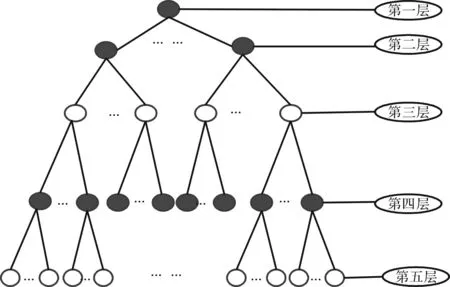
图1 同义词词林5层结构
本文根据同义词词林的编排特点,利用同义词词林的义项计算关键词相似度。主要算法思想是:利用同义词词林结构,得到关键词在词林中的编号,根据两个关键词的语义距离,计算出两个关键词的相似度[13]。
两个关键词A、B的相似度用 表示,根据A,B在同义词词林的位置不同, 有不同的表示,具体如下:
(1)两个义项不在同一棵树上,Sim(A、B)=f;
(2)两个义项在同一棵树上:在第2层分支,系数为a
Sim(A、B)=1×a×cos(n×π/180)(n-k+1)/n
在第3层分支,系数为b
Sim(A、B)=1×1×b×cos(n×π/180)(n-k+1)/n
在第4层分支,系数为c
Sim(A、B)=1×1×c×cos(n×π/180)(n-k+1)/n
在第5层分支,系数为d
Sim(A、B)=1×1×d×cos(n×π/180)(n-k+1)/ni
此外,为了确定相似度的阀值,本文通过实验证明当两个词语相似度>0.9时[14],两个词语之间可以相互代替。所以在本文中设置阀值为0.9,当相似度>0.9时,即认为两个关键词是相同的,可以予以合并为其中一个。该关键词的词频也变为两个关键词词频之和。
2.2 基于同义关键词合并构造共词模型
如果按照两两词语之间都要计算相似度的方法,那么将耗费大量的时间,整个程序效率就会非常低,这是不可取的。因此本文提出一种基于同义词合并的共词模型(CSK Co-word Model),此模型先根据同义词林的编排及语义特点计算词语相似度,同时又解决了不同词性的词语对之间的相似度很低,并且词频较低的词语对计算结果影响也较低[15]的问题。所以在本文中只计算词频大于某个事先设定好的阀值,并且相同词性之间的相似度。这样可以有效地减少比较的次数,从而大幅提高了相似度算法的效率。具体流程如图2所示。

图2 CSK Co-word Model 流程图
3 融合WK Co-word Model和CSK共词分析
融合关键词加权和同义词合并的共词分析算法包括以下3步,算法的流程描述如下:
(1)根据WK Co-word Model对关键词进行加权,得到关键词的频次集合L1={s1,s2,s3,…,sN};
(3)根据CSK Co-word Model,对集合L中的关键词进行同义关键词合并。其中词性为名词的关键词集合用Ln={s1,s2,s3,…,sn}表示。计算集合Ln中每两个关键词的相似度Sim(A,B),当Sim(A,B)>0.9,合并关键词A,B为同义个关键词;
(4)把同义关键词的频次相加Sim(A,B),得到最终的高频关键词集合Sum(A,B)。
4 实验及结果分析
4.1 实验数据准备
实验数据来自Medline数据库[16],以“代谢组学”、“蛋白质组”、“非编码RNA”、“基因组学”、“糖类”、“糖蛋白类” 、“多糖类”、 “癌症”、 “糖尿病”、“毒物学研究”、“输血”、“贫血症”、“髓膜炎”和“肝炎”为主题词得到15类文献,并标记出每类文献的80个能反映文献主题内容的关键词,同时对这80 个关键词重要性进行排序。
4.2 实验设计
为了验证基于本文WKWAIKW、UWKWA 、WKWA的3种方法。实验中,分别用以上3种方法选出前80个关键词。
4.3 评价标准
在本研究中,采用召回率R和准确率p作为算法性能评价指标。
定义1 召回率(Recall):用计算机找到关键词的个数与人工标记的80个关键词相同的比值。表达式为
R=B/A
(2)
定义2 准确率(Precision):计算机找出的关键词与人工标记的关键词相同且排序也相同的比例。它体现了准确程度。表达式为
P=C/A
(3)其中,A表示专家人工抽取的关键词并按重要性排好序的关键词集合;B表示通过计算机抽取的关键词并且与A中相同的关键词集合;C表示通过计算机抽取的关键词并且该关键词的排序与A中相同的集合。
4.4 实验结果及分析
表2给出基于本文的融合关键词加权和同义关键词合并的共词分析法(WKWAIKW)与传统的基于未加权的关键词共词分析方法(UWKWA )以及钟伟金等人提出的基于关键词加权但是没有合并同义关键词的共词分析法(WKWA)3种方法分别得到的数据。表5分别为以“代谢组学”与“蛋白质组”为搜索主题词得到的前10个高频关键词。图3和图4分别是WKWAIKW、UWKWA、WKWA的R、P的折线图。
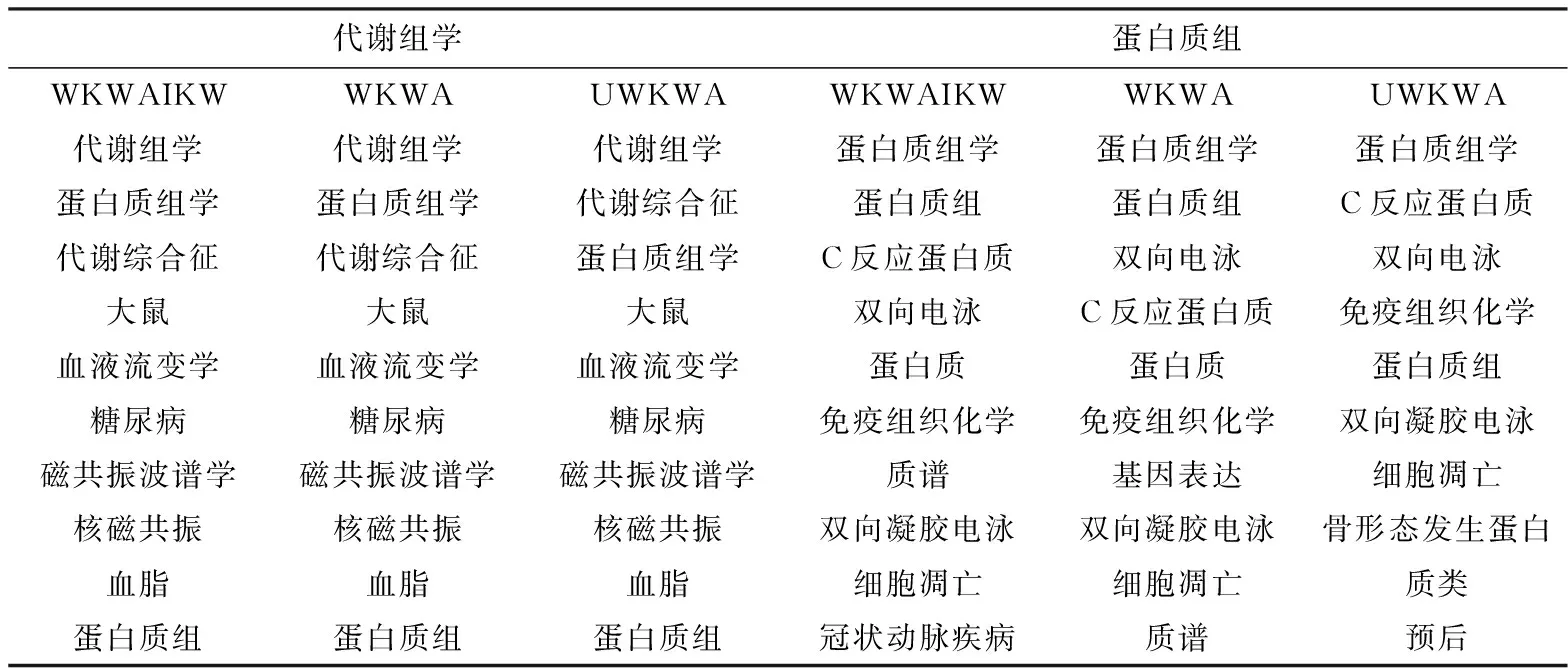
表2 分别用WKWAIKW、UWKWA、WKWA得到的高频关键词
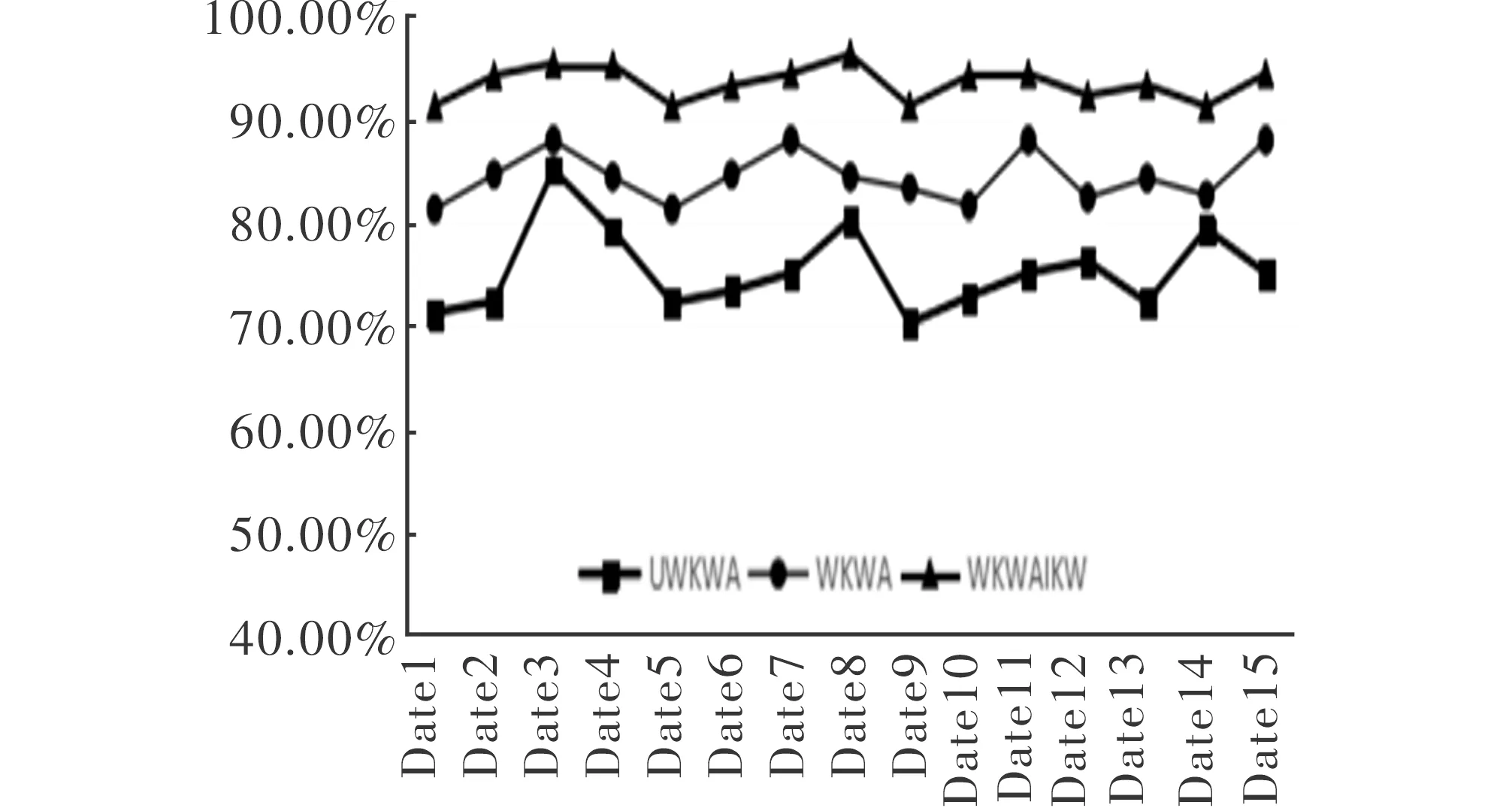
图3 WKWAIKW、UWKWA、WKWA的P值对比
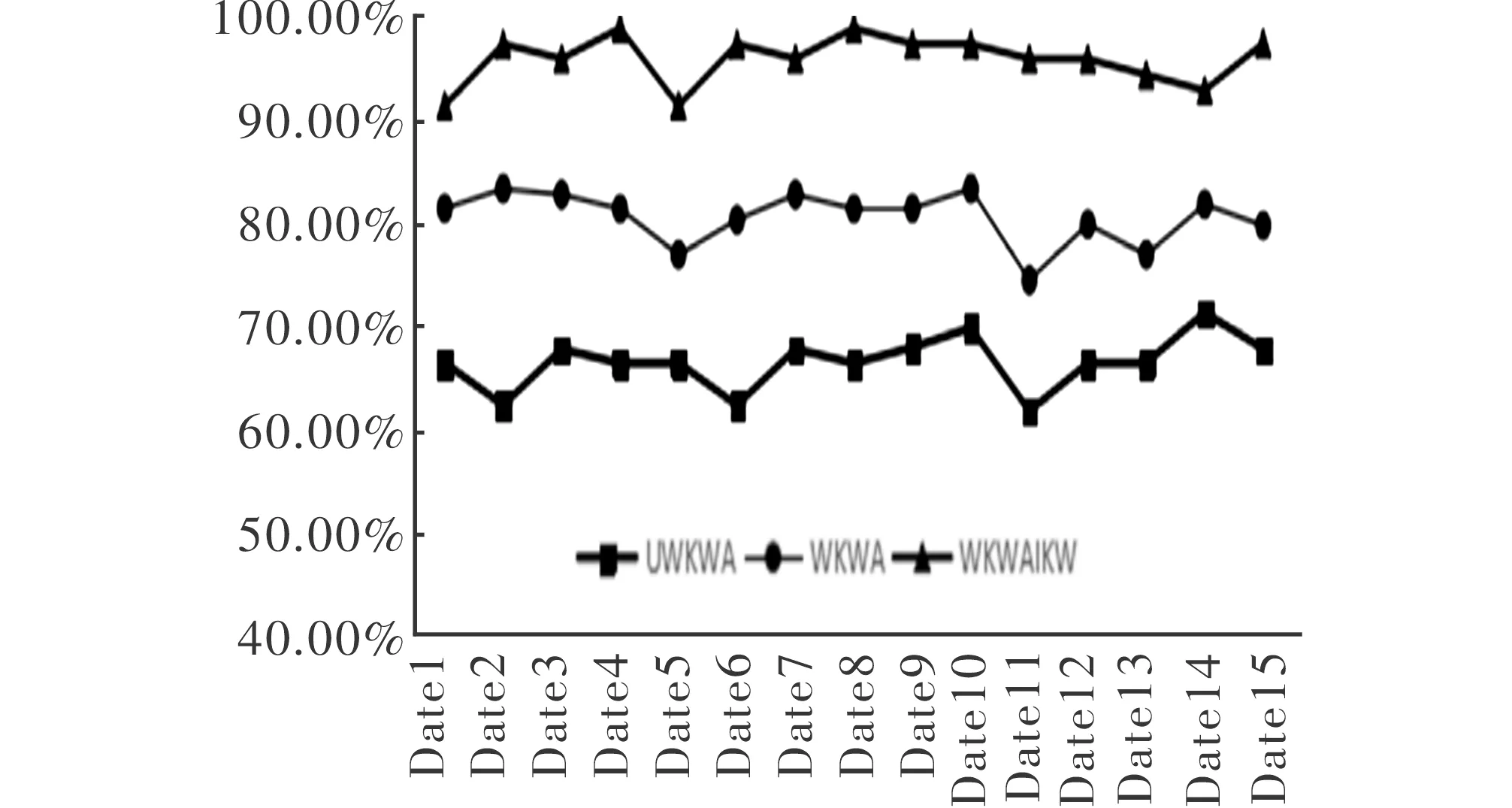
图4 WKWAIKW、UWKWA、WKWA的R值对比
图3~图4的数据可以看出,本文所提出的方法无论是准确率、召回率都比未加权的共词分析方法有显著的提高,接近人工标记的结果。这说明融合了关键词加权和同义关键词合并的方法能更准确的找到反应文献内容的关键词,提高了所提取关键词的质量。比传统的仅统计关键词出现的次数,决定哪些词是文献的热点词汇更有说服力。
5 结束语
本文结合关键词自身的特征以及关键词的载体文献的特征,对关键词进行加权,突破了传统基于共词分析方法在关键词词频统计时只是简单的累加关键词出现的次数,将词频较高的关键词就作为该类文献的特征词,同时,对关键词中的同义词进行合并,消除了由于汉语的灵活性及文献作者不同等客观因素造成的同义不同词的现象。实验证明,融合了关键词加权及同义词合并的共词分析方法在抽取能够表达文献意义的关键词时,有更高的正确率。
当然,这种方法也存在不足和需要改进的地方,比如本文只考虑了关键词的加权与相似度计算,但是并没有考虑在构造共现矩阵时,关键词对的绝对的共现频率也无法准确表达关键字之间的相互关系。或许也需要对关键词对进行加权。这也是本文后续需要研究完善的地方。
[1] 王林,冷伏海.学术论文的关键词与引文共现关系分析及实证研究[J].情报理论与践,2014,35(12):82-86.
[2] Dalpé R, Gauthier E, Ippersiel M P. The state of nanotechnology research[C].Report to the National Research Council of Canada,1997.
[3] 李颖,贾二鹏.国内外共词分析研究综述[J]新世纪图书馆,2012(1):23-27.
[4] 邵作运, 李秀霞. 共词分析中作者关键词规范化研究——以图书馆馆个性化信息服务研究为例[J]. 情报科学, 2012, 30(5):731-735.
[5] 李纲,李轶.一种基于关键词加权的共词分析方法[J].情报科学,2011 (3):321-324.
[6] Vaughan L,Yang R,Tang J.Web co-word analysis for business intelligence in the Chinese environment[J].Aslib Proceedings, 2012, 64 (6):653-667.
[7] 钟伟金. 基于主要主题词加权的共词聚类分析法效果研究[J].情报学报, 2009, 28(2): 214-219.
[8] 唐晓波,肖璐.融合关键词增补和领域本体的共词分析方法 [J].现代图书馆情报技术,2013, 29 (11): 60-67 .
[9] 吴清强,赵亚娟.基于论文属性进行加权共词模型探讨 [J].情报学报,2008(1): 89-92.
[10] Onoda T,Sakai M,Yamada S.Careful seeding method based on independent components analysis for k - means clustering[J].Journal of Emerging Technologies in Web Intelligence,2012,4(1):51-59.
[11] Leydesdorff L. Why words and Co-words cannot map the development of the sciences [J].Journal of the American Society for Information Science,1997,48(5):417-428 .
[12] 梅家驹,竺一鸣,高蕴琦,等.同义词词林 [M].上海:上海辞书出版社, 1993.
[13] 田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报:信息科学版,2010(6):602-608.
[14] 杨霞.基于同义词词林的微博客评论情感分类研究[J]. 电子科技,2014,27(7):134-136.
[15] 秦春秀,赵捧未,刘怀亮.词语相似度计算研究[J].情报理论与实践,2007(1):105-108.
Co-word Analysis Combining the WK and CSK Co-word Models
WANG Fuyan, SHAO Qing
(School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
Co-word cluster analysis based on keyword is a method for determining the research focus point in a field by the times keywords appear in the literature. Traditional co-word cluster analysis based keyword method simply calculates the absolute times keywords appear, ignoring the inherent characteristics of keywords and literature as well as the repeated keywords in concept, thus inaccurate results. This paper proposes a new co-word cluster analysis method that merges the keyword weighted model (WK Co-word Model) with synonymous keywords combined model (CSK Co-word Model). The method weights the keyword according to characteristics of keywords and the literature that keywords appear, and calculates the similarity of the keywords and combined synonymous keywords, which not only emphasize the different weight between the keywords, but also eliminates the effects caused by synonyms keywords. Experiment shows that the new method improves the accuracy of co-word cluster analysis.
keyword; weighted; co-word analysis; synonyms; similarity
2016- 03- 28
国家自然科学基金资助项目(61170277);上海市教委科研创新基金资助项目(02120557)
王芙艳(1989-),女,硕士研究生。研究方向:网络智能等。邵清(1970-),女,博士,副教授。研究方向:网络智能等。
10.16180/j.cnki.issn1007-7820.2017.02.029
G354
A
1007-7820(2017)02-110-05
