图书馆多源大数据融合研究:问题与挑战
2017-03-06马晓亭
摘 要 随着大数据的关联和交叉,图书馆的数据特征和实际应用需求都发生了变化,如何利用多源大数据的融合实现大数据价值最大化,是图书馆当下亟待解决的重要问题。论文分析了图书馆多源大数据的特征,讨论了大数据融合可能带来的挑战和问题,并且构建了大数据环境下图书馆的多源大数据融合与服务决策框架模型,有助于实现图书馆的信息资源整合。
关键词 图书馆 多源大数据 大数据融合
分类号 G255.76
DOI 10.16810/j.cnki.1672-514X.2017.01.007
Research on the Multi-source Big Data Fusion for Libraries:Issues and
Challenges
Ma Xiaoting
Abstract Data characteristics and practical application requirements have changed in libraries because of the link and crossover of big data. The immediate problem to be solved in library is how to use the multi-source big data fusion to achieve the maximum value of big data. This paper analyzes the features of multi-source big data in library, and discusses the challenges that may be caused by multi-source big data fusion. Also, a model of the multi-source big data fusion and service decisions for libraries under the big data environment is proposed, which will help the library to realize the information resource integration.
Keywords Library. Multi-source big data. Big data fusion.
0 前言
當前,世界已进入大数据时代。MGI(麦肯锡全球研究院)和麦肯锡商业技术办公室的研究报告指出,“当今世界的信息量已呈现爆炸式增长态势,分析大型数据集——即所谓的大数据,将成为竞争、引发新一轮生产力增长、创新及消费者剩余的关键基础之一”[1]。近年来,随着大数据技术的发展,大数据已成为图书馆发现读者需求、预测服务模式变革、评估服务收益率和提升服务生产力的重要依据。但是,伴随大数据技术在图书馆界应用的深入,图书馆的大数据环境呈现出“4V+1C”的特点,分别是数据体量巨大(Volume)、数据类型繁多(Variety)、价值密度低(Value)、处理速度快(Velocity)和具有较强的复杂性(Complexity),导致图书馆难以在海量、复杂和多类型的大数据环境中有效挖掘数据价值,大幅降低了大数据分析与决策的科学性、可靠性和可用性。因此,如何科学整合大数据资源,实现不同区域、行业和部门的大数据融合,是图书馆提升自身大数据应用水平和服务保障力应重点关注的问题。
我国从“八五”规划开始,把数据融合技术列为发展计算机技术的关键技术之一,众多科研机构和不同领域专家,开始了信息综合处理和数据智能化融合的研究[2]。随着云计算技术、传感器网络与数据存储技术的发展,大数据的采集、传输和存储等问题,已不再是制约图书馆大数据应用有效性的关键问题,如何科学构建数学模型,并对所采集的大数据进行自动化探测、互联、相关、估计和融合处理,已经成为当前图书馆界的研究热点。
1 图书馆多源大数据融合的问题与挑战
1.1 图书馆多源大数据呈现新的特征属性
伴随图书馆服务模式的变革与读者阅读需求的提升,图书馆数据除保留原有的“4V+1C”大数据特点外,还呈现出新的特征属性。首先,图书馆大数据除多源、多类型外,还具有在时间、空间、语义和底层属性上的多维度特征,并且其蕴藏的知识范畴的“粒度”多样,图书馆难以对数据进行识别和标准化处理。其次,图书馆在大数据的采集中,同一数据源产生的数据是随着时间、空间、作用对象和解释方法的变化而演变的,图书馆难以保证数据在多空间上的一致性,也不能有效控制数据知识的动态演化性[3]。第三,图书馆对所采集大数据的标准化处理和知识表达方式的多样性,以及大数据关系的动态演化和不确定性,增加了数据融合的复杂度和不可控性。第四,伴随大数据总量和数据关系复杂度的增长,大数据之间的隐性关联更加紧密,如何通过数据融合有效挖掘大数据关联中隐匿的知识,是图书馆大数据应用面临的挑战。
1.2 图书馆多源大数据融合面临的挑战
1.2.1 图书馆大数据具有多源异构的特性
大数据时代,读者的阅读活动呈现出移动性、高带宽、多模式和多终端的特点[4]。因此,图书馆采集的大数据呈现出海量、多源和多类型的特点,信息资源在组织上表现为非线性化和异构的特性,大数据的价值难以被发现和利用。
多源异构数据呈现分散采集和分类管理的状态,这些分别存储于不同的系统、节点和数据库的数据以数据孤岛的形式存在,增加了图书馆统一数据标准、统一管理平台、统一存储系统和统一数据接口的难度。此外,非结构化数据占据图书馆大数据总量的85%以上,如何跨越图书馆不同的部门、系统和对象,实现图片、视频、音频数据、文本数据等多结构数据的关联,也是图书馆大数据整合应重点关注的问题。
1.2.2 实时大数据增加了大数据的融合复杂度
伴随图书馆大数据采集终端数量和实时数据总量的激增,实时数据之间隐含的知识关系、特征将更加复杂,如何通过噪声过滤、价值提取等方法有效控制大数据的融合规模,是确保图书馆大数据融合结果可控、可用应重点关注的问题。
此外,传感器网络和物联网技术在有效感知读者需求的同时,也对图书馆实时数据流的传输、处理、存储和管理能力有了新的要求。如何在高效处理历史大数据的同时,完成实时数据的动态检测和实时分析,实现历史大数据与实时大数据的查询、融合和迭代分析,是图书馆提升大数据决策科学性和即时性的关键[5]。
实时大数据产生的速度和数据流量的快速增长,对图书馆数据库的存储、管理和维护能力提出了新的挑战。大数据融合过程如何动态、透明地统一数据源,实现大数据库对异构数据的索引和更新,并依据大数据类型和知识表示模式的变化而不断更新策略,是图书馆完全、即时发现实时大数据中隐匿的知识和数据关系的重要保证。
1.2.3 大数据融合系统对传感器系统的功能性需求
图书馆大数据融合系统是一个多源的信息重构框架,通过对多信息源、多媒体和多格式信息的挖掘与重构,生成完整、准确、及时和有效的综合信息,其中多传感器系统是图书馆数据融合的硬件基础,而多源信息是数据融合的对象,协调优化和综合处理是数据融合的核心。图书馆传感器系统可全面感知与获取读者行为、特征、服务器参数、运行日志等数据,其数据感知与获取的科学性与覆盖面,关系到大数据融合系统运行的效率、经济性与结果可用性。
图书馆大数据融合系统对传感器系统有较高的功能性需求。大数据融合系统的构建,应重点加强融合系统在时间、空间、语义和底层属性上对大数据多维度特征的覆盖,保证系统完全、高效地发现大数据关系并融合数据价值[6]。其次,如何有效实现读者特征数据、阅读行为数据、服务数据和服务器参数的多传感器采集,不断提升传感器所采集大数据的准确性和价值密度,是确保图书馆大数据融合系统运行高效、精确和容错的前提。第三,传感器系统应实现对所采集对象多个不同特征的综合描述,通过对传感器所采集数据多特征信息的互补,有效增强传感器系统采集数据的正确性。此外,如何降低传感器系统的建设和部署成本,也是图书馆有效提升大数据融合效率和降低数据融合成本应关注的问题。
1.2.4 大数据开放与安全之间的矛盾
为了提升大数据的价值总量和价值密度,图书馆通常会采用传感器、视频监控系统、服务器监控设备和读者管理信息系统等,全方位、多角度、不间断地采集服务数据和读者特征数据。此外,图书馆还可通过与第三方大数据共享的方式,避免数据库的重复建设和大数据资源的重复采集。这些大数据中,有部分数据是涉及国家机密、企业秘密和读者隐私的敏感数据,如何快速识别敏感数据并划分数据的安全级别,依据数据的安全级别制定和执行相应的大数据存储、融合安全策略,关系着图书馆大数据融合的安全性和可靠性。
其次,图书馆内部不同部门、服务系统、第三方服务商之间,缺少统一的数据规划、采集和存储标准,导致许多大数据以“信息孤岛”的形式存在,较低的数据开放程度严重影响了大数据融合的效率和可用性[7]。因此,图书馆通过数据类型标准化和数据库共享全面开放大数据的同时,保证读者对自身小数据的知情和控制,是图书馆个性化服务可信度和读者阅读满意度的关键。
2 图书馆多源大数据融合管理架构图与管理策略
2.1 图书馆多源大数据融合管理与服务决策系统的组织架构
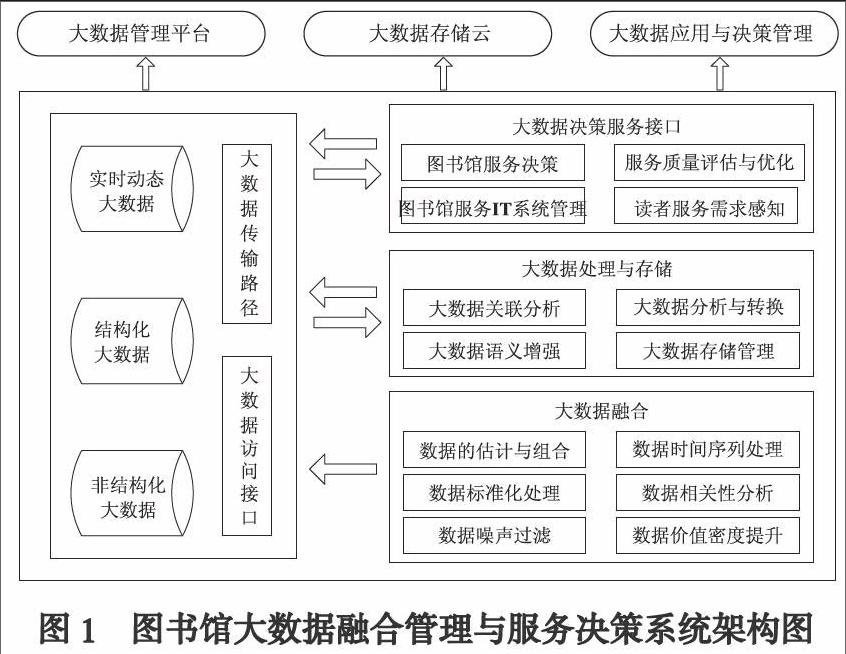
根据图书馆大数据呈现出的“4V+1C”特点,本文设计的图书馆大数据融合管理与服务决策系统如图1所示。
该系统主要由大数据存储私有云、大数据融合系统、大数据处理与存储管理系统、大数据决策服务接口4部分组成[8]。大数据存储私有云按照大数据的结构特征和应用价值,分为非结构化大数据存储库、结构化大数据存储库和实时动态大数据库3部分,可为结构化数据与非结构化数据、实时数据与历史数据的融合提供数据存储服务。大数据融合系统通过数据噪声过滤、价值密度提升和数据标准化处理,在有效降低大数据融合的复杂度和成本后,经过大数据的估计与组合、数据时间序列处理和相关性分析等操作,实现大数据的融合和数据标准化处理。大数据处理与存储系统主要通过大数据存储管理、语义增强、关联分析、大数据分析与转换等,完成融合大数据价值的二次发现,为大数据决策提供可靠的数据支持[9]。大数据决策服务基于底层大数据处理与存储系统的支持,为图书馆IT服务系统管理、读者阅读需求感知、服务策略制定、服务质量的评估与优化提供可靠的大数据决策依据。
2.2 图书馆多源大数据的融合管理策略
2.2.1 实现图书馆内外部大数据的统一融合
加强多传感器数据、不同业务部门数据、第三方服务商数据的融合,是圖书馆增强大数据融合和数据价值二次挖掘有效性的关键。
随着传感器制造成本的大幅下降,图书馆会在多个位置放置更多的传感器,以此提升对读者阅读需求和服务有效性感知的敏感度与精确性。多传感器数据在提升大数据总价值量和可用性的同时,也存在着数据价值密度下降和冗余的缺点,严重影响大数据融合与数据价值二次发现的效率。为了提升多传感器大数据融合的可用性,图书馆应对多传感器采集的数据进行标准化处理,有效统一大数据的类型和结构,并以数据采集对象为索引,实现大数据采集对象在特征向量和物理属性上的集合与分类。当图书馆进行大数据决策时,可根据决策应用需求在大数据集中选取恰当的特征向量和物理属性数据,通过数据的实时融合来提升数据决策的可用性和针对性。比如在读者阅读需求的预测上,可以将读者历史阅读数据、阅读终端实时数据、读者阅读需求数据等进行实时融合,而不需要将读者位置信息、移动路径数据、读者阅读关系等无关大数据融合[10]。
此外,应实现图书馆内部不同业务部门之间,以及图书馆和第三方服务商之间大数据的融合。数据孤岛是严重影响图书馆大数据关系发现和数据价值二次挖掘的重要问题,图书馆应在确保数据安全和读者隐私的前提下,实现内部不同业务部门、第三方服务商和政府相关部门间的数据公开与共享。社交网络、移动互联网、信息化企业、电信运营商等都是海量数据的制造者,图书馆将第三方大数据与自身大数据进行融合,可有效提升图书馆大数据的价值总量、决策科学性和大数据应用经济性[11]。
2.2.2 增强无线传感器数据融合的实时性
无线传感器数据融合通过对多个无线传感器数据进行处理,组合出具有更少数据总量、更高价值密度和可用性的数据。无线传感器网络具有安装便捷、使用灵活、经济节约和易于扩展的特点,已成为图书馆读者行为数据和用户服务数据采集的主要模式。为了保证大数据采集全面、准确,图书馆无线传感器网络通常由多个传感器共同完成大数据的感知和采集,然后将采集的大数据经噪声过滤和融合后,传输至图书馆大数据库进行存储。这种利用无线传感器冗余配置,来提升移动大数据监测和采集可靠性的方式,在提升图书馆无线感知敏感性和准确性的同时,也产生大量的冗余数据[12]。因此,提升数据的价值密度和减少数据总量,是图书馆确保大数据决策实时性的关键。
首先,图书馆应通过数据噪声过滤,增强所采集大数据的相关性,在确保大数据精确性的前提下,清除位于同一监测区域的多传感器采集的相同或相似数据,有效降低拟融合的数据总量。其次,为防止无线传感器在数据融合中丢失重要的细节信息或者降低数据质量,图书馆应对融合前后的大数据价值总量、数据融合与应用层数据语义的关系、数据融合操作的深度进行评估,不能因数据的过度融合而降低无线大数据的价值总量、相关性和可用性。
2.2.3 大数据融合应以读者个性化服务需求为依据
提升图书馆对读者需求的感知、保障和服务能力,是图书馆大数据融合的根本目标。
图书馆对读者大数据个体的融合应坚持以读者的身份ID为索引,实现图书馆内部多业务部门、多服务商数据、线上与线下数据的融合[13]。通过对这些相关融合大数据的分析,在保护读者隐私的前提下,完成读者在时间、地理位置、阅读行为和语义特征上的四维度感知,激发读者潜在的服务需求。其次,服务时效性是关系读者个性化阅读满意度和图书馆服务效率的关键因素。图书馆应通过数据融合来提升对读者需求的感知力,精确预测读者阅读需求的时间、内容和模式,并在恰当的时间完成图书馆个性化服务的精确推送,增强读者阅读的愉悦感和满意度。此外,通过大数据的融合、分析来预测图书馆服务负载的变化趋势,也是图书馆合理调配服务系统资源和预防服务拥塞的重要依据。
2.2.4 大数据融合应确保大数据安全和读者隐私
图书馆通过将读者个体数据与其它相关大数据的融合、分析,可以精确发现读者的阅读需求、模式、习惯和社会关系,但对读者特征大数据的过度融合和数据关联性的发掘,则可能会导致读者的隐私泄露。因此,图书馆应通过对大数据敏感度的评估,以及大数据融合过程的监督与控制,来保证大数据融合的数据安全和读者隐私。
图书馆大数据融合的根本目的是增强数据的关联性,有效提升大数据的价值总量和价值密度。为了防范大数据融合过程可能发生的数据侵犯和隐私泄露问题,图书馆应构建大数据敏感度与大数据融合过程的风险评估机制,依据大数据敏感度执行动态的数据风险预警和安全防范策略。同时,在大数据融合过程中还应采用数据溯源技术,支持图书馆逆向发现大数据的融合风险及其产生的原因。此外,图书馆应根据大数据的安全管理和读者隐私保护需要,判断大数据的字段名称、字段类型、字段长度和赋值的敏感性。对于涉及图书馆安全、管理、运营与读者隐私重要数据,则可通过匿名、替换、加入随机噪声、顺序、时滞和取消等方式,在保留大数据价值、准确性和易用性的前提下取出敏感信息[14]。
3 结语
当前,图书馆大数据的采集从传感器网络的感知层到读者阅读活动的应用层,涉及图书馆日常运作的所有环节,这些环节产生的大数据总量以指数级增长,传统的提升IT设备数据处理能力的方式,已不能满足图书馆大数据处理的需求。因此,科学、高效地融合、挖掘和智能处理海量大数据,已成为关系图书馆发现大数据价值和确保大数据决策科学性的重要因素[15]。
为了保证大数据融合过程安全、高效、经济和可控,图书馆应遵循大数据的生命周期规律,重点加强大数据在采集、噪声过滤、传输和存储过程中的质量管理,确保大数据具有较高的数据价值密度和可用性。此外,还应不断增强图书馆大数据融合系统在硬件平台、应用软件和数据融合策略上的相关性,处理好数据转换、数据相关、态势数据库、融合推理和融合损失等关键问题,为图书馆管理和读者服务提供可靠的大数据决策支持。
参考文献:
[ 1 ] Nature. Big data[EB/OL].[2013-06-17].http://www.nature.com/news/specials/bigdata/index.html.
[ 2 ] 郭春霞.大数据环境下高校图书馆非结构化数据融合分析[J].图书馆学研究,2015(5):30-34.
[ 3 ] 钟声.大数据驱动的高校图书馆数据监护探究[J].情报资料工作,2014(3):103-106.
[ 4 ] 李建中,刘显敏.大数据的一个重要方面:数据可用性[J].计算机研究与发展,2016,53(2):1-16.
[ 5 ] 唐晓波,朱娟,杨丰华.大数据环境下的知识融合框架模型研究[J].图书馆学研究,2016(1):32-35,18.
[ 6 ] 孟小峰,杜治娟.大数据融合研究:问题与挑战[J].计算机研究与发展,2016(2):231-246.
[ 7 ] FISCH D,KALKOWSKI E,SICK B. Knowledge fusion for probabilistic generative classifiers with data mining applications[J].IEEE Transactions on Knowledge and Data Engineering,2014(3):652-666.
[ 8 ] 沈旺,李亚峰,侯昊辰.数字参考咨询知识融合框架研究[J].图书情报工作,2013(19):139-143.
[ 9 ] SMIRNOV A,LEVASHOVA T,SHILOV N. Patterns for context-based knowledge fusion in decision support systems[J].Information Fusion,2015(21):114-129.
[10] 廖龍龙,叶强,路红.面向移动感知服务的数据隐私保护技术研究[J].计算机工程与设计,2013,34(6):1951-1955.
[11] PAPADAKIS G,KOUTRIKA G,PA-
LPANAS T,et al. Metablocking:taking entity resolution to the next level[J].IEEE Trans on Kno-
wledge and Data Engineering,2014,26(8):1946-1960.
[12] 陈茜,史殿习,杨若松.多维数据特征融合的用户情绪识别[J].计算机科学与探索,2015(10):1-11.
[13] 维克托·迈尔·舍恩伯格,肯尼思·库克耶.大数据时代:生活、工作与思维的大变革[M].盛杨燕,周涛,译.杭州:浙江人民出版社,2012.
[14] 马晓亭.开放环境下图书馆敏感大数据保护研究[J].高校图书馆工作,2015,35(5):33-363.
[15] 唐晓波,魏巍.知识融合:大数据时代知识服务的增长点[J].图书馆学研究,2015(5):8-14.
