基于数据融合方法的群推荐系统研究
2017-03-02锐李军葛晓滨叶淳康
王 锐李 军葛晓滨叶淳康
(1 安徽城市管理职业学院,安徽 合肥 231635)
(2 安徽工商管理学院,安徽 合肥 230027)
(3 安徽财贸职业学院,安徽 合肥 230601)
(4 香港城市大学,香港 999077)
1 引言
推荐技术在当今的互联网产品中已经得到了广泛的运用,它可以根据用户的行为数据,结合机器学习和数据挖掘算法,自动的给用户提供内容,在提高网络使用效率上发挥了积极的作用。随着互联网技术和用户需求的发展,推荐系统针对不同的情境需要不同的解决方案。群推荐希望对一群用户推荐可能存在共性的内容,这种形式的推荐技术在团购,餐饮,旅游,兴趣小组等集体性质的互联网产品上有很大的需求。随着互联网虚拟社区发展,加入群组获得信息和资源比单一的搜索和使用普通个性化推荐更加有效,因为前者需要明确的目标,而后者需要丰富的历史信息,群组自动集中了兴趣相似的用户并通过群推荐技术把推荐得到的内容推荐给所有人,既提高效率也增强了效果,加上群组中的用户之间可以进行交流,让推荐更加具有互动性。
数据融合作为一门信息处理技术,在信息检索、搜索引擎等互联网应用上也有很广泛的运用。另外,作为一门新兴的交叉学科,其发展的适应性很强,但是暂时很少有研究将数据融合技术运用到群推荐领域,或者重点突出数据融合的思想在群推荐技术中的作用,更多的是简单的平均加权得到推荐结果。群组推荐对推荐的数据融合类似于信息检索中的数据融合,同时也存在着差异性。信息检索系统得到的检索结果是匹配搜索得到的结果,其有效性与搜索相关,所以其数据融合技术围绕检索结果相对于搜索的准确性,而群组推荐不存在搜索项,其效果是推荐后评估得到的。其融合的关键并不是准确性,而是用户之间的相似点。基于此,检索系统数据融合中很多关于准确性的融合算法设计思想并不适用于群组推荐。如何研究出更适应群组推荐特性的数据融合技术也是把数据融合技术融入群组推荐的关键以及难点。
本文试图运用一种更适合群组推荐的数据融合方法来发掘用户的商品偏好模式。由于群中每个用户的推荐列表的偏好分值的量纲并不统一,而简单的标准化并不能解决这个问题并带来了更多数据缺失产生的误差。而使用马氏距离等距离测算方法大大增加了数据融合的复杂性和实现难度。因此,本文运用了一种基于排序的用户偏好相似性度量,这种度量方法在确定相似性过程中忽略了推荐列表评分值,仅根据推荐商品的排序进行度量,得出的用户之间的相似度是量纲统一的。并且缺失值对结果的影响远小于基于分值的相似度确定方法,在效果上结合了高效和高质量的优点。由排序相似性最后求得用户的偏好权重在反应用户和群组的相似性效果上比单纯的推荐分值距离测算更接近事实,而在效率上比马氏距离等复杂距离公式高效。
2 基于数据融合的群推荐系统框架
本文使用聚集预测模型,首先将预处理得到的用户行为矩阵使用传统的协同过滤技术得出单个用户的推荐列表,再使用数据融合的思想计算出每个用户的权重,最终采用加权融合技术测算得到群推荐结果。
首先我们使用传统的协同过滤算法得到单个用户的推荐列表,其主要包括相似性度量寻找近邻以及项目评分预测。实验使用MyMediaLite软件进行协同过滤,使用基于用户的协同过滤,首先要确认用户的近邻,然后通过近邻和相似度给每个用户进行预测,排序后产生每个人的推荐列表。

图1 基于数据融合的群推荐框架
然后我们使用基于排序的用户相似性度量来确定群用户之间的偏好相似性,本文根据偏好排序的无量纲性的特点设计了一种更灵活的相似性确定方法,然后根据用户的相似度确定用户在群中的权重,最后根据物品在群中的推荐分值分布以及用户的权重得到该物品最终的群推荐数值,取分值Top-N物品得到群推荐列表。
3 基于排序的用户相似度模型
3.1 基于排序的用户相似度模型的优势
计算相似度有很多方法,不过大部分算法的数据是提供了用户的评分值的,所以不存在量纲不统一的问题。本文考虑到没有评分的用户行为分值的量纲问题,提出了一种基于排序的相似性度量方法。
相似度反映了群组内各个用户偏好的相似性,可以想象,要想群体的整体满意度提高,就应该选择群组里具有普遍偏好的商品。从另一个角度看,一个群组中和其他人偏好更接近的人应该有更大的参考价值。比如说一个群组的大部分人喜欢体育和文学,那么一个在这两方面都有兴趣的人的推荐列表应该比一个喜欢IT的人重要的多,同时也比喜欢体育但不喜欢文学的人要重要。如果给相似度较高的人较高的权重,那么群推荐的满意度应该就会提高。因为其更接近群的偏好。
如果给用户按照和群的相似度从左到右排序并设为x轴,推荐结果设为y轴,并将数值抽象为n维一个点,我们可以假设如果这些用户做出推荐都是独立同分布的,那么群推荐系统情境下的用户权重也应该符合高斯分布,那么和群相似性越高的用户也就是差异度越低的用户权重也越高,如图2。图中相似度可以粗略假定为和0轴的接近程度。我们可以假定权重等于相似性的概率。当然如果有适用于计算n维的高斯分布和确定的群推荐结果的n维表达,我们还可以进一步优化权重的表达。
本文使用数据融合的方法来反应用户之间的相似度,通过对集中数据融合方法的研究,我们可以发现基本的数据融合方法都适用于群推荐系统,不过由于情境的不同,方法的效果在具体运用时需要根据群推荐本身的特征加以改进。
正是基于这种考虑,我们设计了一种计算用户之间排序相似度的算法,并进而计算每个用户的相似度权重用。该算法可以解决量纲的问题,同时对缺失值的处理较好,在无评分的推荐结果聚集情境下的效果较好。

图2 偏好相似性和权重的关系
3.2 基于排序的用户相似度模型的实现
正如上文所说,评分的相似度在本文的情境下无法实现,不过推荐列表的排序量纲性,因为每个人的商品集是一样的。虽然最后的个人推荐列表各不相同,我们可以从中发掘出关于排序的模式相似度的一个度量。我们首先计算每两个用户之间的相似度,然后求得相似度平均值作为用户和群组的相似度度量,即得到用户的相似度权重。
本文结合了一种要素模型来解释相似度,认为两个对象之间的偏好相似度应该考虑相同内容占所有内容的比例。
两个对象之间的共有元素可以用相似性度量的要素模型来解释,最常用的包括要素—匹配模型,如图3所示,A,B分别表示两个不同的对象,则两个对象之间的相似度可以用公式(1)来计算。

其中f(X)函数表示集合所含元素的个数,x,y,z分别表示三个集合的权重,在这里我们定义为1,因为每个物品都是相同属性并且互相独立的。Sim表示集合部分的相似性,由于不重合部分我们不能判断排名差异,我们估算为0,这存在一定的误差。
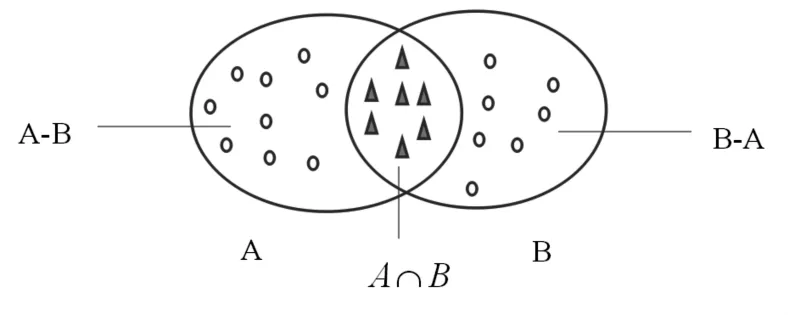
图3 要素—匹配模型
接下来我们就要计算相同元素的相似性,我们假设群组有p个用户,每两个人的推荐列表拥有同样的推荐数量n,如果两人间重复的推荐商品为m,如公式(2)。其中m表示两个对象间相同元素的个数,rA(di)表示用户 A 对物品 i的排名。

计算完相似度后,我们可以得到一个(p-1)*(p-1)的相似度矩阵,然后我们用公式(3)求得每个用户的相似度向量的平均值作为相似度权重。
相似性度量算法的证明如下:
a)自反性
当A=B时,即可以得出推荐列表相同,相同推荐物品数m=n,并且排名相同,显然可以证明等式(4),进而可以得出 Sim=1。

b)对称性
首先根据绝对值的性质,我们可以得出|a-b|=|b-a|,然后我们可以发现A和B的相同物品数也符合对称性即 m=m,设相似性度量公式简写为,我们可以得出等式(5),得证。
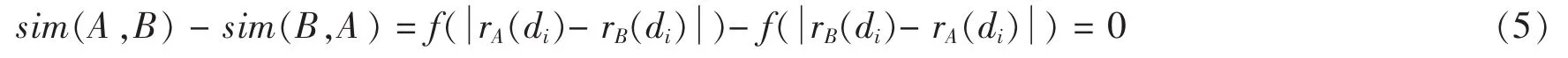
c)取值范围
根据要素匹配模型的基本定义,我们可以得出该相似性度量的取值范围取决于每个要素的相似性取值范围,由于非重复部分的取值等于0,取值范围取决于m的值以及重复部分的相似性取值。确定m后,相似度取值范围为[0,m/(2*n-m)]。首先我们可以得出排序差值绝对值除以n-1,也就是最大排序差值的取值范围为[0,1],所以m个上述值的平均数也符合该取值范围,只有当两个排名相等时等于0,当两个排名正好是最高和最低时等于1,该式计算两个排名的差异度,1减去该式为相似度。整体的相似度还需考虑到m的取值,只有m=n并且排名相同时相似度等于1.
在得到了每个用户的权重之后,我们就可以得到每个商品的融合推荐数值,文章使用线性加权如

G表示群组,I表示物品,群组u表示用户,w表示用户权重。取Top-n为群组推荐列表。
4 实验与测试
4.1 实验使用的数据集
本文使用有超过1500万活跃听众的全球最大的社交音乐平台Last.fm的数据集作为测试集。Last.fm是一家充分利用用户的收听习惯的音乐个性化网站,通过每个用户的收听行为提供个性化推荐,联系品味相近的用户,提供定制的电台广播及更多其他服务。通过the Scrobbler软件记录用户在iTunes,foobar等国际上主流的音乐播放器的音乐行为。
使用的数据集包含10936545条user-item-tag记录和1011280条group-user记录为原始数据,其中每条user-item-tag记录代表该用户标签过该音乐和所作的标签,每条group-user记录代表某群组有这个用户。数据包含了99405个用户(其中活跃用户52452个,也就是有记录的用户),1393559首音乐,282818种标记以及66428个群组,由于数据量庞大,我们需要对数据进行缩减过滤。
实验首先得到每个用户对应的记录次数,设置10为阈值,得到活跃用户29305位。然后选取活跃度最高的10个群组用于之后的协同过滤,因为这些用户可能会有更多相似的爱好。这10个群组包含30772条group-user记录,其中活跃用户9598位,这些用户对应的不重复user-item记录1874596条,去除只标记1次和2次的音乐还剩下627826个记录,用户6620个。以此作为接下来协同过滤的目标数据源。实验证明该数据源得到的矩阵稀疏性明显改善。并且数据量不会占用过大的内存。将记录的80%设置为训练集,剩下20%设置为实验集,为实验用的群组中的每个用户推荐一定数量的歌曲,由此得到用户的协同过滤的结果,数据分为用户,音乐以及分值三列。
为了简化实验过程,选取用户数在5—80区间并且大部分属于这6620人的群组,然后把这些群组根据人数分为3大类,进行后续的实验和检验。在这里,群组划分为5—10人,10—30人,30—80人三类,每类协同过滤分别推荐200,400和800个商品。
4.2 推荐结果有效性评价指标
本文使用召回率值和f1值来测评推荐算法的优劣,计算公式如下:公式(6)对每个商品进行计算。

召回率公式可以检验推荐算法的预测结果,越多的物品被推荐,说明该方法推荐越符合用户的可能偏好。F1考虑到精确度以及召回率,不过两个公式都不能检测用户以及群的满意度,这一点限于数据的单一性,不能得到用户的评分以及反馈,也希望后来的研究可以得到改善。
4.3 实验结果及展示
由于A群的用户仍然偏少,很多组的结果都基本相同且召回率大大低于其他群组,文章过滤了这些群组,剩下的10组用于检验结果的比对。10—30组也存在召回特别少的群组,取10组用于实验。30—80人的取所有15组用于实验。
4.3.1 A群实验结果
首先我们比较A群的使用不同方法的召回率和f1值。我们分别画出四种方法在推荐50、100和200首歌时的线形图,如图4和5:
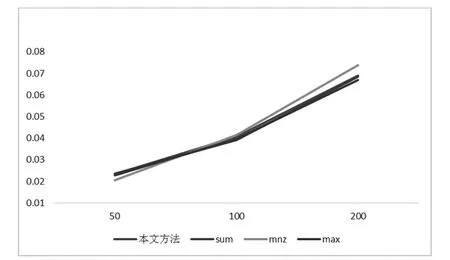
图4 A在推荐不同数量音乐时4种方法的平均召回率

图5 A在推荐不同数量音乐时4种方法的平均F1值
可以发现文章算法在5—10群组中本文方法有效性和其他3种方法一样都不太稳定,在推荐数量较大时CombMNZ算法表现出较好的效果,因为他考虑到每个物品被提及的次数,这在预测问题上会体现出比较直观的效果,特别是小群组的情况,CombMAX方法总体较差,因为他只考虑最高的分值,忽略了其他用户的分值,这种方法在用户满意度上会表现出更差的效果。总的来说,4种方法在小群组的有效性并不固定,说明测评方法在小群组分析中并不稳定。文章认为这是因为小型兴趣群组的每个用户之间的关系难以反映出趋势,另外协同过滤推荐的商品偏少,算法求出来的权重不会相差太多,加上协同过滤算法推荐列表的局限性,很难有新产品的突破。为此,我们认为如果能由此分析出群组偏好进行结合基于用户和基于物品的协同过滤方法,也许会有更大的突破。
4.3.2 B群实验结果
然后我们比较B群的不同方法的召回率和f1值。分别画出推荐50、100和200首歌时的线形图,如图6和7:

图6 B在推荐不同数量音乐时4种方法的平均召回率
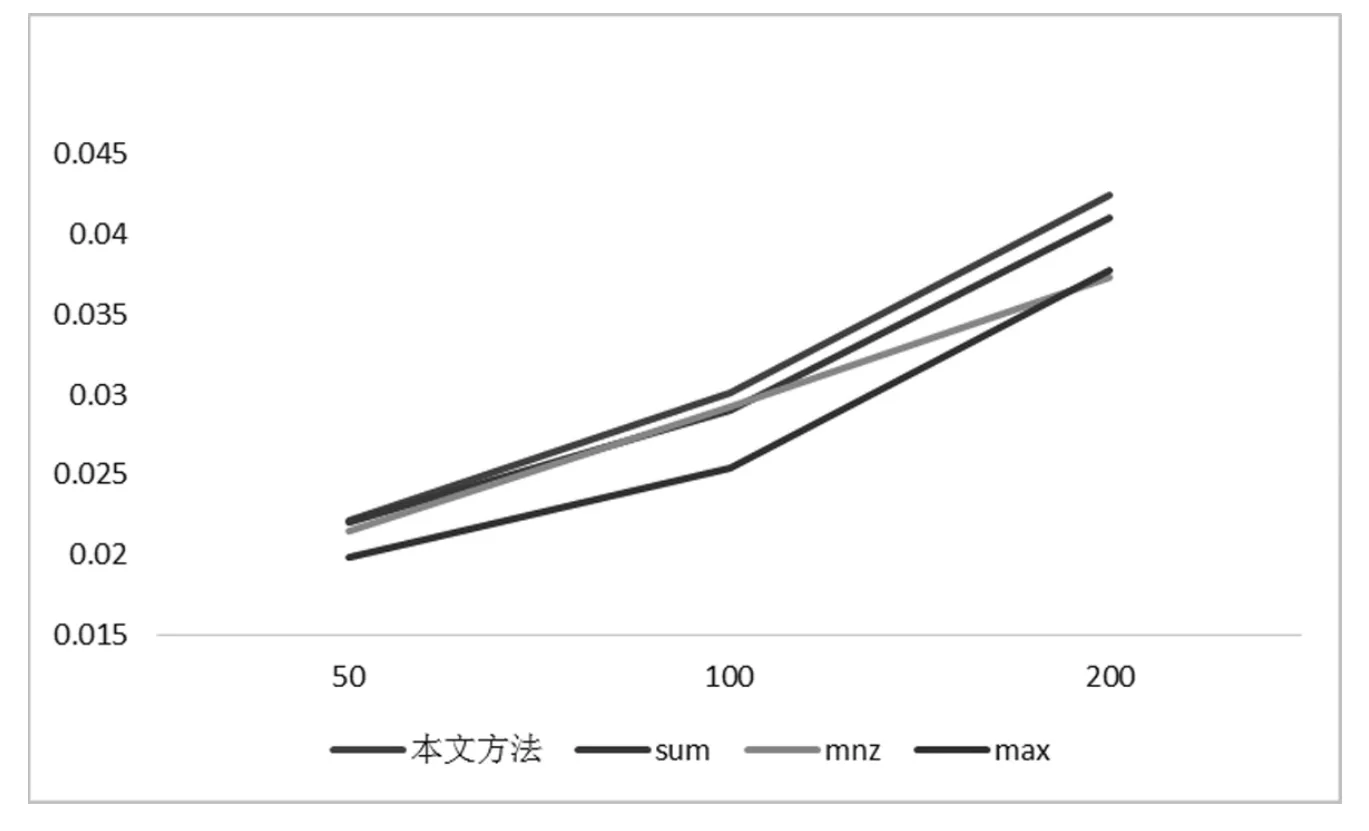
图7 B在推荐不同数量音乐时4种方法的平均F1值
在推荐大小在10—30用户的群组时,本文方法表现出较好的推荐效果。并且我们可以发现CombMAX方法在群组人数增大时效果会明显变差,进一步验证了上一小节关于该方法的假设再推荐50,100和200首歌时本文方法的召回率和F1值都比CombMAX提高10%—20%。CombMNZ方法在这次实验中没有表现出优势,在推荐200首音乐时本文方法的召回率和F1值分别比CombMNZ高13.8%和13.7%。文章认为该方法给物品提及数赋予了过度的权重。CombSUM和本文方法都比较稳定,从数据上可以发现,本文方法在推荐50首音乐时效果和CombSUM类似,推荐100首音乐时召回率比CombSUM方法提高3.3%,F1值提高3.8%,推荐200首音乐时召回率提高1.8%,F1值提高3.5%。经过以上对比测算,本文所提出的方法试验效果最好。
4.3.3 C群实验结果
最后我们比较C群的不同方法的召回率和f1值。画出推荐50,100和200首歌时的线形图,如图8和9:
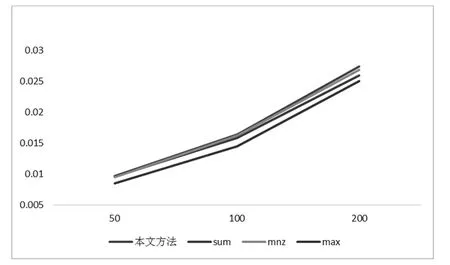
图8 C在推荐不同数量音乐时4种方法的平均召回率
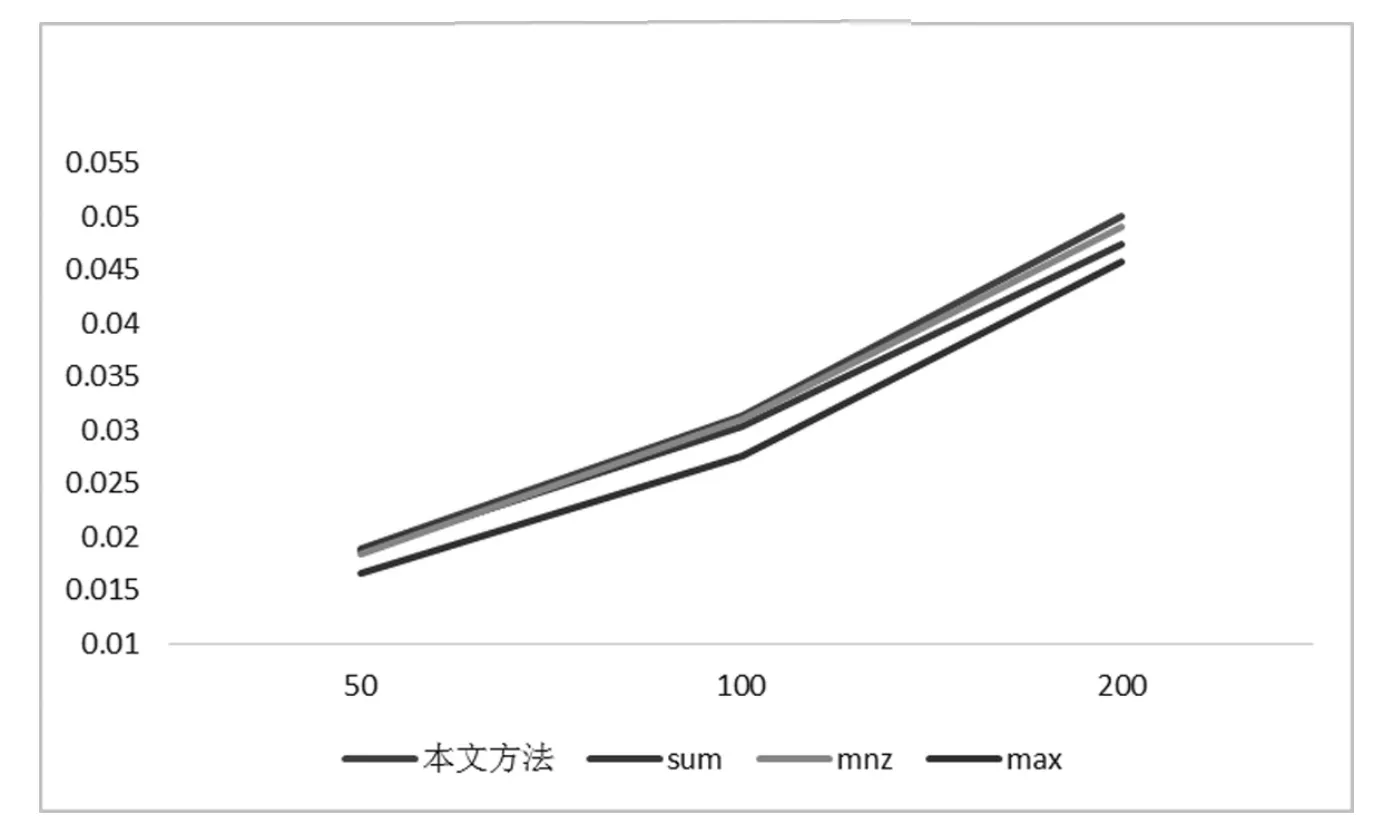
图9 C在推荐不同数量音乐时4种方法的平均F1值
在C类群组中,有效用户占比例较少,可能会有大量的信息丢失,不过另一方面,用户数增多可以更好反映方法的有效性,可以发现C群的实验结果和B群类似,本文方法稍优于CombSUM以及CombMNZ,在推荐50首音乐时三种方法类似,在推荐100首音乐时,本文方法比CombSUM的召回率和F1值都提高3.2%左右,比CombMNZ高1%左右。在推荐200首音乐时,本文方法比CombSUM的召回率和F1值都提高5.5%左右,比CombMNZ高2%左右,本文方法推荐不过并不明显,CombMAX方法效果明显不如其他三种,不过推荐多少音乐,本文方法的召回率和F1值都比CombMAX高出10%以上。
总的来说,本文的方法在用户数在5—10人的群中并没有体现出优势,随着群组人数增加,方法表现出比其他方法更好的推荐效果,特别在推荐较多商品时,其召回率和F1值的效果较好。不过还不是很明显,说明相似性度量还需要不断地改进,由于召回率和f1比较了了方法的预测能力,而本文方法提高了推荐商品和群组的相似性,提高推荐的满意度。更好的评测方法需要进一步的探究用户的满意度等。
5 总结与展望
本文对传统的群推荐技术提出了改进和创新,结合数据融合的思想提高群推荐的总体满意度和精度。文章认为提高群推荐的效果和满意度需要考虑群用户之间的关系,而这一点也可以在做出单个用户推荐后通过算法比较,文章使用用户的排序相似性计算每个用户和群组的整体相似度从而计算用户的权重,利用线性加权得到修正的群推荐列表,该方法在保留了原本个性化推荐算法的优势的前提下,通过再次比较得到更优的效果,而且和得到个人推荐的算法是相互独立的,本文使用了基于用户的协同过滤算法,得到结果相比传统的推荐结果更接近群组偏好,进一步提高推荐的满意度以及推荐效果。
未来我们将进一步优化相似性算法,现在的计算只是对协同过滤的结果进行上述计算,这其中仍然存在信息的缺失。如何提高精度是下一步需要研究的,寻找更科学可靠的相似性度量方法,结合更适合群推荐的推荐算法以进一步提高推荐效果。本文给出的建议是建立物品的类别属性,将相同属性的物品归为同样的类别,并且可以调整类别的聚集精度。用这种方法可以大大降低排序误差带来的影响,可以更好地确定群组偏好以及用户在群组内的重要性。
[1]ORTEGA F,BOBADILLA J,HERNANDO A,etc.Incorporating group recommendations to recommender systems:alternatives and performance[J].Information Processing Management,2013,(4):895-901.
[2]梁昌勇,冷亚军,王勇胜,等.电子商务推荐系统中群体用户推荐问题研究[J].中国管理科学,2013,(3):153-158.
[3]赵兹,马江洪.信息检索中的两个数据融合方法比较[J].计算机应用,2010,(1):54-56.
[4]何军.国外群推荐聚集策略研究综述[J].图书情报工作,2013,(7):127-133.
[5]李汶华,熊晓栋,郭均鹏.一种基于案例推理和协商的群体推荐算法[J].系统工程,2013,(11):93-98.
[6]李岱峰,覃正.一种基于资源多属性分类的群组推荐模型[J].统计与决策,2010,(8):153-155.
[7]朱国玮,杨玲.基于遗传算法的群体推荐系统研究[J].情报学报,2009,(6):946-951.
[8]郭均鹏,赵梦楠.面向在线社区用户的群体推荐算法研究[J].计算机应用研究,2014,(3):696-699.
[9]郭均鹏,宁静,史志奇.基于区间型符号数据的群组推荐算法研究[J].计算机应用研究,2013,(1):67-71.
[10]张佳乐,梁吉业,庞继芳,等.基于行为和评分相似性的关联规则群推荐算法[J].计算机科学,2014,(3):36-40.
[11]朱阿敏,刘业政,韩建妙.基于优化协同过滤与加权平均的群推荐方法[J].计算机工程与应用,2016,(5):65-70.
[12]Wikipedia: http://en.wikipedia.org/wiki/Iteratively_reweighted_least_squares
[13]WANG Y H.Least square method and minimal sum of distances over non-archimedean local fields[J].中国科学院研究生院学报,2004,(4):447-450.
[14]吴胜利.一种信息检索自适应数据融合方法:103116623[P].2013-05-22.
[15]项亮.推进系统实践[M].北京:人民邮电出版社,2012:44-64.
[16]SEGARAN T.Programming collective intelligence[M].USA,O’Reilly Media,2007.
[17]徐涛,杨国庆.数据融合的概念,方法及应用[J].南京航空航天大学学报,1995,(2):258-265.
[18]MACDONALD C,OUNIS I.Searching for expertise:experiments with the voting model[J].The Computer Journal,2009,(7):729-748.
[19]孟妮娜,艾廷华,周校东.顾及排序差异的对象群邻近关系相似性计算[J].武汉大学学报(信息科学版),2013,(6):737-741.
[20]NG P.A group recommender for movies based on content similarity and popularity[J].Information Processing and Management,2012,(3):673-687.
