改进K-means模型在电力系统用户行为分析中的应用
2017-03-02崔志坤李井泉
张 蕾,崔志坤,李井泉,白 涛
(国网河北省电力公司信息通信分公司,河北 石家庄 050000)
改进K-means模型在电力系统用户行为分析中的应用
张 蕾,崔志坤,李井泉,白 涛
(国网河北省电力公司信息通信分公司,河北 石家庄 050000)
针对电力信息系统用户行为分析的问题,提出了一种基于改进K-means聚类模型的电力信息系统用户行为分析方法。该方法把基于单词向量特征的改进K-means聚类模型应用于电力信息系统用户行为分析,解决了传统K-means算法通过随机选出聚类中心质点的方式得到的聚类结果范围波动较大、迭代次数较多、耗费时间较长以及稳定性较差的问题,优化后的算法聚类内距整体缩小,迭代次数也大幅度减少,提升了主动服务信息推送的精准性。
电力信息系统; 用户行为;单词向量;改进K-means聚类模型
0 引言
随着智能电网建设的全面开展,大量信息系统在电力公司全面建成运行,各项业务数据量也呈爆炸式增长。用户大规模的访问也给系统稳定运行、合理调配资源和运维服务保障带来了巨大的压力[1]。为全面掌握用户信息系统使用情况,梳理各岗位、地市信息系统使用频率,确定各业务量爆发时间以及用户集中访问时间,从而针对性地开展系统运维服务,合理规划基础设施及网络安全保障,就需要开展用户行为分析模型的研究,根据用户集中访问时系统和资源的压力,找出瓶颈,合理进行基础建设和规划[2]。通过对用户行为分析,从“用户”和“系统”两个维度分析系统相关模块和流程等使用情况,反映企业运转存在的问题,柔性支撑企业生产管理活动[3]。
对于信息系统用户行为分析通常利用K-means聚类模型[4],但是传统K-means算法是通过随机选出聚类中心质点的方式得到的聚类结果,该模型具有范围波动较大、迭代次数较多、耗费时间较长以及稳定性较差的缺点,本文提出一种基于单词向量特征的改进K-means聚类模型的电力信息系统用户行为分析方法,该方法使得优化后算法聚类内距整体缩小,减少了迭代次数,能够提升主动服务信息推送的精准性。
1 系统模型
用户行为分析模型由三大模块组成:用户行为获取模块、基于Hadoop搭建的大数据平台模块和决策支持平台模块,如图1所示[5]。
用户行为数据获取主要有2种形式:① 日志记录较完善,通过日志解析,存入中间临时表;② 对于日志不够完善系统,采用由数据包捕获及筛选服务实时监听入库形式,然后将处理好的结果存入中间表[6]。

图1 用户分析模型结构
大数据平台主要将中间表数据进行抽取、清洗、转换、存储和分析计算。平台整体采用Hadoop的分布式架构,ETL工具采用Ketlle+Sqoop完成,数据存储集合采用NoSql(Hbase)、Hive及分布式MySQL共同完成,离线计算采用MapReduce与Pig来实现,数据分析模型借助开源类库Mahot进行构建,用于分析展现结果,存入PostgreSQL中。
决策支持部分借助开源的大数据分析展现组件(echarts)实现,对挖掘结果进行描述性分析、推断性分析等,以及实现的智能的多种预测,同时实现基于用户行为分析的业务系统服务信息的精准投送。
对于用户行为分析模型实现的关键技术主要包括2部分:① 信息系统功能访问记录的采集;② 数据处理,本文主要研究数据处理方面[7]的内容。
2 改进K-means聚类模型
2.1 传统K-means算法
K-means是一种基于距离的经典聚类算法,以距离作为判定相似性指标,2个对象的间距越近,它们的相似度就越大[8]。K-means算法认为簇是由相近的对象组成的对象集,所有该算法的最终目标是将数据划分为几个紧凑且独立的簇。
K-means的算法如下[9]:① 随机在数据中选取K个质心点;② 对数据中的所有点求到这K个质心点的距离,距离在阀值之下的,移动到质心点;③ 移动种子点到属于它的类群的中心;④ 重复第②步和第③步,直到质心点没有移动。
在K-means算法的核心数学公式为:
(1)
式中,J(c,u)表示各样本点到质心的距离平方和。算法的目标是要将J(c,u)调整到最小,如果当前J并没有达到最小值,首先固定所有类的质心uc(i),然后调整每个样本c(i)的所属类别来减小距离平方和。同样,固定样本所属类别,调整每个类的质心点也可以达到减小距离平方和的目的。
K-means作为一种简单的迭代型聚类算法,具有算法简单高效、便于处理大型数据集等优点,已经被广泛应用在诸多领域。但是,传统的K-means算法还存在一些缺点,如在聚类运算时,初始质心点为随机选取,这样聚类结果具有随机性和不确定性。而且对于用户行为分析来说,将用户行为聚类划分,还得需要对文本内容做处理,因此,需要提出一种适合本用户行为分析的K-means算法。
2.2 基于单词向量特征的K-means聚类模型
结合用户行为分析数据类型,将单词向量特征这一概念引入了算法之中,提出一种基于单词向量特征的K-means聚类模型[10]。相对于传统的K-means聚类算法,该算法以单词向量作为聚类划分的对象,通过单词向量的特征对比来确定与质心点的相似度,并且质心个数和质心点通过具体业务来确定,使得该算法的收敛时间更快速、收敛效果更稳定。
该算法的过程与传统算法相似,其计算公式如下:
① 系统信息文本相似度是本文聚类算法的关键依据,采用通过余弦函数和向量空间算法来计算:
单词加权值公式:

(2)
式中,TFmn为特征项Tn在用户关键词Cn中出现次数;IDFmn为特征项Tn关键词的倒数。2个词之间的相似度可以用其对应的向量之间的余弦之间的夹角余弦来表示,即

(3)
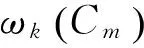
② 将得到的文本向量值带入欧式距离计算,这样可直观表达文档中句子间语义间关联性。
(4)
式中,VSm和VSn为句子的向量表达式;J为文档集合的特征数;WSmk和WSnk为句子的在K维的权值。通过上述公式便可获得向量距离矩阵。
根据业务要求,选取k个聚类质心点,该质心点便是业务关键词特征向量。
调整质心点的计算公式:
(5)
重复计算归类直到收敛。
3 算法模型测试及分析
测试数据主要从系统的ERP日志、用户操作系统行为记录和工作流转情况这3个典型数据来源抽取,分别为ERP、actionLog和workflow。3个数据集的参数如表1所示。
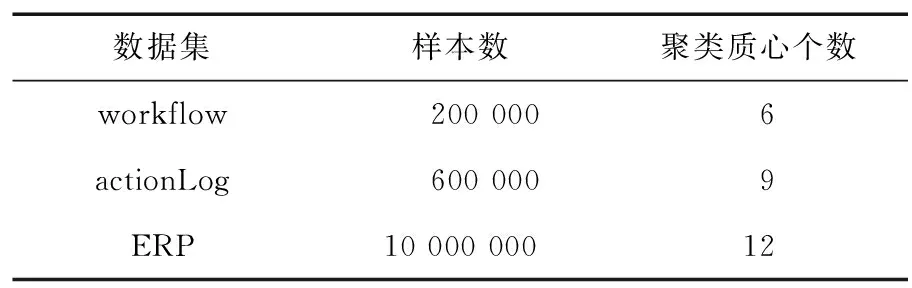
表1 测试数据集信息
分别将这3个数据集用于测试原始K-means聚类算法和基于单词向量特征K-means算法,二者参数设置的最大迭代次数均为140 000,进行测试60次,分析其平均收敛次数、平均聚类速度和行为分析准确度,其结果如表2所示。

表2 数据集性能分析
由表2可以得出以下结论:
① 基于单词向量特征K-means算法迭代次数相对于传统算法要少好几倍,减少了算法的迭代次数,加快了聚类速度;
② 基于单词向量特征K-means算法完成聚类所需时间仅为零点几秒,在数据量增大时,耗费时间增幅并不是很大,而传统的算法则需要几十秒,并且随着数据量的增大,耗费时间增涨非常快;
③ 基于单词向量特征K-means算法在对用户行为进行聚类时准确度均保持在80%之上,准确度相当高,而传统的算法分析准确度却在40%~60%之间。基于单词向量特征K-means算法在快速聚类的前提下很好地保证了聚类质量。
通过基于单词向量特征K-means算法对ERP、actionLog和workflow的聚类分析,能很好地统计出每个用户对各系统的使用情况、其所在岗位的工作重点和问题咨询方向等一系列信息,为以后的精准消息推送服务做准备。
4 结束语
本文提出了一种基于单词向量特征的K-means聚类模型,并在电力信息系统用户行为分析当中进行了应用。解决了传统K-means算法通过随机选出聚类中心质点的方式得到的聚类结果范围波动比较大、迭代次数也多、耗费时间较长和稳定性差的问题,优化后的算法使聚类内距整体缩小,迭代次数也少很多。依据内距越小、迭代次数越少、聚类质量越好这一聚类性质,可以得出改进K-means算法提高了聚类结果的稳定性和有效性,准确地对用户行为特征进行归类,提升了主动服务信息推送的精准性。
[1] 周国亮,宋亚奇,王桂兰,等.状态监测大数据存储及聚类划分研究[J].电工技术学报,2013,28(2):337-334.
[2] 华志洁.基于Hadoop云计算平台仿百度智能输入提示算法的研究与实现[J].天津科技,2015,42(12):20-23.
[3] 刘尔凯,崔振东.基于HADOOP技术实现银行历史数据线上化研究[J].金融电子化,2014(1):65-66.
[4] LI Hai-yang,HE Hong-zhou,WEN Yong-ge.Dynamic Particle Swarm Optimization and K-means Clustering Algorithm for Image Segmentation[J].Optik-International Journal for Light and Electron Optics,2015,126(24):19-22.
[5] 梁 伟.基于用户用电行为正向分析负荷预测方法的研究[D].广州:华南理工大学,2015.
[6] 顾 强.基于消除噪声的聚类算法的手机用户行为分析[J].移动通信,2014,38(7):36-39.
[7] CEPEDA-GOMEZ R,OLGAC N.Stability of Formation Control Using a Consensus Protocol under Directed Communications with Two Time Delays and Delay Scheduling[J].International Journal of Systems Science,2016,47(2):433-449.
[8] PAUL H,AMANDEEP C,ANDREW C,et al.CL-dash:Rapid Configuration and Deployment of Hadoop Clusters for Bioinformatics Research in the Cloud[J].Bioinformatics,2016,32(2):301-303.
[9] 杨天剑,张 静.基于聚类算法的通信基站能耗标杆建立与分析[J].移动通信,2015,39(18):92-96.
[10] 安建成,史德增.一种改进的K-means算法[J].电脑开发与应用,2011,24(4):39-42.
张 蕾 女,(1964—),硕士,高级工程师。主要研究方向:电子技术。
崔志坤 男,(1982—),硕士,工程师。主要研究方向:计算机技术及应用。
Application of Modified K-means Model in User Behavior Analysis of Electric Power System
ZHANG Lei,CUI Zhi-kun,LI Jing-quan,BAI Tao
(StateGridHebeiInformation&TelecommunicationBranch,ShijiazhuangHebei050000,China)
Aiming at the problem of user behavior analysis of electric power information system,a new method based on the modified K-means clustering model is proposed.It applies the modified K-means clustering model based on word vector feature to the user behavior analysis of electric power information system,and solves the problems existing in the traditional K-means algorithm,which gives the clustering results by means of randomly selected clustering center,resulting in large fluctuation range,more iteration times,long time consuming and poor stability problems.The optimized algorithm makes the intra-cluster distance shrink,also greatly reduces the iteration times,and improves the precision of active information push service.
electric power information system;user behavior;word vector;modified K-means clustering model
10.3969/j.issn.1003-3106.2017.03.03
张 蕾,崔志坤,李井泉,等.改进K-means模型在电力系统用户行为分析中的应用[J].无线电工程,2017,47(3):12-14,38.
2016-12-28
�
A
1003-3106(2017)03-0012-03
