文本挖掘中主客观因素影响性的眼追踪研究
2017-02-22郭楠
郭 楠
(同济大学 电子与信息工程学院,上海 201800)
文本挖掘中主客观因素影响性的眼追踪研究
郭 楠
(同济大学 电子与信息工程学院,上海 201800)
基于文本主题模型与眼动仪技术,从主题挖掘的客观角度与阅读兴趣的主观角度研究文本内容提取技术。传统文本挖掘多基于文本本身内容等客观因素,而主观取向的重要因素很少在文本挖掘中发挥作用。文章利用眼部追踪技术,先将眼动数据转换为阅读兴趣等主观结果形式,并利用LDA(Latent Dirichlet Allocation)模型对文本进行客观主题提取,继而对眼部数据与主题建模结果进行比较,提取分析主客观因素对文本挖掘的影响。新闻数据集的眼部追踪实验与主题提取实验显示了主客观因素对结果影响的具体差异性与相似性,未来两者结合并调控比率可作为对文本挖掘效果提升的基本方向。
文本主题建模;眼部追踪技术;文本挖掘;主题模型
0 引言
文本主题建模以LDA(Latent Dirichlet Allocation)模型[1]为代表,是近年来文本挖掘领域的一个热门研究方向。主题模型挖掘出的主题可以帮助理解文本背后隐藏的语义,也可以作为其他文本挖掘方法的输入,完成文本分类、话题检测等多方面的文本挖掘任务。然而近年来,主题建模模型的代表LDA模型的改进与扩展研究正面临方法上的瓶颈,层出不穷的模型改进算法多使用参数上调整、建模层数优化等基本方法[2],这些改进对于主题模型的效率、效果提高程度有限;另一方面,主题挖掘研究集中于研究文本本身内容等客观因素,而人类主观取向因素很少在文本挖掘方面发挥重要作用,事实上,阅读兴趣等主观因素对于文本挖掘有非常重要的参考价值,对主题模型本身也有极大的意义[3]。
因此针对文本挖掘、主题建模领域的相关研究,希望解决的相关问题就是,如何能够在现有的主题建模模型基础上,不仅对于不同内容领域的文本本身的客观因素能够统一进行分析挖掘,并且同时考虑人主观阅读规律、兴趣取向因素的影响性,使得文本中所抽取的信息与知识更有价值、更有意义。
眼动仪技术可以获得视觉信息提取过程中的生理和行为表现,它与人的心理活动有着直接或间接的关系,能够为主题提取与文本挖掘提供人主观兴趣取向信息[4]。本文通过对眼动仪捕获的用户文本阅读数据的分析和对主题提取模型LDA的研究,比较分析主观眼动数据结果与主题模型的挖掘结果,从主观规律和客观模式两方面对文本挖掘效果进行结果分析,对于推动未来文本挖掘领域建模与应用方法的进步,提高文本挖掘模型效果,具有一定的参考意义和应用价值。
1 文本主题提取算法
1.1 LDA模型
LDA模型以一种“词袋”假设,把每个文档当作组成文档的词汇分布的向量,这样,文档由多个主题的概率分布所代表,而主题则由单词的概率分布所刻画。
它对于每个文档的主题生成过程如下:如图1所示的概率模型,矩形代表重复的过程,外部矩形代表一个文档,内部矩形则代表对于每个词语选择主题的重复过程,重复次数为文档内词语的个数。α和β代表语料库级的参数,每进行一次语料库的生成都要进行采样化。θ则是文档级参数,每取一个文档则进行一次采样化,z和w则为词语级参数,对每一个文档的每一个词都进行一次采样化。
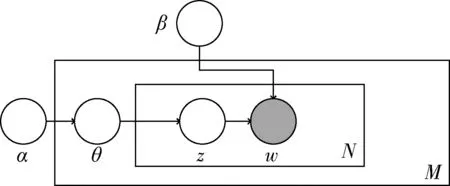
图1 LDA模型图
1.2 文本主题提取过程
每一个文件集合M在T主题上服从多项式分布,系数为θ。如果每个主题对于组成的词语而言都服从多项式分布,参数记为φ。θ和φ服从Dirichlet分布,超参分别为α与β,每一个文档d中的词语,话题z是以多项分布θ为参数从文档中进行采样的,词语w则是以多项分布φ为参数从话题z中进行采样。这个生成过程重复次数为N,是文档d中词语的总个数,形成文件D。
因此,利用该模型,有两个参数需要从数据中推断,即文档的主题分布θ和主题的词语分布φ,推断的方式是采用Gibbs抽样的方式来进行模型的参数估计。θ与φ参数则可分别代表用户文章中主题的分布情况,以及能够刻画该主题的词语的分布情况。
通过LDA模型的应用,输入的文档级数据可以转化为主题分布的形式,主题数目由事先设定好的参数N来确定,最终以用户感兴趣的程度(主题分布中所占比率大小)取前N个主题输出,以主题级数据刻画文档。而每个主题由组成的词语的分布表示,词语同样也对应于分布中所占比率的参数。因此,可以通过LDA获得用户文档中所描述的多个主题内容,并且抽取出描述该主题的词语。
2 基于眼动仪的阅读兴趣提取方法
通过眼动仪捕获的实验对象阅读文本的视觉追踪数据,其结果形式体现在用户阅读文本的轨迹和看每个词语的集中时间长度,图像化结果如图2所示,其中圆圈直径代表对该词语(位置)眼球集中时间长短,时间越长,直径越大;直线代表眼球运动轨迹。

图2 眼部追踪数据图像化形式
而眼动仪的非直观性数据形式,则以观察文本时间内每个捕获视觉点的坐标和对应时间点的形式给出。如:(x,y),t: 0908。因此对这类数据进行形式转换处理,最终转换结果应为词语及对应集中时间。
2.1 词语区域统计
眼动仪实验使用统一的图片形式,即txt格式文本转化为包括首行缩进、行距等文本分布形式均相同的图片格式。根据一致的分布形式,统计每篇文章每个词语所占区域的坐标范围(x0x1y0y1)。如式(1)~(4)所示。
(1)
(2)
(3)
(4)
其中,d0、D0为每行和每列第一个字符的初始x、y坐标值;wi、Wi分别为水平与垂直方向的第i个词的词长和词与词间距长的和;K0、Q0分别为水平和垂直方向词与词间距长。
2.2 词语集中时间计数
根据每个词语的坐标区域划分情况,对眼动数据结果文件中的坐标与对应时间点数据进行统计,落在某个词语坐标区域内的坐标对应的该词语的集中时间计数加一。全部观察时间范围内所有坐标与时间点均可通过转换关系,转为词语和词语集中时间的结果形式,即实验对象阅读文本通过眼动仪所捕获到的集中度和兴趣规律。
通过对每个词语集中时间的计数,可以得到实验对象对该文本中所有观察词语的集中时间排序结果。
3 实验结果
数据集采用BBCnews的20篇文章,实验对象为20名,每名实验对象分别阅读20篇新闻文章,并通过SMI眼动仪进行眼部数据跟踪并捕获。文本主题建模算法应用于同样数据集中。如图3所示为眼动数据实验词语的计数分布结果(横轴代表各个词语,具体内容略);图4所示为对于每个词语,所有实验对象的均值与方差变化图,可见方差基本稳定在0.1左右。
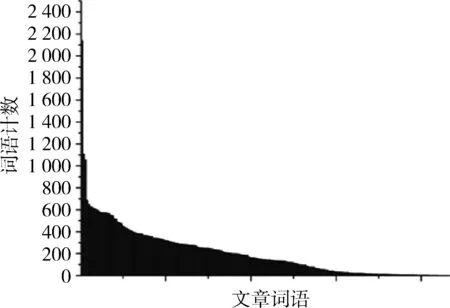
图3 单人单文本词语计数分布
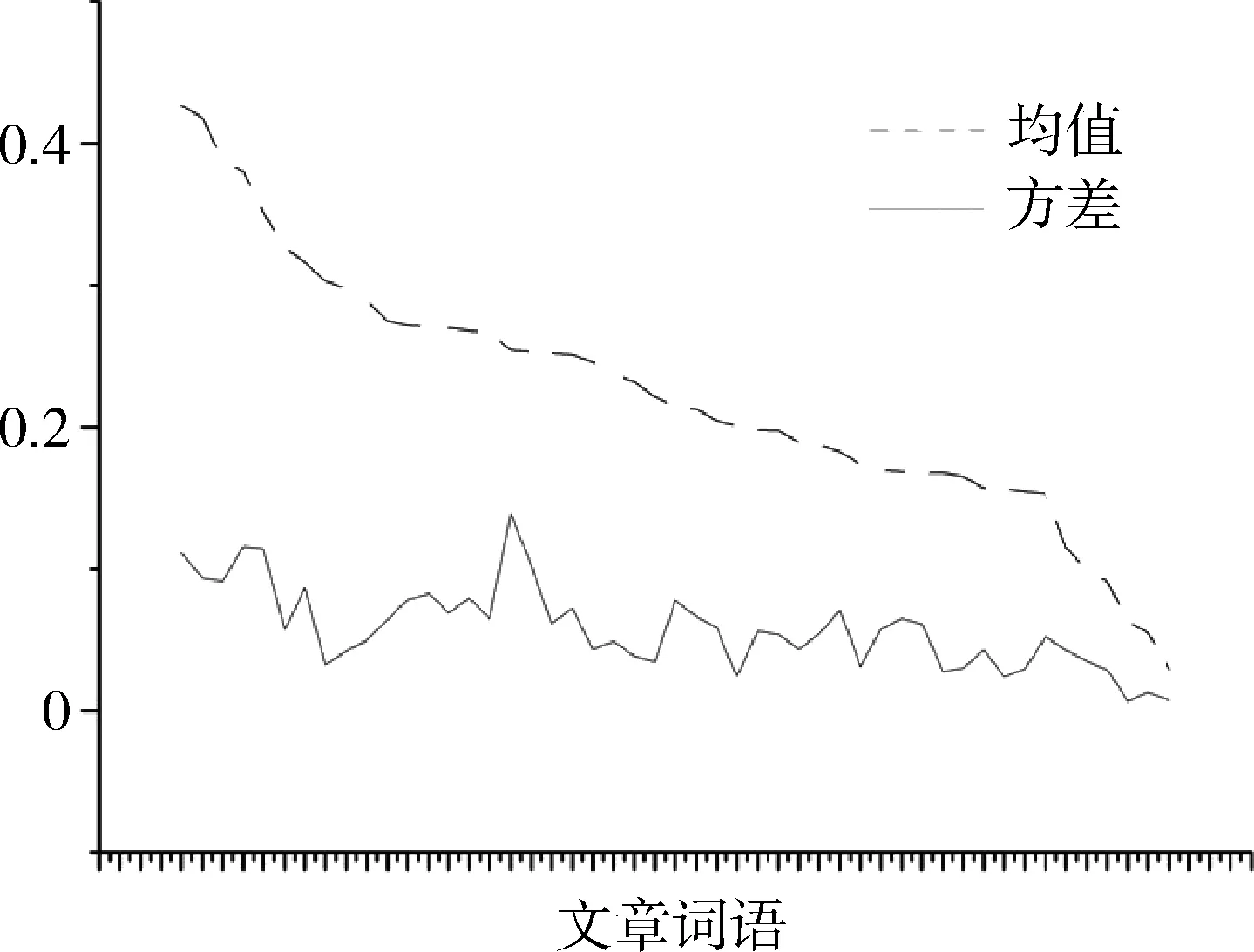
图4 某篇文章每个词语20个人的均值与方差(归一化后)
对LDA模型主题提取结果排序后与眼动数据结果排序后进行比较分析,每篇文章中同一词语的计数值比较如图5。而图6显示了具体主客观文本挖掘方法的差异性和相似性。均值的重合度以排序前30个词语为例,基本维持在0.6左右。分析比较结果,此例中,LDA模型对文本内容的客观性提取有0.6的比率与人主观兴趣取向一致,而0.4比率是基于词语频率等内容因素的偏向客观性的主题内容。
根据实验数据结果可以看出,文本主题模型对于文本的提取结果与人的兴趣行为取向存在一致性和差异性,而
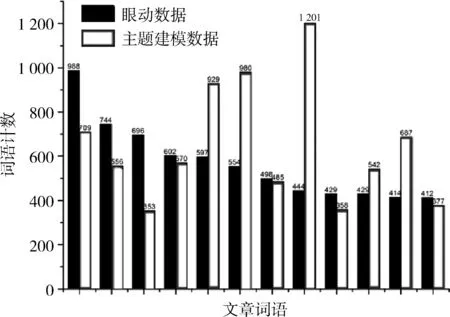
图5 单人同词LDA与眼动分布数据对比

图6 20人眼动数据均值与LDA词语结果重合度(取排序前几十)
通过调控主题提取结果所取的词语比率,结合眼动数据结果中兴趣部分的词语比率,二者结合可同时反映主题内容和阅读兴趣这两种文本挖掘因素,对于实际文本分类、文档摘要等文本挖掘应用效果会有很大提升。
4 结论
本文通过LDA模型进行文档的客观性主题抽象,利用眼动仪提取主观兴趣取向因素结果。在News数据集上的比较分析实验显示了主观因素和客观结果对文本挖掘的具体不同影响,可以为未来主客观因素相结合的文本挖掘算法提供一定参考与应用价值。
[1] BLEI D M, NG A Y,JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3):993-1022.
[2] DU L, BUNTINE W, JIN H. Modelling sequential text with an adaptive topic model[C]. Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012:535-545.
[3] MICHELSON M, MACSKASSY S A. Discovering users’ topics of interest on twitter: a first look[C]. Proceedings of the Fourth Workshop on Analytics for Noisy Unstructured Text Data,2010:73-80.
[4] DUCHOWSKI A T. Eye tracking methodology: theory and practice[M]. Springer-Verlag:2003.
An eye-tracking study on the influence of subjective and objective factors in text mining
Guo Nan
(School of Electronics and Information Engineering, Tongji University, Shanghai 201800, China)
Based on the text topic model and eye-tracking technology, this paper studies text mining from the objective topic extraction and the subjective tendency of reading interest. Traditional text mining is based on the objective factors such as the content of text itself, but the important factors of subjective orientation rarely play an important role in text mining. In this paper, eye tracking technology is used to convert eye movements into subjective data such as reading interest. LDA (Latent Dirichlet Allocation) model is used to extract information from the subjective text, and then the eye data and modeling results are evaluated by extraction, comparison and analysis of the subjective and objective factors on the impact of text mining. The eye-tracking experiment and topic modeling experiment of the BBC news dataset show the specific differences and similarities of the subjective and objective factors, and the future combination and regulation can be done as the basic direction of enhancing the effect of text mining.
text topic modeling; eye tracking technology; text mining; topic model
TP391
A
10.19358/j.issn.1674- 7720.2017.03.023
郭楠.文本挖掘中主客观因素影响性的眼追踪研究[J].微型机与应用,2017,36(3):79-81.
2016-10-02)
郭楠(1992-),女,硕士,主要研究方向:文本挖掘、数据挖掘。
