DCST:主存空间高效的缓存敏感型T-树索引研究*
2017-02-20史太齐秦小麟
史太齐,刘 亮,秦小麟
南京航空航天大学 计算机科学与技术学院,南京 210016
DCST:主存空间高效的缓存敏感型T-树索引研究*
史太齐+,刘 亮,秦小麟
南京航空航天大学 计算机科学与技术学院,南京 210016
已有主存索引通过指针消除和预取机制提升索引结构的缓存感知能力,减少缓存失效次数,但是并没有有效地利用现代计算机的CPU性能和内存空间。为了进一步提升索引结构对内存空间以及CPU性能的利用率,提出了DCST-树索引结构。该索引结构采用数据压缩的方式,对结点中的关键字进行压缩,提高索引结构对内存空间和缓存空间的利用率,减少内存访问次数,提高缓存命中率。同时,对结点进行分区,增加结点容量,提高结点扇出度,降低树的高度。实验结果表明,所提方案比现有主存索引机制具有更加高效的空间利用率和缓存感知能力,同时具有更加优秀的查询处理能力。
压缩;主存索引;缓存敏感
1 引言
随着主存容量不断增加,主存价格不断降低,计算机配备超大容量主存成为现实[1-4]。例如,许多数据库服务器都已经使用主存作为数据的主要存储介质。可以预见,在不久的将来,所有数据都可以存放在主存当中,主存数据库也因此得以快速发展。研究人员已经对主存数据库的各个方面进行了研究,索引作为提升数据库查询性能的重要方式,也是研究人员关注的重点。
随着计算机硬件的发展,主存的访问速度成为数据库新的性能瓶颈[5-6]。如图1所示,在过去的三十几年,处理器速度的提升速率大于主存速度的提升速率,长期累积下来,不均衡的发展速度造成了内存的存取速度严重滞后于处理器的计算速度,内存瓶颈导致高性能处理器难以发挥出应有的功效——内存墙效应[7-10]。因此,现代计算机处理器都配备了高速缓存[11],用于平衡处理器和主存之间的速度差异。缓存是位于处理器和主存之间的低延迟存储器,存储了处理器最近访问过的数据。缓存的读取速率比主存的读取速率快一到两个数量级。因此,提升应用程序的缓存感知能力,可以有效提高应用程序的执行效率。索引技术是数据库系统的重要组成部分,提升索引技术的缓存感知能力,对于提升数据库系统性能是十分重要的[12-16]。
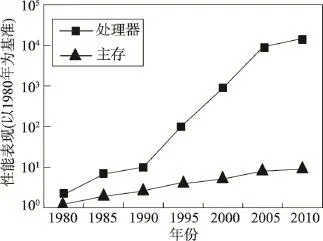
Fig.1 Comparison of process-memory performance图1 处理器和主存性能发展对比
现有的缓存感知型索引结构,都是通过调整索引的数据结构来减少缓存失配的次数,与传统的磁盘数据库索引相比有了很大的性能提升[16-20]。但是这些索引结构并没有高效利用主存空间,当索引数据较多时,会消耗大量的存储空间。高速缓存的容量是十分有限的,通常只有主存容量的几百分之一,甚至几千分之一。在进行查找时,会造成很多次缓存失配,需要频繁地访问主存。Gray提出“主存是新的磁盘”。类似的,在主存数据库中,缓存就是新形式的主存,缓存与主存之间的关系十分类似于主存与磁盘之间的关系。在传统数据库中,基于磁盘的索引结构使用压缩的方式减少磁盘的访问次数[21]。在主存数据库中,可以采用压缩的方式减少主存的访问次数。在缓存的层次上对数据压缩,虽然要消耗CPU指令,但可以显著地减少缓存失效次数,提高缓存命中率,降低主存的访问频率[3,12]。与十分有限的缓存容量相比,索引结构经常包含几百万甚至几亿的数据,此时,内存墙效应会更加显著,索引性能的发挥主要受限于主存访问次数。Rao等人[18]提出当索引结点大小接近缓存块大小时,索引树的总体性能接近最优。因此,大多数缓存感知型索引都将结点大小设置成缓存块大小,但是这样就限制了结点容量,增加了树的高度,使得从根结点到叶结点的查找过程,会产生更多的缓存失配次数。
针对以上问题,在现有的缓存感知型索引结构——CST-树(cache-sensitive T-tree)的基础上,采用压缩和分区的方法,提出了DCST-树。与CST-树相比,DCST-树主要具有以下特点:
(1)结点压缩。对CST-树结点中存储的关键字进行压缩,减少索引数据对存储空间的消耗,提高结点对缓存空间的利用率,减少主存访问次数。
(2)结点分区。把CST-树结点分成几个连续的分区,将结点中的查找操作限制在特定的分区中进行。通过分区,可以增加结点容量,提高结点的扇出度,并降低索引树的高度。
本文组织结构如下:第2章介绍相关工作;第3章研究DCST-树的结构和特点;第4章讨论DCST-树的相关算法;第5章给出实验评估和结果分析;第6章进行总结并介绍未来工作。
2 相关工作
计算机处理器从缓存中读取数据的速度快于从主存中读取的速度。因此,在主存数据库中,提升程序的缓存感知能力是非常重要的。这里首先介绍缓存行为特点,随后介绍缓存感知型主存索引的相关工作。
2.1 缓存
缓存是介于CPU和主存之间的随机存取存储器,CPU以一个或者数个缓存块的大小读写数据。缓存能够保存处理器最近访问过的数据,根据程序局部性原理[5-7,20],这些数据以后还可能会被处理器再次访问。此时,处理器可以直接从缓存中读取数据,不再需要访问主存,因此可以提升程序性能。处理器需要的数据在缓存中,称之为一次缓存命中(cache hit),数据以近似处理器的速度得到处理。如果访问的数据不在缓存中,称之为一次缓存失配(cache miss)。一次缓存失配就会造成一次主存访问。缓存只有在缓存命中的情况下才能够提升主存数据库的性能,缓存命中率主要取决于应用程序的数据存取模式。索引性能的表现也深受缓存行为的影响。提升索引的缓存感知能力,其本质就是减少缓存失配次数以及提高缓存空间利用率[3,18]。
2.2 缓存感知型索引
CSB+-树[18](cache-sensitive B+-tree)及其变种:B+-树在传统数据库中占据着重要的地位,为了提升B+-树的缓存感知能力,Rao提出了它的变种CSB+-树。CSB+-树的更新操作类似于B+-树,与B+-树不同的是,CSB+-树的每一个结点只保留了很少的指针。通过减少结点中指针的数量,相同的缓存空间可以保留更多的关键字,从而表现出更加优秀的性能。
CST-树:T-树的总体性能表现优良,自问世以来就被大部分主存数据库所采用。但是,正如前文所述,T-树的缓存感知能力不如B+树。在对T-树进行搜索时,首先比较结点中的最大值和最小值,然后再决定搜索左右子树。当T-树的一个结点被放在缓存中时,CPU访问其中的最大值和最小值,而缓存块中剩余的关键字不再被访问。由此可以看出T-树的缓存空间利用率非常低。T-树已经无法适应处理器速度和主存访问速度发展不平衡的状况。Lee等人[17]通过建立结点组(node group)和数据结点(data node),将T-树结点中的最大值和最小值提取出来和结点中剩余的关键字分别存放的方式,增强被频繁访问数据的局部性特性。如图2所示,结点组包含对应的数据结点中的最大值,并且结点组是用数组表示的二分查找树。而数据结点则是原来T-树结点中的关键字,两者分开存储。遍历CST-树时,首先遍历结点组,定位到相应的关键字之后,再到关键字对应的数据结点中搜索。在结点组中搜索时,每一个关键字都是有价值的,提高了缓存空间的利用率,减少了缓存失配次数,改善了T-树的性能。

Fig.2 CST-tree图2 CST-树
3 DCST-树
CST-树中的结点设置为缓存块大小,为的是在结点中查找时,不会造成缓存失配,但是这样会导致CST-树的高度增加,增加从根结点到叶结点查找过程中的缓存失配次数。同时,CST-树没有高效地利用主存空间,当索引数据较大时,需要很多次主存访问才能查找到需要的数据,尤其当今正步入大数据时代,这种问题更加显著。针对以上问题,DCST-树在CST-树的基础上,对CST-树中的结点进行分区,并添加结点内索引的方式,提高结点的扇出度,增大索引结点的容量,降低索引树的高度。同时,对分区内部存储的关键字进行压缩,提高结点对缓存空间的利用率,增加缓存块可以存储的关键字数量,提高缓存命中率。同时,对关键字进行压缩,可以进一步降低树的高度,减少查询过程中从根结点到叶结点查找时造成的缓存失配次数。
3.1 两级结点布局
DCST-树结点采用两层结构,是为了便于对CST-树结点进行分区和管理。通过对CST-树结点进行分区,可以将查找过程限制在特定的分区中,减少查找范围。同时,对结点进行分区可以提高结点的容量,增加结点的扇出度,降低索引树的高度。
第一层结构称之为结点内头部索引区,第二层结构是由多个分区组成的区域。将原来T-树中的结点分成几个分区,每个分区都保存原来结点中部分关键字信息。这些分区称之为结点内分区。结点内分区之间以及结点内分区中的关键字均是有序排列,保留了原有结点中关键字的顺序。图3展示了采用两层结构的DCST-树结点的结构特征。

Fig.3 DCST-tree node structure图3 DCST-树结点结构
结点内头部索引区存储的是没有压缩的关键字〈H1,H2,…,H13>,这些关键字有序排列,并且编号为k的结点内分区中的任一关键字都小于Hk,编号为k+1的分区中的任一关键字都大于或者等于Hk。假设Keyk,i代表编号为k的结点内分区中的任意关键字,Keyk+1,j代表编号为k+1的结点内分区中的任意关键字,则有Keyk,i〈Hk≤Keyk+1,j。因此,结点内头部索引区如果包含n个索引项,则结点中最多包含n+1个结点内分区。对结点内部分区,是为了限制查找的范围。在结点中查找关键字时,如果能够限定在某一个分区中,就可以减少查找数量,提高查找效率,也可以减少缓存失效次数。如果不对结点进行分区,当结点大于一个缓存块容量时,由于无法将结点一次全部装入缓存中,在结点中查找就会造成比较多的缓存失配。位于结点头部的索引区,能够快速定位到需要查找的分区,加快查找速度。在访问结点时,首先访问结点头部的索引区,定位到某一个索引项,再通过该索引项可以直接定位到与之对应的结点内部分区。图3中虚线箭头表示的指针指向与索引区中Hk对应的结点内分区,只是在DCST-树中,这些结点内部的指针不是直接存储在结点中。分区地址是结合结点基地址,通过计算得到的。结点内头部索引区和结点内分区的大小均设置为两个缓存块大小。因为在现代计算机硬件中,高速缓存在从主存空间中读取一个缓存块大小的空间时,可以紧接着从相邻的主存空间中再连续读取一个缓存块大小的空间。采用这种预取机制后,可以减少缓存失效次数,提高缓存命中率。头部索引区和结点内分区设置成两个缓存块大小后,可以通过一次主存访问将头部索引区或者结点内分区装入缓存中。在结点中查找时,除了第一次访问头部索引区或者结点内分区会造成缓存失效并导致该区域被装入缓存之外,在头部索引区或者结点内分区中进行查找时,就不会造成缓存失效。
3.2 数据压缩机制
对索引结点中的关键字进行压缩,可以减少索引结点对空间的消耗,提高索引结点对缓存空间的利用率。在缓存块层次上对索引结点进行压缩,可以增大缓存块中存储的关键字数量,提高查找过程中的缓存命中率,减少对主存的访问次数。在多数应用场景中,索引中的关键字都是数值型数据,比如4 Byte整型数据。本文以数值型数据为基础,讨论如何对关键字进行压缩存储。
如图4所示,在一个缓存块中存储的关键字,其类型是4 Byte的整型数据,缓存块大小为64 Byte。假设一个结点中的关键字个数为n(K[0,1,2,…,n-1]),如果存储完整的关键字,缓存块中最多存储16个关键字。当结点中的关键字个数超过16时,在一个结点中遍历,就会引起多次缓存失配,触发主存访问。在对整型数据进行压缩的方法中,最常用的就是差分编码(delta encoding)。对一个结点中的数据,除了最后一个数值最大的关键字外,其余的关键字并不是存储本身完整的关键字,而是存储剩余的关键字和最大关键字之间的差值。即对关键字序列K[0,1, 2,…,n-1],除了K[n-1]之外,剩下的关键字K[x]都是存储其与K[n-1]之间的差值D[x]。式(1)给出了D[x]的计算方式。
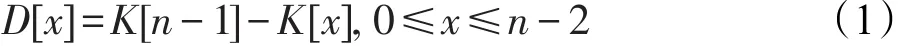

Fig.4 Keys in a cache line图4 一个缓存块中存储的关键字
式(1)中,D[x]由结点中最大关键字数值减去原始关键字数值得到,因此D[x]≥0。在计算机系统中,一个字节可以表示的正整数范围是[0,255],即28-1。同时,一个整型数值,不论数值大小,在计算机中均占用4 Byte。因此当数值范围较小时,可以通过存储字节形式,降低存储数值消耗的存储空间,提升缓存行的空间利用率。
D[x]可以用低于4 Byte的空间进行存储,D[x]所占用的最少储存空间可以通过函数space(x)进行计算。式(2)是space(x)的计算方式:

假设D[x]需要占用的最少字节数为n,则n应满足28×n≥D[x],即,经过变形可得式(2)。
由space(x)的计算公式可知,D[x]所占用的实际存储空间可能为1 Byte、2 Byte或者4 Byte,由于D[x]的长度是一个变量,没有固定大小,为了方便对经过编码的关键字进行查询,需要在结点内分区中的关键字序列前面加上索引信息。索引信息中记录了不同长度的D[x]的个数,分别表示为x、y、z。其中,x代表D[x]长度为1 Byte的差值个数,y代表D[x]长度为2 Byte的差值个数,z代表D[x]长度为4 Byte的差值个数。如图5所示,分区内部的储存结构分为两部分:第一部分是分区内头部,存储关键字编码信息。其中的3个字段分别记录了不同长度的差值个数,用来定位第二部分内容区域中相应的关键字。当需要查询时,首先计算查询关键字数值在本结点中的差值D[x]。然后查找头部索引信息,通过累加小于D[x]的差值个数,就可以根据不同差值对应的空间大小,计算出D[x]在当前结点的偏移量,并从该偏移量开始查找与D[x]相等的数值。

Fig.5 Adelta coded node key structure图5 编码后结点内部关键字序列结构
从图5中可以看出,在内容区域存储的不再是关键字原始数值本身,而是其与最大关键字数值之间的差值。如果不存储关键字50,而是存储它和最大值191之间的差值,并且两者之间的差值可以用1 Byte的空间进行表示。假设一个缓存块大小为64 Byte,一个关键字为4 Byte,则缓存块中最多存储16个关键字。但是,在采用压缩机制后,一个缓存块最多可以存储56个关键字。当结点中的关键字之间的差值都在127之内时,差值D[x]可以用一个字节表达,与存储完整关键字相比,采用压缩机制后,结点内部可以存放3.8倍的数据。即存储完整关键字比存储编码后的关键字要多消耗3.8倍的存储空间,从而造成更多的缓存失配,降低了索引的性能表现。
3.3 复杂度分析
本节将对DCST-树的插入、删除、查找的时间复杂度进行分析。假设一个数据结点中包含s个关键字,DSCT-树结点组中包含m个结点。若存储n个关键字,则DCST-树的高度为height≥logmn/s。结点组是一个数组表示的二叉树,树的高度为lbm。查找操作需要从DCST-树的根结点组遍历到叶结点组,并在相应的数据结点中查找关键字key。因此,查找操作需要花费lbm×lbn/s定位到特定的数据结点,并花费lbs用以在数据结点中搜索关键字。综上,在DCST-树中查找关键字的时间复杂度为O(lbm×logmn/s× lbs)=O(lbn)。
DCST-树的插入操作首先需要定位到关键字要插入的数据结点。如果该数据结点已经满了,就需要将最小的关键字移除并插入到该结点的左子树的数据结点中。在最坏情况下,定位到要插入的数据结点的时间为lbn,通过二分查找需耗时lbs从数据结点中删除最小关键字,同时需要lbn时间将删除的最小关键字插入到左子树数据结点中。因此,整个插入操作的时间复杂度为O(lbn)+O(lbs)+O(lbn)=O(lbn)。
DCST-树的删除操作也需要定位到包含关键字的数据结点,然后才能在数据结点中搜索关键字并删除该关键字。与插入操作类似,DCST-树的删除操作的时间复杂度也为O(lbn)+O(lbs)+O(lbn)=O(lbn)。
4 算法
4.1 查找操作
DCST-树的查找过程分为两个部分:第一部分是在结点组中进行查找。结点组是用数组表示的二叉树,存储的是原T-树中每个结点的最大关键字。在一个结点组中查找时,并不会造成缓存失配,因为结点组的大小设置成一个缓存块的大小。查找到结点组中某一个关键字时,就利用该关键字定位到相应的数据结点。数据结点中存储原来T-树中相对应结点的全部关键字,然后再在数据结点中进行搜索,直至找到查找的关键字或者返回失败,即没有找到要查找的关键字。遍历结点组的算法如算法1所示。
算法1结点组查找算法search(key,tree)


结点组是用数组表示的二叉树,里面存放的是原T-树结点中的最大关键字数值。结点组中的每一个结点都对应着一个数据结点,数据结点中存放着编码之后的关键字序列,相当于T-树的一个结点。
算法1第1行首先在第一个结点组中查找,通过将查找的关键字key与根结点组中的关键字K比较,找到相应的叶结点组,并最终定位到数据结点。算法1第3行到第7行表示的就是遍历结点组并最终定位到相应叶结点组的过程。若结点组中的关键字K大于查找关键字key,就继续遍历其左子树,并将该结点进行标记。如果K小于查找关键字key,则继续遍历该结点的右子树,并不做标记。递归查找结点组,直至遍历至叶结点组。当叶结点组遍历完成后,若标记结点不为空,则根据叶结点组中标记结点定位到相应的数据结点。
算法1第9行表示在结点组中查找完成,并通过最后一次比较得到的关键字定位到相应的数据结点。接下来开始在数据结点中查找关键字。由于数据结点采用两层结构,并且对结点进行了压缩,在数据结点中的查找过程和CST-树不一样,具体算法如算法2所示。
算法2数据结点关键字查询算法


算法2第1、第2行主要是为了定位到包含关键字key的结点内分区。第1行表示在数据结点头部索引区中查找,找到索引项Hk(Hk-1〈key〈Hk)。第2行表示通过索引Hk计算包含关键字key的结点内分区的位置。第3行计算关键字key与结点中最大关键字之间的差值de。如果de小于0,则表明查找的关键字大于数据结点中最大键值,查找的键值不在数据结点中,不需要再遍历结点,直接返回。若key小于最大键值,则首先计算差值de所占用的最小字节数space(de),同时检查数据结点头部中的x、y、z字段。如果space对应的字段中记录的数目不等于0,表明数据结点中有和de占用同样大小字节数的差值,通过头部索引信息可以计算出de在结点中的偏移量,并定位到相应的区域进行查找,如果找到,返回关键字记录,否则返回失败。如果space对应的字段,比如x,其值为0,则表明占用space大小的差值不存在,直接返回查找失败。
4.2 插入算法
插入操作与CST-树类似,数据结点中当最大关键字被取代时,需要对结点进行重构。对于给定的关键字key,首先需要定位到要插入的数据结点,然后将关键字key插入到该数据结点中。如果该数据结点没有满,则直接插入关键字。如果数据结点空间已满,则需要删除最小的关键字,然后将key插入到数据结点,并将删除的最小关键字插入到树中。具体过程如算法3所示。
算法3插入算法insert(key,tree)


算法3第1行表示在结点组中查找关键字key,在最终的叶结点组中查找完成后,根据标记可以定位到数据结点。查找过程的详细步骤如算法1所示。算法3第3行首先根据数据结点的最大关键字数值计算出key对应的差值D[x],并根据D[x]定位到相应的结点位置,然后插入数据。
算法3第11行表示将删除的最小关键字插入到子树中。如果数据结点没有对应的左子树,就需要添加一个新的数据结点,然后将关键字插入其中。当创建新的数据结点时就必须要创建一个新的结点组。而这样的操作可能会造成DCST-树的不平衡,此时就需要平衡操作来保证树左右子树的高度相对平衡。
5 实验结果与分析
本章主要对所提方案进行验证和评估,测试DCST-树和当前主流缓存感知型索引结构之间的性能对比。首先介绍实验环境及实验数据设置,然后根据实验结果进行分析。
5.1 实验环境设置
所有实验都运行在同一台机器上,处理器是Intel®CoreTMi3-2120 3.3 GHz,主存为4 GB DDR3,装载Ubuntu 12.04操作系统,该机器拥有〈256 KB,64 B, 8〉(缓存容量、缓存块大小、路数)L2缓存。
实验中,关键字和指针均设计为4 Byte无符号整型数据。索引包含的信息数据来源于某市采集的交通数据。
5.2 实验结果
本实验首先测试了DCST-树的查找性能。使用了不同数量的键数分别进行了测试,插入的键值是按照上文描述的交通数据中随机产生的整型数据。实验将DCST-树与CST-树和文献[16]提出的ART-树进行对比,测试它们在不同键数下分别进行200 000次关键字查找所消耗的时间,每次查找的关键字都是从预先生产的关键字里面随机挑选的。如图6所示,在查找性能上,DCST-树的查找性能表现最好,比CST-树和ART-树分别提升23%和11%。随着键数的增大,DCST-树的优势更加显著。
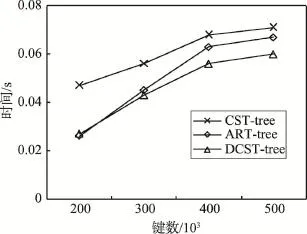
Fig.6 Performance comparison of index search图6 索引查找性能对比
随后,测试了在随机查找关键字过程中造成的缓存失配次数。如图7所示,DCST-树在查找过程中造成的缓存失配次数是最少的,并且随着记录的增加,其优势也越来越明显。DCST-树对结点中的关键字采用了压缩机制,相同存储空间可以存储更多的关键字,如前文所述,在最好的情况下可以多存储3倍的数据,从而显著提高对缓存空间的利用率。同时,单个结点数据存储量的增大,也降低了索引树的高度,使得遍历索引结点引起的缓存失配次数减少,从而提升了索引的查找性能。

Fig.7 Comparison of cache misses图7 缓存失配次数对比
图8 是压缩后的索引结构和没有压缩的索引结构之间空间消耗的对比。本次实验分别测试了不同的键数下,索引结构的空间消耗。从图中可以看出,DCST-树的空间利用率是最高的。与CST-树、ART-树相比,DCST-树对存储空间的消耗分别降低了30%和26%。

Fig.8 Comparison of space consumption of index图8 索引空间消耗对比
图9 是各个索引结构插入操作的实验对比。在本次实验中,预先建立包含100万关键字的索引树,然后对其分别插入不同数量的键值,并计算时间。从图中可以看出,CST-树和DCST-树的插入效率低于ART-树,是因为这两种树在插入的时候需要保持树的平衡而要增加额外的旋转操作。但DCST-树依然快于CST-树,并且随着键数的增加,DCST-树与ART-树之间差距逐渐变小。

Fig.9 Performance comparison of index insertion图9 索引插入性能对比
6 结束语
为了提高主存索引结构的缓存感知能力,本文在CST-树的基础上,通过调整结点结构,改进关键字存储方式,提出了DCST-树。DCST-树对结点进行分区,把结点划分成连续的存储区间,并建立结点内头部索引,以便快速定位包含查找关键字的特定分区。通过对结点划分分区,增加了结点容量,提高了结点的扇出度,降低了树的高度。同时,对于分区内的关键字进行压缩,可以减少数据消耗的存储空间,提高结点对缓存空间的利用率,减少失配次数。在实验验证阶段,从索引查询、更新等性能方面进行测试,并统计索引查询过程中造成的缓存失配次数以及索引对储存空间的消耗。实验结果表明,本文提出的DCST-树索引结构,可以高效地利用储存空间,提高了索引结构的缓存感知能力,提升了索引的查询处理能力。
随着信息化的发展,各个领域产生的数据与日俱增,索引结构的不断扩展,加剧了对储存空间的消耗。在保证查询效率的同时,降低空间消耗依然有着迫切需求。在未来的工作中,将继续研究其他的压缩策略,进一步降低对存储空间的消耗。同时,研究基于字符串的压缩机制,将DCST-树应用在更广泛的场景中。
[1]Bernstein P,Brodie M,Ceri S,et al.The asilomar report on database research[J].ACM SIGMOD Record,1998,27(4): 74-80.
[2]Ailamaki A,DeWitt D J,Hill M D,et al.DBMSs on a modern processor:where does time go?[C]//Proceedings of the 25th International Conference on Very Large Data Bases, Edinburgh,UK,Sep 7-10,1999.San Francisco,USA:Morgan Kaufmann Publishers Inc,1999:266-277.
[3]Silva J,Sklyarov V,Skliarova I.Comparison of on-chip communications in Zynq-7000 all programmable systemson-chip[J].Embedded Systems Letters,2015,7(1):31-34.
[4]Shi Yanan,Su Wenjie.Research and implementation of an inverted index cache replacement algorithm[J].Computer Technology and Development,2015,25(5):60-63.
[5]Kocberber O,Grot B,Picorel J,et al.Meet the walkers: accelerating index traversals for in-memory databases[C]// Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture,Davis,USA,Dec 7-11, 2013.New York:ACM,2013:468-479.
[6]Ding Chen,Li Pengcheng.Cache-conscious memory management[C]//Proceedings of the 2014 ACM SIGPLAN Workshop on Memory System Performance and Correctness,Edinburgh,UK,Jun 9-11,2014.NewYork:ACM,2014.
[7]Yang Tianming,Feng Dan,Chou Wenkuang,et al.A study on disk index design for large scale de-duplication storage systems[J].International Journal of Computational Science and Engineering,2015,10(1/2):171-180.
[8]Chen S,Gibbons P B,Mowry T C.Improving index performance through prefetching[J].ACM SIGMOD Record,2002, 30(2):235-246.
[9]Yang Zhaohui,Wang Lisong.Prefetching T-tree:a cacheoptimized main memory database index structure[J].Computer Science,2011,38(10):161-165.
[10]Zhou J,Cieslewicz J,Ross K A,et al.Improving database performance on simultaneous multithreading processors [C]//Proceedings of the 31st International Conference on Very Large Data Bases,Trondheim,Norway,Aug 30-Sep 2, 2005.New York:ACM,2005:49-60.
[11]Leis V,Kemper A,Neumann T.The adaptive radix tree: ARTful indexing for main-memory databases[C]//Proceedings of the 29th IEEE International Conference on Data Engineering, Brisbane,Australia,Apr 8-12,2013.Washington:IEEE Computer Society,2013:38-49.
[12]Binna R,Pacher D,Meindl T,et al.The DCB-tree:a spaceefficient delta coded cache conscious B-tree[C]//LNCS 8921: Proceedings of the 1st and 2nd International Workshops on In Memory Data Management and Analysis,IMDM 2013, Riva del Garda,Italy,Aug 26,2013,IMDM 2014,Hongzhou,China,Sep 1,2014.Switzerland:Springer International Publishing,2015:126-138.
[13]Rogers T G,O'Connor M,Aamodt T M.Cache-conscious thread scheduling for massively multithreaded processors[J].IEEE Micro,2013,33(3):78-85.
[14]Xi Fang,Mishima T,Yokota H.CARIC-DA:core affinity with a range index for cache-conscious data access in a multicore environment[C]//LNCS 8421:Proceedings of the 19th International Conference on Database Systems for Advanced Applications,Bali,Indonesia,Apr 21-24,2014.Switzerland: Springer International Publishing,2014:282-296.
[15]Kim H,Koltsidas I,Ioannou N,et al.Flash-conscious cache population for enterprise database workloads[C]//Proceedings of the 2014 International Workshop on Accelerating Data Management Systems Using Modern Processor and StorageArchitectures,Hangzhou,China,Sep 1,2014.
[16]Kwon S J.A cache-based flash translation layer for TLC-based multimedia storage devices[J].ACM Transactions on Embedded Computing Systems,2016,15(1):11.
[17]Lee I,Shim J,Lee S,et al.CST-trees:cache sensitive T-trees [C]//LNCS 4443:Advances in Databases:Concepts,Systems and Applications,Proceedings of the 12th International Conference on Database Systems for Advanced Applications,Bangkok,Thailand,Apr 9-12,2007.Berlin,Heidelberg:Springer,2007:398-409.
[18]Rao J,Ross K A.Making B+-trees cache conscious in main memory[J].ACM SIGMOD Record,2000,29(2):475-486.
[19]You Xiaorong,Cao Sheng.Storage research of small files in massive education resource[J].Computer Science,2015, 42(10):76-80.
[20]Wang Guoqing,Huang Tao,Liu Jiang,et al.A new cache policy based on sojourn time in content-centric networking [J].Chinese Journal of Computers,2015,38(3):472-482.
[21]Wu Qiuping,Liu Bo,Lin Weiwei.Adaptive replacement cache mechanism for fault tolerance in cloud storage[J]. Computer Science,2015,42(S1):332-336.
附中文参考文献:
[4]时亚南,束文杰.一种倒排索引缓存替代算法的研究与实现[J].计算机技术与发展,2015,25(5):60-63.
[9]杨朝辉,王立松.pT-树:高速缓存优化的主存数据库索引结构[J].计算机科学,2011,38(10):161-165.
[19]游小容,曹晟.海量教育资源中小文件的存储研究[J].计算机科学,2015,42(10):76-80.
[20]王国卿,黄韬,刘江,等.一种基于逗留时间的新型内容中心网络缓存策略[J].计算机学报,2015,38(3):472-482.
[21]伍秋平,刘波,林伟伟.一种面向云存储数据容错的ARC缓存淘汰机制[J].计算机科学,2015,42(S1):332-336.

SHI Taiqi was born in 1992.He is an M.S.candidate at Nanjing University of Aeronautics and Astronautics.His research interests include index in database,cache conscious and main memory database,etc.
史太齐(1992—),男,安徽淮南人,南京航空航天大学计算机科学与技术学院硕士研究生,主要研究领域为数据库查询,缓存感知,主存数据库等。

LIU Liang was born in 1985.He is a lecturer at Nanjing University of Aeronautics and Astronautics.His research interests include sensor network database and distributed database,etc.
刘亮(1985—),男,江西景德镇人,南京航空航天大学讲师、博士后,主要研究领域为传感器网络数据库,分布式数据库等。

QIN Xiaolin was born in 1953.He is a professor and Ph.D.supervisor at Nanjing University of Aeronautics and Astronautics,and the senior member of CCF.His research interests include spatial and spatio-temporal databases, data management and security in distributed environment,etc.
秦小麟(1953—),男,江苏南京人,南京航空航天大学教授、博士生导师,CCF高级会员,主要研究领域为空间与时空数据库,分布式数据管理与安全等。
DCST:Main Memory Space-Efficient Delta Coded Cache Conscious T-tree*
SHI Taiqi+,LIU Liang,QIN Xiaolin
College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016, China
+Corresponding author:E-mail:stqhappy@qq.com
Existing main-memory index structures use pointer elimination and prefetching mechanism to improve the cache consciousness of index structure and reduce the number of cache invalidation,but do not make efficient use of main-memory space and CPU performance.To make index structure utilize memory and CPU much better, this paper proposes DCST-tree.DCST-tree implements data compression to use memory and cache space more effectively.This can reduce the number of swap between memory and cache,and improve the rate of cache hit eventually. Meanwhile,node is partitioned into buckets to increase node size and improve the fan-out degree of node,such that the height of index tree can be reduced.The experimental results show that the proposed index structure has higher cache consciousness and space utilization,compared with existing index structures.
compression;main-memory index;cache consciousness
10.3778/j.issn.1673-9418.1603029
A
TP311
*The National Natural Science Foundation of China under Grant Nos.61373015,61300052,41301047(国家自然科学基金);the PriorityAcademic Development Program of Jiangsu Higher Education Institutions(江苏高校优势学科建设工程资助项目).
Received 2016-03,Accepted 2016-05.
CNKI网络优先出版:2016-05-19,http://www.cnki.net/kcms/detail/11.5602.TP.20160519.1513.004.html
SHI Taiqi,LIU Liang,QIN Xiaolin.DCST:main memory space-efficient delta coded cache conscious T-tree. Journal of Frontiers of Computer Science and Technology,2017,11(2):221-230.
