分布式水文模型子流域编码方法对比分析
2017-02-13刘佳嘉周祖昊贾仰文
刘佳嘉,周祖昊,贾仰文,王 浩
(1. 中国水利水电科学研究院流域水循环模拟与调控国家重点实验室,北京 100038;2. 水利部水资源与水生态工程技术研究中心, 北京 100038)
分布式水文模型子流域编码方法对比分析
刘佳嘉1,2,周祖昊1,2,贾仰文1,2,王 浩1,2
(1. 中国水利水电科学研究院流域水循环模拟与调控国家重点实验室,北京 100038;2. 水利部水资源与水生态工程技术研究中心, 北京 100038)
根据分布式水文模型对子流域编码的要求,对文献中河流和流域编码方法进行研究。研究发现只有5种编码方式符合要求,分别是:拓扑属性表法、二叉树编码、多叉树编码、Pfafstetter法、干支拓扑编码。在深入研究这5种编码规则的基础上,对比分析其优缺点,并以第二松花江作为实例进行子流域划分及编码。结果表明:拓扑属性表法、多叉树编码和干支拓扑编码方法在河段单一汇流、多河段汇流支持方面优于其他编码方法;在直接计算相邻上下游子流域编码方面,拓扑属性表法可以直接查找获取,二叉树编码和干支拓扑码编码方法可直接计算,Pfafstetter编码和多叉树编码均需要遍历整个编码体系进行搜索获取;在判别任意2个子流域上下游关系方面,Pfafstetter编码和干支拓扑码均优于其他3种方法。不同编码方式具有各自的优缺点,在实际应用中需要根据不同分布式水文模型具体研究内容和编码要求选择适宜的编码方式。
分布式水文模型;Pfafstetter编码;二叉树编码;多叉树编码;干支拓扑编码;子流域划分
分布式水文模型因其能够反映流域参数离散化并进行分布式模拟,正越来越受水文工作者的青睐。尤其随着GIS等技术的发展,模型应用越发容易,基于DEM的分布式水文模型已经成为当今水文学界研究的热点[1-3]。目前,分布式水文模型流域离散方法应用广泛的主要有栅格和自然子流域2种[2,4]。随着对大、中尺度流域模拟需求的出现,基于子流域划分的水文模型得到广泛应用[5-8]。其原因在于,使用栅格进行大流域离散化,如果栅格精度较高,则容易造成数据维度灾,而如果栅格精度较低,则容易造成地形、河流描述失真。采用子流域划分则能够保证子流域之间的上下游关系,子流域内部可以采用高精度DEM进行描述,而且子流域内的模拟计算也可以引进传统水文模型进行运算。在大流域模拟中,采用子流域划分方式能够保证一定模拟精度的同时缩短模型运行时间。
分布式水文模型的子流域划分主要包括2个部分:子流域范围确定和子流域编码。在确定子流域范围时,一般以流域内河段为基础,将流入相同河段的区域归为同一个子流域,即子流域和流域内的河段是一一对应的。子流域范围确定后,需要对每个子流域分配一个标识(数字或字符),用于在水文模拟以及结果展示时,进行指示和定位。根据分布式水文模型应用要求,子流域编码方法需要具有以下3个基本要求[9-11]:(a)编码对象是河网中的各个河段而不是整条河流;(b)每个编码唯一对应一个子流域,从而可以通过编码直接进行定位;(c)编码能够反映河段之间的拓扑关系,从而可以通过编码判别2个子流域之间的上下游关系。此外,随着分布式水文模型的应用及发展,对子流域编码方法提出了更高的要求[8,11-14]:(a)能够对具有多个出口的流域进行编码;(b)拥有足够的编码容量用于大尺度流域划分;(c)能够通过编码直接计算相邻上下游编码,而非低效的遍历搜索;(d)能够处理多种河段汇流情景,而非单一的二叉树划分(例如,加密无分叉河段、考虑水库水文站划分、考虑3个以上河段汇入同一河段等)。
目前,文献中河网编码方法很多,例如爱尔兰测站编码[15]、芬兰河流编码[15]、Strahler法[16]、Shreve法[17]、Horton法[18]、拓扑属性表法[5, 19]、Pfafstetter法[12, 20-22]、德国LAWA编码[23]、二叉树编码[10, 24-25]、多叉树编码[13]、干支拓扑编码[11, 26]等。然而,大部分都不适合用作子流域编码,即相关编码方式并不能全部满足子流域编码的3个基本特征。研究表明,只有拓扑属性表法、二叉树编码、多叉树编码、Pfafstetter法、干支拓扑编码这5种方法能够完全满足上述3个基本特征以及部分满足4个高级要求。本文主要在介绍这5种子流域编码方法的基础上,对其进行对比分析,探索各方法的优缺点,为水文模型开发者提供参考。
1 子流域编码方法原理介绍
拓扑属性表法是最简单的子流域编码方法。该方法对每个子流域随机或者根据一定的算法设置一个唯一的自然数编码,然后根据河网上下游关系,建立拓扑属性,用于水文模型河网汇流演算。该方法又可细分为非拓扑序列编码和拓扑序列编码,两者的区别在于后者能够确保每一个子流域的所有上游子流域编号均小于自身编号,因此在进行河网汇流演算时,只需根据自然数顺序依次进行模拟计算,而不需要递归检测上游是否已经完成汇流演算。在实际应用中,研究人员往往对非拓扑序列编码另外建立一个演算顺序[27-30],从而等同于拓扑序列编码。因此本文中拓扑属性表法特指拓扑序列编码,编码示例见图1(a)。在应用时需要额外提供拓扑关系属性表,标识各子流域的上下游子流域编码信息,例如,需要提供属性表说明子流域6的上游子流域是2、3、4、5,下游子流域为8。
二叉树编码[24]是一种基于二叉树理论,并以二元形式表示的河网编码方法。该方法将整个河网概化成以出口河段为根节点的二叉树结构,以(Ln,Vn)二元形式进行编码,其中Ln表示该节点在二叉树中所处的层数(即到流域出口的河段数),Vn表示该节点在对应层内序号(对同一条支流而言,离干流越远,该值呈2n指数级增长),则其下游河段编码为(Ln-1,Vn2)(其中“”表示整除),其上游干流编码为(Ln+1, 2Vn),上游支流编码为(Ln+1, 2Vn+1)。因此该方法能够通过编码本身直接计算上下游子流域编码,而无需查找拓扑关系表。王皓等[25]通过引入虚拟节点有效地解决了该方法无法处理只有1个子节点或多于2个子节点的问题。王皓等[25]和Li等[10]通过采用分区的思想将纵深发育很大的子流域裁剪出来独立编码,并通过分区间的拓扑关系进行耦合,用(Zn,Ln,Vn)三元方式进行编码解决了Vn指数级增长引起的整数溢出问题。二元(Ln,Vn)编码示例如图1(b)所示。
多叉树编码[13]是基于多叉树理论的一种能够解决多支流汇流情景的编码方法。该方法将整个河网概化成以流域出口为根节点的多叉树结构,以(L,N,PN)三元形式进行编码,其中L表示该节点在多叉树中的层数(即到流域出口的河段数),N表示该节点在对应层中从左到右的自然数序号(从0开始,按顺序递增),PN表示该节点的父节点的N值,则其下游编码为(L-1,PN, ?),上游编码为(L+1, ?,N)(其中?表示未知编码,下游只有1个,上游可能多个)。因此,该方法无法直接通过编码自身推算相邻上下游子流域完整编码,而需要通过遍历整个编码体系查找符合要求的编码,编码示例如图1(c)所示。
Pfafstetter编码[21]将集水面积最大的4条一级支流,从下游到上游依次编码2、4、6和8,将其分割得到的5个干流河段从下而上依次编码1、3、5、7和9。对划分所得的每个河段按相同的规则重复执行,直至给定的编码级别或者无法细分,其中后续划分的河段编码拥有上一级别河段编码,例如在支流6上进行二级编码,则其河段编码应该是6X形式(X表示当前级别编码)。原始的Pfafstetter规则要求河道必须有4条以上支流,否则不能继续进行细分编码,不适用于分布式水文模型。因此,罗翔宇等[22]、Fürst等[20]、雷晓辉等[12, 31]对该规则进行改进,使得方法能够对少于4个支流情况进行编码。由于各河段具有不同的编码级别,因此不能通过Pfafstetter编码直接计算相邻上下游子流域编码。本文所指Pfafstetter编码是改进后的编码规则,编码示例见图1(d)。
干支拓扑编码[11, 26]是一种类Pfafstetter编码体系。该方法采用{O, S, B : U}四元形式编码,其中O是水系序列码,用以标识相互独立的水系;S是干流流程码,表示被编码河段到流域出口所流经的各级河道中河段个数,编码对象是各个河段;B是支流流程码,表示被编码河段到流域出口所流经的各级别河道的支流标识,编码对象是整个河流,用于区别流入相同河段的支流;U是上游入流数,表示被编码河段上游流入河段数。其中,OSB组合称之为主码,能够唯一标识流域中各河段;而U则是辅码,用于扩展编码功能。上游子流域编码的主码是在其直接流入的下游子流域编码基础上拓展得出的,因此,方法能够反映河段上下游拓扑关系。编码示例见图1(e)(由于只有一个水系,省略了O编码)。

图1 不同编码方法编码示例Fig. 1 Examples of coding of different coding methods
2 不同子流域编码方法优缺点比较
根据各子流域编码规则以及分布式水文模型应用要求,笔者分别从编码特性、编码能力、拓扑关系分析能力3个方面对现有5种子流域编码方法优缺点进行比较分析,对比分析结果见表1。
表1 不同编码方法优缺点比较
Table 1 Comparison of advantages and disadvantages of different coding methods

编码方法编码特性编码能力拓扑关系分析能力拓扑属性表法①自然数顺序编码方式,编码载体是数字;②编码本身不能够反映河网拓扑关系,需要查找拓扑属性表反映子流域之间上下游拓扑关系;③能对任何水系编码,需要精细河段信息,编码级别不是河流级别①支持单一河段汇流编码;支持多河段汇流编码;②无损编码,无冗余子流域产生;③编码无容量限制;④编码无特殊要求,拓扑稳定性最高,编码更新容易①不能直接计算相邻上下游子流域编码,需要通过查找拓扑属性表;②无法直接判别任意2个子流域编码之间的上下游关系,需要遍历整个拓扑属性表获得相关关系Pfafstetter编码①继承式编码方式,编码载体是数字字符;②编码本身能够反映河网拓扑关系,支流编码拥有所流入干流河段所有编码;③仅对树状水系编码,不需要精细河段信息,编码级别不是河流级别①支持单一河段汇流编码;支持最多3河段汇流编码;②有损编码;无冗余子流域产生;③编码无容量限制;④编码采用最大4支流确定法,拓扑稳定性不高,不容易更新,往往需要重新编码①不能直接计算相邻上下游子流域编码,需要通过搜索整个编码体系获取;②通过检查子流域编码不同级别编码之间的包含继承、大小比较等关系判别任意2个子流域之间的上下游关系二叉树编码①内涵式编码方式,编码载体是数字;②编码本身不能够反映河网拓扑关系,主要通过编码之间的倍比关系反映拓扑关系;③仅对树状水系编码,需要精细河段信息,编码级别不是河流级别①支持单一河段汇流编码;可支持多河段汇流编码,但会引入虚拟节点等冗余子流域信息,损失原有快捷计算优势;②有损编码;引入虚拟河段实现无损编码,但此时会产生冗余小子流域信息;③存在整数数据溢出问题导致编码有容量限制,但可通过分区编码实现无容量限制;④编码无特殊要求,拓扑稳定性比较高,编码更新相对复杂,特殊情况需要重新编码①能直接计算相邻上下游子流域编码,但需检查上游是否存在;②通过检查子流域编码之间的倍比关系判别任意2个子流域之间的上下游关系,如果位于不同的编码分区则需要额外判别分区之间的关系多叉树编码①半内涵半继承式编码方式,载体是数字;②编码本身仅部分反映子流域拓扑关系,需要通过sql语句遍历所有编码体现完整的拓扑关系;③仅对树状水系编码,需要精细河段信息,编码级别不是河流级别①支持单一河段汇流编码;支持多河段汇流编码;②无损编码;无冗余小子流域产生;③编码无容量限制;④编码无特殊要求,拓扑稳定性高,编码更新相对容易①不能直接计算相邻上游子流域编码,需要通过sql搜索整个编码体系获取,可通过直接定位下游编码存储位置,获取完整编码;②无法直接判别任意2个子流域编码之间的上下游关系,需要通过sql搜索整个编码体系获得相关关系干支拓扑编码①继承式编码方式,编码载体是数字字符;②编码本身能够反映河网拓扑关系,支流编码拥有所流入干流河段所有编码;③仅对树状水系编码,需要精细河段信息,编码级别是河流级别①支持单一河段汇流编码;支持多河段汇流编码;②无损编码;无冗余小子流域产生;③编码无容量限制;④编码无特殊要求,拓扑稳定性高,编码更新相对容易①能直接计算相邻上下游子流域编码;②通过检查子流域编码不同级别编码之间的包含继承、大小比较等关系判别任意两个子流域之间的上下游关系
2.1 编码特性
拓扑属性表法属于自然数编码方式,编码载体是数字,编码本身不能反映子流域拓扑关系,需要通过查找拓扑属性表获得。Pfafstetter编码和干支拓扑编码属于继承式编码方式,编码载体是数字字符(也可扩展为字母等其他可比较大小的字符集),编码本身能够反映子流域拓扑关系,支流的编码拥有其所流入的干流河段的所有编码。二叉树编码属于内涵式编码,编码载体是数字,主要通过编码之间的倍比关系反映子流域拓扑关系。多叉树编码属于半内涵半继承式编码,编码载体是数字,编码本身仅部分反映子流域拓扑关系,需要通过sql语句遍历所有编码以反映完整的拓扑关系。
拓扑属性表法可对任何水系进行编码;其他4类编码方法只能对树状水系进行编码(即每个子流域最多只有一个下游)。由于其他4类编码能够通过一定的运算转换成拓扑序列编码,因此对于树状水系而言,后面4种编码方法均优于拓扑属性表法。Pfafstetter编码采用从河流到河段的逐步细分的编码方式,即先对某条河段进行编码,然后对该河段再进行细化编码,换言之,编码时不需要知道过于精细的河网河段划分;其他4种方法均采用逐河段编码的方式进行,即在编码时需要知道完整的河网河段划分信息。
2.2 编码能力
根据不同编码规则以及图1实例可以发现,所有5种编码方法都支持单一河段、二岔河段汇流编码,但对3个以上河段汇流情况编码支持程度不一样。Pfafstetter编码最多支持3个河段汇流情况,是一种有损编码方案,即在特殊情况下,无法对某些河段进行编码。对二叉树编码而言,原始编码规则是有损的,不能对多于2个汇流河段进行编码,但可通过引入虚拟河段的方式实现无损编码,此时会产生冗余编码信息;其他3种方法则均能够支持单一、多个河段汇流编码,是无损编码方案。由于二叉树编码中Vn根据河网拓扑结构会呈现2n指数级增长,因此很容易就超出计算机整数范围(264-1),从而导致数据溢出,限制了编码容量大小;虽然改进二叉树采用分区编码的方法解决了编码容量限制问题,但增加了编码复杂度,且破坏了上下游编码快捷计算的优势。
当流域水系拓扑结构发生变化(例如,增加删除某条河流、增加删除河段分割节点等),同一个河段编码在变化前和变化后差异较大,则说明编码的拓扑稳定性低;反之,如果只有受变动的局部区域编码不同,而其他区域编码变化前后保持一致,则说明编码拓扑稳定性高。对Pfafstetter编码而言,如果只是对原有河段进行再细分,拓扑稳定性高,编码更新容易;但是,如果对原河网进行河流增加、减少操作,则拓扑稳定性差,编码更新比较复杂,往往需要对整个流域进行重新编码。这主要是因为Pfafstetter编码采用最大集水面积的4条支流作为划分依据,增减河流之后,最大集水面积4支流可能会被改变,进而需要重新编码。对原始的二叉树编码规则而言,拓扑稳定性高,编码更新相对容易,但流域内河网复杂度不宜过高;而对改进的二叉树编码规则而言,由于虚拟河段和分区属性表的引入,使得编码拓扑稳定性降低,编码更新复杂度增加,特殊情况需要对整个流域重新编码。对多叉树编码和干支拓扑编码而言,编码拓扑稳定性高,编码更新相对容易。
2.3 拓扑关系分析能力
首先是相邻上下游编码计算能力,即通过编码获取其相邻的流入子流域(或流出子流域)的编码。对于拓扑属性表法而言,无法通过编码自身进行分析,而需要查找拓扑属性表才能知道其相邻上下游编码。对于Pfafstetter编码而言,因为不知道各河段的编码级别,因此不能够计算其相邻上下游编码,需要对整个编码体系进行比较分析从而得出。例如,河段“3”的上游可能是“5”,也可能是“51”、“511”等,无法唯一确认。对于原始二叉树而言,可以通过倍比关系由原始编码直接计算相邻上下游编码(见第1节二叉树规则介绍),但计算所得上游可能是不存在的(叶节点没有上游)。对于改进二叉树而言,在采用倍比关系计算之前需要检测其上下游是否位于相同的编码分区,如果位于不同的分区则需要通过查分区属性表确定,反之则通过倍比关系计算。此外,由于引入虚拟节点技术,还需检测计算所得上下游是否是虚拟节点,如果是虚拟节点,则还需继续计算。虽然改进二叉树方法拓展了原始二叉树编码的编码能力,但是却破坏了原有快捷计算相邻上下游编码的能力,使得相邻上下游编码计算变的十分复杂。对于多叉树编码而言,无法直接计算上游子流域编码,需要通过sql语言遍历整个编码体系获取;但可以通过自身编码计算得出下游编码存储地址,从而获取完整编码。对于干支拓扑编码而言,可以直接计算相邻上下游编码的主码。
其次是上下游关系判别能力,即通过任意2个子流域编码判别其是否具有上下游关系。对于Pfafstetter编码和干支拓扑编码而言,由于采用继承式编码体系,可以直接判别两者之间的上下游关系。对于拓扑属性表法而言,无法直接判别上下游关系,需要通过遍历整个拓扑属性表进行递归查询。对于原始二叉树编码而言,可通过倍比关系进行判别。而对改进二叉树编码而言,如果2个编码位于相同的编码分区可直接通过倍比关系直接判断,如果位于不同的分区,则需要通过查询分区属性表判别。对于多叉树编码而言,无法直接判别上下游关系,需要通过sql语言搜索整个编码体系进行判别。
3 实例编码对比
以松花江流域第二松花江为例进行流域划分以及编码应用对比。第二松花江子流域模拟河网和子流域划分结果如图2所示,并对各子流域划分结果分别采用上述5种编码方式,所得结果如图3~7所示。从图中可以看出,5种编码方式都能够对子流域进行有效编码。由于子流域数量较少以及拓扑结果相对简单,因此没有出现前面所提到的各方法的缺点。图3所对应的拓扑属性表如表2所示。
4 结 语
本文详细介绍了现有的5种适用于子流域编码规则,并在此基础上从编码特性、编码能力、拓扑关系分析能力三方面对不同编码方法之间的优缺点进行了比较。结果表明,多叉树编码和干支拓扑编码方法在河段单一汇流、多河段汇流支持方面优于其他编码方法。在直接计算相邻上下游子流域编码方面,拓扑属性表法可以直接查找获取,二叉树编码和干支拓扑码编码方法可直接计算,Pfafstetter编码和多叉树编码均需要遍历整个编码体系进行搜索获取。在判别任意2个子流域上下游关系方面,Pfafstetter编码和干支拓扑码均优于其他3种方法。5种编码方法具有各自的优缺点,在模型构建开发过程中,需要根据模型具体的研究内容和编码要求,选择适宜的编码方式,从而提高模型效率。根据本文研究,如果子流域划分数量较少以及拓扑结果相对简单,则5种方法均能够对流域进行编码,但考虑到后期拓扑关系计算,推荐采用多叉树编码和干支拓扑编码方式进行子流域划分和编码。

图2 流域模拟河网及子流域划分Fig.2 Simulated river network and subwatershed division

图3 拓扑属性表法编码结果Fig.3 Subdivision results of topological property table coding method
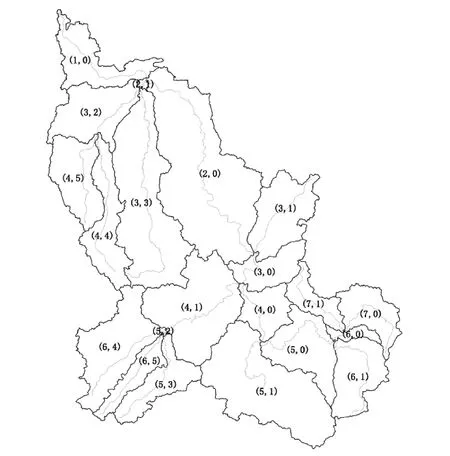
图4 二叉树编码结果Fig.4 Subdivision results of binary-tree coding method

图5 多叉树编码结果Fig.5 Subdivision results of multi-tree coding method

子流域号下游上游1上游2子流域号下游上游1上游2子流域号下游上游1上游2102387910151300211819980016140032451080017140043001170018200536131260019220216571213514152019007681114131617211900

图6 Pfafstetter编码结果Fig.6 Subdivision results of Pfafstetter coding method

图7 干支拓扑码编码结果Fig.7 Subdivision results of stem-branch topological coding method
[ 1 ] 贾仰文, 王浩, 倪广恒. 分布式流域水文模型原理与实践[M]. 北京: 中国水利水电出版社, 2005.
[ 2 ] 王中根, 刘昌明, 左其亭,等. 基于DEM的分布式水文模型构建方法[J]. 地理科学进展, 2002, 21(5):430-439. (WANG Zhonggen, LIU Changming, ZUO Qiting, et al. Methods of constructing distributed hydrological model based on DEM [J]. Progress in Geography, 2002, 21(5): 430-439.(in Chinese))
[ 3 ] ABBOTT M B, REFSGAARD J C. Distributed hydrological modeling [M]. Kluwer Academic Publishers, 1996.
[ 4 ] JIA Y, WANG H, ZHOU Z, et al. Development of the WEP-L distributed hydrological model and dynamic assessment of water resources in the Yellow River Basin [J]. Journal of Hydrology, 2006, 331: 606-629.
[ 5 ] 陆垂裕, 秦大庸, 张俊娥, 等. 面向对象模块化的分布式水文模型MODELCYCLE I:模型原理与开发篇[J]. 水利学报, 2012, 43(10): 1135-1145. (LU Chuiyu, QIN Dayong, ZHANG Jun’e, et al. MODELCYCLE-an object oriented modularized hydrological model I: theory and development [J].Journal of Hydraulic Engineering,2012, 43(10): 1135-1145.(in Chinese))
[ 6 ] 杨大文, 李翀, 倪广恒,等. 分布式水文模型在黄河流域的应用[J]. 地理学报, 2004, 59(1): 143-154. (YANG Dawen, LI Chong, NI Guangheng, et al. Application of a distributed hydrological model to the Yellow River basin [J]. Acta Geographica Sinica, 2004, 59(1): 143-154.(in Chinese))
[ 7 ] 贾仰文, 王浩, 周祖昊, 等. 海河流域二元水循环模型开发及其应用:I.模型开发与验证[J]. 水科学进展, 2010, 21(1): 1-8. (JIA Yangwen, WANG Hao, ZHOU Zuhao, et al. Development and application of dualistic water cycle model in Haihe River Basin: I. model development and validation [J]. Advances in Water Science, 2010, 21(1): 1-8.(in Chinese))
[ 8 ] 张峰, 廖卫红, 雷晓辉,等. 分布式水文模型子流域划分方法[J]. 南水北调与水利科技, 2011, 9(3): 101-105. (ZHANG Feng, LIAO Weihong, LEI Xiaohui, et al. A review on subbasin delineation methods for distributed hydrological models [J]. South to North Water Diversion and Water Science & Technology, 2011, 9(3): 101-105.(in Chinese))
[ 9 ] 李满, 王山东, 杨松,等. 基于DEM的数字流域河网编码方法研究[J]. 计算机与数字工程, 2014, 42(2): 210-212. (LI Man, WANG Shandong, YANG Song, et al. Drainage network codification method based on DEM [J]. Computer & Digital Engineering, 2014, 42(2): 210-212.(in Chinese))
[10] LI T, WANG G, CHEN J. A modified binary tree codification of drainage networks to support complex hydrological models [J]. Computers & Geosciences, 2010, 36(11): 1427-1435.
[11] 刘佳嘉, 周祖昊, 贾仰文, 等. 基于DEM河网干支拓扑关系的子流域编码规则[J]. 河海大学学报(自然科学版), 2013, 41(4): 288-293. (LIU Jiajia, ZHOU Zuhao, JIA Yangwen, et al. A rule for delineation and codification of subwatersheds based on stem-branch topological relationship of DEM digital river network [J]. Journal of Hohai University(Natural Sciences), 2013, 41(4): 288-293.(in Chinese))
[12] LEI X H, TIAN Y Z, JIANG Y, et al. General catchment delineation method and its application into the Middle Route Project of China’s South-to-North Water Diversion [J]. HKIE Transactions, 2010, 17(2): 27-33.
[13] WANG H, FU X, WANG G. Multi-tree coding method (MCM) for drainage networks supporting high-efficient search [J]. Computers & Geosciences, 2013, 52: 300-306.
[14] 雷晓辉, 王海潮, 田雨,等. 南水北调中线受水区分布式水文模型子流域划分研究[J]. 南水北调与水利科技, 2009, 7(3): 10-13. (LEI Xiaohui, WANG Haichao, TIAN Yu, et al. Subbasin delineation for the service areas of South-to-North water diversion project [J]. South to North Water Diversion and Water Science & Technology, 2009, 7(3): 10-13.(in Chinese))[15] 李建新, 曹国荣, 余向勇. 国内外河流编码技术评述[J]. 水利信息化, 2010(2): 25-30. (LI Jianxin, CAO Guorong, YU Xiangyong. Overview of river coding technology at home and abroad [J]. Water Resources Informatization, 2010(2): 25-30.(in Chinese))[16] STRAHLER A N. Quantitative analysis of watershed geomorphology [J]. Transactions, American Geophysical Union, 1957, 38(6): 913-920.
[17] SHREVE R. Infinite topologically random channel networks [J]. Journal of Geology, 1967, 75: 178-186.
[18] HORTON R. Erosional development of streams and their drainage basins: hydrophysical approach to quantitative morphology [J]. Geological Society of America Bulletin, 1945, 56: 275-370.
[19] ARNOLD J, SRINIVASAN R, MUTTIAH R, et al. Large area hydrologic modeling and assessment part I: model development [J]. Journal of the American Water Resources Association, 1998, 34(1): 73-89.
[20] FÜRST J, HORHAN T. Coding of watershed and river hierarchy to support GIS-based hydrological analyses at different scales [J]. Computers & Geosciences, 2009, 35(3): 688-696.
[21] VERDIN K, VERDIN J. A topological system for delineation and codification of the Earth’s river basins [J]. Journal of Hydrology, 1999, 218(1/2): 1-12.
[22] 罗翔宇, 贾仰文, 王建华,等. 基于DEM与实测河网的流域编码方法[J]. 水科学进展, 2006, 17(3): 259-264. (LUO Xiangyu, JIA Yangwen, WANG Jianhua, et al. Method for delineation and codification of a large basin based on DEM and surveyed river network [J]. Advances in Water Science, 2006, 17(3): 259-264.(in Chinese))
[23] BRILLY M, VIDMAR A. Watershed coding of large river basins [C] // IAHS. Modelling and management of sustainable basin-scale water resource systems. Boulder: IAHS, 1995.
[24] 李铁键, 王光谦, 刘家宏. 数字流域模型的河网编码方法[J]. 水科学进展, 2006, 17(5): 658-664. (LI Tiejian, WANG Guangqian, LIU Jiahong. Drainage network codification method for digital watershed model [J]. Advances in Water Science, 2006, 17(5): 658-664.(in Chinese))
[25] 王皓, 李铁键, 高洁,等. 大尺度流域河网二叉树编码方法[J]. 河海大学学报(自然科学版), 2009, 37(5): 499-504. (WANG Hao, LI Tiejian, GAO Jie, et al. Binary-tree coding for drainage network of large-scale basins [J]. Journal of Hohai University(Natural Sciences), 2009, 37(5): 499-504.(in Chinese))
[26] LIU J, ZHOU Z, JIA Y, et al. A stem-branch topological codification for watershed subdivision and identification to support distributed hydrological modelling at large river basins [J]. Hydrological Processes, 2014, 28(4): 2074-2081.
[27] 叶爱中, 夏军, 王纲胜, 等. 基于数字高程模型的河网提取及子流域生成[J]. 水利学报, 2005, 36(5): 1-9. (YE Aizhong, XIA Jun, WANG Gangsheng, et al. Drainage network extraction and subcatchment delineation based on digital elevation model [J]. Journal of Hydraulic Engineering,2005, 36(5): 1-9.(in Chinese))
[28] 李大鸣, 徐好梅, 傅长锋,等. 子牙河流域河网编码与流域划分方法的研究[J]. 中国农村水利水电, 2012(7): 70-76. (LI Daming, XU Haomei, FU Changfeng, et al. Research on the method of drainage network coding and watershed subdivision of Ziyahe Watershed [J]. China Rural Water and Hydropower, 2012(7): 70-76.(in Chinese))
[29] 任立良, 刘新仁. 数字高程模型在流域水系拓扑结构计算中的应用[J]. 水科学进展, 1999, 10(2): 129-134. (REN Liliang, LIU Xinren. Application of digital elevation model to topological evaluation of drainage system [J]. Advances in Water Science, 1999, 10(2): 129-134.(in Chinese))
[30] 舒栋才, 程根伟. 基于多叉树的遍历算法在数字水系拓扑关系计算中的应用[J]. 长江流域资源与环境, 2006, 15(6): 733-739. (SHU Dongcai, CHENG Genwei. Traversal algorithm based on multi-subtrees and its application on the topological relationship in digital drainage network [J]. Resources and Environment in the Yangtze Basin, 2006, 15(6): 733-739.(in Chinese))
[31] 雷晓辉, 周祖昊, 丁相毅, 等. 分布式水文模型子流域划分中界河、海岸线的处理研究[J]. 水文, 2009, 29(6): 1-5.(LEI Xiaohui, ZHOU Zuhao, DING Xiangyi, et al. How to process boundary rivers and coastline in watershed subdivision of distributed hydrological model [J]. Journal of China Hydrology, 2009, 29(6): 1-5.(in Chinese))
Comparison analysis of subwatershed codification methods for distributed hydrological model
LIU Jiajia1, 2, ZHOU Zuhao1, 2, JIA Yangwen1, 2, WANG Hao1, 2
(1.StateKeyLaboratoryofSimulationandRegulationofWaterCycleinRiverBasin,ChinaInstituteofWaterResourcesandHydropowerResearch(IWHR),Beijing100038,China;2.EngineeringandTechnologyResearchCenterforWaterResourcesandHydroecologyoftheMinistryofWaterResources,Beijing100038,China)
According to the requirements of subwatershed codification for distributed hydrological models, river and watershed codification methods described in literature were studied. It is found that only five coding methods can meet the requirements of distributed hydrological models: the topological property table coding method (TPTCM), binary-tree coding method (BCM), multi-tree coding method (MCM), Pfafstetter coding method (PCM), and stem-branch topological coding method (SBTOPO). The advantages and the disadvantages of the five methods were examined based on analysis of their coding rules. The second Songhua River was selected as the study area for subwatershed division and codification. The results show that the TPTCM, MCM, and SBTOPO are superior to the other two methods in one-way and multi-way confluence situations. The TPTCM can directly find and obtain the codes of adjacent inflow and outflow subwatersheds, and the BCM and SBTOPO can directly calculate their codes, but the PCM and MCM obtain their codes by searching the entire coding system. The PCM and SBTOPO are better than the other three methods in terms of analysis of the upstream and downstream relationships between any two subwatersheds. All five coding methods have their own advantages and disadvantages.A suitable coding method should be selected according to research contents and coding requirements of distributed hydrological models in practical applications.
distributed hydrological model; Pfafstetter coding; binary-tree coding; multi-tree coding; stem-branch topological coding; subwatershed division
10.3876/j.issn.1000-1980.2017.01.004
2016-01-26
国家水体污染控制与治理科技重大专项(2008ZX07207-006,2012ZX07201-006);江西省水利科技重大项目(KT201501,KT201411);国家重点基础研究发展计划(973计划)(2015CB452701)
刘佳嘉(1985—),男,江苏扬州人,工程师,博士,主要从事分布式水文模型、水循环演变规律等相关研究。E-mail:vaver@foxmail.com
TV212.4
A
1000-1980(2017)01-0022-08
