基于Web日志挖掘的网络学习行为建模研究
2017-01-16马伟杰
马伟杰
(郑州航空工业管理学院 计算机学院,河南 郑州 450046)
基于Web日志挖掘的网络学习行为建模研究
马伟杰
(郑州航空工业管理学院 计算机学院,河南 郑州 450046)
网络教育的飞速发展,使得网络学习的效果越来越受到重视.主要介绍了基于Web日志挖掘技术的网络学习行为建模的过程.通过数据收集和预处理、模式发现及模式分析等过程,构建了基于Web日志挖掘的网络学习行为模型.
Web日志挖掘;网络学习行为;建模;聚类分析
0 引言
网络学习系统以其开放的网络平台、多媒体数字化的学习资源、灵活自主的学习方式为人们提供了一种新型的学习平台,已成为人们继续教育和获取知识的第二课堂.然而,目前的网络学习系统普遍存在着“个性化指导”缺失的问题.重“资源”轻“指导”现象严重,大多数的网络学习系统只是将教学资源放到了网络上,没有考虑到学习者的个性化特征,师生之间缺乏交流和反馈功能,教师难以对学生学习的过程进行控制,而学习者自己由于能力所限,也难以对学习过程进行自我控制,导致学习者情绪低下、学习热情衰减等问题,严重影响学习效果.因此,师生双方都迫切希望能够建立提供个性化推荐和指导的学习系统.
这一问题已经引起了国内外相关学者的高度重视,人们对网络学习理论与技术的研究重点已从解决教学资源的数字化问题,逐步转移到以认知科学为指导的网络学习行为建模机理与方法的研究.对网络学习者的学习行为进行研究,并从中挖掘网络学习者的学习特征,从而更加深刻地认识网络学习者的学习规律,为建立个性化的推荐和指导的学习系统提供理论支持.本文研究基于Web日志挖掘的网络学习行为建模方法.
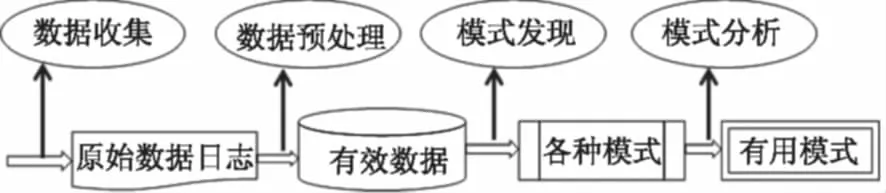
图1 Web日志挖掘过程Fig.1 Web log mining process
1 Web日志挖掘
Web日志挖掘是Web数据挖掘中一个很重要的分支,它利用数据挖掘技术对网站服务器上记录的用户访问相关的数据源,以及与网站服务相关的数据库数据等进行挖掘以发现蕴含的、事先未知的、有应用价值的知识和模式,并将由此得到的结果应用于统计与分析Web站点性能、改进Web站点结构、帮助理解用户意图与预测用户行为等方面.Web日志挖掘一般分为四个阶段(见图1),即数据收集、数据预处理、模式发现和模式分析[1].
2 基于Web日志挖掘的网络学习行为模型研究
2.1 数据收集和预处理
2.1.1 数据收集
网络学习者学习的过程中,Web服务器端日志会记录学习者学习过程中的一系列行为,例如网络学习者向浏览器发出请求,服务器将请求文件发送给学习者这样一个交互过程,日志文件都会记录.因此,服务器端的日志文件记录了网络学习者访问站点的信息,是Web日志挖掘的主要数据来源.本文采用Web服务器端日志数据作为挖掘的数据源.
Web服务器端日志数据,一般情况下,是纯文本文件,文件中每条记录的结束标志为回车换行符号oxod 或oxoa,主要是记录用户访问页面留下来的详细信息,文件格式都必须遵从W3C 标准.Web服务器端日志文件一般包括:用户IP地址、请求时间、用户使用的操作系统和浏览器类型、用户访问页面的时间、方法、用户访问网页的URL(uniform resource locator)和查询关键字等[2].
2.1.2 数据预处理
数据预处理就是把数据收集阶段收集到的原始的Web日志文件数据,有针对性地进行提取、分解、合并,从而转换为适合进行数据挖掘的可靠的精确数据,并保存到数据库中,等待进一步处理.这一过程主要包括四个步骤:数据清洗、用户识别、会话识别和路径补充.
1)数据清洗.目前的学习系统都是建立在B/S模式下基于数字资源的学习系统,Web日志是主要数据来源.数据清洗就是根据需求,对日志文件进行处理,删除与挖掘算法无关而又不影响结果的数据.比如学习者请求页面时发生错误的记录,URL的后缀带有图片(jpeg、gif等)、音频(mp3、wma等)、视频(wmv等)、脚本文件(js)等的日志记录,都可以将其删除[3].
2)用户识别.通常的网络学习系统都会使用代理服务器以及防火墙技术来保证网络系统的安全.这些技术的使用,使得在Web服务器端日志文件中识别每一个用户变得较为困难.用户识别的主要任务是通过分析清洗过的Web日志文件,从而消除代理或防火墙的影响,从中还原出每一个请求的用户并且识别出不同用户的访问路径,进而对用户和访问路径进行分类或聚类.目前,用户识别通常采用启发式规则,即只有IP地址、操作系统、浏览器、浏览器版本以及HTTP协议版本都完全相同才视为同一用户[4].
3)会话识别.网络学习过程中,一个会话(Session)是指网络学习者在一次访问学习系统期间从进入系统到离开系统所进行的一系列活动.不同个性的学习者,网络学习过程中的会话也不尽相同.一次网络学习过程中,网络学习者对某一个知识点感兴趣或者认为重要,可能多次访问了它,会话识别就是把同一学习者对某一知识点的多次访问请求识别为一个会话,即将网络学习者的访问路径序列划分成多个独立的用户会话.目前,会话的划分方法有很多,主要是基于启发式的会话识别方法[5].
4)路径补充.基于B/S模式构建的网络学习系统,在学习者学习的过程中,都会存在本地缓存和代理服务器缓存.这样,当学习者再去访问自己曾经访问过的路径时,Web服务器日志中不会记录下学习者的访问行为.路径补充的任务就是要补全Web服务器日志中遗漏的学习者访问行为,获取学习者完整的访问路径,以减少误差.
2.2 网络学习行为模式挖掘
网络学习行为模式挖掘就是要运用各种算法和技术对网络学习系统中预处理过的学习者的日志数据进行挖掘处理,从中发现网络学习者的学习行为模式,从而对行为模式进行分析.网络学习者学习行为模式分析就是将数据挖掘技术应用于Web日志的过程.本文采用模糊矩阵聚类算法将Web日志聚类.网络学习行为日志聚类主要包括网页聚类和用户聚类,网络学习过程中成为页面聚类和学习者聚类.
2.2.1 模糊矩阵聚类算法
模糊矩阵聚类算法是一种新的数据挖掘算法,它的基本思路是从矩阵Mm×n中析取密集的子矩阵Mm1×n1,其中m1<=m,n1<=n.
定义1 矩阵Mm×n为大型的稀疏二元矩阵,矩阵中的元素ai,j=0 or 1,
(1)
定义2 设∑Mm1,n1为子矩阵Mm1×n1中矩阵元素值为1的数目.
定义3 析取矩阵密度φ=∑Mm1,n1/(m1×n1).
析取算法过程为:
1)确定起始的行元素m,根据矩阵Mm×n,标记出该起始行中ai,j的值为1的矩阵元素的列,构成M1×j矩阵;
2)以M1×j矩阵中ai,j值为1的矩阵元素的列为标准,根据原矩阵Mm×n,给矩阵添加ai,j值为1的矩阵元素的行元素,构成Mi×j矩阵;
3)计算这时Mi×j矩阵的各行中ai,j值的和,将最小值所在行删除,其他行保持不变,构成新的Mi×j;
4)以M1×j矩阵中ai,j值为1的矩阵元素的行为标准,根据原矩阵Mm×n,给矩阵添加ai,j值为1的矩阵元素的列元素,构成新的Mi×j矩阵;
5)计算新的Mi×j矩阵各列元素中ai,j值的和,将最小值所在列删除,其他列保持不变,构成新的Mi×j矩阵[6].
下面以郑州航空工业管理学院“计算机网络”精品课程为例,介绍网络学习行为的建模过程.数据采用的是2015年5月20日的日志文件2.46 MB,共4 936条记录.经过数据清洗、用户识别和会话识别,在日志中保留记录1 523条,识别用户358个,识别会话652个,访问页面215个.
2.2.2 学习者聚类
本文从识别出的358个学习者中选取6个学习者,从识别出的215个页面中选取8个页面,采用模糊矩阵聚类的方法进行聚类分析(U表示学习者,P表示学习者访问的页面).
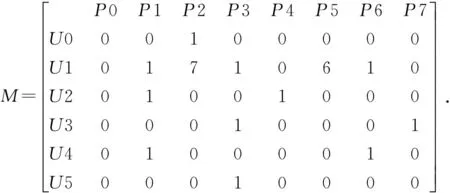
(2)
把式(2)中的数据作为原始的数据矩阵M,经过析取算法处理得到M的相似矩阵M′,
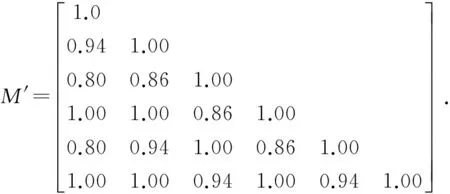
(3)
从式(2)和式(3)可以看出:
1)r=1时,学习习惯相近的学习者分为{U0,U3,U5 },{U2,U4},U1;
2)r=0.94时,学习习惯相近的学习者分为{U0,U3,U5,U2,U4 },U1.
由此可以得出,在选取的6个网络学习者中,U0,U3,U5网络学习习惯比较相近,而U2,U4网络学习习惯比较相近[3].
2.2.3 页面聚类
页面聚类同样采用学习者聚类中的6个学习者和8个页面,通过聚类分析建立用户访问页面的差别矩阵
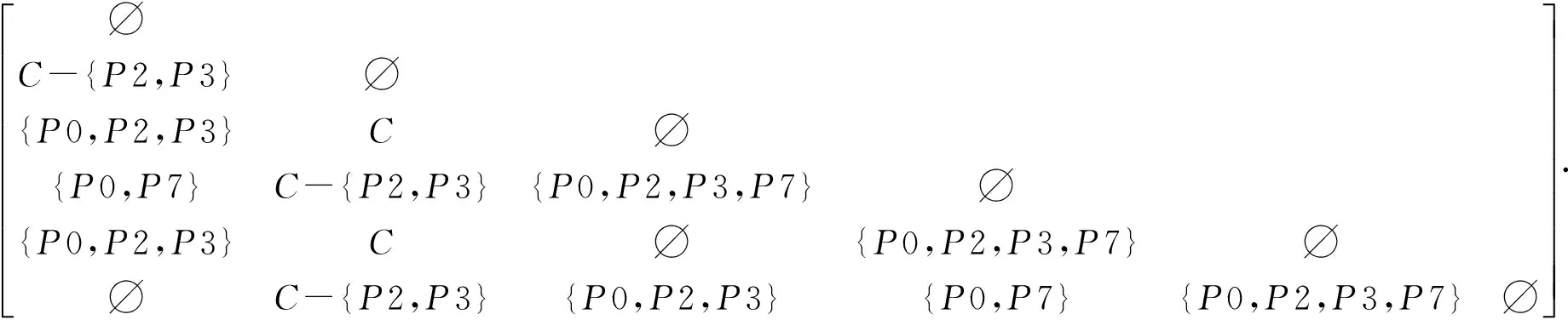
(4)
从式(4)可得属性约简为{P0,P2,P3,P7}.这样,在选取的8个页面中,P0和P7经常被访问,P2和P3也经常被访问,这4个页面非常重要.在改进网络学习系统资源设计的时候,可以调整它们4个的位置,放在比较容易被访问的地方[3].
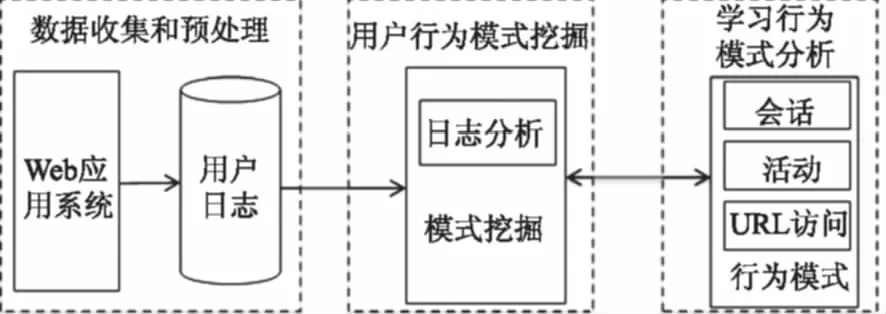
图2 基于Web日志挖掘的网络学习行为模型Fig.2 E-learning behavior model based on Web log
2.3 网络学习行为模型
综上,基于Web日志挖掘的网络学习模型主要分为数据收集和预处理、用户行为模式挖掘和学习行为模式分析三个阶段.基于Web日志挖掘的网络学习模型如图2所示.
3 结束语
个性化的服务是当前网络学习系统发展的重要趋势,它建立了以学习者为中心、因材施教的教育理念,将有效地提高网络学习的质量和效率.网络学习系统要实现真正意义上的个性化,必须及时、准确、全面地把握学习者的兴趣爱好、访问习惯等个性化的信息.而Web日志挖掘技术是获取、分析学习者个性化信息的关键技术之一.因此将Web日志挖掘技术应用于网络学习领域必将促进学习系统提供更加完善的个性化服务[7].
[1]吴瑛,朱岩.基于Web日志挖掘的个性化网络广告模型[J].计算机与数字工程,2010,1(38):103-106.
[2]陆丽娜.Web日志挖掘中数据预处理研究[J].计算机工程,2000,4(26):26-28.
[3]李晓昕,谢维奇.基于Web日志挖掘的网上学习行为研究[J].计算机技术与发展,2011,12(21):35-38.
[4]孙福振,李艳,李业刚.基于Web日志挖掘技术的农业信息网站构建[J].安徽农业科学,2009,33(37):48-51.
[5]王玉珍.基于Web日志挖掘的电子政务个性化服务体系研究[J].情报杂志,2013,8(32):62-65.
[6]孙忠林.面向电子商务的Web使用模式数据挖掘研究[D].青岛:山东科技大学,2002.
[7]杜瑾,刘均,郑庆华,等.一种基于网页元数据的用户访问行为建模方法[J].西安交通大学学报,2008,42(2):152-155.
Research on the E-learning Behavior Modeling Based on Web Log Mining
MA Weijie
(SchoolofComputerScience,ZhengzhouUniversityofAeronautics,Zhengzhou450046,China)
With the rapid development of network-based education,learning effect of network-based education becomes more and more important.Mainly introduces the e-learning behavior process which used Web log mining technology.Through the process of data collection and preprocessing,pattern discovery and pattern analysis,the e-learning behavior model which based on Web log mining was constructed.
Web-log mining;e-learning behavior; modeling; cluster analysis
2016-07-15
郑州航空工业管理学院青年基金项目“基于Web日志和页面元数据的网络学习行为建模方法研究”(2014103001)阶段性成果
马伟杰(1982—),男,河南郑州人,郑州航空工业管理学院计算机学院讲师.
10.3969/j.issn.1007-0834.2016.04.005
TP3-05
1007-0834(2016)04-0019-04
