基于逆幂法的组合稀疏约束主成分分析
2017-01-13刘向阳
李 霞,刘向阳
(河海大学 理学院,江苏 南京 210098 )
基于逆幂法的组合稀疏约束主成分分析
李 霞,刘向阳
(河海大学 理学院,江苏 南京 210098 )
讨论了在标准主成分分析的基础上增加L0罚,L1罚和L2罚约束条件,使主成分变得更加稀疏,以便于解释实际问题,运用逆幂法给出了求解目标函数的迭代算法.数据模拟实验展示了此算法在主成分的稀疏程度和累积贡献率上都取得了很好的效果.
主成分分析; 稀疏主成分分析; 逆幂法; 非线性特征提取
主成分分析(Principal Component Analysis, PCA)[1]广泛应用在数据降维和数据处理方面,其应用包括手写数字识别和人脸识别等.尽管经典的主成分分析算法有许多优点,但是在实际应用中主成分分析却存在着一些不足,主要表现在主成分依赖于所有的原始变量,很难给出其实际解释,有时需要对主成分进行分析和解释时,无法解释每一个主成分对应的特征是什么.稀疏主成分分析就是为了解决此问题而引进的一个算法,会把主成分系数变的稀疏,即把大多数系数都变成零.通过此方式,可以把主成分的主要部分凸现出来.因此,主成分就会变得较为容易解释.
实现主成分分析稀疏化最终会转化为优化问题,即对本来的主成分分析(PCA)中的问题增加一个惩罚函数,此惩罚函数包含有稀疏度的信息.最终得到的问题是NP-难题,为了解决其,就需要采用一些方法逼近此问题的解.最先提出的方法是简单门限主成分[2],但此方法被证明具有误导性.之后又提出的方法主要基于主成分L1范数的惩罚项,包括ScoTLAS和SPCA[3-8]. D’Aspremont等人[9]根据L0约束公式提出了贪婪的算法来计算出全套好的候选方案,使得一个向量成为全局最优解.Moghaddam等[10]用分支界限法来计算小问题实例的最优解.另外,还有D.C.和基于EM方法.Journee等[11]提出2种方法,基于L0罚和L1罚的单一的个体(一个成分的计算)和二分区式(多个成分同时计算).Matthias等[12]根据L1罚和L2罚[13]约束公式提出使用逆幂法解决此问题.笔者基于文献[12]的工作进一步添加L0约束条件,运用逆幂法给出求解目标函数的迭代算法,并且数据模拟实验充分展示了该算法在主成分的稀疏程度和累积贡献率上都取得了很好的效果.
1 稀疏主成分分析
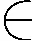

(1)
现在考虑函数F的下面的形式

(2)

(3)
为了得到稀疏的主成分,Hein M[12]在分子上使用L1范数和L2范数的组合来代替L2范数,在此基础上增加L0范数,把分子变为L0范数,L1范数和L2范数的线性组合使得主成分更加稀疏,函数变为

(4)
2 基于逆幂法的求解算法
2.1 稀疏主成分分析的分析解使用逆幂法求解公式(4)的特征值和特征向量.
获取半正定对称矩阵∑的最小特征向量的标准技术是逆幂法,其主要构建模块是使用迭代方案收敛到∑的最小特征向量.
定理1[11]假设R,S满足上述的条件,那么f*是F的一个驻点的必要条件是
(5)
(6)

(7)
式(7)中,当‖f‖2,β=0时,对于与足够大的α,必须使得f*(α)=0来获取最大的稀疏度.因为

得到‖Xf‖2-α‖f‖1<0,对于所有非零向量f,α始终要严格大于‖xi*‖2.现在假定
α<‖xi*‖2,
(8)
注意到在‖Xf*(α)‖2的值和稀疏解f*(α)有一个权衡.惩罚参数α被引用在上叙的2个极端的情形,其取值范围在区间[0,‖xi*‖2)上,依赖于在实际应用中稀疏度和解释方差的重要性.基于这些考虑,认为式(7)的解是X的稀疏主成分,其分析解由定理2给出.使用记号x+=max{0,x}.

(9)
证明假设目标函数是正一次的,最优化要么是0,插入在之前的迭代程序中,要么是负数,在此情况下最优解在边界取得.因此不失一般性,假设‖f‖2=1,所以目标函数(7)就变为


(10)
由于式(9)里的s仅仅是个换算系数,在执行算法过程中可以忽略掉,从而获得简单又有效的方案来计算稀疏主城分.
2.2 算法步骤基于定理2,设计了类似于文献[12]的算法步骤:
输出:特征值λk+1,特征向量fk+1.
步骤1初始化向量f0随机,S(fk)=1,λ0=F(fk),迭代次数k=1;


步骤4计算λk+1=(-α-β)‖fk+1‖2+α‖fk+1‖1+β‖fk+1‖0;


在文献[12]的基础上,笔者在算法中添加了L0约束条件,运用L0范数表示向量中非零元素的个数的属性来进行稀疏编码和特征选择,通过最小化L0范数,来寻找最少最优的稀疏特征项,为稀疏表示最直接最理想的方案,不足的是容易引发NP难题,所以用L0范数,L1范数和L2范数的线性组合来得到L0的最优凸近似.
3 实验与分析
3.1 实验数据及参数设置采用与文献[5]相同的数据模拟实验进行模拟,具体模拟数据产生方法如下
给出3个潜在的主成分V1,V2,V3,
V1~N(0,290),V2~N(0,300),V3=-0.3V1+0.925V2+ε,
其中,ε~N(0,1)且V1,V2和ε相互独立.
接下来产生10个变量,其构造如下



在实验中,本文算法中α,β稀疏控制参数由动态来确定.另外,主成分的非零个数控制为4个.
3.2 实验结果及分析

表1 PCA,SPCA和SPCA(InvPow)的模拟结果
为了避免模拟的随机性,用精确的协方差阵(X1,…,X10)来运行PCA,SPCA, SPCA(InvPow).
3个潜在主成分的方差分别是290,300和283.8,3个主成分相关变量的数量分别是4,4和2.SPCA,IPM和SPCA(InvPow)提取的前2个主成分分别共解释了总方差的99.6%,86.6%和99.8%,说明仅仅需要考虑2个派生变量.事实上,在正交约束下如果依次最大化前2个派生向量的方差,控制非零载荷的数量为4个,那么SPCA的第一个派生向量统一的在(X5,X6,X7,X8)上赋值非零荷载,第二个派生向量统一的在(X1,X2,X3,X4)上赋值非零荷载,而IPM和SPCA(InvPow) 的第一个派生向量统一的在(X7,X8,X9,X10)上赋值非零荷载,第二个派生向量统一的在(X1,X2,X3,X4)上赋值非零荷载.
由以上数据分析可以得到
1) 从稀疏程度方面,SPCA,IPM和SPCA(InvPow)都能给出稀疏形式的主成分,并且给出的稀疏程度相似,都是是通过预言信息执行的,理想的稀疏表示是仅仅4个变量.事实上,SPCA,IPM和SPCA(InvPow)都实现了前2个主成分的理想稀疏表示.
2) 从方差贡献率方面,PCA的累积贡献率达99.6%, SPCA的累积贡献率只有80.4%,IPM的累积贡献率达83.6%,SPCA(InvPow)的累积贡献率为99.8%,SPCA和IPM提取的主成分的信息损失较大,SPCA(InvPow)相对来说降低了信息的损失.
3) 从收敛速度方面,SPCA(InvPow)达到收敛所需的迭代次数要比IPM要少,收敛速度更快.
4 结束语
通过实验分析的数据可以得到标准PCA虽然信息损失量较小,但是给出的每个主成分自变量Xi的载荷系数都不为零,难以给出其实际解释.SPCA,IPM和SPCA(InvPow)都能给出稀疏形式的主成分,虽然在稀疏程度上有相似的的结果,SPCA(InvPow)减少了信息损失量.
尽管SPCA(InvPow)方法在模拟实验中显示了其良好的性能,但是仍然需要做进一步的研究,有待于在未来的问题中得到广泛应用.例如在处理实际问题时,参数的选择,约束条件的选取等,将来可进一步尝试将其加入到其他典型的相关分析应用当中.
[1] Jolliffe I T. Principal Component Analysis [M]. 2nd ed.New York: Springer, 2002: 167-198.
[2] Cadima J, Jolliffe I T. Loading and correlations in the interpretation of principal components [J]. Journal of Applied Statistics, 1995, 22(1): 203-204.
[3] Zou H, Hastie T, Tibsgirani R. Sparse principal component analysis [J]. Journal of Computational and Graphical Statistics, 2006, 15(2): 262-286.
[4] Shao W, Zhu L P, Liu Q P, et al. Sparse principal component analysis for symmmetrical matrix and application in sufficient dimension reduction [J]. Journal of Shandong University, 2012, 47(4): 116-120.
[5] Shen N J, Li J, Zhou P Y, et al. Extraction method based on sparse principal component for gene expression data [J]. Computer Science, 2015, 42(6A): 453-458.
[6] Liao R H, Li Y F, Liu H. Face recognition based on robust principal component analysis and kernel sparse representation [J]. Computer Engineering, 2016, 42(2): 200-205.
[7] Xiang K. Sparsity in principal component analysis [J]. Acta Electronica Sinica, 2012,40(12): 2 525-2 532.
[8] Zhao Q, Meng D Y. Robust sparse principal component analysis [J]. Science China (Information Sciences),2014,40(2): 175-188.
[9] D’Aspremont A, Bach F, Ghaoui L E I. Optimal solutions for sparse principal component analysis [J]. Journal of Machine Learning Research, 2008, 9(4): 1 269-1 294.
[10] Moghaddam B, Weiss Y, Avidan S. Spectral Bounds for Sparse PCA: Exact and Greedy Algorithms [M]. New York: MIT Press, 2006:915-922.
[11] Journee M, Nesterov Y, Richtarik P, et al. Generalized power method for sparse principal component analysis [J]. Journal of Machine Learning Research, 2010, 11(3): 5 117-5 153.
[12] Hein M, Buhler T. An inverse power method for nonlinear eigenproblems with applications in 1-spectral clustering and sparse PCA [J]. Journal of Machine Learning Research, 2010,9(4): 847-855.
[13] Ding M, Jia W M,Yao M L.A projection algorithm with local preservation based on L2norm [J]. Journal of Xi’an JiaoTong University, 2016, 50(2): 33-37.
Sparse Principal Component Analysis with Sparsity Constraints Based on the Inverse Power Method
Li Xia,Liu Xiangyang
(College of Science, Hohai University, Nanjing 210098, China)
In the report, based on the standard principal components analysis, in order to explain the practical problems, L0penalty, L1penalty, and L2penalty constraint conditions were added, which made the principal components more sparse. The inverse power method was used to obtain the iterative algorithm for solving the objective function. The data simulation experiment results suggested that our algorithm has achieved good effects on the sparse degree and the cumulative contribution rate of the principal component.
principal component analysis; sparse principal component analysis; the inverse power method; nonlinear feature extraction
2016-05-18
国家自然科学基金(61001139)
李霞(1989-), 女, 山西晋中人,河海大学2014级硕士研究生, 研究方向:稀疏主成分分析,E-mail:1294301102@qq.com
刘向阳(1977-), 男,博士,副教授, 研究方向:图像与视频分析、数据分析和机器学习, E-mail: liuxy@hhu.edu.cn
1004-1729(2016)04-0338-05
TP 391
A DOl:10.15886/j.cnki.hdxbzkb.2016.0051
