基于深度全卷积神经网络的文字区域定位方法
2017-01-11骆遥
骆 遥
(同济大学 测绘与地理信息学院,上海 200092)
基于深度全卷积神经网络的文字区域定位方法
骆 遥
(同济大学 测绘与地理信息学院,上海 200092)
近年来,深度学习模型在各种计算机视觉方面都展现出了远远优于传统方法的性能,在自然场景中的文字区域定位问题中引入深度学习方法无疑也是大势所趋。文章提出了一种基于深度全卷积网络方法的文字区域定位方法,实现了端到端的训练、检测,使得训练更为有效,检测过程更加高效。最终文中方法在ICDAR 2015数据集上对比基于MSER等的传统方法有了很大提升,达到了86.57%的查准率和82.1%的召回率。
深度全卷积网络;自然场景文字区域定位;图像区域分割
传统的自然场景文字定位问题通常遵循自下而上的检测流程,首先是对图像进行预处理,然后通过传统的检测方法通常是使用模版匹配的方法来选择候选区域,接着对候选区域进行投票选择融合或者非极大值抑制方法生成最后的文字区域[1]。这类模板在解决特定场景下的定位问题时非常有效,例如应用在扫描文件的OCR问题上[2],因为这类问题通常带有很强的先验信息,比如字体统一、大小统一等信息,但是在自然场景中文字字体千差万别、尺度跨度非常广,背景信息复杂,面对这些情况从低层特征构建出的模板泛化能力非常有限,这类方法的代表有SWT和MSER方法。
本文提出一种利用深度全卷积网络来对像素点进行分类,从而达到检测文字区域的目的。这种方法有如下几个优点,第一深度全卷积网络不同于传统的深度卷积神经网络,不需要对输入图像的尺寸做归一化操作,因此能最大程度上地在不损失原有图像信息的基础上利用好图像信息。第二,由于是利用对像素点进行分类来检测文字区域,因此对文字区域的尺度变化和旋转变化要比传统的模板匹配的方法鲁棒很多。第三,这是一种端到端的训练检测方法,能最大程度上的利用图像的上下文信息和局部信息对参数进行有效训练,检测阶段只需要进行一次前向传播就能完成所有的检测步骤,因此对比传统的模板匹配方法效率要提高不少。
1 方法描述
1.1 传统方法
过去很长一段时间内,自然场景的文字区域检测问题都依赖于单个文字的检测。单个文字通常使用一些低层特征例如HOG,LBP、区域面积、区域长宽比等来对单个文字进行描述,然后使用模板匹配的方法利用SVM,Random Forest等强分类器进行单个文字的检测。近年来,深度卷积神经网络所表现出的强大的特征表达能力使得该类方法在各个计算机视觉方向都取得了突破性的进展,因此也有一些工作使用深度卷积神经网络来代替低层特征加强分类器来进行单个字符的检测,也确实取得了更好的结果。但是基于该种思想的方法仍然无法在复杂的自然场景中游刃有余。
1.2 本文方法
VGG-16[7]是牛津大学视觉几何组在2015年提出的一种图像分类的深度卷积神经网络模型。该模型所采用的小卷积核(3×3)有效地减少了参数数量,防止过拟合,提升了训练效率,一经提出就在各大视觉竞赛中取得了优异的成绩。
由于VGG-16具有优异的特征表达能力,基于这个模型的各种衍生品层出不穷[3]。本文也是基于VGG-16的特征表达来实现自然场景的文字区域检测。本文提出网络结构如图1所示,前五层卷积部分完全继承自VGG-16,每个卷积部分都包含2个卷积层,2个激活层和一个下采样层。虽然卷积核的大小固定为3×3,可是由于网络层深不同的缘故,不同卷积部分所提取的特征侧重也有所不同,浅层的卷积部分更关注图像的局部细节,例如边缘和纹理等;深层的卷积部分更关注图像的全局信息,不同深度的卷积部分提取不同尺度上的图像特征,级联。这些特征对于准确地描述图像特征非常有帮助。承接5个卷积部分的是5个反卷积层,分别对应不同深度的卷积特征,其将这些卷积特征反卷积到和输入图像相同的尺寸大小。反卷积操作效果相当于上采样再加上一个1×1卷积核的卷积层。然后将这些反卷积得到的结果级联起来,再通过一个1×1的卷积层,这样就生成了最终的特征图。特征图通过Sigmoid层来实现对每个像素点的二分类。
基于深度全卷积网络的训练方法还是采用传统的minibatch的随机梯度下降方法,由于采用logistic作为二分类器,损失函数很自然地选择了交叉熵损失函数。训练阶段为了加速模型的收敛速度使用了Dropout层来加速收敛。测试阶段是用Sigmoid层代替Cross-Entropy损失层来得到最后的概率预测图,针对概率选择阈值就可以确定最后的结果。
2 实验结果与分析
2.1 实验数据
实验数据选择了ICDAR—2015中的自然场景文本标准数据集。这个数据集是ICDAR—2015自然场景文本区域定位比赛的专用数据集,是一个公认的具有挑战性的数据集。
2.2 训练细节
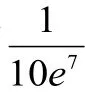
本文所提出的方法基于Caffe开源框架实现,服务器配置如下:2.0 GHz 8-coreCPU,32 GRAM,GTX—1070GPU,操作系统为Ubuntu-14.04 LTS。
2.3 检测结果
采用查准率和召回率来定量评价算法的性能与表现。设Nt为图像中文字区域数量,Nc为正确检测的文字区域数量、Nf为错检的文字区域数量,则查准率定义为:precision=Nc/(Nc+Nf),召回率定义为:recall=Nc/Nt。所有测试图像上有文字区域,基于本文算法共检测出1 508个文字区域,其中1 303个是正确的,205个是错误的,即查准率为86.57%,查全率为82.1%。
3 结语
本论文将深度学习引入了自然场景的文字区域识别问题中,并设计采用深度全卷积网络来进行像素分类并以此来解决文字区域定位的问题。像素分类不易受尺度变化、方向变化等要素影响,全卷积网络不受输入图像的图幅限制,本文将二者结合起来设计了端到端的训练、检测方法。对比以往的基于单个字符的区域检测方法更具有鲁棒性,在标准数据集上取得了不错的测试效果。

图1 本文设计的网络结构
[1]MATAS J, CHUM O, URBAN M, et al.Robust wide baseline stere of rommaximally stable extremal regions.[C].British: British Machine Vision Conference, 2002:384-396.
[2]DONOSER M, BISCH H.Efficient Maximally Stable Extremal Region(MSER)Tracking[C].USA: IEEE Conference on Computer Vision and Pattern Recognition, 2006:625-630.
[3]SALEMBIER, PHILIPPE, OLIVERAS A, et al. Antiextensive Connected Operators for Image and Sequence Processing.[J]. Transactions on Image Processing, 1998(4):555–570.
[4]NEUMANN L. A Method for Text Localization and Recognition in Real-World Images[C].Taibei: Asian Conference on Computer Vision,2010:770-783.
Text area location method based on depth full convolutional neural network
Luo Yao
(Surveying and Mapping and Geographic Information College of Tongji University, Shanghai 200092, China)
Deep learning has drawn lots of attention recently due to its powerful ability in both computer vision and voice field. Introducing depth learning method in text area localization problem of natural scene undoubtedly is the trend. In this paper we proposed a new method based on deep fully convolutional networks for neural scene text localization task which is an end-to-end method.The method we proposed makes the training and detection much more efficient compared with the traditional method such as MSER method. Finally we achieved 86.57% precision and 82.1% recall in ICDAR 2015 data set.
neural scene text localization;natural scene text area location; image region segmentation
骆遥(1992— ),男,甘肃天水,硕士研究生;研究方向:计算机视觉。
