基于支持向量机和决策树CART的个人信用评估
2017-01-05魏冠男
魏冠男
(安徽财经大学 管理科学与工程,安徽 蚌埠 233030)
基于支持向量机和决策树CART的个人信用评估
魏冠男*
(安徽财经大学 管理科学与工程,安徽 蚌埠 233030)
为了更好地控制借款人的信用风险,利用支持向量机对个人信用进行预测与分析,在支持向量机对个人信用评估产生缺陷的基础上提出基于代价敏感学的CART决策树预测个人信用的方法。实证分析表明:该方法能够较好地对借款人信用状况进行预测,为互联网金融机构进行相关风险管理提供理论依据。
支持向量机;个人信用;互联网金融机构;CART决策树;风险管理
随着社会经济的发展,互联网金融对促进小微企业融资和扩大就业产生了积极影响。但由于目前国内征信体系不完善、违约成本低等原因极易出现借款人违约等信用风险。风险的出现无疑会给相关金融机构和投资人带来巨大的损失,最终不利于互联网金融的健康发展。因此,建立互联网金融标准时应将信用管理作为一个关键指标。美国互联网金融机构把FICO信用分[1]作为信用风险控制最重要的参考数据,而国内尚缺乏这样的信用评分体系,不能精确估计消费信贷的风险。同时,由于互联网金融与传统商业银行在客户定位上的根本性差异,两者的信用评价模式也就不同。传统商业银行客户信用评价模式依赖于提供足够的抵押物或有效担保,或提供合适的财务报表等“硬信息”;互联网金融小微客户缺乏充足的抵押物,难以提供有效担保,且财务报表往往不规范、不全或失真,因此,我国应在基于本国国情的基础上结合客户的特征进行风险管理。充分利用积累的信息和数据,采用合适的信用评估方法对不同类别的借款人进行有效的信用评估。目前国内学者已经提出关于个人信用评估的多种分类方法:如李太勇等[2]针对传统信用评估方法分类精度低、特征可解释性差等问题,提出了一种使用稀疏贝叶斯学习方法来进行个人信用评估的模型(SBLCredit)。张燕等[3]针对个人信用评估中未标号数据获取容易而已标号数据获取相对困难,以及普遍存在的数据不对称问题,提出了基于改进图半监督学习技术的个人信用评估模型。汤浩龙等[4]以个人贷款信用评估为切入点,将支持向量机(Support Vector Machines,SVM)方法应用到个人贷款信用评估模型中。本文在利用Clementine软件基于支持向量机方法对个人信用评估进行评估的基础上提出了不平衡类问题,并提出基于代价敏感学习的分类决策树(Classification And Regression Tree,CART)的解决办法。
1 基于支持向量机的个人信用评估
1.1 支持向量机分类原理
SVM是一种监督式学习的方法,基本思想是把输入空间的样本通过非线性变换映射到高维特征空间,然后在特征空间中求取把样本线性分开的最优分类面[5],如图1所示。
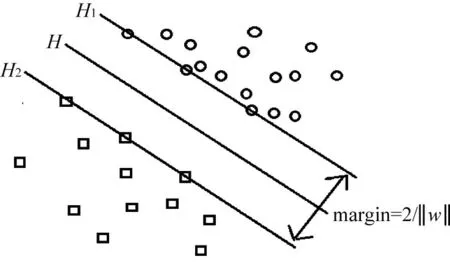
图1 支持向量机的分类原理图
图1中,H代表分类线,H1和H2分别将样本分开且离分类线最近且平行于分类线的直线,它们之间的距离称为分类间隔(Margin)。最优分类线能将两类样本正确分开,并且使分类间隔最大。分类线的方程表示为x·w+b=0,对于给定线性可分的样本集(xi,yi),i=1,2,…,n,xi∈Rd,y∈{-1,1}满足
yi(w·xi+b)-1≥0(i=1,2,…,n),
(1)
得到分类间隔为2/││w││,当分类间隔最大时,即等价于││w││2最小,满足条件式(1)并且使││w││2/2最小的分类面就叫做最优分类面,H1、H2上的训练样本叫做支持向量。
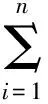
(2)
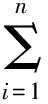
常用的核函数有线性核函数K(xi,x)=xixj;多项式核函数K(xi,xj)=[(xixj)+1]q;RBF核函数K(xi,xj)=exp(-(xi-xj)2/σ2);Sigmoid核函数K(xi,xj)=tanh(v(xixj)+c)。
1.2 个人信用评估的SVM模型建立
本文通过运用数据挖掘中的Clementine软件来对样本数据进行建模分析,具体过程如下:
1.2.1 商业理解
目前,住房按揭、消费信贷、汽车贷款、信用卡等信用消费已经逐步浮出水面,但是国内商业银行对消费贷款的风险管理水平较低,管理手段与方法均较落后,本研究利用信贷评估实例数据进行实证分析,采用最合适的任务安排和挖掘算法,为商业银行评估个人信用状况,并进行相关风险管理提供了理论依据。
1.2.2 数据理解
数据理解的关键是数据源的选择。本研究选用德国一银行信贷评估实例数据进行实证分析,实例数据中主要有20个影响违约状况的因素,第21个指标为该德国银行根据前面20个属性指标进行综合判断后对每个各户给出的信用评估类别。该样本数据中共包含1 000个客户,被银行批准获得贷款的“好客户”有700个,同时未获得银行贷款的“坏客户”有300个。
1.2.3 数据准备
在构建模型时,数据的处理对模型的评估结果有很大的影响。为了使模型的评估结果更准确,需要对数据进行预处理。我们将其中关于各个属性对应的状态编码数字化,首先根据每个属性的不同的状态按照0,1,2,…由小到大按顺序进行编号,其次将所有的属性及状态标号汇总在同一张Excel表中用于导入到Clementine软件中进行分析。
1.2.4 模型建立
选取 Clementine中的支持向量机节点建模,并分别用不同的核函数进行分类,具体的操作过程为:
Step1:将德国信用数据集Excel表导入其中作为源节点,将表节点附加到变量文件节点并执行流,将一个类型节点附加到源节点,将客户类别的字段值类型设置为“标志”,方向设置为“输出”,其他所有指标字段的方向设置为输入。
Step2:SVM 节点提供多个可选的核函数用于执行处理过程。由于无法知道哪个函数对于任意给定的数据集性能最佳,依次选用RBF(径向基函数)、poly(多项式函数)、Sigmoid函数和 line(线性函数)进行比较研究。
Step3:依次运行4个SVM节点可以生成4种核函数的分类模型,在最后一个模型后面附加一个分析节点并执行分析节点来对模型进行比较。
1.2.5 模型分析
将分析节点附加到最后一个模型节点上,然后使用分析节点的默认设置来执行。在完成模型实施阶段之后,数据流设计中的数据流图如图2所示。
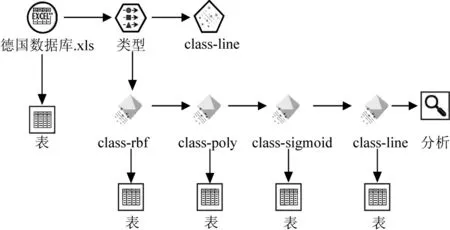
图2 SVM模型实施阶段数据流图界面
支持向量机中不同核函数的运行结果如表1所示。
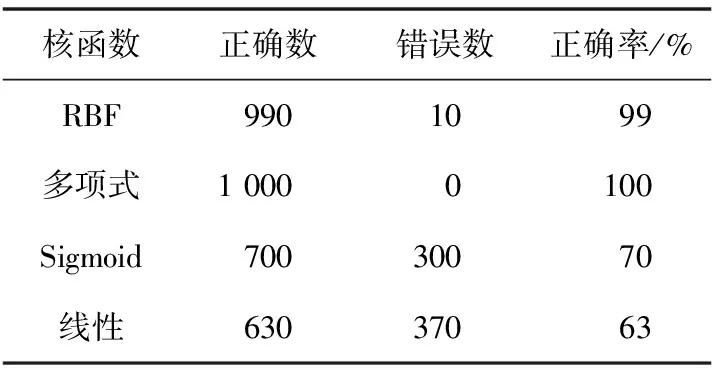
表1 模型预测数据分析表
表1给出了不同的核函数对于样本数据分类为正确或不正确的准确性。通过运行分析节点,可以得到每个模型的预测效果,来自分析节点的输出显示 RBF 函数可以正确地预测 99%的观测值,多项式函数可以正确预测每个观测值中的诊断。而Sigmoid函数和线性函数则只能预测70%和63%的观测值。这就意味着多项式函数相比其他3种核函数在预测个人信用方面要更加实用一些。
2 不平衡类问题
在分类过程中,属于不同类的实例数量都不成比例,对于银行来说,拒绝“好”客户和接受“坏”客户所造成的损失并不相等。接受“坏”客户,银行可能遭受较大的违约风险;而拒绝“好”客户,损失的是贷款利息[6]。也就是说,接受“坏”客户比拒绝“好”客户的成本高。虽然欺诈的量级可能是百分之一,但其所带来的损失必将是大于其收益的,因此,本文提出了基于代价敏感学习的个人信用预测方法。
2.1 CART决策树简介
CART决策树模型使用二叉树将预测空间递归地划分为若干子集,而树中的节点对应着划分不同区域,划分是由每个内部节点相关的分支规则来确定的,通过从树根到节点移动,一个预测样本被赋予一个唯一的叶节点,应变量在该节点上的条件分布也即被确定。CART算法包含3部分内容:分支变量即拆分点的选择、树的修剪和模型树的评估[7-9]。
2.2 CART决策树建模
Step1:采用的方法是将1 000个样本数据按照2∶1的比例分为训练样本(667个,从第一个到第667个样本)和测试样本(333个,从第668个到第1 000个样本)
Step2:将接受“坏”客户损失与拒绝“好”客户的损失比例分别设置为不同的比例时,对333个测试样本进行测试。
Step3:按照支持向量机的建模过程得到CART决策树的数据流如图3所示。
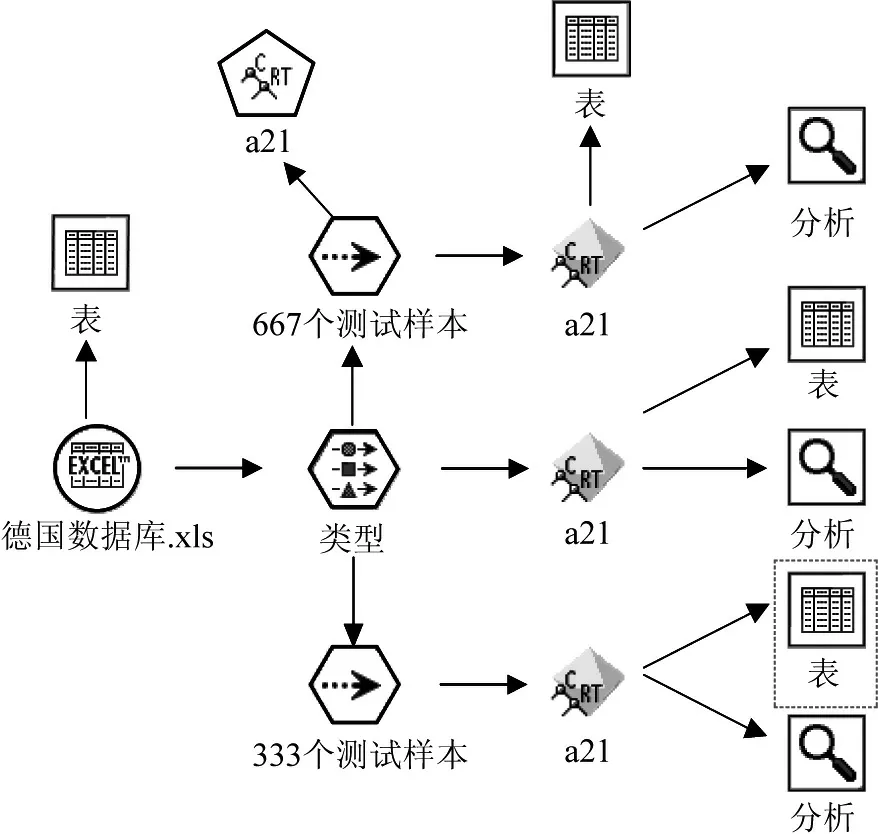
图3 CART模型实施阶段数据流图界面
2.3 不同误分类损失比例的结果分析
根据上述实验得到的结果如表2所示,其中a为接受“坏”客户损失与拒绝“好”客户的损失比例。
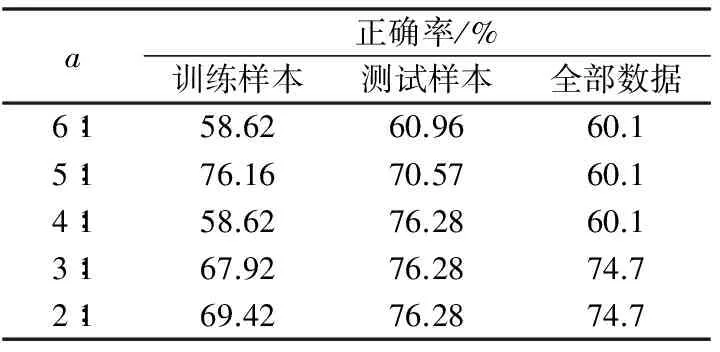
表2 CART模型预测结果表
从表2可以看出,随着接受“坏”客户损失与拒绝“好”客户的损失比例的加大,把“好”的客户误判为“坏”客户的可能性也加大,其预测结果的正确率会降低。
3 结论
信用评估准确率直优劣直接影响到互联网金融机构的利益和投资者的资金安全,影响到整个行业的健康发展。专业的信用风险控制能够将平台的逾期和坏账率控制到最低,可以保证金融机构长期运营的稳定和规范化发展。因此,无论是传统的银行借贷,还是互联网金融借贷,都应该把控好借款人质量,维护投资人的利益。
[1] FICO信用评级介绍[EB/OL].(2014-06-18)[2016-04-10]. http://wenku.baidu.com/link?url=aZF2-QNJMMe1cetFot x0jvJeJigr9VTxVlG_qW3ga6Rag_cVmJiSQE18PfO6T9BVHG8Cx5El 3zp4t6EB2JzQjWFIgMlje_ddcqqB_ta70DS.
[2] 李太勇,王会军,吴江,等.基于稀疏贝叶斯学习的个人信用评估[J].计算机应用,2013,33(11):3094-3096.
[3] 张燕,张晨光,张夏欢.基于改进图半监督学习的个人信用评估方法[J].计算机科学与探索,2012,6(5):473-480.
[4] 汤浩龙,和炳全,周薇.基于SVM的银行个人贷款信用评估模型研究[J].西部经济管理论坛,2012,23(1):45-50,55.
[5] 叶俊勇,汪同庆,杨波,等.基于支持向量机的人脸检测算法[J].计算机工程,2003,29(2):23-24.
[6] 宓文斌. 数据挖掘在银行信贷业务中的应用[D].上海:上海交通大学,2012.
[7] 王鹤琴,朱萍,程代娣. 决策树算法分析及其未成年人犯罪行为分析应用[J].合肥学院学报(自然科学版),2011,21(1):59-62.
[8] 高尚.支持向量机及个人信用评估[M].西安:西安电子科技大学出版社,2013:引用页码.
[9] TAN P N, STEINBACH M, KUMAR V.Introduction to data mining[M].Addison-Wesley Longman Publishing Co.Inc.2005.
Personal Credit Evaluation based on Support Vector Machines and Classification and Regression Tree
WEIGuannan*
(Anhui University of Finance and Economics, Institute of Management Science and Engineering, Bengbu,233030)
To predict and analysis individual credit by using support vector machine (SVM),the author puts forward a method of personal credit evaluation approach based on cost-sensitive CART, which provides a theoretical basis to commercial banks of the assessment for personal credit status about related risk management .
Support Vector Machine(SVM); personal credit; online financing;classification and regression tree; risk management
10.13542/j.cnki.51-1747/tn.2016.04.015
2016-06-27
魏冠男(1989— ),男(汉族),河南南阳人,在读硕士研究生,研究方向:互联网金融,通信作者邮箱:nan_shan@foxmail.com。
F830.49
A
2095-5383(2016)04-0060-03
