图像处理技术在车牌号识别领域中的算法改进
2016-12-29刘飞鹏沈希忠
刘飞鹏,沈希忠
(上海应用技术大学 电气与电子工程学院,上海 201418)
图像处理技术在车牌号识别领域中的算法改进
刘飞鹏,沈希忠
(上海应用技术大学 电气与电子工程学院,上海 201418)
针对图像处理技术在车牌号识别领域中的运用,结合目前常用识别方法(模板匹配法、神经网络法和支持向量机识别法)和主要特征提取方式(统计特征提取和结构特征提取)各自的优点,设计出一种多层分支结构的车牌号识别系统,该系统根据不同待识别字符的特征进行分类,然后匹配上对该类特征识别较有优势的特征提取方法和字符识别算法,并提出一种对折识别算法运用其中,通过对字符的分层识别和分支识别,从而达到精确、高效识别的目的,最后通过试验测试和统计分析,证明了该方法在车牌号识别中的优越性。
车牌号识别;图像处理;易混字识别
近年来,随着国民经济的快速发展,机动车数量增长迅猛,接踵而来的交通违章、肇事逃逸、车辆盗窃等行为呈现快速上升趋势,给交通管理和车辆监管部门造成不小的压力。智能交通系统的开发和运用已成为缓解交通管理问题的必然出路[1],而该系统中最主要的环节之一就是车牌号的智能识别。目前的车牌号识别方法有模板匹配法、神经网络法和支持向量机法(Support Vector Machine,SVM),其中后两种方法需要先对字符特征进行提取,字符特征提取的方式又可分为统计法和结构特征法。统计法对字符的变形和噪点容错能力较强,但对相似字符的细节特征难以区分;结构特征提取法能够分辨出字符的细节结构,但当拍摄图像清晰度不高时容易出现特征提取错误。由于车牌字符特征的多样化和拍摄环境的复杂化,运用单一的字符特征提取方式和字符识别方式无法满足字符识别较高正确率的要求,尤其不能满足对相似字符的识别要求。
因此,为了实现对车牌字符更高的识别率,尤其提高对易混字符的识别率,本文在适当改进简单字符识别算法的同时,重点在易混淆字符的识别算法上进行研究和改进,通过结合以上不同识别方法和不同特征提取方式的优势,同时运用一种独创的对折算法,设计出一种多层分支结构的识别系统,该系统本着简单字符少分支、易混淆字符巧分支的原则,在实现提高字符正确识别率的同时,让系统具有更加简洁、高效的工作效率。
1 车牌号识别方法
在车牌号识别过程中主要运用到图像处理技术,该过程主要包括图像的采集、车牌的定位、字符的分割[2]和字符的识别[3]。经过前期图像处理分割出的字符如图1所示,字符识别环节是车牌信息获取的关键,也是本领域研究的热点,目前主流的车牌号识别方法有模板匹配法、神经网络法和支持向量机法。

图1 分割处理后的车牌字符
1.1 基于模板匹配的识别方法
模板匹配法的识别过程为:首先建立模板库,然后对待识别字符进行特征提取,通过待识别字符的特征向量与模板库中字符的特征向量进行比对,相似度最高的模板所对应的字符即为待识别字符的识别结果,该方法的优点是原理简单、算法简洁、识别速度快,但该算法对字符的变形容错能力较差。
1.2 基于人工神经网络的识别方法
人工神经网络由输入层、中间层和输出层组成,其结构如图2所示,理论上通过3层神经网络即可无限拟合任意非线性函数,人工神经网络识别方法的优点为对字符的噪声及变形不敏感,容错能力较强,其不足为该识别方法对相似字符的细节结构难以区分。另外,因其神经元较多、运算量较大,实时性较差。
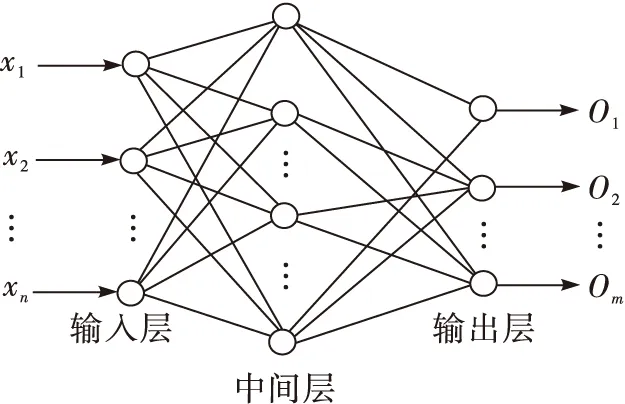
图2 人工神经网络结构图
1.3 基于支持向量机的识别方法
支持向量机(SVM)是一种基于统计学的机器学习算法,其原理为将输入的样本向量通过核函数映射到一个高维空间,然后求出由多个支持向量构成的最优分类超平面,使得超平面间的分类间距尽量大,这样就使得分类错误的风险尽量小,简而言之,即高维空间的线性规划问题。因该算法具有较好的过度拟合训练样本功能。 因此,SVM对于即使未见过的测试样本也具有较好的分类功能。
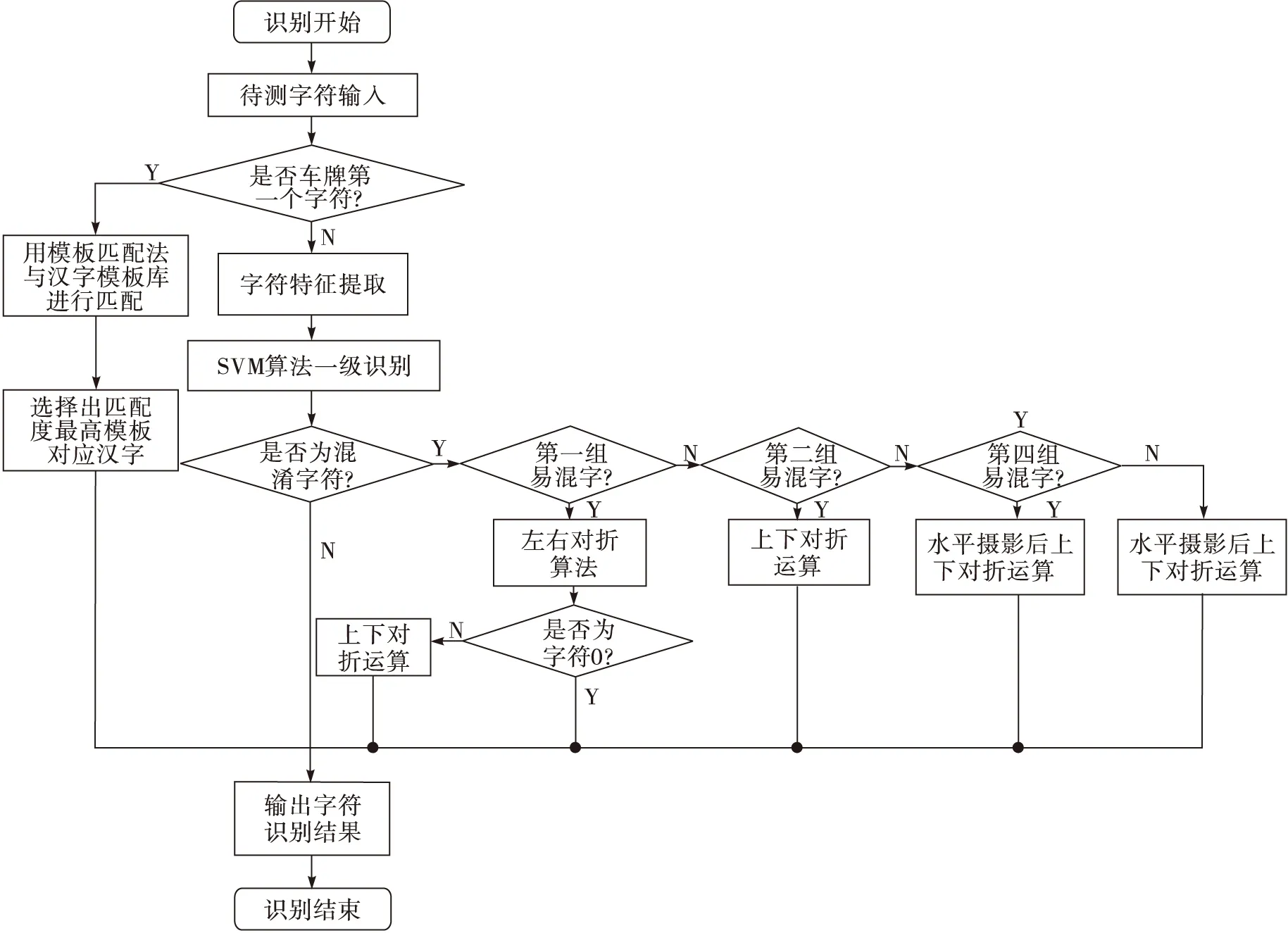
图3 字符识别整体流程图
2 改进的多层分支结构算法
要进一步提高车牌号识别的正确率,首先要吸取原有识别算法的识别优势,其次要对不同特征的字符进行分类识别,同时,最关键要在易混淆字符的识别上采取更加有效的识别算法。本系统在识别算法上采用多层分支结构,对不同分支采用对应更有效的识别算法,同时,对于一级识别中识别出的字符属于易混淆字符的,再根据该字符在易混淆字符中的分组,进行二次甚至多次识别,直到准确识别出易混字符的特征为止。本系统的整体工作流程图如图3所示。
2.1 车牌汉字的识别
在车牌的左侧第一个字符为汉字,其外形如图4所示,为了能清晰识别字符的细节结构特征,该系统采用模板匹配算法作为汉字的识别算法。另外,该系统在模板匹配前增加了一个黑像素点统计环节,然后把汉字模板库中黑像素数目与待测字符最相近的10个作为模板子集进行匹配,这样既减小了模板匹配数量,又提高了模板匹配效率。

图4 车牌字符中的汉字
2.2 字母和数字字符的一级识别
对于车牌中字母和数字的一级识别,如图5所示。在字符特征提取方面,采用统计特征提取和结构特征提取[4]相结合的方法,在字符识别算法的选择方面,因对字符特征提取的数据稍多,因此在字母和数字的一级识别阶段,采用SVM支持向量机识别算法。在字符的统计特征提取方面,采用水平投影和竖直投影相结合的方式,即对每行和每列黑像素的点数进行统计,如图6所示为字母“C”的水平投影统计图。在结构特征提取方面,将每个待测字符分成8列16行的小方格,统计每个小方格中的黑像素点个数,然后再除以该字符中总的黑像素个数,这样每个字符通过统计特征与结构特征提取将得到一个64+32+8×16=224维的特征向量。而原图像为64×32=2 048维的数组,因此通过该方案的特征提取在保证字符整体特征和细节结构的同时充分降低了特征向量的维数。
图5 车牌中字母和数字字符
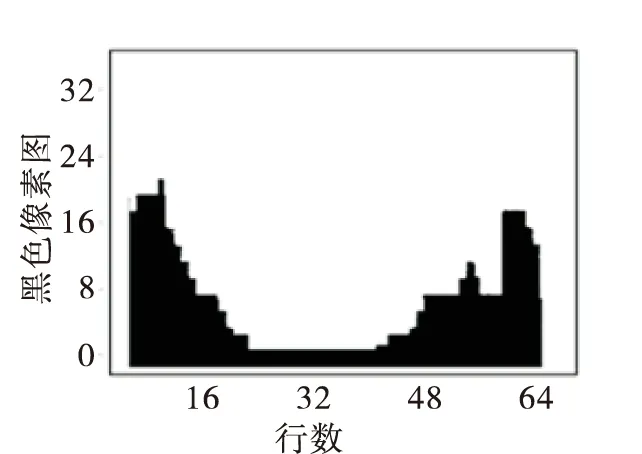
图6 字母“C”的水平投影特征数据图
然后,将待测字符的特征数据经SVM算法运算和处理,输出待测字符的一级识别结果,如果识别结果为非易混字符,即可直接输出识别结果,如果为易混字符,则进入下一环节的易混字符识别算法。
2.3 易混字符的识别
在车牌的字符识别过程中,易混字的识别一直制约着车牌字符识别正确率的提高,本识别系统通过对易混字符单独建立易混字符库,同时将结构相似的字符进一步分组,然后根据每组易混字的特征分别采取对应更加有效的识别算法,从而达到对易混字符准确识别的目的。
经相关资料查阅和实践测试,总结出以下几组易混字:
第1组:字母O,Q,D,数字0;
第2组:字母C,G;
第3组:字母Z,数字2;
第4组:字母S,数字5;
第5组:字母A,R,数字4。
因车牌上的字符都是专用字体,这里截取车牌中二值化处理后的第一组易混字,其形状如图7所示。

图7 二值化的车牌字符专用字体
从图7中可以看出字母”O”与数字“0”在车牌中的结构形式是一模一样的,因此主要看该字符在车牌中出现的位置,出现在车牌的第二位即为字母“O”,出现在其他位置则根据车牌字符排列的规则进行辨别[5],从此也可以看出部分文献中想当然地把字母“O”和数字“0”的识别方式表达为“矮胖”和“高瘦”的区别是一种纯空虚理论。
在本组的易混字识别中,笔者采用对折算法进行识别。首先,找到待识别字符黑色像素点中最下侧和最上侧像素点的纵坐标,分别表示为y1,y2,计算字符的水平中心线的纵坐标y3,算法如式(1)所示
(1)
并检测出纵坐标为y3时,字符中最左侧和最右侧黑像素的横坐标x1,x2, 计算字符的竖直中心线的横坐标x3,算法如式(2)所示,各坐标在字符中的位置如图8所示。
(2)
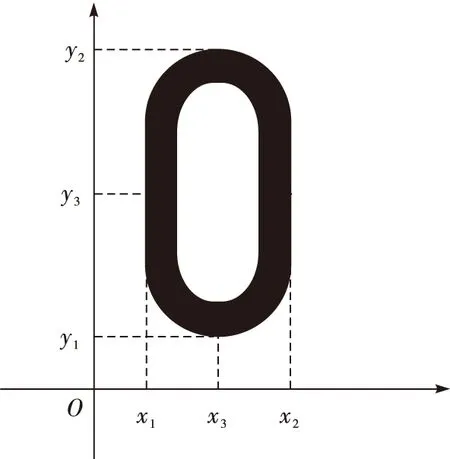
图8 对折算法字符坐标图
首先,运用式(3)算法,对字符进行左右对折,公式中函数f(i,j)代表在坐标(i,j)处图像的像素点值,黑色为“1”,白色为“0”,C1代表待测字符左右对折后未重叠部分占字符总面积的比重,经运算后,如果C1为0,则待识别字符为字母“O”或数字“0”的符号
(3)
如果C1不为0,则进行式(4)算法,对待测字符进行上下对折,C2代表字符上下对折后未重叠部分占字符总面积的比重;如果C2为0,则待识别字符为字母“D”,如果不为0,则待识别字符为字母“Q”,如此即可准确识别出该组易混淆字符。
(4)
第2组:字母C,G的字符识别。字母C,G在车牌专用字体中的形状如图9所示,对该组易混淆字符可以运用式(4)算法对字符进行上下对折,如果输出的结果C2为0则为字母“C”,而字母“G”的对折后未重叠部分如图10所示的斜线区域,从此图可以看出未重叠部分还是很明显的,因此当C2大于5%时,即未重叠部分大于整个字符部分的5%时,则该字符即为字母“G”。
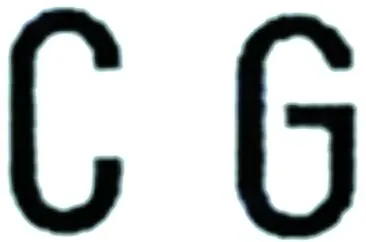
图9 字母C,G在车牌专用字体中的形状
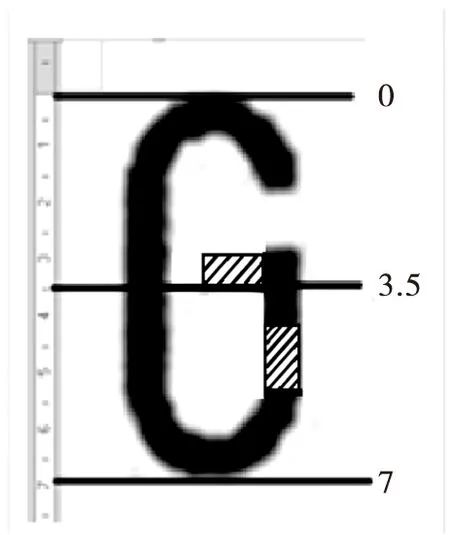
图10 字母G的上下对折未重叠部分
第3组:字母Z,数字2。字母Z与数字2在车牌中的字符外形如图11所示,考虑到字符变形和倾斜等因素[6]的影响,会使特征差别不太明显,因此这里采用水平投影数据上下折叠的算法,因为即使字符发生偏斜和形变,但因整体都有影响,经投影折叠作差,干扰因素将被抵消,其原有的差别特征将仍能很好地提取出来,经投影作差运算,其输出结果如果为0则为字母“Z”,否则为数字“2”。
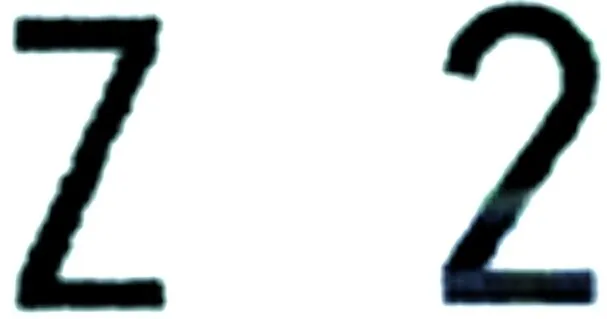
图11 字母Z、数字2在车牌中的字符外形
第4组:字母S、数字5。本组的识别方式与第三组的较为相似,这里不再详细论述。
第5组:字母A,R,数字4。在某些仅仅利用结构特征提取的识别算法中,该组将是一个很难区分的易混字,如果把结构特征和统计投影特征相结合的方式进行字符特征提取,该组字符在第一级识别中即可准确地识别出来,因此,在该系统中,本组字符不属于易混字。
综上所述,在其他车牌号识别系统中的5组易混字符,在本文所设计的车牌号识别系统中,其实际易混
淆字符仅为4组,有效减少了易混字符的数量,同时也意味着有效地提高了车牌号识别的正确率。
3 测试、统计与结果分析
本车牌号识别系统算法在宏碁E5-511便携式计算机上用MATLAB7.10平台进行运行,通过对300个待测车牌样本进行测试,从车牌图像采集到识别出的字符串输出,每个车牌识别平均用时2.779 s,即单个字符平均用时0.397 s,完全能满足车牌号识别的实时性要求。如图12所示,为本车牌号识别系统的测试界面。
通过对300个车牌样本的识别结果进行统计,其统计结果如表1所示(最右侧”整体识别正确率”下面数据为99.10%,有时显示不出来,可通过鼠标点击该栏即可显示出来)。
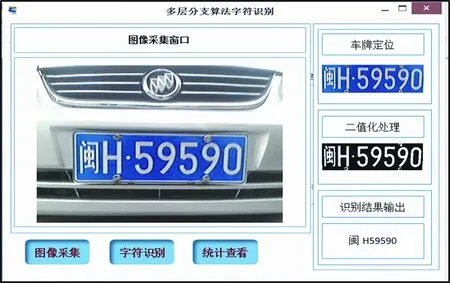
图12 车牌号识别系统界面(截图)

表1 识别正确率分类统计表
在车牌样本测试过程中,识别错误字符的详细统计信息如表2所示。

表2 样本测试时识别错误字符详细统计表
本车牌号识别系统与同领域其他车牌号识别系统的正确率情况对比如表3所示。
结果分析:从表1可以看出,虽然整体的识别正确率已经很高,但汉字的识别正确率仍然较低,其次是易混淆字符的识别率,虽然在识别过程中运用了多种识别算法进行优势互补,但仍然难以与简单字符的正确率相平齐,另外可以看出,简单字符的识别技术已经基本趋于成熟。
从表2数据分析,“赣”字识别错误的原因为因该字笔画复杂,同时拍摄清晰度有限,后经提高清晰度处理后,就不再出现该种错误。对于“鲁”与“晋”,因这两个字符的统计特征曲线图较为相似,但在汉字中未设置易混字识别环节,导致识别错误。对于字符“H”和“K”、字符“U”和“N”容易出现识别混淆,可以通过把这两组字符也加入易混淆字符库来解决。而对于易混淆字符中“0”与“D”仍然容易发生混淆,其原因为“D”在对折运算后的差值因过小,已经满足判为“0”的阈值,“2”与“Z” 识别错误的原因也类似,但如果阈值再调小一些,字符识别的抗干扰能力将降低,因此可以通过微调来选出更优的阈值或增加深一层的特征识别算法来解决。
从表3中的信息进行对比分析,本车牌号识别系统在一级识别和易混字识别的算法上都在同领域优势算法的基础上做了进一步优化和改进,在字符识别正确率方面,该车牌号识别系统在同领域较高识别正确率的基础上又提高了约一个百分点,因此可以证明:本车牌号识别系统在算法上的优化和改进在提高识别正确率方面起到了显著和积极的作用。
4 总结
本车牌号识别系统通过在一次识别时,对不同特征提取方式的优势互补,在易混字符识别上通过多种识别方式的配合运用,有效提高了系统的综合性能。然后,通过对待测样本的识别测试和结果统计,该系统的识别正确率较文献记载的最高正确率又提高了一个百分点,因此,通过试验证明,该种优化和改进对系统的识别性能起到了显著积极的作用。当然该识别算法仍存在一定不足,随着技术的不断改进和完善,车牌号智能识别系统一定能以更加成熟和稳健的步伐在交通管理控制领域掀起一场新的技术革命。
[1] 柴治,陶青川,余艳梅,等.一种快速实用的车牌字符识别方法[J].四川大学学报(自然科学版),2002,39(3):465-468.
[2] 施丽红,刘刚.基于改进蜂群优化的图像分割算法[J].电视技术,2016,40(2):37-44.
[3] 李会民,张仁津.基于改进BP网络的车牌字符识别方法研究[J].计算机工程与设计,2010,31(3):619-621.
[4] 宋加涛,刘济林.车辆牌照上英文和数字字符的结构特征分析及提取[J].中国图象图形学报,2002,7(9):945-949.
[5] 中华人民共和国机动车号牌:GA36-92[S].[S.l.]:中华人民共和国公安部,1992.
[6] 王啸晨,潘榕.基于图像失真类型的自适应图像质量评价方法[J].电视技术,2016,40(2):137-140.
[7] 薛丹,孙万蓉,李京京,等. 一种基于SVM的改进车牌识别算法[J].电子科技,2013,26(11):19-23.
[8] 何兆成,佘锡伟,余文进,等.字符多特征提取方法及其在车牌识别中的应用[J].计算机工程与应用,2011,47(23):228-231.
[9] 朱皓.基于易混淆字符集神经网络的车牌识别算法研究[D].武汉:华中师范大学,2014.
刘飞鹏(1988— ),硕士生,主研图像处理与智能识别;
沈希忠(1968— ),教授,主要研究方向为盲信号处理。
责任编辑:闫雯雯
Improvement of image processing algorithm in license plate recognition
LIU Feipeng,SHEN Xizhong
(ElectricalandElectronicEngineeringCollege,ShanghaiUniversityofInstituteandTechnology,Shanghai201418,China)
A design of license plate number recognition system with multi layer branch structure is introduced,which combines the advantages of template matching method, neural network method, support vector machine method, statistical feature extraction and structure feature extraction method. Firstly, this system classifies these characteristics into different classes, then match these classes with feature extraction and character recognition algorithm,and a fold recognition algorithm is also employed in it. With the help of the characters and branch recognition, the system performance achieves accurate and efficient identification. Finally, the experiment results and statistical analysis prove that the design perform better than other systems in the license plate number recognition.
license plate number recognition;image processing technology;confusable word recognition
上海市科委项目(15ZR1440700)
刘飞鹏,沈希忠.图像处理技术在车牌号识别领域中的算法改进[J].电视技术,2016,40(12):28-33. LIU F P,SHEN X Z. Improvement of image processing algorithm in license plate recognition [J]. Video engineering,2016,40(12):28-33.
TN911.73
A
10.16280/j.videoe.2016.12.006
2016-04-20
