A visual awareness pathway in cognitive model ABGP①
2016-12-29MaGangYangXiLuChengxiangZhangBoShiZhongzhi
Ma Gang (马 刚), Yang Xi, Lu Chengxiang, Zhang Bo, Shi Zhongzhi
(*The Key Laboratory of Intelligent Information Processing, Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100190, P.R.China)(**University of Chinese Academy of Sciences, Beijing 100190, P.R.China)
A visual awareness pathway in cognitive model ABGP①
Ma Gang (马 刚)②***, Yang Xi*, Lu Chengxiang*, Zhang Bo***, Shi Zhongzhi*
(*The Key Laboratory of Intelligent Information Processing, Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100190, P.R.China)(**University of Chinese Academy of Sciences, Beijing 100190, P.R.China)
The cognitive model ABGP is a special model for agents, which consists of awareness, beliefs, goals and plans. The ABGP agents obtain the knowledge directly from the natural scenes only through some single preestablished rules like most agent architectures. Inspired by the biological visual cortex (V1) and the higher brain areas perceiving the visual feature, deep convolution neural networks (CNN) are introduced as a visual pathway into ABGP to build a novel visual awareness module. Then a rat-robot maze search simulation platform is constructed to validate that CNN can be used for the awareness module of ABGP. According to the simulation results, the rat-robot implemented by the ABGP with the CNN awareness module reaches the excellent performance of recognizing guideposts, which directly enhances the capability of the communication between the agent and the natural scenes and improves the ability to recognize the real world, which successfully demonstrates that an agent can independently plan its path in terms of the natural scenes.
ABGP, visual cortex (V1), convolution neural networks (CNN), awareness, visual pathway
0 Introduction
Rational agents have an explicit representation for their environment (sometimes called world model) and objectives they are trying to achieve. Rationality means that the agent will always perform the most promising actions (based on the knowledge about itself and sensed from the world) to achieve its objectives. For a rational agent facing with a complex natural scene, how to get knowledge from scenes to drive their actions? Most agent designers may have a common view that they either create a virtual scene or set some single inflexible rules for agent to recognize surroundings.
There exist numerous agent architectures as mentioned above, such as BDI[1,2], AOP[3], SOAR[4]and 3APL[5], in which the communication of information between the agents and the world is based on a single fixed rule as well. With respect to the theoretical foundation and the number of implemented and successfully applied systems, the belief-desire-intention (BDI) architecture designed by Bratman[1]as a philosophical model for describing the rational agents should be the most interesting and widespread agent architecture. Of course, there are also a wide range of agents characterized by the BDI architecture, where one of these types is called ABGP (a 4-tuple
ABGP model consists of the concepts of awareness, beliefs, goals, and plans. Awareness is an information pathway connecting to the world (including the natural scenes and the other agents in the multi-agent system). Beliefs can be viewed as the agent’s knowledge about its setting and itself. Goals make up the agent’s wishes and drive the course of its actions. Plans represent agent’s means to achieve its goals. However, the ABGP model agent still has a disadvantage that it just transfers special fixed-format message from the world. Obviously, if the agent constructed by ABGP model (ABGP-agent) is expected to have an ability to sense directly the natural scenes, a new awareness pathway must be proposed.
Motivated by the above analysis, the primary work of this paper is to construct a novel flexible natural communication way between the ABGP-agent and the natural scenes by introducing a so-called artificial neural networks as the environment visual awareness pathway. The ABGP-agent using the artificial neural networks as an environment visual awareness pathway will be a natural (human-like) modeling and a higher level simulation of artificial organisms. However, which artificial neural network is better for the visual awareness path?
Convolutional neural networks (CNN) from Hubel and Wiesel’s early work on the cat’s visual cortex[7]have some functions like the human visual pathway. The deep CNN with the trainable multiple-stage architectures composed of the multiple stages can learn the invariant features[6,8]. Each stage in a deep CNN is composed of a filter bank, some nonlinearities, and feature pooling layers. With the multiple stages, deep CNN can learn the multi-level hierarchies of features. That is the reason why deep CNN have been successfully deployed in many commercial applications from OCR to video surveillance[9].
Taking into account all statements depicted above, the deep CNN based on the biological visual cortex theory is more suitable for an environment visual awareness pathway in cognitive model ABGP. Therefore, our main work in this study is to embed the deep CNN as a novel environment visual awareness pathway to the awareness module of ABGP, and apply it to the rat-robot maze search.
1 Cognitive model ABGP
In computer science and artificial intelligence, agent can be viewed as perceiving its environment information through sensors and acting environment using effectors[10]. A cognitive model for the rational agent should especially consider the external perception and the internal mental state. The external perception as a knowledge is created through the interaction between an agent and its world. For the internal mental state, BDI model conceived by Bratman[1]will be consulted as a theory of human practical reasoning. Reducing the explanation framework for the complex human behavior to the motivational stance is the especially attractive character[11].
The cognitive model ABGP (Fig.1) proposed by Shi.[6]is one of the most typical agent models characterized by the BDI architecture, which is represented as a 4-tuple framework as

Fig.1 Cognitive ABGP model[6]
1.1 Awareness
Awareness in cognitive ABGP agent model should be considered as the basic elements and the relationship related to its setting. A definition of awareness can be depicted as a 2-tuple
1.2 Belief
Belief for an agent can be commonly seen as the knowledge base from its internal state and external world, which contains abundant contents, including basic axioms, objective facts, data, etc. A 3-tuple
1.3 Goal
Goal represents the agent’s motivation stance and is a driving force for its actions. Four typical structures of goal are listed as perform, achieve, query, and maintain goal[12,13]. A perform goal specifies some activities to be done, therefore the outcome of the goal only depends on the fact if activities were performed[14]. An achieve goal represents a goal in the classical sense by specifying what kind of world state an agent wants to bring about in the future[13]. A query goal is used to enquire information about a specified issue. A maintain goal has the purpose to observe some desired world state and the agent actively tries to re-establish this state when it is violated[13]. The goal deliberation process has the task to select a sub-set of consistent desires. Moreover, all goals represented above inherit the same generic lifecycle[13].
1.4 Plan
Plan represents the agent’s means to act in its environment. Therefore, the plans predefined by the developer are composed of the action library that the agent can perform. Depending on the current situation, plans are selected for responsing to the occurring events or goals. The selection of plans is done automatically by the system and represents one main aspect of a BDI infrastructure. When a certain goal is selected, the agent must look for an effective way to achieve the goal, this reasoning process is called planning. In order to accomplish the plan reasoning, the agent can adopt two ways: one is using already prepared plan library to achieve some specific or pre-established goals, which is also called static planning[6]; Another way is instantly planning for achieving the goals based on the beliefs of current status, namely dynamic planning[6].
1.5 Policy-driven reasoning
Policy-driven reasoning mainly makes the plans (policies) selection by handling a series of events. A policy will directly or indirectly cause an action aito be taken, the result of which is that the system or component will make a deterministic or probabilistic transition to a new state Si. Kephart, et al.[15]outlined a unified framework for autonomously computing policies based upon the notions of states and actions.
The agent policy model can be defined as a 4-tuple P={St, A, Sg, U}, where Stis the trigger state set at a given moment in time; A is the action set; Sgis the set of goal states; U is the goal state utility function set to assess the merits of the goal state level.
2 Deep convolutional neural networks
The theory of CNN is primarily rooted in Hubel and Wiesel’s early work on the cat’s visual cortex neurons with the capability of locally-sensitive and orientation-selective in 1962[7,16]. However, the first implementation of CNN in computer science was the so-called Neocognitron proposed by Fukushima[17]which had been originally applied to the problem of hand-written digit recognition. After 2006, deep learning technology described new ways to train CNN more efficiently that allowed networks with more layers to be trained[18].
The deep CNN consisting of multiple layers of small neuron collections has been adopted to recognize natural images[19]. Furthermore, some local or global pooling layers may be included in the deep CNN, which combine the outputs of neuron clusters[20]. A typical deep CNN consists of various combinations of convolutional layers and fully connected layers, with point-wise non-linearity applied at the end of or after each layer[21]. Generally, the combination consisting of a filter bank layer, a non-linearity transformation layer, and a feature pooling layer, is called a stage. Fig.2 shows a typical deep CNN framework composed of two stages.

Fig.2 A typical deep convolution neural networks framework with two feature stages
2.1 Filter bank layer
The input is a 3D array with n12D feature maps of size n2×n3. Each component can be marked as xi, j,k, and each feature map is denoted as xi, where the output is also a 3D array, and y consists of m1feature maps of size m2×m3. A trainable filter (so-called kernel) ki, jin the filter bank has the size of l1×l2and connects input feature map xito output feature map yj. The module computes: yj=bj+∑iki, j*xi, where * is the 2D discrete convolution operator and bjis a trainable bias parameter[22].
2.2 Non-linearity layer
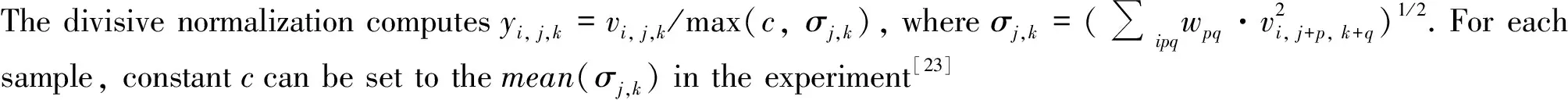
2.3 Feature pooling layer
The purpose of this layer is to build the robustness to small distortions, playing the same role as the complex cells in models of visual perception. PA(Average Pooling and Subsampling) is a simplest way to compute the average values over a neighborhood in each feature map. The average operation is sometimes replaced by a PM(Max-Pooling). The traditional deep CNN use a point-wise tanh(·) after the pooling layer, but the more recent models do not. Some deep CNNs dispense with the separate pooling layer entirely, but use strides larger than one in the filter bank layer to reduce the resolution[24]. In some recent deep versions of CNN, the pooling also pools similar feature at the same location, in addition to the same feature at nearby locations[25].
3 Deep CNN adopted to build visual awareness pathway of ABGP
An agent perceives its environment information through sensors and acts upon the environment using effectors. The way of perceiving is numerous and varied, such as vision, audition, touch, smell, etc. The vision among those perception ways significantly plays a more important role. However, the visual information in most agent models isn’t directly perceived from the natural scenes.
Therefore, our main work is introducing deep Convolutional Neural Networks as an environment visual awareness pathway into awareness module of ABGP agent model in terms of the mind mechanism of biological vision, which can not only enhance the capability of communication between the agent and the natural scenes, but also improve the ability to cognize the true world as human being.
3.1 Motivation
The awareness module in AGBP model is used to obtain, transform and transmit information from the environment. It firstly needs to convert the external original natural scenes into the identified internal signal format. From the vision theory of assembling scenes, it can be learned that a good internal representation of the natural scenes in recognition framework should be of hierarchical. So the method adopted to implement those functions should be able to represent the hierarchical features.
It is generally known that the deep Convolutional Neural Networks (CNN) consisting of the multiple trainable stages stacked on top of each other are inspired by the biological visual neural pathways. Each level being able to represent a feature hierarchy of image in deep CNN means that it is suited for the hierarchic feature representation for a natural image (Fig.2). Furthermore, the researchers in recent deep learning have proposed a series of unsupervised methods to significantly reduce the need for labeled cases, which greatly expand the deep CNN application domains. In addition, all parameters of the deep CNN as an environment visual awareness pathway can be viewed as a special internal knowledge that an agent owns to represent a cognition to the environment, which means the deep CNN is an appropriate way to implement visual awareness pathway in the ABGP model at present.
3.2 Model architecture
The cognitive model ABGP with deep CNN (ABGP-CNN) (Fig.3) proposed in this work is also one of typical agent models characterized by BDI architecture. ABGP-CNN still consists of 4 modules awareness, belief, goal and plan, and a 4-tuple
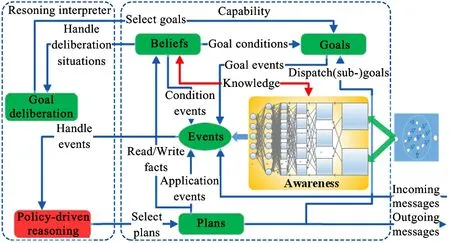
Fig.3 Cognitive ABGP-CNN model
Every internal goal action in ABGP-CNN model must be converted into an event to drive the policy-driven reasoning module. The events consist of internal events (occurrence inside an agent) and external events (incoming from external world including the natural scenes and the other agents). The goal consisted of motivation stance is a driving force for the behaviors of an agent. Unlike most traditional BDI systems, ABGP-CNN doesn’t simply view goals as a special sort of events nor assume that all adopted goals need to be consistent with each other. Because the goals in ABGP-CNN have lifecycle about themselves.
A major attraction of ABGP-CNN model is the intrinsic properties of the deep CNN, such as non-linearity, robustness and hierarchic feature representation. Those properties can be directly adopted to make up one of abilities and knowledge of a cognitive agent, and enable the agent like human to recognize the true world. Because of the introduction of the deep CNN in the awareness module, an agent based on the ABGP-CNN model needs also to accept a good learning process before cognizing the natural scenes.
3.3 Model implementation
For an agent based on the ABGP-CNN model, the learning process recognizing the natural scenes should mainly focus on how to train the deep CNN as its awareness module and how to build the appropriate belief base, goals, and plans library. Training the deep CNN includes what the multi-stage architecture is appropriate for the natural object recognition and what the learning strategy is better availability. The aim of building beliefs, goals and plans is to achieve a series of agent’s behaviors feedback according to the accepted environment information.
The implementation of ABGP-CNN model adopts a declarative and a procedural approach to define its core components awareness, belief, goal and plan as well. The awareness and plan module have to be implemented as the ordinary Java classes that extend a certain framework class, thus providing a generic access to the BDI specific facilities. The belief and goal module are specified in a so-called Agent Definition File (ADF) using an XML language (Fig.4). Within the XML agent definition files, any developer can use the valid expressions to specify any designated properties. Some other information is also stored in ADF such as default arguments for launching the agent or service descriptions for registering the agent at a directory facilitator. Moreover, awareness and plan need to be declared in ADF before they work.
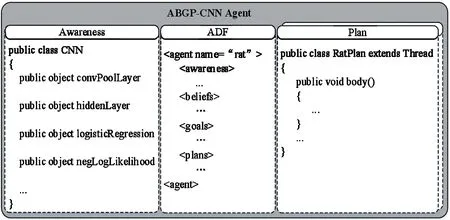
Fig.4 Composition of an ABGP-CNN Agent
Awareness is commonly viewed as an information path connecting to the environment. The ADF of ABGP-CNN provides a description of attributes for deep CNN, such as the number of CNN stages, the number of hidden layers, filter shape, pooling size, etc, which can be any kinds of ordinary Java objects contained in the awareness set as an XML tuple. Those Java objects are stored as named facts.
Beliefs are some facts known by the agent about its environment and itself, which are usually defined in ADF and accessed and modified from plans. Generally the facts can be described as an XML tuple with a name and a class through any kind of ordinary Java objects.
Goals in the real society are generally viewed as the concrete instantiations of a person’s desires. The ABGP-CNN model still follows the general idea. In particular, the ABGP-CNN model does not assume that all adopted goals need to be consistent to each other. Because the goal in the ABGP-CNN model has its own lifecycle consisting of the goal states option, active, and suspended. For the ease of usage, each goal in an ADF still is depicted in XML tuple with the flags of 4 goal styles.
Plans in ABGP-CNN model can be considered as a series of concrete actions expecting to achieve some goals or tasks. ABGP-CNN model adopts the plan-library approach to represent the plans of an agent. Each plan contains a plan head defining the circumstances under which the plan may be selected and a plan body specifying the actions to be executed. In general for reusing plans in different agents, it’s needed to decompose concrete agent functionality into the separate plan bodies, which are the predefined courses of the action implemented as Java classes.
3.4 Model execution
For a complete ABGP-CNN model, awareness, belief, goal and plan are necessary. The core of ABGP-CNN like most BDI architectures is obviously the mechanism for the plan selection. Plans in ABGP-CNN not only have to be selected for the awareness information, but also for the goals, the internal events and the incoming messages as well. Policy-driven reasoning as a specialized module in ABGP-CNN is adopted to collect all kinds of internal events and forward them to the plan selection mechanism. Of course, the other mechanisms, such as executing selected plans, keeping track of plan steps to monitor failures, are required if a complete plan process wants to be executed successfully. Algorithm 1 shows the function of those modules when they execute the interpret reasoning process.

Algorithm1Interpret⁃reasoningprocessofABGP⁃CNN Initializeagent’sstates; whilenotachievegoalsdo Deliberategoals; ifworldinformationINForincomingmessagesIME wasperceivedthen CreateinternaleventEaccordingtoINForIME; FillinternaleventEintoeventqueueEQ; end Options←OptionGenerator(EQ); SelectedOptions←Deliberate(Options); Plans←UpdatePlans(SelectedOptions) Execute(Plans); Plansdriveagent’sbehaviors; Dropsuccessfulorimpossibleplans; end
In Algorithm 1,the goals deliberation constantly triggers the awareness module to purposefully perceive the visual from the world the agent locates (extract visual information feature y:yj=gj·tanh (∑iki, j·xi), y∈D) and convert those visual information feature into the unified internal message events which are placed in the event queue (signal mapping T:D→E). According to goal events the event dispatcher continuously consumes the events from the event queue (corresponds to the OptionGenerator(EQ) function) and deliberates the events satisfying the goals (like Deliberate(Options)function). Policy-driven reasoning module builds the applicable plan library for each selected event (similar to the UpdatePlans(SelectedOptions) operation). In the Execute(Plans) step Plan module in Fig.3 will select plans from the plan library and execute them by possibly utilizing the meta-level reasoning facilities.Considering the competition among the multiple plans, the user-defined meta-level reasoner will rank the plan candidates according to the priority of plans. The execution of plans is done stepwise, and directly drives the agent’s external and internal behavior. Each circulation of goal deliberation will be followed by a so-called site-clearing work that means some successful or impossible plans will be dropped.
4 ABGP-CNN model applied in rat-robot maze search
An actual simulation application of the rat-robot maze search (Fig.5) will be provided here in order to significantly demonstrate the feasibility and the validity of ABGP-CNN. The following will mainly represent the actual design of the rat-robot agent and the environment agent based on the ABGP-CNN model in the simulation experiment and proves that why the CNN is better for the awareness module.
4.1 Design of agents in rat-robot maze search
In the maze search, there exist two types of agents, ie. the rat-robot agent and the environment agent. The task of the rat-robot agent is to start moving at the maze entrance, and finally reach the maze exit denoted as a red flag depended on guideposts in Fig.5. In order to fulfill the maze search task, the composition of the rat-robot agent should implement all the four basic modules, < awareness>,
Compared with the rat-robot agent, the configuration of the environment agent is simpler. Its belief base just contains a maze map and a specification about the guideposts as shown in Fig.5. It is not only required to deploy awareness module, but also needs a maintain goal to keep the life circle of displaying maze map. Moreover, the environment agent has a creating plan to create the maze map and the specification.

Fig.5 Rat-robot maze search
4.2 Performance evaluation of ABGP-CNN model in rat-robot maze search
In the rat-robot maze search experiment, the rat-robot agent is designed to have 4 basic behaviors including moving on, moving back, turning left and turning right in the maze. Therefore, a sub-MNIST dataset is constructed, called mnist0_3, extracting 4 types of handwritten digits with flag ‘0’ denoting moving on, ‘1’ moving back, ‘2’ turning left and ‘3’ turning right from the original MNIST dataset. The dataset mnist0_3 consists of 20679 training samples, 4075 validating samples and 4257 testing samples.
A successful maze search activity in Fig.5 is defined as the rat-robot agent starting from the maze entrance and successfully reaching the maze exit marked as a flag. In the moving process, the rat-robot agent is guided by the guideposts in the path, its search behavior will be considered as the failure if it incorrectly recognize one of guideposts in the moving path. There are 32 guideposts in the maze path shown in Fig.5, which means that the rat-robot agent who wants to successfully complete a maze search will correctly recognize the 32 guideposts in one maze search behavior. Obviously, the performance validation of the deep CNN turns into the recognition rate of a sequence of length 32. Therefore a little change will be made to the test set in mnist0_3. A series of sequences, shown in Fig.6, are constructed based on the test set from mnist0_3. Each row with the length of 32 in Fig.6 is a sequence with the structure [2,0,3,3,0,2,2,0,3,2,3,2,1,2,3,0,3,2,2,3,2,3,3, 1,3,2,2,1,2,2,0,3] orderly corresponding to all the guideposts in the maze path. The guideposts with the same value in each column in Fig.6 are randomly selected from the test set in mnist0_3. A new test set with the size of 10000 sequences is constructed according to the above principle.

Fig.6 10 Guideposts sequence test set
The original ABGP model have developed a complete goal pursuit, event responding and action planning in its internal world. Those mechanisms are executed accurately in terms of the belief knowledge base and the information from environment. The performance of the agent’s action planning is primarily decided by the information from the environment if the belief knowledge is represented definitely. It is clear that the belief knowledge in the maze search experiment is precisely represented as ‘0’ denoting moving on, ‘1’ moving back, ‘2’ turning left and ‘3’ turning right.
In order to prove the performance of ABGP-CNN model, the other two methods, multi-layer perceptron (MLP) and support vector machine (SVM), are respectively used for awareness module of ABGP to construct two different comparison models ABGP with awareness MLP (ABGP-MLP) and ABGP with awareness SVM (ABGP-SVM). For ABGP-MLP, the MLP is designed to a common neural network having 3 hidden layers with the activation function tanh(·) and a logistic regression output layer. For the SVM structure in ABGP-SVM, the 4 types of kernel functions, linear uT*v, polynomial γ*uT*v+c, radial basis function e-γ*|u-v|2and sigmoid tanh(γ*uT*v+c), are adopted to construct 4 different types of SVMs. Table 1 shows the success rate that the agents designed by ABGP model with 3 different awareness modules can recognize all guideposts in the maze path.
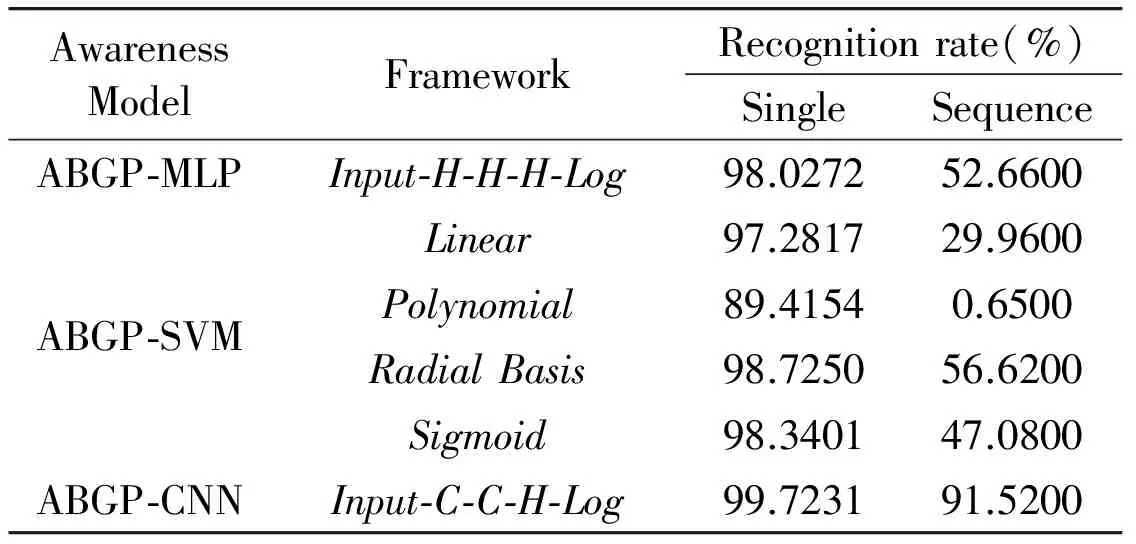
Table 1 Recognition rate of MLP, SVM, CNN as the awareness modulein ABGP for 10000 guidepost sequences
In Table 1, Input-C-C-H-Log means the deep CNN has double convolutional layers C, a hidden layer H and a logistic regression output layer Log. It is not hard to see there exists the similar hierarchy for awareness module MLP and CNN. Table1 shows that ABGP-MLP, ABGP-SVM and ABGP-CNN keep the high recognition rate for single guidepost, and ABGP-CNN has the highest recognition rate among them. However, for recognizing the sequence ABGP-CNN behaves the excellent performance of 91.52% compared with ABGP-MLP, ABGP-SVM. In particular, though there is a similar awareness module structure for ABGP-MLP and ABGP-CNN, the performance of ABGP-CNN on the sequence is significantly better than ABGP-MLP.
Therefore the rat-robot agent based on ABGP-CNN model most easily passes through the maze from the entrance to the exit. That is the reason why the deep CNN with the excellent performance recognizing the guidepost sequences is better for the awareness module of ABGP besides its architecture inspired by biological visual.
5 Conclusion and future work
Inspired by the biological visual theory, a novel cognitive model, ABGP-CNN is proposed, with BDI architecture by introducing the deep CNN as a visual pathway into the awareness module of cognitive model ABGP, and applying it to the rat-robot maze search. The awareness module based on deep CNN can directly recognize the guideposts in natural scenes and accurately conduct the rat-robot agent’s behaviors, which enhances the capability of communication between the agent and the natural scenes, and improves the visual cognitive ability as human being to the true world. For future work, the ABGP-CNN model will be applied to the true world by the actual robot, and an appropriate guidepost database adopted to train the ABGP-CNN agent will be constructed. In addition, the learning algorithms of the agent and some better awareness structures for the different natural scenes will be the research focus as well in the future.
[ 1] Bratman M E. Intention, Plans, and Practical Reason. Massachusetts: Harvard University Press, 1987. 124-136
[ 2] Rao A S, Georgeff M P. BDI Agents: From theory to practice. In: Proceedings of the 1st International Conference on Multi-Agent Systems, Menlo Park, USA, 1995. 312-319
[ 3] Shoham Y. Agent-oriented programming. Artificial Intelligence, 1993, 60(1): 51-92
[ 4] Lehman J F, Laird J E, Rosenbloom P. A gentle introduction to soar, an architecture for human cognition. Invitation to Cognitive Science, 1996, 4: 212-249
[ 5] Hindriks K V, De Boer F S, Van der Hoek W, et al. Agent programming in 3apl. Autonomous Agents and Multi-Agent Systems, 1999, 2(4): 357-401
[ 6] Shi Z Z, Zhang J H, Yue J P, et al. A cognitive model for multi-agent collaboration. International Journal of Intelligence Science, 2013, 4(1): 1-6
[ 7] Niell C. Cell types, circuits, and receptive fields in the mouse visual cortex. Annual review of neuroscience, 2015, 38: 413-431
[ 8] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In: Proceedings of Advances in Neural Information Processing Systems, Lake Tahoe, USA, 2012. 1097-1105
[ 9] LeCun Y, Kavukcuoglu K, Farabet C. Convolutional networks and applications in vision. In: Proceedings of 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 2010. 253-256
[10] Shi Z Z, Wang X F, Yue J P. Cognitive cycle in mind model CAM. International Journal of Intelligence Science, 2011, 1(2): 25-34
[11] Pokahr A, Braubach L. The active components approach for distributed systems development. International Journal of Parallel, Emergent and Distributed Systems, 2013, 28(4): 321-369
[12] Korecko S, Herich T, Sobota B. JBdiEmo-OCC model based emotional engine for Jadex BDI agent system. In: Proceedings of the IEEE International Symposium on Applied Machine Intelligence and Informatics, Herl’any, Slovakia, 2014. 299-304
[13] Visser S, Thangarajah J, Harland J, et al. Preference-based reasoning in BDI agent systems. Autonomous Agents and Multi-Agent Systems, 2015, 30(291): 1-40
[14] Pokahr A, Braubach L, Haubeck C, et al. Programming BDI Agents with Pure Java. Germany: Springer International Publishing, 2014. 216-233
[15] Kephart J O, Walsh W E. An artificial intelligence perspective on autonomic computing policies. In: Proceedings of the 5th IEEE International Workshop on Policies for Distributed Systems and Networks, New York, USA, 2004. 3-12
[16] Namboodiri V M K, Huertas M A, Monk K J, et al. Visually cued action timing in the primary visual cortex. Neuron, 2015, 86(1): 319-330
[17] Fukushima K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 1980, 36(4): 193-202
[18] Hinton G, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural computation, 2006, 18(7): 1527-1554
[19] Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Ohio, USA, 2014. 1725-1732
[20] Ciresan D C, Meier U, Masci J, et al. Flexible, high performance convolutional neural networks for image classification. In: Proceedings of International Joint Conference on Artificial Intelligence, Barcelona, Spain, 2011. 1237-1242
[21] Ciresan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, USA, 2012. 3642-3649
[22] Jarrett K, Kavukcuoglu K, Ranzato M, et al. What is the best multi-stage architecture for object recognition? In: Proceedings of the IEEE 12th International Conference on Computer Vision,Kyoto, Japan, 2009. 2146-2153
[23] Khan A M, Rajpoot N, Treanor D, et al. A nonlinear mapping approach to stain normalization in digital histopathology images using image-specific color deconvolution. IEEE Transactions on Biomedical Engineering, 2014, 61(6): 1729-1738
[24] Simard P Y, Steinkraus D, Platt J C. Best practices for convolutional neural networks applied to visual document analysis. In: Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, USA, 2013. 958-958
[25] Bo L, Ren X, Fox D. Learning hierarchical sparse features for RGB-(D) object recognition. The International Journal of Robotics Research, 2014, 33(4): 581-599
Ma Gang, born in 1986. He is studying for a Ph.D degree in Computer Software and Theory in Institute of Computing Technology, Chinese Academy of Sciences. He received his B.S. degree in Computer Science and Technology and M.S. degree in Computer Application Technology from China University of Mining and Technology in 2010 and 2013, respectively. His research interests include artificial intelligence, machine learning, deep learning and complex networks.
10.3772/j.issn.1006-6748.2016.04.008
① Supported by the National Basic Research Program of China (No. 2013CB329502), the National Natural Science Foundation of China (No. 61035003, 61202212) and the National Science and Technology Support Program (No. 2012BA107B02).
② To whom correspondence should be addressed. E-mail: mag@ics.ict.ac.cn Received on Aug. 10, 2015
杂志排行

High Technology Letters的其它文章
- Research of refrigeration system for a new type of constant temperature hydraulic tank①
- Integration of naval distributed tactical training simulation system based on advanced message queuing protocol①
- Measurements and analysis at 400MHz and 2600MHz in corridor radio channel①
- Clustering approach based on hierarchical expansion for community detection of scientific collaboration network①
- Fluid simulation of internal leakage for continuous rotary electro-hydraulic servo motor①
- Fuzzy image restoration using modulation transfer function①