基于改进的K-means算法在高校学生消费数据中的应用
2016-12-28马幸飞李引
马幸飞,李引
(无锡商业职业技术学院教育信息化中心,江苏无锡 214153)
基于改进的K-means算法在高校学生消费数据中的应用
马幸飞,李引
(无锡商业职业技术学院教育信息化中心,江苏无锡 214153)
校园一卡通系统作为数字化校园建设的重要组成部分,集多种功能为一体,并代替传统的消费管理模式,能更好处理噪声和孤立点。文章采用新距离标准的K-均值算法对学生三餐消费、商铺营业等情况进行聚类分析,并将结果应用于校内贫困生的评定工作及经营单位的产品、服务定位。
校园一卡通;数据挖掘;聚类分析;新距离标准;K-均值算法
随着校园信息化建设进程的不断发展,校园一卡通系统在高校中的应用越来越成熟,数字化校园建设日益完善。“校园一卡通”[1]基于一个数据中心集中存放所有数据,实现数据整合、信息共享及资源的综合利用,同时为高校人员提供具有开放性、灵活性的管理平台。
目前校园一卡通所覆盖的校园业务非常广泛,包括食堂消费、超市消费、医疗消费、洗浴消费、水果休闲吧消费、图书借阅等。其中食堂消费数据最稳定、准确、全面,能够很好地反映大学生在校的消费行为。一卡通消费数据均为流水数据,记录学生在校的每一笔消费。这些流水数据,不仅提供了学生消费行为特征,而且反映了经营单位的营业状况。
一、数据挖掘技术
数据挖掘[2-4]是一门新兴的交叉学科,从广义上讲,数据挖掘是指从大量的、不完全的、有噪声的、模糊的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又具有潜在使用价值的信息和知识的过程。狭义上的数据挖掘是知识发现过程中的一个步骤,即利用分析工具发现模式的子过程。按照挖掘的知识类型分类,数据挖掘可分为特征规则挖掘、聚类规则挖掘、关联规则挖掘等。
二、聚类分析
聚类分析[5]作为数据挖掘技术中的重要方法,是将数据对象按相似性标准划分到不同的类或者簇的过程,使得属于同类别的数据相似度尽量高,而不同类别的数据差异性尽量大。聚类分析是一个无监督的学习过程,它不仅是数据挖掘的一项独立工具,也是其他知识发现算法的预处理基础。聚类分析已经广泛应用于多个领域,包括市场营销、图像处理、模式识别等,目前学者和专家提出了众多的、典型的算法。例如:基于距离的K-均值和K-中心聚类算法;基于层次的凝聚和分裂算法;基于密度的DBSCAN算法;基于网格的STING 和CLIQUE算法等,各个独立的算法都有其代表性。但到目前为止,仍然没有一个通用算法,能够同时包含超强的聚类能力、超高的执行效率和简单的参数设置等优势。因此一般情况下,学者们会根据数据类型、簇形、噪声、孤立点、高低纬度等提出不同的聚类算法,使得算法具有可伸缩性、可用性、可解释性等特点。
(一)K-均值聚类算法
k-均值,也被称为硬C-均值聚类算法[6],是一种基于距离的划分聚类算法,目前已在多个领域广泛使用。K-均值算法的基本原则是:对于给定的数据对象集X,以数据对象到聚类中心点的距离和作为聚类准则函数,通过求准则函数的极小值方法进行迭代,把数据对象划分到聚类个数为c的类中,并使得每个类内部的数据对象相似程度最大,而不同类的数据对象不相关程度最大。
(二)基于新距离的K-均值聚类算法
在基本的K-均值聚类算法的平方误差和准则函数中运用了欧氏距离,使得其聚类过程会受到噪声、孤立点数据的影响。使用已给出的一种新距离度量标准取代欧氏距离,应用在K-均值聚类算法中,能够适应噪声和孤立点的处理,具有较强的鲁棒性特性,提高了整个聚类性能。
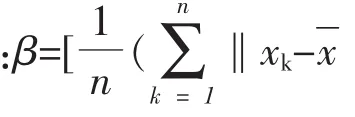

使得新目标函数达到最小的必要条件是其中心向量公式更新为:
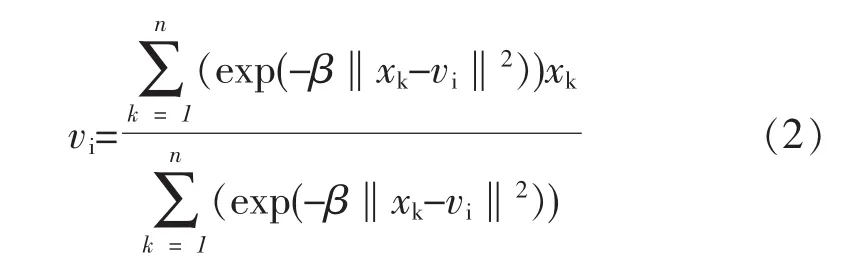
通过相关的仿真实验证明:不同于基本HCM聚类算法,AHCM聚类算法对处理具有不同大小和密度的图形或有噪声存在的环境数据,有较小的误差。
三、实验与结论
(一)校园消费数据预处理
学生在校消费的特点存在实时性、冗余性,而且易使校园一卡通消费数据大量存储在数据库中,长期积累下来,这些数据往往是含噪声、空值、孤立点等,不适合直接进行数据分析,挖掘内部规则,需要对原始数据进行选择、清洗、转换等预处理来保证数据的准确和完整。
一卡通消费数据均为流水数据,实时记录学生在校的每一笔消费,包括学生学号、姓名、消费日期、当前消费金额、消费类型、消费档口名称等信息。以无锡商业职业技术学院为例,校园一卡通后台程序代码运行在校内虚拟服务器的Oracle数据库上,每天产生的实时数据量达到十万以上。因此为了得到一个好的聚类结果,针对流水数据选择能够反映学生消费行为特征的关键字段作为原始数据,同时可以设置数据的时间等约束条件。
(二)新算法应用到高校学生消费数据中的结果对比与分析
本实验采用的软件环境:开发平台使用Matlab7.9,在Windows8操作系统下完成。硬件环境:CPU Inter(R)Core(TM)i5-4570,4GB内存。
本论文的实验数据集来源于无锡商业职业技术学院一卡通数据平台,其中学生三餐消费数据以数字媒体学院14级学生的3月份早、中、晚餐消费情况为研究样本,校内商铺营业数据以全校师生的3月、11月、12月的消费情况为研究样本。具体实验参数设置如表1所示。
仿真实验一,用学生三餐消费数据集比较两种算法(K-均值算法、改进的K-均值算法)在聚类上的性能,其中目标函数分别选用公式(1)和(3),各运行100次,实验结果取目标函数、类内距离及运行时间三项指标的平均值,所得的结果如表2所示。
从表2可以看出:数字媒体学院2014级学生三餐消费数据使用新距离标准进行聚类,相较于基本K-均值算法得出的目标函数值小,且聚类之间差异性较大;两种算法收敛速度都很快,能达到相同的量级。

表1 实验数据集简单描述及参数设置

表2 数字媒体学院2014级学生三餐消费数据的聚类结果对比
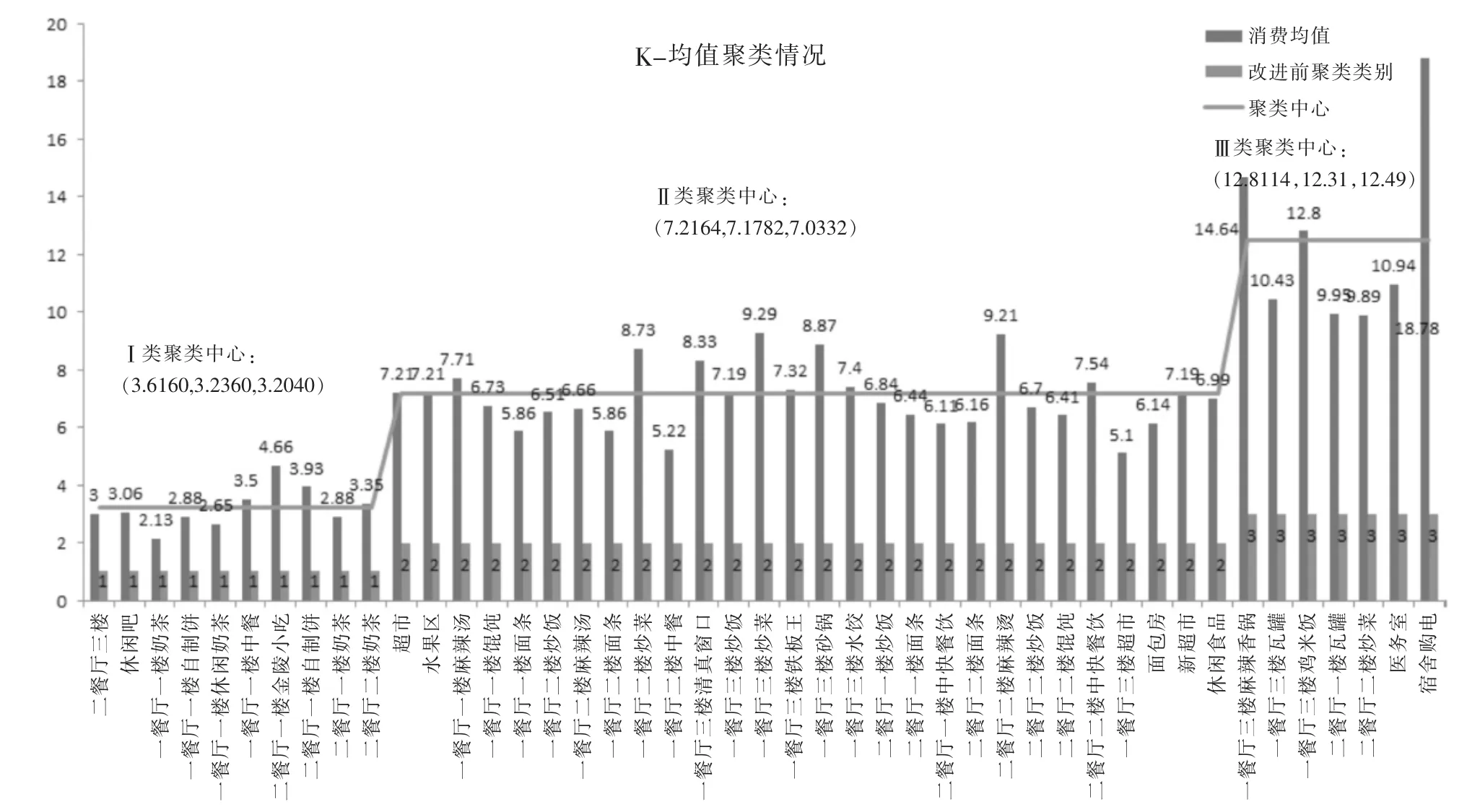
图1 校内商铺营业数据聚类结果比较
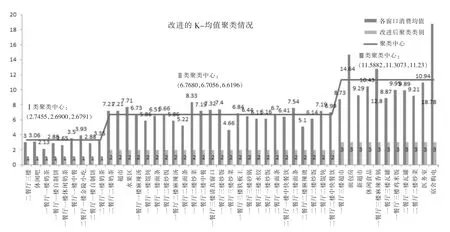
图2 校内商铺营业数据改进的聚类结果分析
改进的K-均值算法把学生三餐消费分成五类时,付出的时间代价不高,得到的聚类中心也最符合实际。将此聚类效果应用于数字媒体学院2014级的贫困生评定工作,如果某学生的早、中、晚餐消费均值金额分别为4.63元、6.88元、4.29元,与聚类中心最低类(3.5438,7.3606,4.9365)距离最近,那么该学生可评定为特困生。因此,聚类效果可以为相关部门学生资助工作提供决策依据,并实现有效监管。
仿真实验二,两种算法应用于校内商铺营业数据集,其聚类结果比较如图1所示。
从图1、图2可以看出:各算法所得出的聚类中心点代表该类别商铺营业的均值水平,其中改进的K-均值聚类中心较符合实际情况。如一餐厅三楼炒菜、砂锅,二餐厅二楼麻辣烫三个窗口的消费均值分别为9.29元、8.87元及9.21元,这三个窗口归类于高消费窗口较为合适。
四、结论
在基本K-均值算法中,新的度量标准取代欧几里得标准,仿真实验证明新度量标准的健壮性。本文基于高校学生消费数据,利用数据挖掘技术,对消费群体进行聚类分析,将结果应用于校内贫困生的评定工作,为相关部门提供学生资助的辅助管理决策依据,实现有效监管。同时,依据各商铺的营业月均值数据,分析各商铺窗口的营业状况,帮助商铺合理定位,为提高服务质量提供数据依据。
[1]刘志龙.校园一卡通数据分析系统的设计与实现[D].上海:华东师范大学,2007.
[2]Jiawei Han,Micheline Kamber.Data Mining:Concepts and Techniques[M].Morgan Kaufmann Publishers,2007.
[3]梁循.数据挖掘算法与应用[M].北京:北京大学出版社,2006.
[4]朱明.数据挖掘[M].合肥:中国科学技术大学出版社,2008.
[5]Everitt B.,Landau S.,Leesse M.Cluster Analysis[M]. London,2001.
[6]Sulaiman,S.N Adaptive fuzzy-K-means clustering algorithmforimagesegemen-tation[C].IEEE Transactions on Consumer Elect-ronics,2010(4):2661-2668.
[7]Wu Kuo-lung,YangMiinshen.Alternative c-means clustering algorithms[J].Pattern Recognition,2002(35):2267-2278.
(编辑:林钢)
Application of Campus card Consumption data based on Improved K-means Algorithm
MA Xing-feiLI Yin
(Educational Informatization Centre,Wuxi Institute of Commerce,Wuxi 214153,china)
As an important part of digital urban construction,campus card system is more and more to a wide range,through the effective integration of various resources.It has replaced the traditional consumption management pattern.The paper proposes a novel K-means clustering algorithm based on a new metric,which canθenhance the ability of dealing with the abnormal data.This algorithm has been adopted in analysis of students'consuming data and business data.It can provide scientific and effective data in proverty stricken students'assessment system and the product orientation process.
campus card system;Data mining;cluster analysis;a new metric;K-means clustering algorithm
G 647.4
A
1671-4806(2016)06-0082-04
2016-10-10
无锡商业职业技术学院教科研课题(SYKJ15B13)
马幸飞(1982—),男,江苏宜兴人,助理实验师,研究方向计算机系统设计、信息化管理;李引(1987—),女,安徽砀山人,助理实验师,硕士,研究方向计算机系统设计、数据分析。
