基于排队论的交易系统时延分析
2016-12-26黄寅飞
黄寅飞 王 泊 白 硕
(上海证券交易所技术开发部 上海 200120)
基于排队论的交易系统时延分析
黄寅飞 王 泊 白 硕
(上海证券交易所技术开发部 上海 200120)
低延迟是证券交易系统从小型机迁移到PC服务器过程中的主要挑战,为此需要进行时延度量和分析。首先设计实现基于Redis和Python的时延数据采集监控框架。其次提出队列级联方法,分析分布式系统时延构成。最后通过参数试验和数据分析,找到令吞吐量和时延最优的配置方法,并分析解决可扩展性和毛刺问题。将分布式系统建模为级联队列,在此基础上通过量化分析、性能调优和流控保护等手段,令时延指标显著提升。所提出的队列级联方法可为企业级关键业务实时系统的设计和调优提供参考。
时延度量 监控框架 低延迟 证券交易系统
0 引 言
轻便高效交易系统LTP(Light Trading Platform)是国家科技支撑计划《证券核心交易系统研发》课题(2012BAH13F04)的交付成果,于2015年4月通过国家验收,达到吞吐量10万笔/秒、交易时延小于1毫秒的技术指标。LTP基于PC服务器集群搭建,选用Linux操作系统(RHEL 6.3,64位)。LTP引入内存复制技术,在保证高吞吐和高可用性的基础上,时延指标相比现有系统[1]提升两个数量级。
本文建立交易时延模型,设计监控架构采集时延数据,在排队论基础上提出队列级联方法,以指导吞吐量和时延指标调优。
1 技术架构
证券处理的全业务流程如图1所示。LTP关注的是业务流程中由交易所负责的部分,重点解决实时撮合处理的时延和吞吐量问题。LTP架构如图2所示,主要包括通信网关CS和交易主机TC两块内容。LTP集成基于TCP协议的ZeroMQ消息中间件[2]作为通信层,以实现多对多的广播订阅通信方式。集群主机按照产品集合SET进行分区,以支持水平扩展。

图1 证券处理业务流程示意图
图2中,CS上robot 进程负责模拟报单。TC上router 进程负责消息路由,matcher进程负责撮合处理,main为主撮合线程,csq为定序线程。从业务逻辑出发,也称CS为报盘机,TC为撮合器。TC构成集群,基于Paxos算法[3]实现主备机订单序号同步。
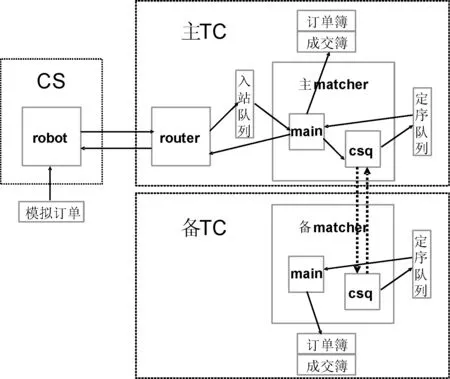
图2 LTP进程通信数据流图
LTP监控架构与交易架构通过libmoni监控探针库以低耦合方式相连接,见图3所示。每台TC和CS上均安装有Redis数据库[4],用以存放实时监控数据。监控主机上开发有PyShow监控工具包,通过 Redis客户端离线抓取各台主机的监控数据。使用NumPy库[5]在内存中整合形成矩阵以利高速处理,使用Pickle库持久化以便数据重用,使用MatplotLib库进行可视化展示。
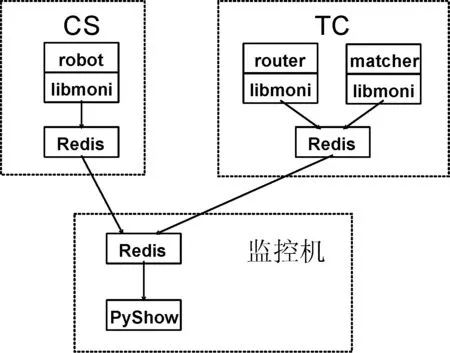
图3 LTP监控架构图
2 时延建模
2.1 时延定义
交易时延指的是交易订单从发出到收到响应之间的时间间隔。参照Cinobber公司白皮书[6],定义端到端、门到门和撮合器三个时延指标,见图4所示。交易所关注的交易时延指的是门到门时延,即消息从CS到TC再回到CS的处理时延[7]。
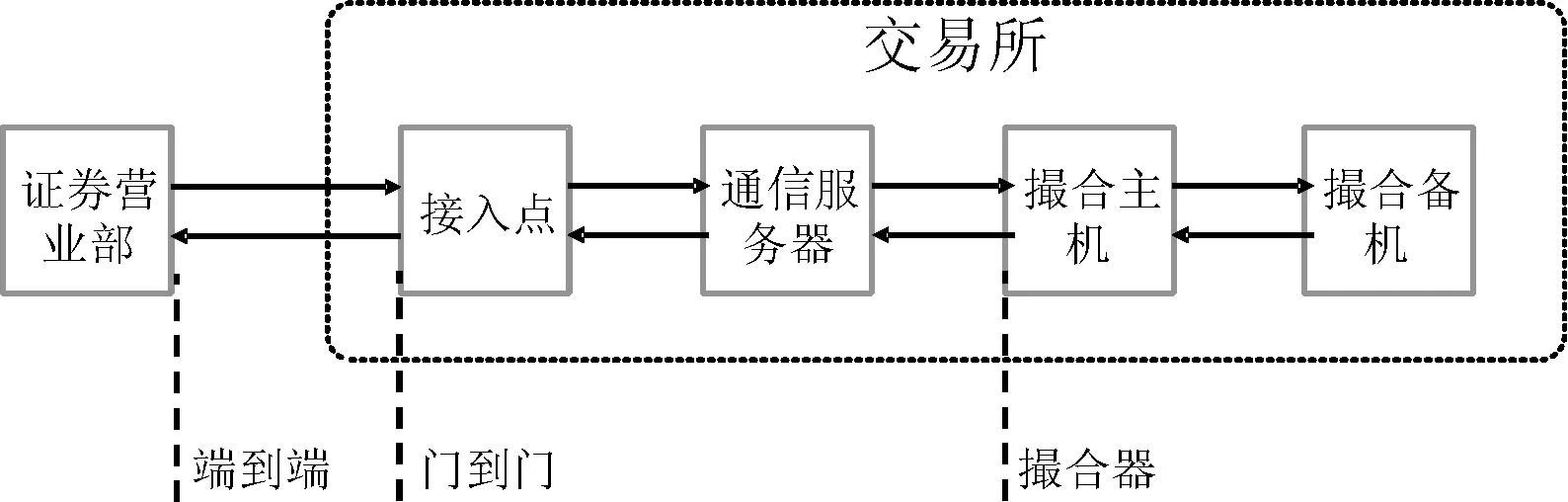
图4 时延指标定义
为进一步分析交易时延构成,设置N个采样点t0,t1,…,tN-1,定义分段时延:
Ti,j=tj-ti
(1)
特别地,定义:
Ti=ti-ti-1
(2)
交易时延构成如下:
T0,N-1=T1+T2+…+TN-1
(3)
2.2 时延模型
LTP系统中订单生命周期如图5所示。设置8个采样点,其中T1、T7为CS到TC间网络时延,T2、T6为router到matcher 进程间通信时延,T3为主备机定序时延(包含两跳网络时延),T4为撮合器中csq 到main线程间排队时延,T5为撮合业务处理时延。LTP交易时延为:
T0,7=T1+T2+…+T7
(4)
因t0、t7采样点位于CS主机,t1到t6采样点位于TC主机,不同主机上的时钟难以做到微秒级同步[8]。T1、T7两段时延无法直接计算,而需采用间接计算公式,如下:
(5)
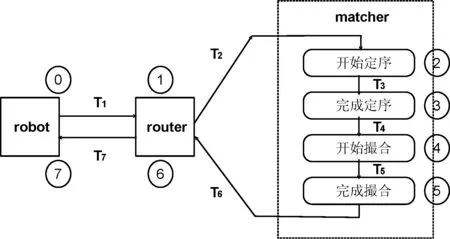
图5 LTP订单生命周期图
2.3 队列级联方法
单个撮合器对应单服务窗口的排队系统,订单依次进入撮合器的过程为一个排队过程。订单进入撮合器的事件流为泊松流,具备平稳性、无后效性和普通性[9]。

多报单机、多撮合器对应多事件流、多服务窗口的排队系统。设报单机总数为m,主撮合器总数(即SET数)为n。每个报单机向n个撮合器发送订单,每个撮合器接收来自m个报单机的订单。每个报单机承担的事件流强度为λ×n,每个撮合器承担的事件流强度为λ×m。
针对系统中包含多个队列的情况,提出队列级联方法。将分布式系统视作若干队列组的串联,其中每个队列组又可由多个并联的队列组成。为保证平稳服务,可设定系统负荷水平ρ(通常在0.5到0.6之间)。根据队列级联关系,计算所有队列的服务能力并取最小值,即为整个系统能稳定支持的最大事件流强度。
以CS、TC多对多关联构成的系统为例,包含两个排队点:CS发送队列、TC撮合队列。设报单机服务能力为μ0,撮合器服务能力为μ1。有如下公式:
(6)
(7)
综合考虑报盘机和撮合器的服务能力,取事件流强度为min(λ0,λ1)可获得吞吐量和时延的最优配置。
2.4 试验设计
交易时延由通信时延、排队时延和处理时延三部分构成,其中排队时延受吞吐量影响最大,且二者关系并非线性关系。当吞吐量接近服务处理能力时,排队时延将指数增长。
针对排队模型中的事件流和服务窗调整参数,试验不同的模型组合,找到系统中的不变量和随事件流变化的变量。根据试验结果,进一步细化模型,给出令时延最优和吞吐量可扩展的配置策略。
3 试验与分析
3.1 环境准备
试验环境为千兆以太网,三台CS为HP DL380p(PC服务器,32核,128 GB内存),四台TC为IBM x3850(PC服务器,64核,128 GB内存)。设置8个SET,采取一主两备配置,每台TC上部署2个主SET、4个备SET。实际试验可选取主机和SET的子集,如表1所示。
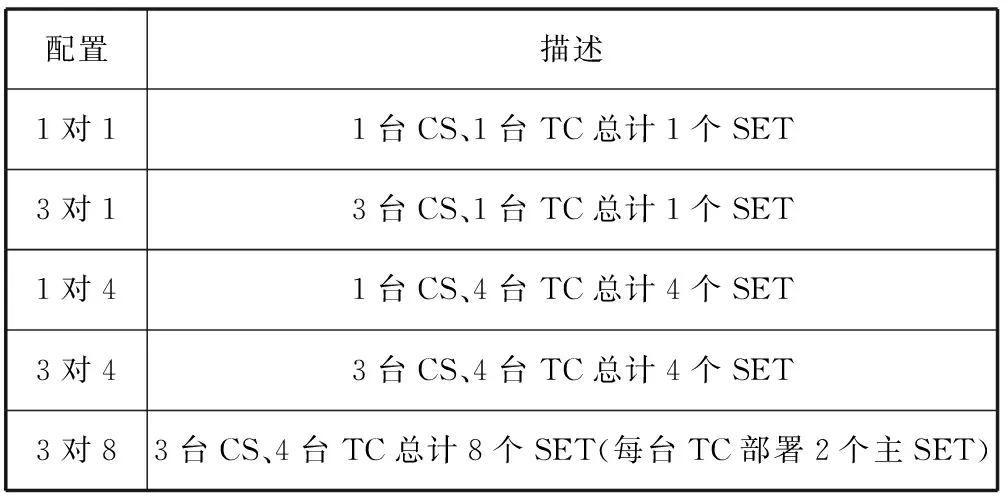
表1 环境配置表
为接近真实场景,使用工具生成由100万账户和100支产品构成的一亿条模拟持仓。使用工具围绕40支产品和1万账户生成480万条模拟订单,每台CS对每个SET准备20万条订单。订单价格和数量字段随机生成。订单消息长度为154字节。CS采取匀速报单方式,每隔固定间隔向TC发送1笔订单。
3.2 模型试验
分别使用1对1、3对1、1对4和3对4配置,试验系统的服务能力,以及不同事件流强度下的性能表现,结果见表2至表5所示。表中λ用报单间隔推算,μ用处理时延推算。吞吐量取单个CS到所有SET的吞吐量总和。
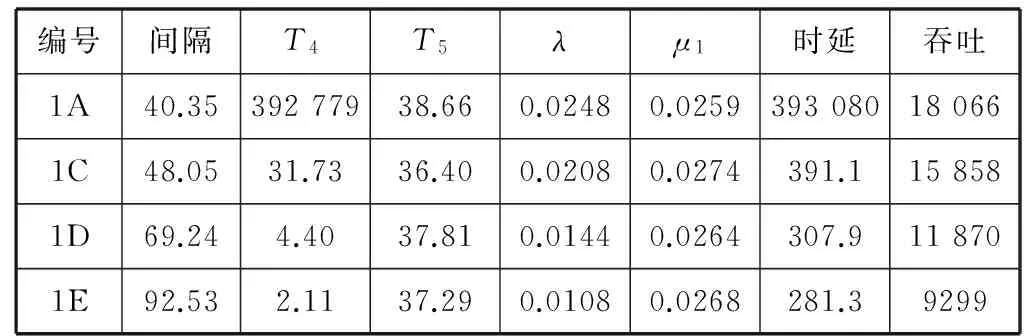
表2 模型参数:1对1事件流

表3 模型参数:3对1事件流
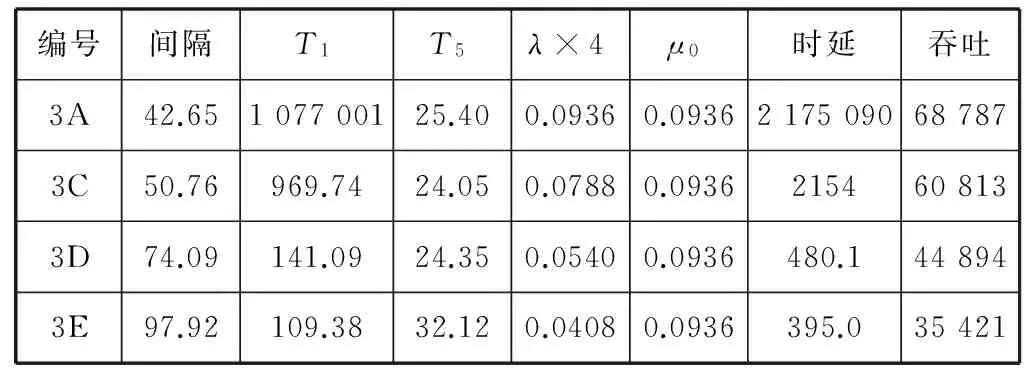
表4 模型参数:1对4事件流
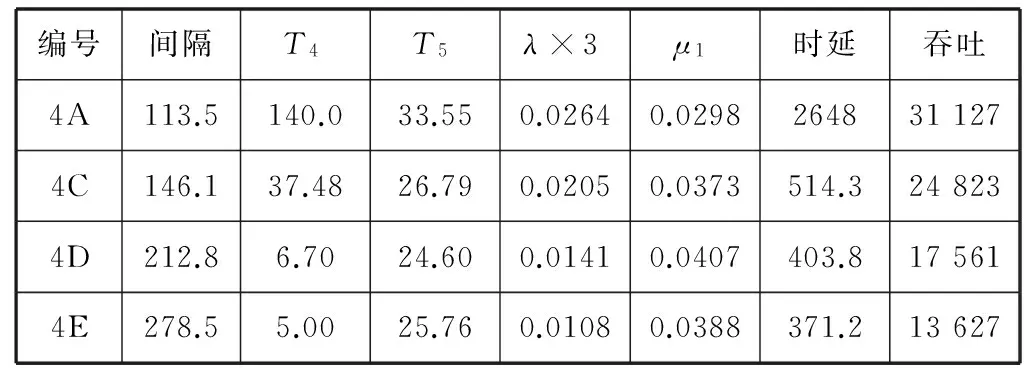
表5 模型参数:3对4事件流
通常起作用的是TC撮合队列,对应于撮合器服务能力μ1,排队时延取T4,处理时延取T5。1对4场景比较特殊,起作用的是CS发送队列,因此表4中取报盘机服务能力μ0,排队时延改取T1。μ0通过临界点时的事件流强度推算。
3对8环境采用增加进程的办法增加服务窗口。在单台主机上部署多个撮合进程,可充分利用多核计算优势,在基础时延少量升高的同时令系统整体吞吐量翻倍,见表6所示。
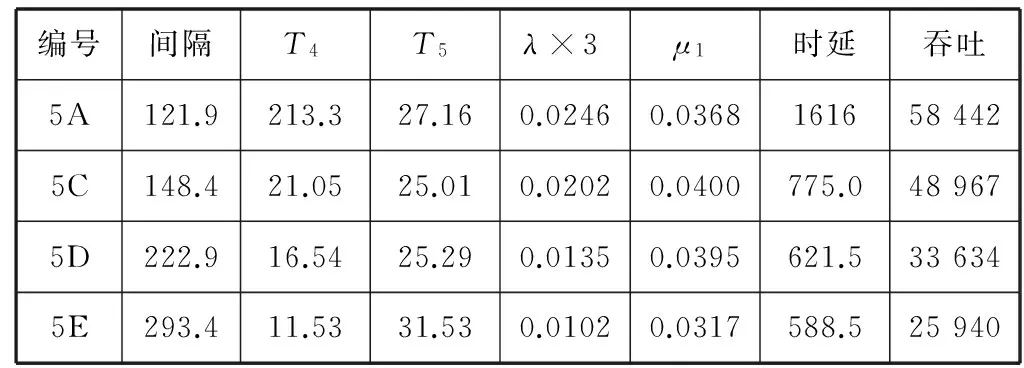
表6 模型参数:3对8事件流
3.3 数据分析
3.3.1 时延折线图
综合不同配置下的λ和排队时延间变化关系绘制折线图,见图6所示。从变化曲线可以看到,一开始时延随着λ增大而缓慢增加,当λ达到特定拐点后时延会迅速上升,最终在λ趋近于临界点μ时趋向无穷大。其中1v4曲线临界点为μ0/4, 其他曲线临界点为μ1。
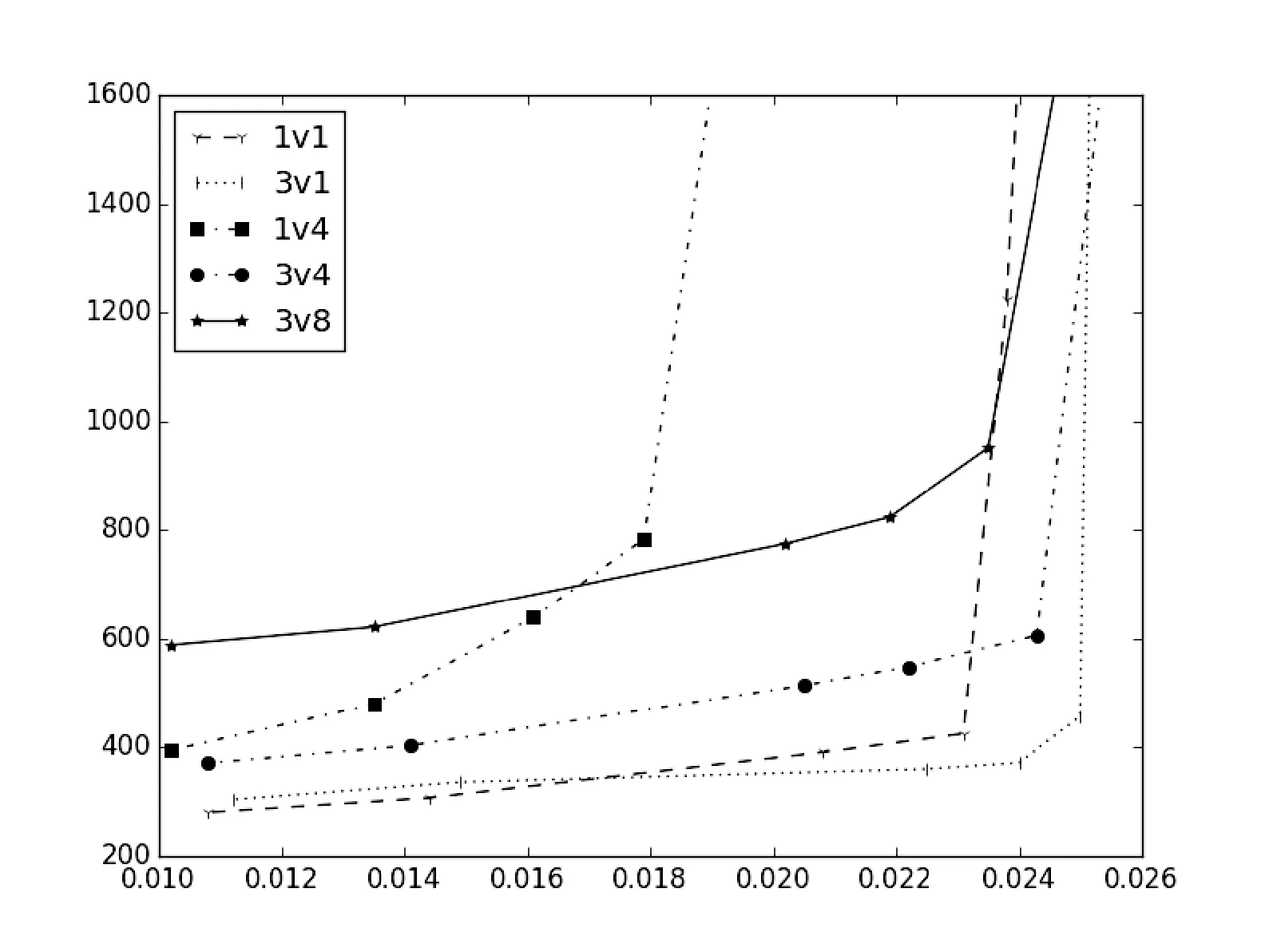
图6 时延折线图
可以看到,1v1曲线、3v1曲线拐点出现在ρ=0.9左右位置,且拐点处曲线变化陡峭;而3v4、3v8曲线拐点出现在ρ=0.7左右位置,且曲线变化较为平滑。随着服务窗口增加,一方面基础时延会增加,另一方面时延拐点会前移。
3.3.2 可扩展性分析
代码不变,队列μ值固定,从而决定了在该点的λ-时延曲线。在此基础上可通过增加事件流和增加服务窗口来提升系统的整体吞吐量。
对比表4和表5数据可以看到,扩展CS主机个数可用来增加事件流强度,以突破CS发送队列瓶颈的束缚。1对4场景下,吞吐量受限于μ0参数,为 44 894笔/秒(用例3D,ρ=0.58)。3对4场景下,单CS吞吐量为24 823笔/秒(用例4C,ρ=0.55),整体吞吐量最大达到74 469笔/秒。吞吐量提升65.9%,代价是时延指标微降6.6%。
对比表2和表3数据,当系统瓶颈不在CS发送队列时,扩展CS主机个数也能带来一定收益。1对1场景下吞吐量为11 870笔/秒(用例1D,ρ=0.55),3对1场景下单CS吞吐量为4610笔/秒(用例2D,ρ=0.57),整体吞吐量为13 830笔/秒。吞吐量提升16.5%,代价是时延指标降低8.5%。
对比表3和表5数据可以看到,扩展TC主机个数可用来增加服务窗口,以突破TC撮合队列瓶颈的束缚。3对1场景下整体吞吐量为13 830笔/秒(用例2D),3对4场景下整体吞吐量为74 469笔/秒(用例4C)。吞吐量提升5.38倍,代价是时延指标降低34.6%。注意到撮合器服务能力μ1在不同场景下存在差异。
对比表5和表6数据可以看到,扩展撮合进程个数可用来增加服务窗口。3对4场景下整体吞吐量为74 469笔/秒(用例4C),3对8场景中单场景下单CS吞吐量为48 967笔/秒(用例5C,ρ=0.51),整体吞吐量为146 901笔/秒。吞吐量提升1.97倍,代价是时延指标降低33.6%。
系统瓶颈主要在撮合器服务能力,通过增加TC主机和撮合器进程个数,可以线性提升整体吞吐量,但会损失一定的时延性能。
3.3.3 毛刺分析
3对8场景,输入480万条订单,打单时长约31秒。取从CS1到SET1的数据进行分析,λ×3为0.0214,μ1为0.0350,ρ为0.61。整体吞吐量15.6万笔/秒,平均时延848.9 μs,其中95%的订单时延在1359 μs以内,99%的订单时延在1719 μs以内,100%的订单时延在2898 μs以内。时延曲线见图7所示,时延分布图见图8所示,局部放大见图9所示。

图7 时延曲线图
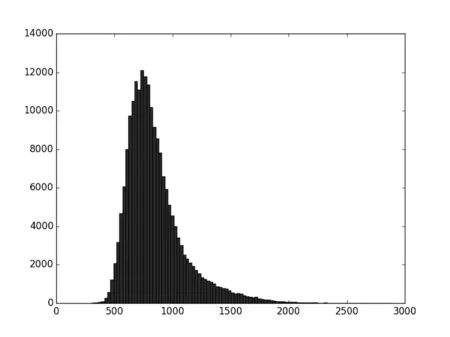
图8 时延分布图
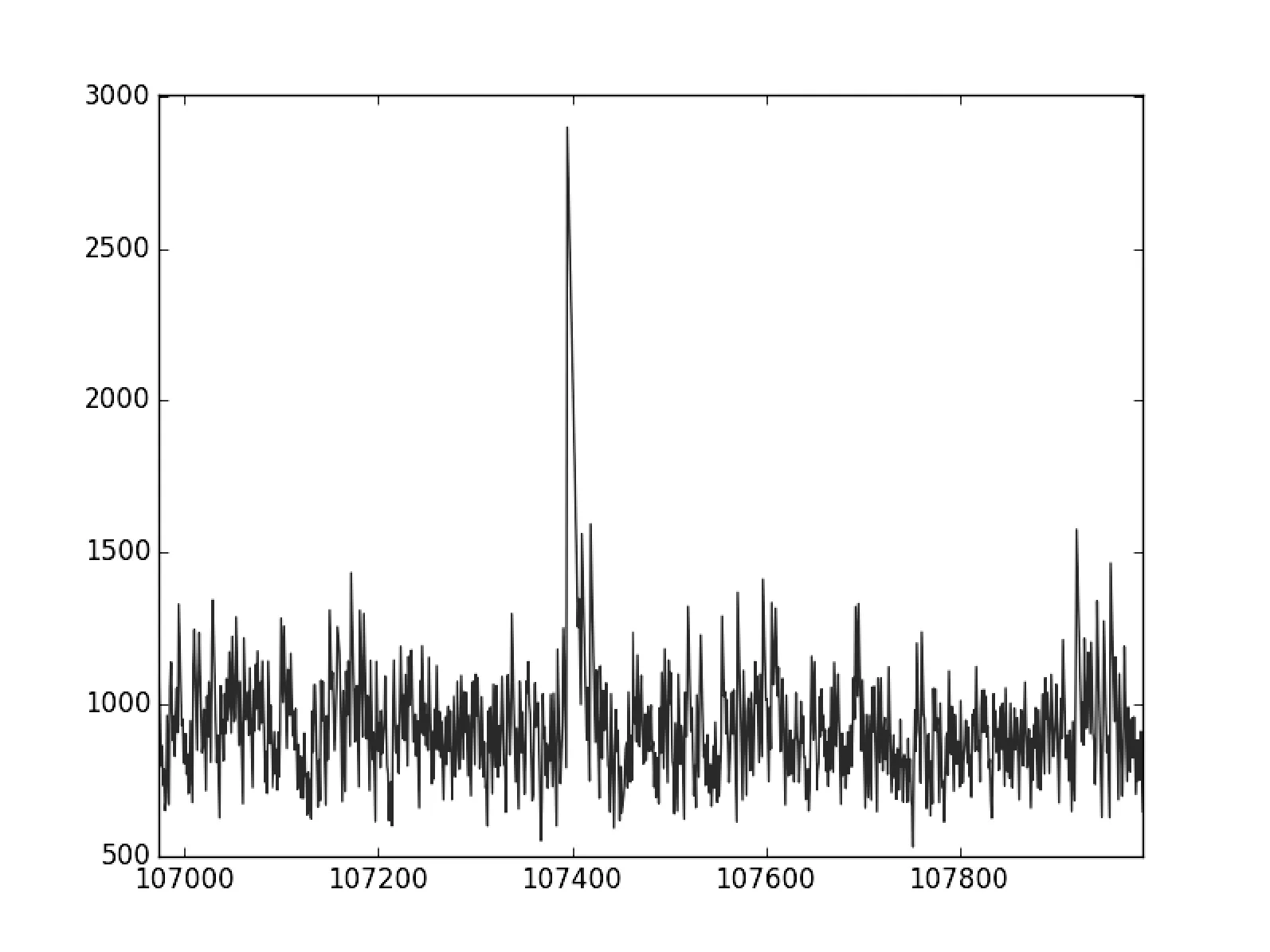
图9 时延曲线局部放大
观察出现毛刺的第107 395点,设为P点,该点时延DP=2898。发现DP-1为792,DP+1至DP+11为逐步减小的序列,说明毛刺是在特定点突然达到峰值,然后再逐步回归到平均值。对P点观察其时延分布,发现T1=T7=1277,即毛刺产生的原因是网络通信。如能扩大网络带宽、升级网络设备,应可降低毛刺出现频度,进而改善整体时延性能。
3.4 总结和展望
3.4.1 分析方法
为突破单机性能瓶颈,需要采用多机分布式架构。然而多机系统架构上的复杂性,会带来更多的交互延迟和隐藏阻塞点,从而加大系统调优代价。本文提出的队列级联方法,将系统抽象为一个个消息队列的组合,系统时延由各个队列的处理时延和排队时延,再加上队列间的通信时延构成。其中排队时延是引发性能不确定性的主要因素,可以用libmoni库测量排队时延,并通过调节事件流压力推算队列服务能力参数μ。
受环境所限,文中只测量了TC撮合队列和CS发送队列的μ参数。节点规模扩大及部署云计算环境后,网络带宽、虚拟机等因素会带来新的性能瓶颈点,仍可用队列级联方法加以分析。
3.4.2 调优和流控
将分布式系统视作消息队列的组合,这些消息队列的处理时延和通信时延加在一起,是整体时延的底线。消息队列的服务能力,决定了不带来过多排队时延的合理事件流强度,也即系统吞吐量。性能调优包含两个阶段:第一个阶段是尽量降低处理时延和通信时延,达到时延底线;第二个阶段是在不引入过多排队时延的基础上,令吞吐量最大化。通过在排队模型中增加事件流和服务窗口,可以突破μ参数的限制,达到通过增加节点线性提升性能的效果。
为使系统能按照设计的最优性能可靠运行,应引入用量化时延进行自适应流量控制的策略,以保证系统内每个队列都不会受到高于服务能力的事件流冲击。当事件流强度接近队列临界点时,时延会趋向无限大。此时应抑制系统中的重传机制,避免重传消息进一步增大队列压力,引发消息阻塞、丢失和振荡,令系统不可用。
4 结 语
LTP为交易系统轻型化提供了试验平台,允许组合各种通信协议、主备策略和并行策略进行算法试验。本文以轻型化交易系统为例,提出分布式系统时延的队列级联分析方法,并介绍相应的性能优化和流控策略。本文可为企业级关键业务实时系统的设计和调优提供参考。
[1] 黄寅飞,黄俊杰,王泊,等.证券交易系统中的事务恢复方法[J].计算机工程,2010,36(24):241-243.
[2] Pieter Hintjens.ZeroMQ:云时代极速消息通信库[M].卢涛,等,译.北京:电子工业出版社,2015.
[3] 黄晓东,张勇,邢春晓,等.一种基于Paxos算法的证券交易系统内存复制方法研究[J].计算机科学,2012,39(12):139-144,166.
[4] 李子骅.Redis入门指南[M].北京:人民邮电出版社,2013.
[5] Wes McKinney.利用Python进行数据分析[M].唐学韬,等,译.北京:机械工业出版社,2014.
[6] Cinnober公司.A Cinnober white paper on: latency[EB/OL].http://www.cinnober.com/whitepapers.
[7] 徐广斌,武剑锋,白硕.低延迟证券交易系统关键技术研究[J].计算机工程,2011,37(18):28-31.
[8] 李波,张新有.单向时延测量的时钟同步技术及测量方法[J].小型微型计算机系统,2013,34(8):1954-1958.
[9] 陆传赉.排队论[M].第2版.北京:北京邮电大学出版社,2009.
QUEUING THEORY-BASED LATENCY ANALYSIS ON TRADING SYSTEMS
Huang Yinfei Wang Bo Bai Shuo
(Technology Development Department,Shanghai Stock Exchange,Shanghai 200120,China)
Low latency is the major challenge of stock-trading system when to be moved from minicomputers to PC servers, with regard to this it requires the latency measurement and analysis. First we designed the Redis and Python-based latency data collecting and monitoring framework and implemented it. Then we proposed the cascading queues method to analyse the latency composition in distributed systems. Finally we found the configuration way enabling the optimisation of throughput and latency through parameters test and data analyses, and studied the solutions for extensibility and microburst problems. In this paper we model the distributed systems as cascading queues, on this basis, we make a significant improvement in latency index by the means of quantitative analysis, performance tuning and flow control protection, etc. The cascading queues method proposed in the paper can provide references for design and tuning of enterprise-level mission-critical real-time systems.
Latency measurement Monitoring framework Low latency Stock-trading system
2015-08-31。国家科技支撑计划项目(2012BAH13F 04)。黄寅飞,高工,主研领域:证券交易与数据分析。王泊,工程师。白硕,研究员。
TP3
A
10.3969/j.issn.1000-386x.2016.11.074
