基于用户信任及推荐反馈机制的社会网络推荐模型
2016-12-26刘柏嵩
翟 鹤 刘柏嵩
(宁波大学信息科学与工程学院 浙江 宁波 315211)
基于用户信任及推荐反馈机制的社会网络推荐模型
翟 鹤 刘柏嵩
(宁波大学信息科学与工程学院 浙江 宁波 315211)
社会网络包括以兴趣为核心的兴趣网络和以信任为核心的信任网络。如何利用社会网络中用户信任与兴趣相似的好友的项目数据来扩展用户本身的项目数据集,缓解用户数据稀疏性,利用目标用户的好友的项目评分数据为其产生推荐,是研究的重点。和传统的推荐方法相比,提出一种改进模型SIMTM(Similar and Trust Model)来提供用户更加高效的推荐体验。该模型融合用户兴趣度和信任度作为初始亲密程度,根据融合后的好友网络进行推荐,同时根据推荐反馈,来不断地优化用户的项目评分数据集,使得亲密的用户好友更加亲密,过滤掉用户的普通好友,优化用户之间的兴趣和信任关联;并重新计算用户之间的亲密程度形成融合用户与其好友的融合网络,直至前后两次根据亲密程度得到的推荐结果相近,根据得到的最优的亲密程度构建融合网络来进行推荐。实验结果表明,该模型在数据稀疏的情况下,能有效提高用户推荐的准确率和覆盖率。
社会网络 兴趣网络 信任网络 融合网络 推荐反馈 信任更新
0 引 言
随着现代科技及互联网技术的发展,人与人之间的原有的物理活动,逐渐向互联网等虚拟空间发展,人与人的社交活动也全面带入了在线社交时代。在线社交网络已经成为了人与人交往的必不可少的手段,也衍生了很多很优秀的在线社交平台,如Facebook、Twitter、国内的QQ和新浪微博等。在这种背景下,基于社交网络的个性化推荐,已成了传统的推荐方法的有效补充,也引起广大的研究人员的关注。在现实社会中,人们更相信来自自己身边的人,自己好友的推荐,人们也会在社交网络中,更多的与自己信任的人,或者与自己兴趣相同的人进行交流。如何将社交网络引入到个性化推荐当中,为用户提供基于社交网络的推荐,以便提高推荐结果的质量,是社交网络个性化推荐方法研究的热点和难点。
基于社交网络的推荐可以分为两类:基于信任的推荐和基于信任及兴趣的推荐。而绝大部分的推荐,都是纯粹的基于信任的传递。基于信任的传递又可以在信任传递、信任提取两个方面进行改进。在信任传递方面,2004年,Massa等[1]首先将信任引入到推荐系统当中,提出利用用户信任关系的传递,从而为用户匹配更多的邻居,一定程度上解决了协同过滤出推荐中存在的数据稀疏性问题,并提出了信任感知的推荐系统框架。将信任传播模型引用到协同过滤中。由于信任度传递,提高了用户预测的精确度和覆盖率,并在一定程度上解决了冷启动的问题[2]。胡福华提出一种基于可信相似度传递的协同过滤算法,该算法在用户相似度传递过程中,考虑用户之间信任度,可以提高用户相似度传递过程中推荐的准确度。但是,由于考虑的是兴趣在信任中传递,所以导致很多高信任的用户在传递过程中遗失,而事实上,基于信任的推荐比基于兴趣的推荐更可靠[9]。在信任提取方面,Golbeck用信任关系来定量分析社交网络中的社会关系,提出了信任网络,开发了个性化的电影评论网FilmTrust,利用社会网络中的信任关系作为电影评分的权值,从而为用户提供更加准确可信的电影推荐,但是由于未考虑用户之间的兴趣关联,因此,用户的推荐体验较差[3-5]。郭艳红等采用用户评价个数和对其他用户的推荐次数建立信任模型,并将此模型应用到协同过滤推荐算法中,提高了推荐算法的准确率,而在实际应用中,由于用户对商品的评价数据非常稀少,因此该方法的推荐结果不够精确[6]。Bedi等人根据蚁群算法中信息素更新算法提出了用户间信任值的动态更新算法,但是这种方法的信任初始值是通过用户之间的兴趣度和双方共同评价数获取到的,在用户数据稀疏的情况下,这种方法存在严重的缺陷[8]。王英等人提出利用社会学理论的社会等级理论和同质性理论构建信任关系预测模型。该方法有效地解决了数据稀疏性问题,还针对用户所属的不同领域实现了信任关系的预测。和其他方法相比,此方法具有较高的信任关系预测精度,但是由于算法的时间复杂度和空间复杂度较大,无法大规模应用到推荐领域[10]。上述的方法都是基于信任的推荐,没有考虑用户之间的兴趣关联,无法保障为用户提供有效的、感兴趣的商品。而综合考虑信任和兴趣的推荐,Gao等融合社交网络和改进CF算法,提出一个混合型推荐系统,用户间直接信任值由用户自身给出,间接信任值由基于信任传递距离和最长传递距离的公式加权算得[7]。这种信任计算方式比较主观,用户之间的直接信任关系是通过用户直接给出的,但是在现实的电商平台,电影播放领域,以及音乐推荐领域中,用户直接给出直接信任值的情况是非常稀少的,该方法实用性不足。张富国对基于社交网络的推荐进行了系统性的阐述[11]。
1 模型构建
用户往往选择自己信任的,或者与自己兴趣相关的社交团体,社交团体中的用户往往相互影响。并且由于推荐系统的局限性,如何缓解用户数据稀疏性一直都是推荐系统的热点和难点。而如何利用社交网络来缓解推荐系统的数据稀疏性,并利用好友的项目评分数据来对用户进行推荐,是本文考虑的重点。
本文提出一种同时考虑用户的兴趣相似度和信任关系的模型SIMTM。该模型融合用户的兴趣网络和信任网络,作为衡量用户亲密程度的标志;同时在兴趣网络中,采用共同项目评分个数作为调和权重,校正用户之间的兴趣度;对信任度采用迭代的方式进行推荐反馈,得到一个最终的融合用户兴趣及信任的,有效表达用户之间亲密程度的融合网络,而信任度的初始值,是通过隐形方式获得,符合绝大部分的电商平台以及其他的相应的推荐领域。通过这样一种方式,提高对目标用户推荐结果的精确度和覆盖度。
在推荐系统中,用户集U={u1,u2,…,un},项目集I={i1,i2,…,im},每一个用户u对项目集的项目进行评分,得到用户项目评分用rui表示,rui一般用1~5表示。在基于信任的推荐系统中,用户与用户之间构建一个信任网络,用tuv表示用户u对用户v的信任度。信任度的取值范围一般在[0,1]。社交网络融合信任网络和兴趣网络,可以用图表示:G=
1.1 融合网络
从社会学理论出发,任何一个单纯的信任网络或者兴趣网络都不是一个完整的社交网络。在现实世界中,人与人之间的社交圈应包括兴趣关联和信任关联两部分,因此,只有融合了信任关系和兴趣关系,才更符合现实世界中的社交网络。
在本文中采用两种方式计算融合两种关联之后的亲密程度,亲密程度用Itc表示,兴趣度用sim表示,信任度用tru表示。
方法一简单的线性加权
其公式为:
Itc(u,v)=αsim(u,v)+(1-α)tru(u,v)
(1)
当α=0,Itc(u,v)=sim(u,v);当α=1;Itc(u,v)=tru(u,v)。
方法二通过用户信任放大用户偏好
当在用户的信任网络中,其信任的用户同时与其具有相似的兴趣偏好,则强化用户对该用户的信任。
其公式为:
Itc(u,v)=max{sim(u,v)·(1+tru(u,v)),tru(u,v)}
(2)
对于冷启动用户,和其他用户的兴趣偏好为0,此时只考虑用户之间信任度。
其中,sim(u,v)采用皮尔逊相关系数计算用户之间的兴趣度,并采用校正系数校正用户之间的兴趣度。其公式为:
(3)
其中:
(4)
采用校正系数是为了避免由于用户共同项目数差距比较大而造成的相似度的不准确性。
得到兴趣度后,计算用户对项目的预测评分,其公式为:
(5)
对于式(2)中的tru(u,v)表示用户之间的信任度。由于用户之间的信任度大多数情况下无法直接从用户中获取,本文采用隐式的方法来获取用户之间的信任度。直接信任度的计算公式为:
(6)
其中,SuccessSet(u,v)表示用户u对用户v的推荐成功数,RecommandSet(u,v)表示用户u对用户v的推荐总次数。ru,v表示用户u对用户v的推荐总次数,而ru,max表示用户u向其好友网络中的好友的最大推荐次数。
推荐成功的定义为:
(7)
间接信任度分为单路径下间接信任度和多路径下间接信任度。在本文中,单路径下的信任传递信任度,采用直接信任度相乘的方式得到。假设用户u和用户v存在n个用户,当信任传递距离小于阈值δ,则得到的单路径下的间接信任度为:
Tu,v=Tu,s1·Ts1,s2,…,Tsn-1,sn·Tsn,v
(8)
当用户之间存在多条路径,多中间节点的情况下,对并联信任传递的间接信任计算公式为:
(9)
其中,a表示用户u和v的中间节点。
当用户与好友之间同时具有直接信任关系和间接信任关系时,以直接信任关系为准。
得到最终的融合用户信任和兴趣关联的亲密程度之后,筛选前K个值最高的用户,形成邻居集合,并根据亲密程度进行推荐,推荐公式为:
(10)
SIMTM是融合兴趣关联和信任关联来模拟现实世界中的好友关系,并产生推荐。初始亲密程度Itc(u,v)采用式(1)或式(2)计算得到,并将筛选取到的K个值,得到以目标用户为中心的融合网络,并计算目标用户的直接节点的融合网络,以此类推,得到以目标用户为核心的、用户资源丰富的融合网络,并在此融合网络上,进行个性化推荐。
1.2 算法描述
由于数据的稀疏性,单纯从现有的数据中计算得到用户的兴趣度很小,不足以呈现出用户的兴趣关联,而由此得到的信任关联也不能真实有效地体现用户之间的信任关系。而且,用户之间的信任关系,并不是一成不变的,而是会随着推荐结果的反馈而进行动态更新,因此,本文中,引入了推荐反馈这个概念。
定义1亲密程度是指融合了用户信任和兴趣关联的,用来衡量用户与其好友之间的友好程度的指标。
定义2推荐反馈是指所有向u推荐的用户中,若用户v向用户u推荐成功,则把用户v的项目评分通过用户u及用户v的亲密程度作为权重,扩展到用户u的项目评分集,并重新计算用户v对用户u的亲密程度。
本文中,根据得到的初始亲密程度进行推荐,并根据推荐成功率进行反馈。设置阈值δ,取推荐成功率大于δ的进行反馈。
由于ACM的国际大学生程序竞赛,提出的社交网络中距离大于2的节点之间的关系对于链接预测的影响很小。而且在以前的基于信任的推荐算法中,证明了这一点,因此,本文中的好友距离默认为2。
好友之间的兴趣度往往是十分相似的,因此通过推荐反馈来填充用户的项目评分矩阵,来缓解用户项目评分数据的稀疏性。根据填充后的用户评分矩阵,重新计算用户之间的兴趣度、信任度及亲密程度。直至两次亲密程度相差不大为止,即:
(11)
系统框架如图1所示。
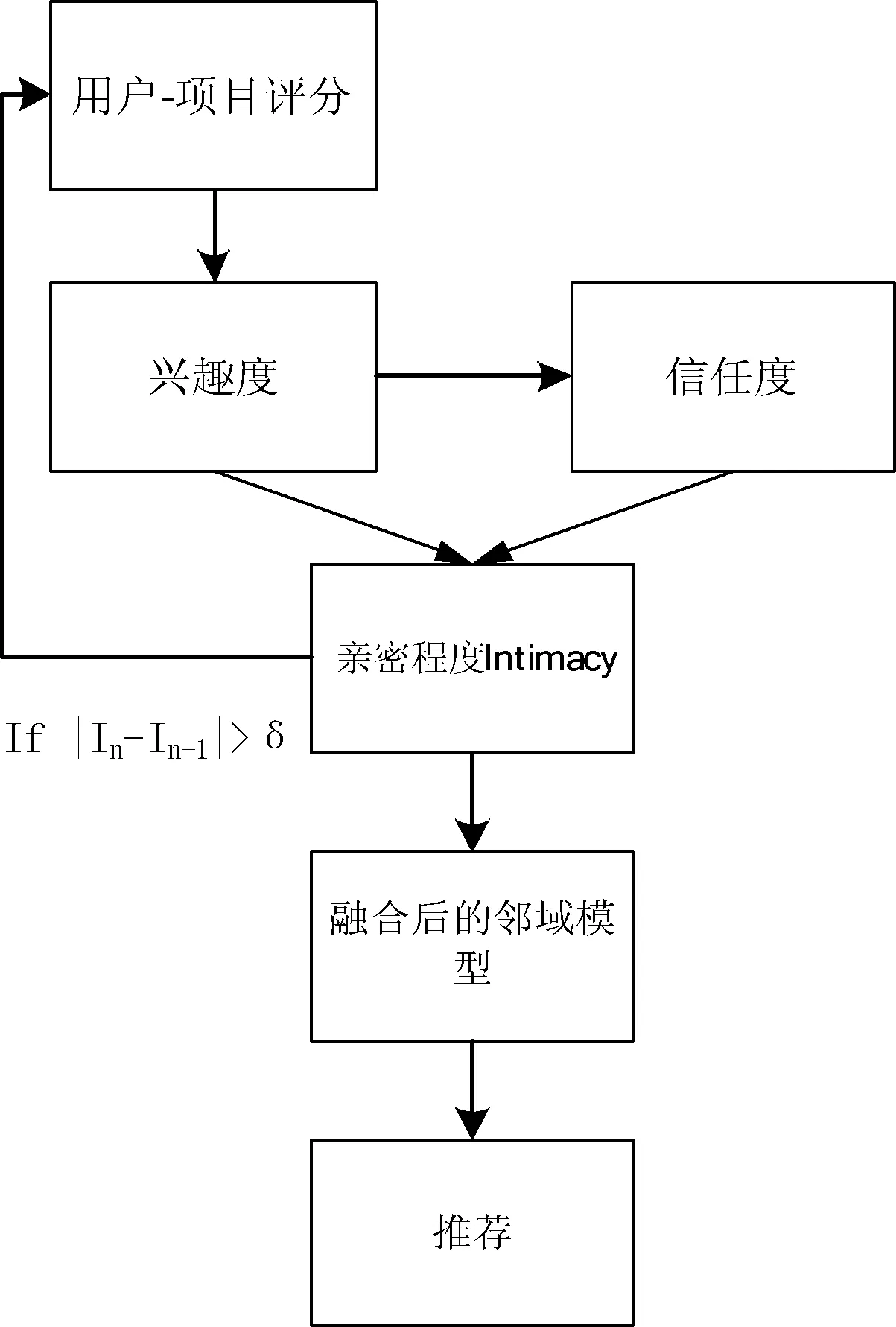
图1 系统架构图
算法根据上述算法思想,设u为目标用户,U为用户集合,I为项目集合,U_I为用户项目评分集合。整个算法计算流程如下:
1) 从用户集合U中查找目标用户u的好友集合;
2) 遍历好友集合,去数据集中查找每个好友的直接好友集合;
3) 根据步骤1)和步骤2)得到的好友集合,构建目标用户u的好友网络;
4) 计算好友网络中,任意两个直接相连的节点的兴趣度;
5) 根据计算得到的兴趣度,按式(5)产生推荐;
6) 根据推荐结果和式(6)计算节点之间的信任度;
7) 根据计算得到的信任和兴趣度,采用式(1)和式(2),计算融合二者关系的亲密程度;
8) 选择topK的亲密程度,扩展好友网络中相应好友的用户项目评分数据,并去除掉未选择的亲密程度的好友的边,重新回到公式步骤4)进行计算;
9) 前后两次计算得到亲密程度的差的绝对值。若小于阈值,则迭代结束;否则继续回到步骤4)进行计算;
10) 根据最终得到的最优亲密程度,采用式(10)进行推荐,选择topK个评分,推荐给目标用户。
上述算法中,首先得到用户u的直接好友集,并分别得到好友集中的每个用户的直接好友集,并由此得到以用户u为核心的好友网络,此时得到的网络是一个有向有环图,对应步骤为1)-3);在好友网络中,分别计算任意两个好友之间的兴趣度,并根据得到的用户项目评分做出推荐并计算任意好友之间的信任度,对应步骤为4)-6);得到兴趣度和信任度后计算亲密程度,得到亲密程度后选取topK,去除未选择的亲密程度的好友之间的边,并根据亲密程度填充好友网络中的用户项目将评分,重新回到式(4)计算,直到两次亲密程度差值小于某个范围,则亲密程度计算完成,并根据亲密程度产生推荐。
本方法中,通过好友之间的兴趣扩展,有效地缓解了用户项目评分的数据稀疏性。与传统的推荐方法相比,本文中由于加入了动态更新的迭代方法,因此,该算法的时间复杂度更高,但是也正是由于动态更新,该方法有效地保证推荐结果的准确性。
2 实验结果与分析
2.1 数据集
本文采用Epinions数据集来验证本次模型的可用性。Epinisons数据集是目前公开可用的、为数不多的既包含用户好友关系、又含有用户项目评分数据的数据集[15]。Epinions数据集是来源于Epinions网站的真实数据。该数据集中包含两个文件,第一个为用户评分文件,包含49 289个用户对139 738个商品的664 825个评分。另一个为好友关系文件,包含了49 289个用户间487 181个信任关系。为了避免由于冗余数据而造成的数据孤点,本文选取评分分布与全体用户评分分布大致一致的用户、评分人数分布与全部商品评分人数分布大致一致的商品作为实验数据集。将实验数据集的80%设置为训练数据,余下的20%为测试数据。
2.2 评价指标
为了验证本文中提出的模型,本文采用推荐准确率和覆盖率作为评测指标。
2.2.1 准确率
平均绝对误差(MAE)是推荐系统或者推荐算法最常用的评价指标之一,用来度量为用户预测行为的能力。MAE是通过计算项目的预测评分值和项目实际评分的差值的绝对值的平均得到。MAE越小,表示算法的推荐结果越好。MAE的计算公式为:
(12)
其中,Ri表示用户u对项目i的推荐评分,Pi表示项目的实际评分,n表示项目的预测个数。
2.2.2 覆盖度
覆盖率是描述一个推荐系统对物品长尾的挖掘能力。简而言之,是推荐系统能够推荐出来的物品占所有物品的比例。推荐系统,目的是为了给用户推荐用户感兴趣的商品,而不是所有商品。因此,在本文中,对覆盖率公式进行调整,其分母调整为用户与其所有好友的项目评分数据取并集,用Nall表示。修改后的公式为:
(13)
其中,NIR表示用户的推荐项目集个数,Nall表示用户与其所有好友的所有项目的个数。
2.3 实验及实验结果
本文实验分为两个部分,第一个实验用于确定式(12)的α的值;第二个实验用于比较本文改进的推荐算法和传统的协同过滤算法以及基于信任的协同过滤算法的平均绝对误差,在实验之前,需先对数据集的评分数据进行归一化处理。
2.3.1 融合系数α确定
本实验目的在于通过同一个用户的不同邻居数在得到最优的α值,设置邻居个数分别为5、10、20。通过调整后的邻居个数重新计算推荐算法的平均绝对误差,根据MAE来选择最优值,得到的结果如图2所示。
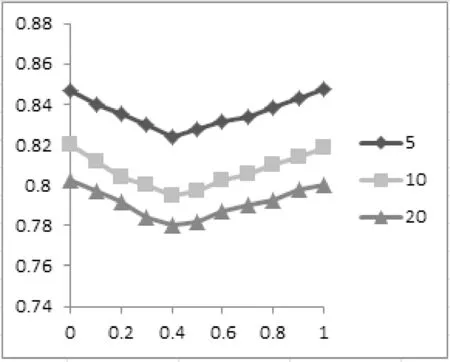
图2 不同α值不同好友数下的MAE对比
从图2可以看出,随着邻居数的增加,MAE变小,这表明用户好友越多,其推荐结果越准确。并且可以看出,当α=0.4的时候,计算得到的平均绝对误差最小,得到最后的推荐效果。
2.3.2 推荐结果比对
为了验证本文提出的改进算法的有效性,本文采用对比本文的改进算法和基于用户的协同过滤算法以及基于信任的协同过滤算法的平均绝对误差和覆盖率来验证算法优劣。其中,UCF和TrustD的实验数据通过相应的算法在Epinions数据集上计算所得,部分实验结果记录在表1中。

表1 不同好友数下的三种算法效率对比
在不同的好友数下验证三个算法的时效性,其MAE数据对比用柱状图表示,如图3所示。
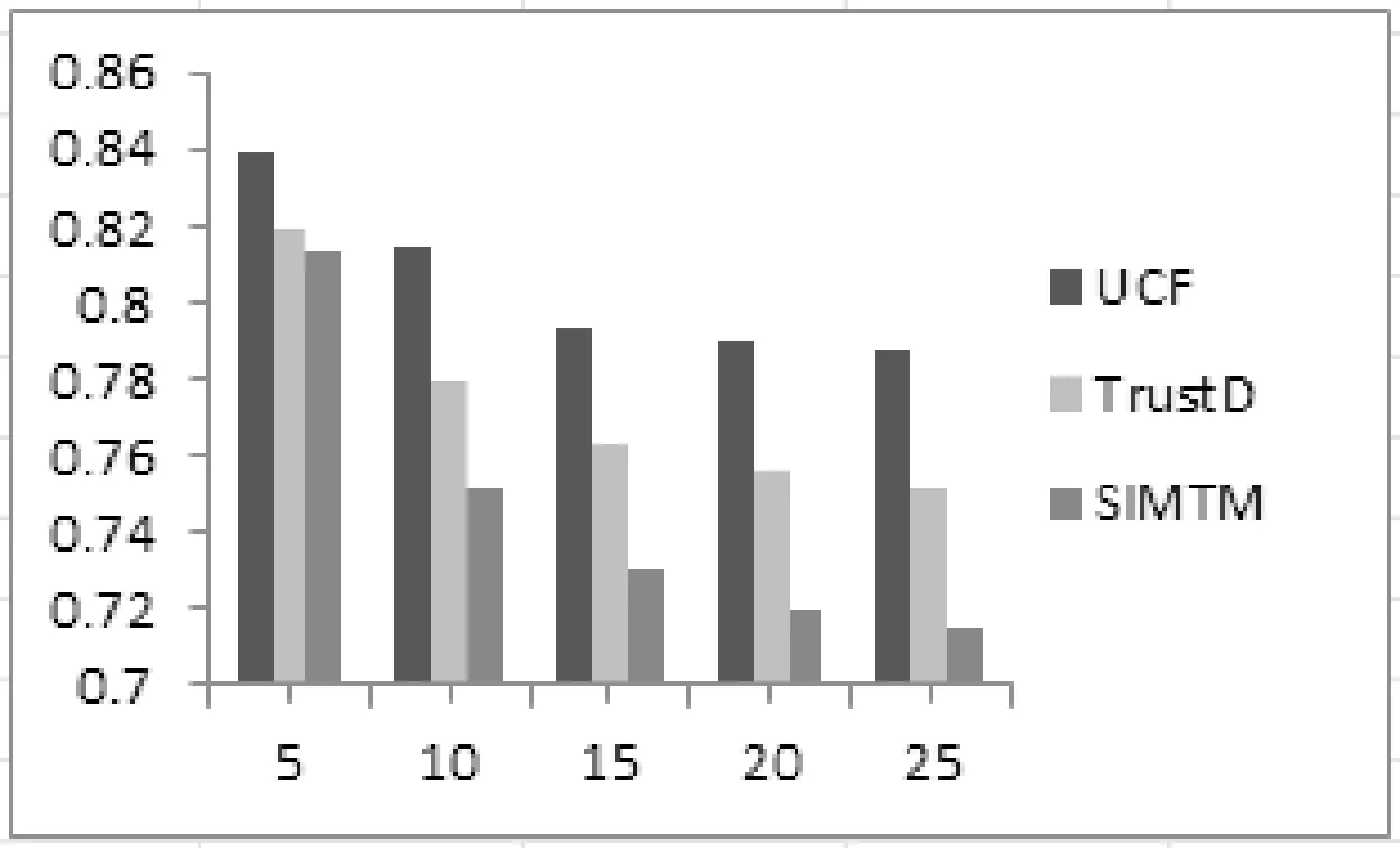
图3 不同好友数下的三种算法MAE对比
从图3可以看出,随着用户好友数的增加,三个算法的MAE逐渐下降,并且本文提出的改进算法的MAE一直小于另两个算法。当用户的好友数超过20以后,算法的MAE逐渐趋于平缓。这是因为数据的稀疏性,目标用户的好友用户较少,导致得到的用户的相似用户较少,构建的邻域集合较小,因此无法得到足够的评分数据来进行预测。在本文中,通过迭代,得到最终的融合后的亲密程度,并且把好友用户的一些评分数据通过亲密程度作为权重添加到目标用户的评分集中,扩展了用户的数据,极大地缓解了推荐系统数据稀疏性的问题。随着好友数的增加,通过迭代扩展的数据集也越来越丰富,得到的推荐效果也越来越好。当好友数大于某一范围后,用户的评分集饱满,因此得到的MAE也趋于平缓。
覆盖率结果用柱状图表示,其结果如图4所示。从图4可以看出,随着用户好友数的增加,推荐结果的覆盖率随之上升,这是因为当用户的好友数增多,得到的用户的相似用户就随之增多,从而使得构建的邻域集合增大,对用户推荐的项目也随之增多。当用户增加到一定数量以后,覆盖率的增加随之平缓。因为用户及用户好友的项目,随着人数的增多,用户的项目集趋于饱和,因此覆盖率随之平缓。因此,本文提出的改进算法明显优于另两种算法,这是因为采用本文提出的算法扩展了用户的项目集,扩展后的项目集包含了其他好友的项目。随着好友的增加,SIMTM的覆盖率增加的斜率也比另两种算法更大。

图4 不同好友数下的三种算法的覆盖率对比
从覆盖率和MAE的结果图可知,本文提出的改进算法SIMTM明显优于另两种算法。和传统的UCF相比,本文考虑用户的社交网络,有效缩小了用户的好友数,避免用户过多而造成的时间复杂度和空间复杂度过大。和纯粹的基于信任的推荐算法相比,本文考虑用户之间的兴趣度,选取那些与目标用户既信任又兴趣一致的用户进行推荐,明显优于只考虑信任的推荐算反。并且,本文采用了推荐反馈来进行动态更新用户的项目评分数据集,很好地缓解了数据稀疏性的问题,而且在覆盖率方面,本文提出的算法明显优于另两种算法,在解决长尾问题上,有明显优势。
3 结 语
社交网络包括由兴趣建立的兴趣网络和由信任构建的信任网络两方面,本文提出一种改进的推荐算法SIMTM。该算法融合了用户兴趣度和信任度,并根据融合的亲密程度对用户评分数据进行更新,通过不断的迭代过程,得到最优的亲密程度,并根据亲密程度进行推荐。根据实验结果显示,该算法在推荐结果上,明显优于传统的基于用户的协同过滤算法和纯粹的基于信任的推荐算法,并且很好地解决了用户评分数据稀疏的问题及长尾,也证明了当用户好友数足够的情况下,能得到最优的推荐结果。该算法没有考虑到用户之间的不信任因素以及信任的时间衰减等因素,并且由于该算法采用了一种迭代的计算过程,所以算法时间复杂度偏大。而且由于本算法是采用的融合社会网络中好友的一些评分数据,因此在用户数据隐私性问题上,也需多加考虑。在后续的工作中,会重点处理这些问题,争取进一步完善算法。
[1] Massa P,Bhattacharjee B.Using Trust in Recommender Systems:An Experimental Analysis[J].Lecture Notes in Computer Science,2004:221-235.
[2] Chen X C,Liu R J,Chang H Y.Research of Collaborative Filtering Recommendation Algorithm Based on Trust Propagation Model[C]//Computer Application and System Modeling (Iccasm),2010 International Conference on.2010:V4-177-V4-183.
[3] Golbeck J.Computer Science-Waving a Web of Trust[J].Science,2008,321(5896):1640-1641.
[4] Golebec J.Computing and Applying Trust in Web-Based Social Networks[D].University of Maryland,USA,2005.
[5] Kuter U,Golebeck J.Sunny:A New Alogorithm for Turst Inference in Social Networks Using Probabilistic Confidence Models[C]//Proceedings of The 22nd National Coference on Artificial Intelligence.Coulumbla,Canada,2007:1377-1392.
[6] 郭艳红,邓贵仕,雒春雨.基于信任因子的协同过滤推荐算法[J].计算机工程,2008,34(20):1-3.
[7] Gao Y,Xu B,Cai H.Information Recommendation Method Research Based on Trust Network and Collaborative Filtering[C]//E-business Engineering (Icebe),2011 Ieee 8th International Conference on IEEE,2011:386-391.
[8] Bedi P,Sharma R.Trust Based Recommender System Using Ant Colony for Trust Computation[J].Expert Systems with Applications,2012,39(1):1183-1190.
[9] 胡福华.基于可信相似度传递的协同过滤算法研究与应用[D].浙江大学,2011.
[10] 王英,王鑫,左万利.基于社会学理论的信任关系预测模型[J].软件学报,2014(12):2893-2904.
[11] 张富国.基于社交网络的个性化推荐技术[J].小型微型计算机系统,2014,35(7):1470-1476.
[12] Guo L,Ma J,Chen Z.Learning to Recommend with Multi-faceted Trust in Social Networks[C]//International Conference on World Wide Web Companion. International World Wide Web Conferences Steering Committee,2013:205-206.
[13] De Meo P,Nocera A,Terracina G,et al.Recommendation of Similar Users,Resources and Social Networks in a Social Internetworking Scenario[J].Information Sciences,2011,181(7):1285-1305.
[14] Zhang J,Cohen R.A Framework for Trust Modeling in Multiagent Electronic Marketplaces with Buying Advisors to Consider Varying Seller Behavior and the Limiting of Seller Bids[J].Acm Transactions on Intelligent Systems & Technology,2013,4(2):55-73.
SOCIAL NETWORK RECOMMENDATION MODEL BASED ON USER TRUST AND RECOMMENDATION FEEDBACK MECHANISM
Zhai He Liu Baisong
(College of Information Science and Engineering,Ningbo University,Ningbo 315211,Zhejiang,China)
Social networks include the interest network taking the interest as core and the trust network taking the trust as core. The research focus of this paper is that how to use the projects data of the friends in social networks with similar trust and interest to expand the project dataset of user’s own, to alleviate the sparsity of user data, and to use the data of project rating score of target user’s friends to generate recommendation for it. Compared with traditional recommendation methods, the paper presents an improved SIMTM(Similar and Trust Model), which can provide more efficient recommendation experience. The model fuses interest and confidence as the initial intimacy, and makes recommendation according to the fused networks of friends, at the same time it constantly optimises the project rating score dataset according to the recommended feedbacks, this makes user’s close friends be more intimate while filtering out user’s ordinary friends, and optimises the association of interest and trust between user, moreover it re-calculates the intimacy degree between users to form a fusion network which fuses the user and user’s friends until the twice recommendation results before and the after derived from intimacy degree are close, and then constructs the fusion network based on the derived optimal intimacy degree for recommendation. Experimental results show that, the model can effectively improve the accuracy and coverage of recommendation of users, especially in the case of data sparsity.
Social network Interested network Trust network Fusion network Recommendation feedback Trust update
2015-06-27。翟鹤,硕士生,主研领域:数据挖掘。刘柏嵩,研究员。
TP391
A
10.3969/j.issn.1000-386x.2016.11.060
