一种朴素贝叶斯文本分类算法的分布并行实现
2016-12-26郭绪坤范冰冰
郭绪坤 范冰冰
1(广州体育学院 广东 广州 510500)2(华南师范大学计算机学院 广东 广州 510631)
一种朴素贝叶斯文本分类算法的分布并行实现
郭绪坤1范冰冰2
1(广州体育学院 广东 广州 510500)2(华南师范大学计算机学院 广东 广州 510631)
针对当前朴素贝叶斯文本分类算法在处理文本分类时存在的数据稀疏、分类不准及效率低的问题,提出一种基于MapReduce的Dirichlet朴素贝叶斯文本分类算法。算法首先根据体征词语义因素以及类内分布情况对权重进行加权调整,以此对的计算公式进行修正;引入统计语言建模技术中的Dirichlet数据平滑方法来降低数据稀疏对分类性能的影响,并在Hadoop云计算平台采用MapReduce编程模型实现本文算法的并行化。通过测试实验对比分析可知,该算法显著提高了传统朴素贝叶斯文本分类算法的准确率、召回率,并具有优良的可扩展性和数据处理能力。
朴素贝叶斯 文本分类 TF-IDF修正 数据平滑 MapReduce并行化
0 引 言
随着计算机技术的不断发展,电子文档特别是大数据成指数倍级增加,如何将大量文本以隶属类别进行有效分类并检索成为数据挖掘与信息检索领域的研究重点和热点。主要的文本分类算法由朴素贝叶斯[1-3]、K近邻[4]、神经网络[5]、支持向量机[6]、向量空间模型的Rocchio分类器[7]、最大熵[8]等。以贝叶斯概率理论为基础基于统计的贝叶斯分类方法,假定文本特征独立于类别,简化了训练和分类过程计算,取得了令人满意的分类效果,已成为文本分类中广为使用的一种方法。文献[9]提出了一种改进的朴素贝叶斯分类方法,通过卡方检验方法求文档特征并降维,以文本特征来代替原始词条进行朴素贝叶斯分类;文献[10]提出了基于特征相关的改进加权朴素贝叶斯分类算法,算法考虑到特征项在类内和类间的分布情况,并结合特征项间的相关度,调整权重计算值;文献[11]提出了一种基于特征选择权重的贝叶斯分类算法,采用卡方值和文档频数相结合的数值来表示特征词的重要程度,以此获得特征词权重,建立加权贝叶斯分类器;文献[12]对经典朴素贝叶斯分类算法进行了改进,提出了一种文本分类算法,提高了分类精度;文献[13]提出了一种基于辅助特征词的朴素贝叶斯文本分类算法,提高了类条件概率精确度。
以上算法在一定程度上提高了文本分类的性能,但也存在两方面的局限:其一,文本分类过程中,语言中大部分词都属于低频词,容易造成数据稀疏问题;其二,由于其自身扩展性和计算能力的限制,集中式平台运行传统朴素贝叶斯文本分类算法时,难以保证数据处理的高效性。为了解决以上两个方面的问题,本文借鉴统计语言建模技术[8]中的数据平滑方法,提出一种基于Dirichlet朴素贝叶斯文本分类算法,同时采用MapReduce编程模型[9],在 Hadoop[10]云计算平台上实现该算法的并行化。
1 朴素贝叶斯文本分类算法及改进
1.1 朴素贝叶斯文本分类算法
朴素贝叶斯文本分类算法NB(Naive Bayes)是一种基于概率统计的学习方法。常用的模型为多变量伯努利模型和多项式模型。二者的计算粒度不一样,多项式模型以单词为粒度,伯努利模型以文件为粒度,因此二者的先验概率和类条件概率的计算方法都不同。计算后验概率时,对于一个文档d,多项式模型中,只有在d中出现过的单词,才会参与后验概率计算,而伯努利模型中,没有在d中出现但在全局出现的单词,也会参与计算,不过是作为“反方”参与的。本文采用多项式模型[11]。
设文档d由其所包含的特征词d=(t1,t2,…,t|n|)表示,tk为特征词,k=1,2,…,|n|,n是特征词的集合,|n|为特征词个数。同时,集合C为目标类别集合,C={C1,C2,…,Cm},Cj为类标签。根据贝叶斯公式,文档d属于类别Cj的概率为:
(1)
式中分母与类别无关,故可将式(1)改为:
P(Cj|d)=P(Cj)P(d|Cj)
(2)
式中类先验概率P(Cj)和类条件概率P(d|Cj)都可以通过训练集学习获得,一般用最大似然估计作为它们的估计值。P(Cj)可由式(3)估计得到:
(3)
式中Nj为类Cj的特征词总数,N为训练集的特征词总数。
由于文档d可由其所包含的特征词表示,可将P(d|Cj)改写为:
P(d|Cj)=P((t1,t2,…,t|n|)|Cj)
(4)
朴素贝叶斯假设特征词ti和tj之间对类别的影响相互独立,则式(4)可改写为:
(5)
将式(5)代入式(2)中可得:
(6)
基于朴素贝叶斯独立性假设,将式(5)中文档类条件概率转换为求特征词的类条件概率,特征词的类条件概率P(tk|Cj)的计算式为:
(7)

1.2 TF-IDF权重的改进
特征词的权重是计算向量相似度的关键,直接影响计算结果的准确性,一般采用TF-IDF计算方法,其中,TF为特征词频率,反映特征词在文本内部的分布情况;IDF为特征词的倒排文本频率,反映了特征词在整个文本集合的分布情况,TF-IDF将词频和反文档频率结合使用能基本体现特征词的权重。但其并没有考虑特征词长度、在文本中位置以及类内分布情况等对特征词权重。本文根据体征词语义因素以及类内分布情况对权重进行加权调整,以此修正TF-IDF的计算式。TF-IDF权重的计算式如下:
(8)
式中Wik为特征词ti在文本dk中的TF-IDF权重,Numik为特征词ti在文本dk中出现的次数,N为文本数,ni为出现特征词ti的文本数。
1) 类别区分系数
一个特征词的权重不仅仅由其在文本出现的频率的决定,还体现与其对类别的区分能力。根据式(8)的TF-IDF权重计算,会存在两个相等的特征词t1、t2。若t1只出现在一个类别中,t2分散在多个类别中,很明显t1对类别的区分度要强于t2,但仅两者的TF-IDF权重是相等的。为了解决此种情形,本文引入类别区分系数α,表示类别Cj中包含特征词ti的文本数与训练集中包含ti文本数的比值,比值越大,说明ti在类别Cj中出现的越频繁,区分度越强。加入类别区分系数后,TF-IDF权重的计算式如下:
(9)
2) 位置权重系数
一段文字的首段往往重点点名题意,这些特殊的位置说明特征词的权重受位置的影响。根据研究结果,本文设β为位置权重系数,位置权重系数表如表1所示[18]。

表1 位置权重系数表
设Nti为特征词ti出现在相应位置的次数,βti为特征词ti的位置权重,加入位置权重系数后,TF-IDF权重的计算式如下:
(10)
3) 特征词长度系数
词语的长度也是影响特征词权重的一个重要因素,词语的长度越长,蕴含的信息越多,出现的概率相对较低。由于长特征词与短特征词所包含语义的差别,本文引入特征词长度系数δ加以区分。加入特征词长度系数后,TF-IDF权重的计算式如下:
(11)
式中特征词“新陈代谢”的长度系数δ为4。本文特征词权重采用改进后的TF-IDF算法进行计算。朴素贝叶斯文本分类的目标就是确定极大后验假设MAP,即求出文档d最可能的类别值CMAP,表达式如下:
(12)
1.3 基于Dirichlet朴素贝叶斯文本分类算法
在自然语言语料库中,特征词出现的频率Pt与其在频率表中的排名ω之间有下列关系:
(13)
其中,K和σ都是常数,K通常取值1,σ通常取值0.1。
如果词表包含数十万个词,由式(13)可计算出其中排名前1000个最常用词占各种文章全部词的80%。计算过程如下:
=0.8=80%
上述计算过程表明,自然语言中的大多数词出现的频率都是稀疏的,并且无论怎样扩大训练词库,都无法保证所有词的出现。因此,在式(12)中,由于存在数据稀疏问题,特征词tk在类别Cj中可能出现零次,导致零概率问题。解决此问题的方法是采用Laplace平滑进行估计:
(14)
但是Laplace平滑方法会将所有没出现词的概率等同,这会导致未出现词的概率过高,降低分类准确率。本文将统计语言建模技术中的平滑方法应用到朴素贝叶斯文本分类之中,以解决数据稀疏问题造成的概率失准问题。
对任何句子S=(t1,t2,…,tk),可将其看作是具有以下概率值的马尔科夫过程:
(15)
式中n为马尔科夫过程的阶数。n=1时为一元语言模型,单词序列t1,t2,…,tn在文档中出现的概率P(t1,t2,…,tn)=P(t1)P(t2)…P(tn),此时和朴素贝叶斯文本分类算法的独立假设完全相同。由此,统计语言建模技术中的平滑方法也可适用于朴素贝叶斯文本分类算法中。基于此,本文引入了统计语言建模技术中的Dirichlet平滑方法代替Laplace平滑方法,提出了一种Dirichlit朴素贝叶斯文本分类算法DNB,改进后特征词的类条件概率P(tk|Cj):
(16)
式中ξ为调节分类性能的参数,P(tk|C)表示tk在Cj中出现的预估概率。
2 算法的MapReduce并行化
2.1 文本预处理
文本预处理Job的工作流程:
(1) 辨析输入词语的相对路径Path,然后将将其存放的目录名作为类名Label;
(2) 利用中文分词工具对文档内容进行处理;
(3) 按照贝叶斯模型的要求形成输入格式:每行一篇文档,每篇文档的格式为
2.2 文本向量化
文本向量化Job的工作流程:
(1) 读取TD文件;
(2) 统计特征词数目,生成文件WC;
(3) 读取上一步生成的WC文件,给每个特征词分配ID,生成文件Dictionary;
(4) 统计每个文档中每个特征词的词频TF,得到向量Vector_TF,生成文件TFVectors;
(5) 统计在所有文档中每个特征词出现的文档频率DF,生成文件DF-Count;
(6) 利用式(9)计算出每个特征词的TF-IDF权重;
(7) 根据特征词ti在文本dk中出现的次数Numik,在训练集中出现特征词ti的文本数ni,在Cj中出现特征词ti的文本数nj,统计特征词ti的词长及位置信息,对每个特征词的TF-IDF权重进行修正,得到Vector-TFIDF向量,生成文件TF-IDFVectors。
2.3 训练分类器
训练分类器Job的工作流程:
(1) 为类别建立索引,每个类别有对应的ID,生成文件LabelIndex。
(2) 读取文件TF-IDFVectors,累加相同类别文档的向量Vector-TFIDF,计算出相同类别特征词的权重之和TF-Num,得到Vector_TF-Num向量,生成文件TF-NumVectors。
(3) 读取上一步得到的文件TF-NumVectors,累加所有类别的Vector_TF-Num向量,计算每个特征词在所有类中的权重之和FNum,生成文件FNum-Count;累加每个类别所有特征词的Vector_TF-Num向量,计算出每个类中所有特征词的权重之和TNum,生成文件TNum-Count。
(4) 读取文件TF-NumVectors、FNum-Count、FNum-Count,建一个行由所有类别构成,列由所有特征词构成的二维矩阵Matrix-NaiveBayes,用TF-Num填充此矩阵,然后在Matrix-NaiveBayes的最后一行通过填充TNum增加一行,在最后一列填充FNum增加一列,从而构造一个贝叶斯分类模型,生成文件NaiveBayes-Model。
2.4 测试分类器
测试分类器Job的工作流程:
(1) 读取文件NaiveBayes-Model,建立NaiveBayes-Model对象。
(2) 在NaiveBayes-Model中取出相关参数,根据式(16)计算特征词的类条件概率,根据式(3)计算类先验概率,根据式(6)计算文档对于所有类的后验概率PP,得到向量Vector_PP,生成文件Result
(3) 读取文件Result,取最大后验概率对应的类别为该输入文档的类别CMAP。
3 仿真实验与参数选择
3.1 实验环境
仿真实验平台由8节点组成的Hadoop集群,其中主节点1台,其余为从节点。每个节点的配置如下:Intel Xeon E3-1231 CPU,16 GB内存,1 TB硬盘,操作系统为CentOS 6.5,Hadoop版本选用1.2.1。
利用搜狗实验室提供的文本分类语料库SogouC作为实验数据[19]。数据集包含12个类别,每个类别有10 000篇文档,数据集大小约为107 MB。采用mmseg4j中文分词器进行分词。
3.2 实验结果
实验采用准确率P(Precision)和召回率R(Recall)来评估分类算法的性能[10],计算式如下:
(17)
(18)
式中TPj表示测试文档集中正确分类到Cj的文档数,FPj表示测试文档集中错误分类到类别Cj的文档数,FNj表示测试文档集中属于类别Cj但被错误分到其他类别中的文档数。
3.3 本文算法的参数选择
取70%的数据集作为训练集,其余30%作为测试集,选6个节点进行测试实验。
参数ξ的取值为任意非负整数,为了得到参数最佳的ξ,实验对ξ的取值从0开始以间隔1000为单位逐渐递增。参数ξ的取值对Pj和Rj的影响,结果如图1所示。

图1 参数ξ的取值对准确率,召回率的影响
从图1的曲线图可以看出,在参数ξ的值从0递增到3000过程中,准确率和召回率也在不断增加,当ξ取值在3000之后,准确率和召回率随着ξ的增加在缓慢减小,直至平稳。当取ξ为3000时准确率和召回率最高,这里取ξ为3000。
4 实验结果分析
4.1 本文算法与朴素贝叶斯文本分类算法的性能对比
取70%的数据集作为训练集,其余30%的为测试集,选择6个节点进行测试实验。两种算法准确率和召回率的对比如图2、图3所示。
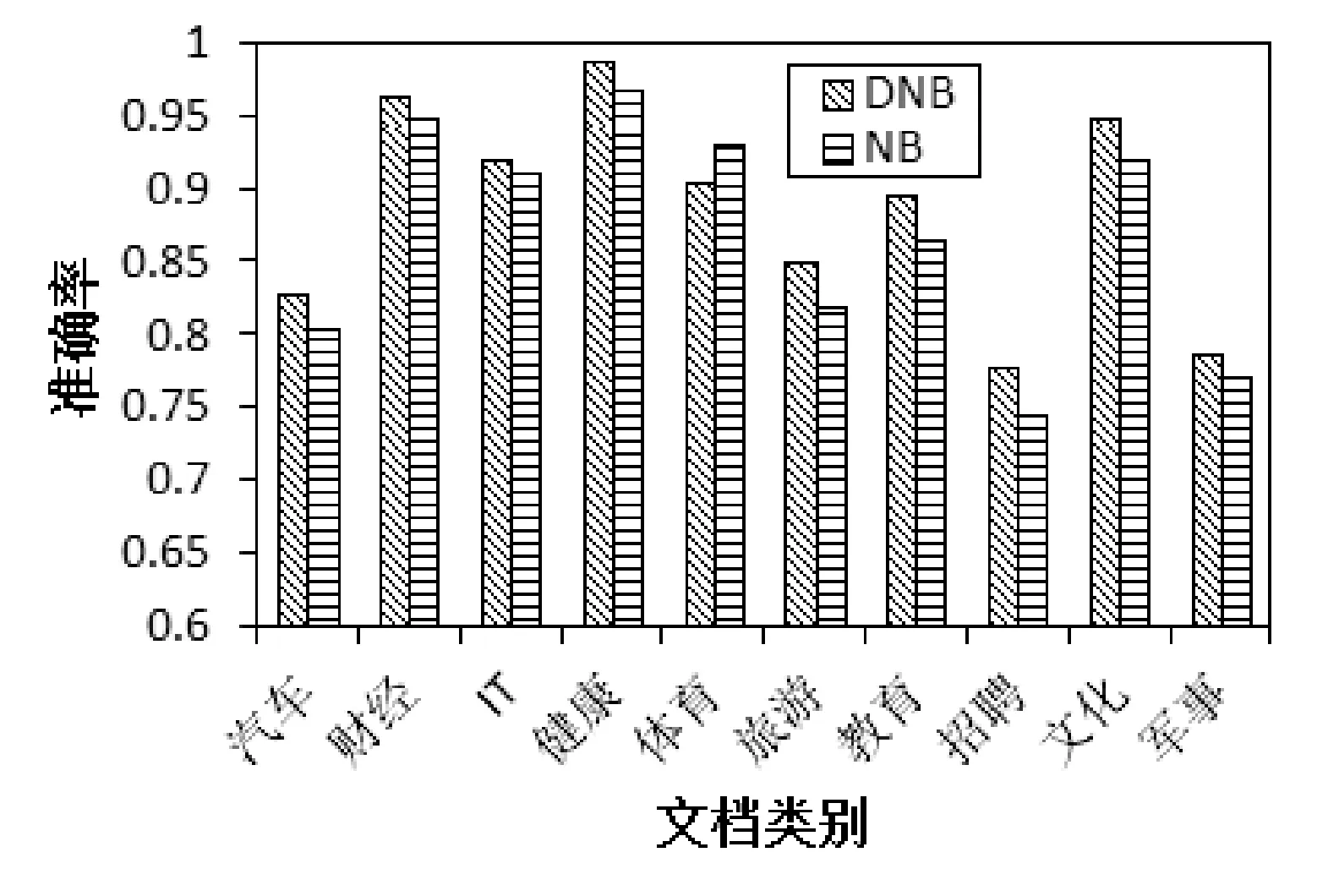
图2 DNB与NB算法准确率的对比
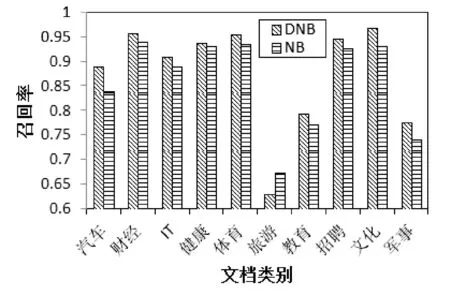
图3 DNB与NB算法召回率的对比
从图2、图3我们可以看出,除个别类外,本文算法(DNB)的准确率和召回率都优于朴素贝叶斯文本分类算法(NB),从而说明经过改进,本文算法提高了分类性能。
4.2 不同数据集对加速比的影响
对数据集进行有返还抽样,分别构造150、250、450、850、1650 MB等5个大小不同的新数据集,然后分别从5个新数据集中取70%作为训练集,其余30%作为测试集,依次选择1、5个节点进行实验。实验结果见表2所示。

表2 不同数据集对加速比的影响
从表2可以看出,当数据集较小时,加速比[20]并不理想。这是由于数据集较小时,节点间通信消耗的时间相对于处理数据时间还多,时间都耗在通信上。但随着数据集的不断增大,处理数据的时间大于节点间的通信时间消耗,加速比有了显著提升。
4.3 不同节点数对运行时间的影响
从1650 MB的数据集中取70%作为训练集,其余30%为测试集,从中选择1、2、3、4、5个节点进行测试。结果如图4所示。
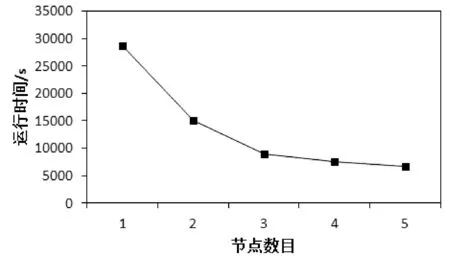
图4 不同节点数对应的运行时间
从图4我们可以看出,运行时间随节点数的增加而显著减小,说明本文算法具有良好的扩展性和高效性。
5 结 语
本文提出了一种基于MapReduce的Dirichlet朴素贝叶斯文本分类算法。为了提高朴素贝叶斯分类器的分类性能,本文根据体征词语义因素以及类内分布情况对权重进行加权调整,以此修正TF-IDF的计算式,并引入统计语言建模技术中的数据平滑方法,以降低数据稀疏问题对分类性能的影响,同时基于MapReduce进行并行计算,以提高分类算法对海量数据的处理能力。实验结果表明,本文算法相较于朴素贝叶斯文本分类算法有较高的准确率和召回率,并具有优良的可扩展性和处理能力。
[1] Jyotishman Pathak.Text Classification Using A Naive Bayes Approach[D].Department of Computer Science Iowa State University.
[2] SangBum Kim,HaeChang Rim,DongSku Yook,et al.Effective Methods for Improving Naive Bayes Text Classifiers[C]//International Conforence on Prical:Trends in Artifical Intelligence,2002:479-484.
[3] Shen Yirong,Jiang Jing.Improving the Performance of Naive Bayes for Text Classification[C]//CS224N Spring,2003.
[4] Aynur Akkus,H Altay Guvenir.K Nearest Neighbor Classification on Feature Projections[D].Department of Computer Engr.and Info.Sei,Bilkent University,Ankara,Turkey,1998.
[5] Taeho Jo.Neuro Text Categorizer:A New Model of Neural Network for Text Categorization[C]//Proceedings of ICONIP,2000:280-285.
[6] Basu A,Watters C,Shepherd M.Support Vector Machines for Text Categorization[C]//Faculty of Computer Science Dalhousie University,Halifax,Nova Scotia,Canada B3H1W5,2003:103c.
[7] Thorsten Joachims.A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization[C]//Proceedings of ICML,1997:143-151.
[8] Nigam K.Using Maimum Entropy for Text Classification[C]//IJCAI-99 Workshop on Machine Learning for Information filtering,1999:61-67.
[9] 梁宏胜,徐建民,成岳鹏.一种改进的朴素贝叶斯文本分类方法[J].河北大学学报:自然科学版,2007,27(3):328-331.
[10] 饶丽丽,刘雄辉,张东站.基于特征相关的改进加权朴素贝叶斯分类算法[J].厦门大学学报:自然科学版,2012,51(4):682-685.
[11] 李艳姣,蒋同海.基于改进权重贝叶斯的维文文本分类模型[J].计算机工程与设计,2012,33(12):4726-4730.
[12] 邸鹏,段利国.一种新型朴素贝叶斯文本分类算法[J].数据采集与处理,2014,29(1):71-75.
[13] Zhang W,Gao F.An improvement to Naive Bayes for text classification[J].Procedia Engineering,2011,15(3):2160-2164.
[14] 丁国栋,白硕,王斌.文本检索的统计语言建模方法综述[J].计算机研究与发展,2015,43(5):769-776.
[15] Lee K H,Lee Y J,Choi H,et al.Parallel data processing with MapReduce:a survey[J].Sigmod Record,2012,40(4):11-20.
[16] ApacheHadoop.Hadoop[EB/OL].[2015-05-04].http://hadoop.apache.org.
[17] Puurula A.Combining modifications to multinomial naive bayes for text classification[M]//Information Retrieval Technology.Springer Berlin Heidelberg,2012:114-125.
[18] 裴颂文,吴百锋.动态自适应特征权重的多类文本分类算法研究[J].计算机应用研究,2011,28(11):4092-4096.
[19] 搜狗实验室.互联网语料库[EB/OL].[2016-01-02].http://www.sogou.com/labs/dl/c.html.
[20] Bauer R,Delling D,Wagner D.Experimental study of speed up techniques for timetable information systems[J].Networks,2011,57(1):38-52.
DISTRIBUTED PARALLEL IMPLEMENTATION OF A NAIVE BAYESIAN TEXT CLASSIFICATION ALGORITHM
Guo Xukun1Fan Bingbing2
1(Guangzhou Sport University,Guangzhou 510500,Guangdong,China)=2(College of Computer Science,South China Normal University,Guangzhou 510631,Guangdong,China)
According to the naive Bayes text classification algorithm in text classification of the existence of data sparse, inaccurate classification and low efficiency problem, this paper proposes a Dirichlet naive Bayes text classification algorithm based on MapReduce. Firstly, according to the words and signs within the meaning of the factors and the distribution of the weight classes is adjusted to be corrected on the TF-IDF; Then, we introduce Dirichlet data smoothing methods which in statistical language modeling techniques to reduce the impact on the classification performance of the sparse data, and we achieve this algorithm parallelization used by MapReduce programming model in the Hadoop cloud computing platform. Through experimental comparison analysis shows that the algorithm significantly improves accuracy and recall rate of traditional naive Bayes text classification algorithm, and it has excellent expansibility and data processing ability.
Naive bayes Text classification TF-IDF correction Data smoothing MapReduce parallelization
2016-01-28。广东省教育厅2015重大科研立项青年项目。郭绪坤,讲师,主研领域:文本分类与数据挖掘,计算机网络。范冰冰,教授。
TP311
A
10.3969/j.issn.1000-386x.2016.11.056
