基于显式和隐式社交网络的混合推荐
2016-12-26兰少华
王 帅 兰少华
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
基于显式和隐式社交网络的混合推荐
王 帅 兰少华
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
传统的社交网络推荐一般依靠用户之间的好友关系,但好友关系不是基于共同兴趣而产生的。针对这种情况,提出通过用户标签所表达的情感兴趣来扩展用户好友关系,形成基于用户好友关系和共同兴趣的混合推荐。利用用户间直接的朋友关系构建显式社交网络,利用标签数据构建隐式社交网络;在显式和隐式社交网络图中分别采用提出的SNA_SPFA(Social Networks Algorithm Based on Shortest Path Faster Algorithm)算法得到推荐结果;最后按照一定权重混合两种推荐结果。实验表明,该方法优于传统的协同过滤方法和社交网络推荐。
社交网络 标签 情感 混合推荐
0 引 言
随着信息技术和互联网的发展,个性化推荐逐渐融入到了人们的日常生活中。而个性化推荐一般需要满足两个基本条件:第一是信息过载,如果用户很容易就能在互联网上找到想要的资源,就不需要个性化推荐了;第二是用户一般没有特别明确的需求,因为如果有明确的需求就可以通过搜索引擎来找到感兴趣的物品。个性化推荐在当前的互联网产品中已被广泛应用,包括大家所熟知的电商推荐、话题推荐、相关搜索、交友推荐等。
如今,社交网络在我们日常生活中开始占据越来越重要的地位,它不仅定义了用户之间的联系,而且隐含了丰富的用户偏好信息。相对于传统的推荐方法,如协同过滤、基于内容的推荐等推荐方法,基于社交网络的推荐较好地利用了用户之间的朋友关系,这和现实生活中向朋友寻求推荐具有较大相似性。大量研究实验表明,基于社交网络的推荐要优于传统的推荐方法。
在社交网络中,标签的应用也越来越广。推荐系统的目的是联系用户的兴趣和相应的物品,而标签作为物品的一种特殊特征,在一定程度上表达了用户对物品的兴趣,所以标签特别适合作为推荐的中间媒介。标签一般分为两种:一种是特定领域的专家给物品打的标签,这种标签一般具有较高的信任度,在属性上更倾向于物品的固有属性;另一种是普通用户给物品打的标签,简称UGC。这种标签一方面表达了用户的兴趣,另一方面表达了物品的语义,从而将用户兴趣和物品联系起来[1]。
1 相关工作
传统的推荐方法主要包括基于内容的过滤和协同过滤。基于内容的过滤通过物品特征和用户偏好来推荐物品。然而,这种方法存在很多局限,目前商业领域几乎没有纯粹的基于内容的推荐系统。协同过滤是推荐系统中最古老的算法,它主要分为两种:一种是基于用户的协同过滤,该算法首先通过用户对物品的评分来计算所有用户之间兴趣的相似度,计算方法一般采用余弦相似性或皮尔逊相关性的方法;然后通过与目标用户兴趣最相似的K个用户去预测目标用户对某一物品的兴趣程度。另一种是基于物品的协同过滤,该算法给用户推荐那些和他们之前喜欢的物品相似的物品[6]。但协同过滤最大的局限在于数据的稀疏性和计算复杂度,而且K值的选择也相应地影响推荐的效果[2]。
随着Web 2.0的发展和兴起,社交网络在人们的日常生活中扮演着越来越重要的角色,而且越来越多的研究者开始将社交网络的方法引入到推荐系统中。研究发现,基于社交网络的推荐效果要优于传统的协同过滤。如文献[3]在3个真实的电影推荐系统和3个图书推荐系统上,分别进行社会化推荐和基于协同过滤的推荐,发现社会化推荐结果的满意度明显高于基于协同过滤的算法。虽然实验存在一些问题,比如不是双盲实验,用户知道结果来自哪个推荐系统,但还是得到了业界认可。部分文献将协同过滤与社交网络的推荐相结合,用户之间边的权重由熟悉程度和兴趣相似度按一定权重混合,然后采用重启型随机游走算法,取得了较好的实验效果。但所采用的重启型随机游走算法计算复杂度过高,且用户全部好友的历史行为数据过于庞大,在实际环境中难以操作[4,5,9,12]。
因此,本文提出一种基于显式和隐式社交网络的混合推荐算法,主要贡献如下:
(1) 对标签进行情感分析,然后利用情感得分计算用户之间的相似度来构建隐式社交网络,扩展用户的好友关系。
(2) 在所构建的显式和隐式社交网络上,采用下文提出的SNA_SPFA算法进行推荐。
(3) 将以上两种推荐结果按照加权组合的方式进行混合,得到最终的推荐结果。
2 基于显式和隐式社交网络的推荐
2.1 显式社交网络
根据用户之间的朋友关系,可以用图来表示一个社交网络。用图G(V,E,W)定义一个社交网络,其中V是顶点集合,每一个顶点代表社交网络中的一个用户;E是边的集合,如果用户Va和Vb是朋友关系,那么就有一条边E(Va,Vb)直接连接这两个用户;而W(Va,Vb)则定义边的权重,在这里代表两个用户之间的熟悉程度或信任程度。
目前社交网络上主要有三种不同的社交网络数据。一种是双向确认的社交网络数据,这类社交网络以Facebook和人人网为代表,好友关系的形成需双方确认,一般采用无向图表示;第二种是单向关注的社交网络数据,这类社交网络以Twitter和新浪微博为代表,好友关系的形成是单向的,一般采用有向图表示;第三种是基于社区的社交网络数据,在这种数据中,用户之间并没有明确的关系,但是这类数据中包含了用户属于不同社区的信息。本文中采用的是双向确认的社交网络数据。
2.2 隐式社交网络
标签作为一种重要的用户行为数据,蕴含了丰富的用户兴趣信息,因此对标签数据的深入研究有助于改进和提高推荐系统的质量。由于让专家给物品打标签的成本较大,而且在Web 2.0时代不能代表用户的个性化情感倾向。而UGC标签是一种表达用户兴趣和物品语义的重要方式,所以本文根据这种UGC标签来分析用户的情感从而进行个性化推荐。
2.2.1 情感分析
本文首先根据所要推荐的领域和常用的情感词典来建立实验所需的情感词典。然后对标签进行情感分析,将标签情感分为正向情感、中性情感和负向情感。最后将标签情感转换为对物品的显式评分,来表示对物品感兴趣的程度。其中正向情感对应1分,中性情感对应0.5分,负向情感对应0分。
2.2.2 隐式好友关系的建立
由于用户对同一个物品可能会打多个标签,我们取多个情感标签评分的平均值来代表用户对物品的评分。将用户所打的标签转换为情感评分后,采用常用的Pearson相关系数来计算用户间相似度,Pearson相关系数的取值从+1(强正相关)到-1(强负相关)。当用户间相似度不小于阈值0.3时,则可在两用户之间建立隐式好友关系。Pearson相关系数的计算公式如下:
(1)
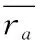
2.2.3 隐式社交网络图
本文通过UGC标签来扩展用户社交关系,若不同用户对相同物品打了相同或相似的标签,则认为用户之间存在着一定程度的隐式好友关系。隐式社交网络通过以下三步来建立:(1)将用户对物品所打的标签按所表达的情感转换为相应的情感评分;(2)通过Pearson相关系数来计算用户之间的相似度,当相似度大于一定阈值时,可建立直接的隐式好友关系,类似于显式网络中直接的朋友关系;(3)用图G′(V,E,W)来表示所建立的隐式社交网络。
2.3 推荐算法
社交网络定义了用户之间的好友关系,而用户行为数据集定义了不同用户的历史行为和兴趣倾向。传统的协同过滤只考虑了用户的历史行为数据,而忽略了用户之间的社交关系对推荐结果的影响。单纯的社交推荐利用了用户之间的社交关系,却忽略了用户的兴趣往往和用户好友的兴趣并不一致。本文就是通过利用这两种数据,在所构建的显式和隐式社交网络图中分别采用相同的算法来计算用户对物品的兴趣程度。
2.3.1 信任度计算
由于现实生活中,好友的熟悉程度存在很大差别,为了更真实模拟现实生活,本文认为用户之间的熟悉程度和信任程度正相关。用户间共同好友越多,则两个用户之间更加信任彼此,且信任可以在网络中进行传播[7]。针对社交网络图,通过以下方法来计算用户间的信任度:
(1) 在所构建的显式社交网络图G(V,E,W)中,首先对所有相连的边分配一个初始的权重Tij=0.5来表示用户间的信任程度;对没有边相连的用户,我们认为用户之间初始的信任程度为0。在隐式社交网络图G′(V,E,W)中,初始边的权重即上文中计算的用户间相似度。(2) 在社交网络图G(V,E,W)和G′(V,E,W)中,用户节点之间路径大致分为单路径和多路径。单路径意味着只有一条从ai到as的路径,图1表示从ai到as唯一的一条路径。对单路径用户之间信任程度的计算方法为:
Tis=∏(m,n)∈path(i,s)Tmn
(2)
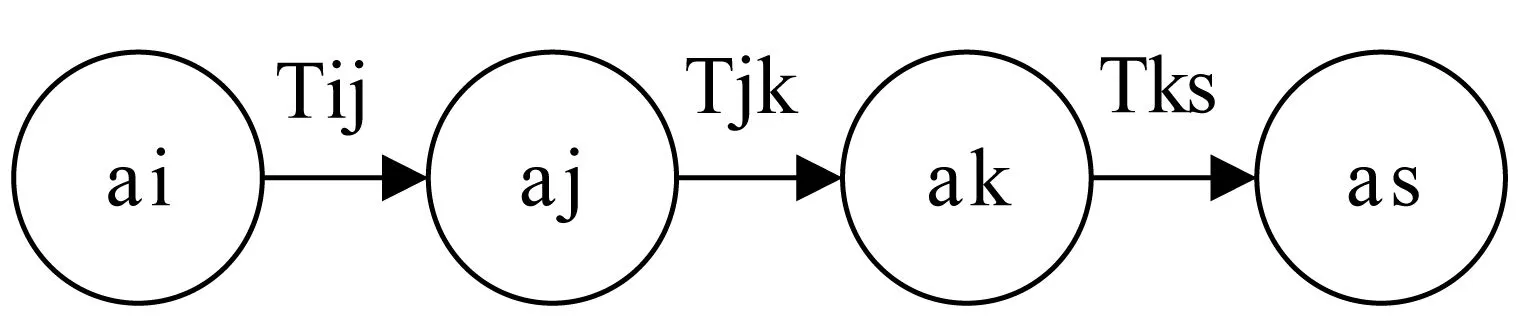
图1 单路径信任传播
通常,所构造的社交网络图中,用户节点之间的路径不止一条。图2表示从ai到as有两条路径。Path(ai,as)={((ai,aj),(aj,ak),(ak,as)),((ai,ar),(ar,as))}。
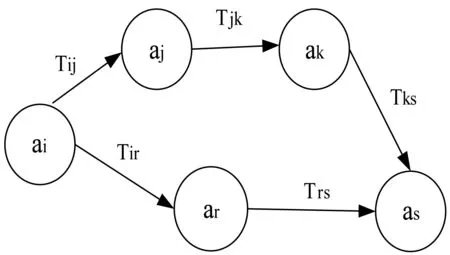
图2 多路径信任传播
为了计算多路径用户之间的信任程度,采用如下的计算方法,这种方法通过用户Ui的所有邻居节点采用加权平均的方法来计算。计算方法如下:
(3)
其中N(i)为Ui的所有邻居节点。
2.3.2 预测评分
当预测用户对某物品p的兴趣时,从目标用户节点首先访问直接相连的用户,但是有时这个相邻节点并没有对物品p的评价或者用户之间具有较低的信任值,所以需要访问不相邻的其他用户节点。本文采用如下公式来预测用户对物品p的兴趣:
P(a,p) =∑b∈V(a)TabRbp
(4)
其中V(a)是分别在显式或隐式网络图中,从目标用户Ua能访问到的所有用户节点。Tab是用户Ua和Ub的信任度,Rbp是用户Ub对物品p的兴趣度,由用户的行为数据来确定,而P(a,p)是预测用户Ua对物品p的兴趣度。
2.3.3 SNA_SPFA算法
为了计算从用户Ua能访问到的所有用户节点,我们采用一种SNA_FPFA算法。该算法分别在显式和隐式社交网络图中寻找符合一定信任度的用户节点,并返回相应的信任度。
在现实生活中,我们总是向有限的朋友寻求推荐,所以为了和现实中场景更加相似,本文中V(a)并不是社交网络图中所有用户节点。SNA_SPFA算法设定了2个全局限制参数:trust_threshold和max_nodes。trust_threshold定义了节点间最小信任度阈值,max_nodes定义了计算过程中从目标用户节点访问的最大节点数。
在计算目标用户对物品兴趣的过程中,本文所采用的SNA_SPFA算法计算过程类似于SPFA算法,采用深度优先遍历的方法来逐层访问其他用户节点,遍历过程中采用优先队列来存储访问到的节点。
算法:SNA_SPFA
输入:图G(V,E,W)或G′(V,E,W),目标起始节点OriginNode
输出:目标用户感兴趣的物品集
1:InitQueue(Que);
//Que是一个优先队列
2:A=getAdjacentNodes(OriginNode);
//获得目标节点的相邻节点
3:for every node i in A do
4:EnQueue(Que,i);
//插入相邻节点到队列中
5:end for
6:while(!Que.Empty()){
7:DeQueue(Que,u);
//弹出队列中头元素u
8:if((++visitedNodes)>max_nodes)
return false;
9:if((u.rating!=NULL)&&(GetTrust(OriginNode,u)>=trust_threshold)){
//节点u满足条件
10:u.visited = TRUE;
//标记u已被访问过
11:return Response(rating)}
//返回起始目标节点感兴趣的物品和兴趣度12:else{
13:A= getAdjacentNodes (u);
14:for every node i in A do
15: if((!i.visited)&&(i!= OriginNode))
//节点i没被访问过且不是原始目标节点
16: EnQueue(Que,i);
17:end for}}
2.4 混合推荐方法
首先分别在显式社交网络和隐式社交网络中按照上文算法得到目标用户Ua最感兴趣的前N个物品集合,分别记为Rc和Rs。对Rc中的任一物品p1,目标用户对它的兴趣度为P(a,p1);对Rs中的任一物品p2,目标用户对它的兴趣度为P(a,p2)。然后对由两种社交网络中得的推荐结果,按一定权重混合用户对物品p的兴趣度,混合公式如下:
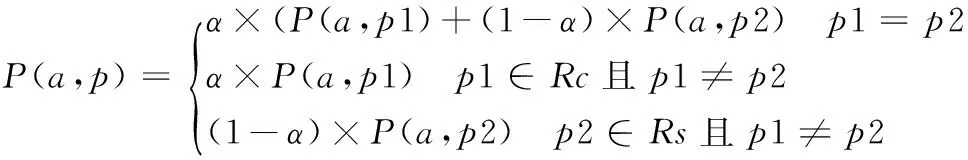
(5)
混合方法对只在Rc中的物品p1,兴趣度按权重α计算;对只在Rs中的物品p2,兴趣度按权重(1-α)计算;对同时出现在Rc和Rs中物品,则分别按照权重α和(1-α)混合后相加。最后按照混合后用户对物品的兴趣度排序,取前N个兴趣度高的物品得到最终的推荐结果。
3 实验评估
3.1 实验设计
本文采用的数据集是ACM第5次推荐系统大会公开的last.fm数据集,该数据集收集了last.fm在线音乐网站上1892位用户的历史行为数据。该数据集包括1892位用户和17 632首音乐、12 717对用户之间的朋友关系、92 834条用户听歌记录,11 946个标签和186 479条用户对歌曲所打的标签记录。
该数据集中,用户对音乐只记录了听歌次数而没有直接的评分。本文将用户对音乐的收听次数转换为间接评分来进行实验,其中收听次数越多则间接评分越高。实验中将数据集随机分为8份,其中训练集占7份,测试集占1份。为了保证测评指标不是过拟合的结果,需要进行8次实验,每次使用不同的测试集,最后将8次实验测出的评测指标的平均值作为最终的评测指标。每次实验中通过直接的朋友关系构造显式社交网络,通过标签来构建隐式社交网络,根据好友对物品的间接评分来预测目标用户对物品的兴趣度。为了比较实验效果,将本文所采用的混合社交推荐方法与传统协同过滤和社交网络推荐进行对比。
3.2 评估标准
预测准确度是衡量一个推荐系统或推荐算法预测用户行为的能力。由于离线的推荐算法有不同的研究方向,预测准确度主要有两个指标:一是评分预测,主要通过均方差和平均绝对误差来评价;二是TopN推荐,主要通过准确率和召回率来度量。为了比较三种方法的好坏,本文采用准确率(precision)、召回率(recall)和F1值来度量。
准确率描述的是最终推荐列表中有多少比例是已经发生过的用户-物品评分记录。召回率描述的是算法推荐的物品有多少包含在最终的推荐列表中。而F1值是准确率和召回率的一种加权平均。算法对用户Ua推荐N个物品(记为R(a)),令用户Ua在测试集上喜欢的物品集合为T(a)。则准确率、召回率和F1值通过以下公式计算:
(6)
(7)
(8)
3.3 实验结果及分析
在本文算法中,主要有二个参数对实验影响较大,分别是最大节点数max_nodes(分别对应其他两种方法中相似用户数K和好友数K)和α。在本文的混合推荐中,参数α决定了显式和隐式社交网络推荐的权重。从图3中实验发现,当α=0.7时,实验效果较好,这说明并不是显式社交推荐所占权重越大越好,也验证了显式社交网络中朋友关系并不是基于共同兴趣而产生的。而协同过滤中相似用户K和传统社交推荐中最熟悉的好友数K也是实验的重要参数。所以,本文详细比较了不同K值下三种推荐方法的推荐质量。
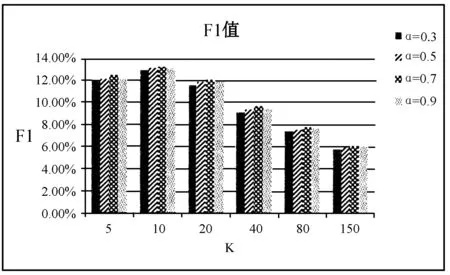
图3 在不同α值下混合推荐的F1值
图4表示三种方法中准确率随最近邻个数K的变化曲线,图5表示三种方法中召回率随最近邻个数K的变化曲线,图6的结果由图4和图5中数据来决定,但它反映了实验的总体效果。从图6中可以看出,当K=10时,三种方法在该数据集上的F1值都达到最大。这同时也启示我们可以对历史行为较少的用户导入少量社交信息,从而在一定程度上解决用户冷启动问题(用户冷启动指新用户到来时,由于缺少用户的行为数据而无法预测其兴趣,也就无法给用户做个性化推荐)。从实验结果可以看出,本文提出的方法要优于传统的协同过滤和社交网络推荐。
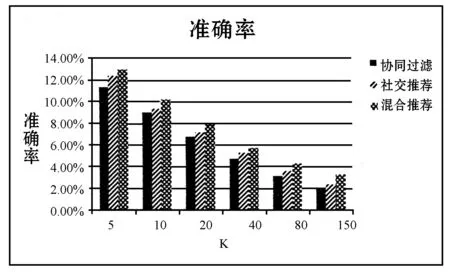
图4 在不同K值下三种方法的准确率
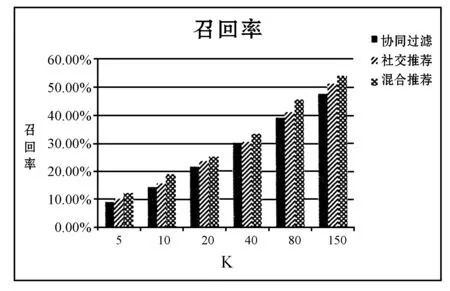
图5 在不同K值下三种方法的召回率
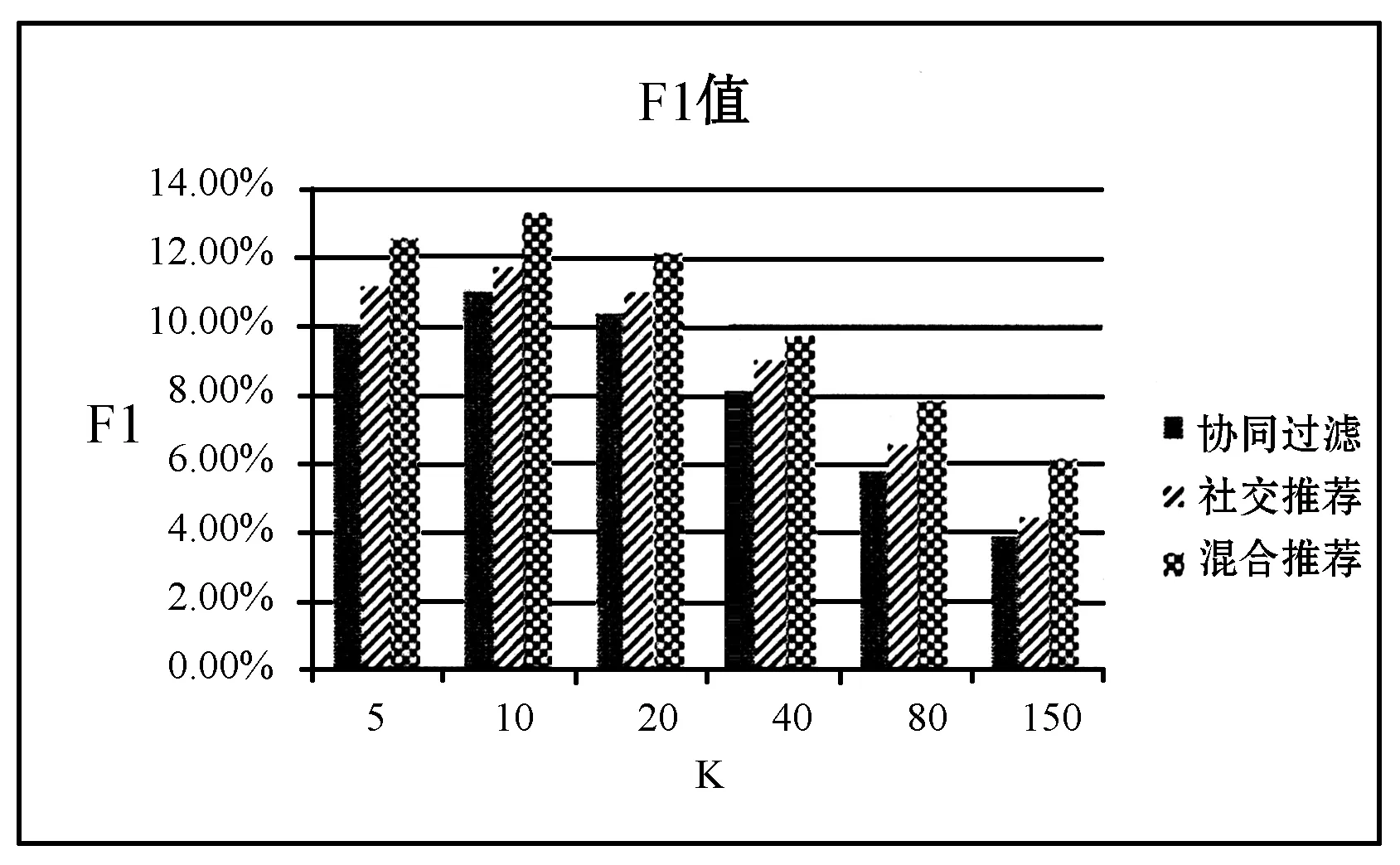
图6 在不同K值下三种方法的F1值
4 结 语
本文提出利用标签数据来扩展用户的好友关系,进一步挖掘用户的社交信息,然后分别在所构建的显式和隐式社交网络中进行推荐,最后按一定权重混合两种推荐结果。实验结果表明,本文方法要优于传统的推荐方法,但也存在一些不足之处,具有一定提升空间。未来将进一步研究隐式社交网络的构建和相应的推荐方法。
[1] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2] Xing Z,Wang X X,Wang Y.Enhancing collaborative filtering music recommendation by balancing exploration and exploitation [C]//Proceedings of the 15th Conference on the International Society for Music Information Retrieval (ISMIR 2014),2014:445-450.
[3] Sinha R,Swearingen K.Comparing Recommendations Made by Online Systems and Friends[C]//DELOS workshop:personalisation and recommender systems in digital libraries,2001.
[4] Konstas I,Stathopoulos V,Jose J M.On social networks and collaborative recommendation[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval.ACM,2009:195-202.
[5] Yang L,Gopalakrishnan A K.A collaborative filtering recommendation based on user profile and user behavior in online social networks[C]//2014 International Computer Science and Engineering Conference (ICSEC).IEEE,2014:273-277.
[6] 罗辛,欧阳元新,熊璋,等. 通过相似度支持度优化基于K 近邻的协同过滤算法[J].计算机学报,2010,33( 8):1437-1445.
[7] He C B,Tang Y,Chen G H,et al.Collaborative Recommendation Model Based on Social Network and Its Application[J].Journal of Convergence Information Technology,2012,7(2):253-261.
[8] Han J W,Kamber M,Pei J.Data mining:concepts and techniques:concepts and techniques [M].Amsterdam:Elsevier,2011.
[9] 俞琰,邱广华.用户兴趣变化感知的重启动随机游走推荐算法研究[J].现代图书情报技术,2012,28(4):48 -53.
[10] 冯勇,李军平,徐红艳,等. 基于社会网络分析的协同推荐方法改进[J].计算机应用,2013,33( 3):841-844.
[11] Yang X W,Steck H,Liu Y.Circle-based recommendation in online social networks[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2012:1267-1275.
[12] Yan Y,Qiu G H.Algorithm of Friend Recommendation in Online Social Networks Based on Local Random Walk [J].Systems Engineering,2013,31(2):47-54.
[13] Chen H C,Chen A L P.A music recommendation system based on music data grouping and user interests[C]//Proceedings of the tenth international conference on Information and knowledge management.ACM,2001:231-238.
MIXED RECOMMENDATION BASED ON EXPLICIT AND IMPLICIT SOCIAL NETWORKS
Wang Shuai Lan Shaohua
(SchoolofComputerScienceandEngineering,NanjingUniversityofScienceandTechnology,Nanjing210094,Jiangsu,China)
Traditional social networks recommendation usually relies on friendships between users,but the friendships are not based on common interests.In light of this situation,we propose to expand users’ friendships by emotion and interest expressed in users’ tags,and to form the mixed recommendation based on users’ friendships and common interests.First,we use direct friendship between users to construct an explicit social network,and use tag data to construct an implicit social network.Then we apply the proposed SNA_SPFA algorithm to explicit and implicit social graphs respectively to get recommendation result.Finally,we mix the two recommendation results according to a certain weight.Experiments show that this method is superior to traditional collaborative filtering methods and social network recommendations.
Social networks Tag Emotion Mixed recommendation
2015-08-15。国家自然科学基金项目(61170035)。王帅,硕士生,主研领域:推荐系统,社交网络,网络安全。兰少华,教授。
TP391
A
10.3969/j.issn.1000-386x.2016.11.009
