基于海量数据的不平衡SVM增量学习的钓鱼网站检测方法
2016-12-21叶志雄王丹弘
叶志雄,王丹弘
(中国移动通信集团广东有限公司,广州 510635)
基于海量数据的不平衡SVM增量学习的钓鱼网站检测方法
叶志雄,王丹弘
(中国移动通信集团广东有限公司,广州 510635)
钓鱼网站每年在电子商务、通信、银行等领域给用户造成极大损失,成功有效的防范钓鱼网站成为一项艰巨任务。本文通过对实际数据的分析,提取了URL相关特点、网页文本内容两方面特征描述网页,然后对不同特征构建相应分类器,根据增量学习思想优化各分类器,提升算法在线学习能力。最后采用分类集成的方法综合各个分类器的预测结果,达到对钓鱼网站在线智能检测的目标。实验表明,集成分类具有良好的在线学习能力和泛化能力。
增量学习;钓鱼网站;不平衡SVM方法;集成分类
随着互联网的高速发展,人们消费模式的改变,网络消费成为一种普遍的消费方式,但网络给人们带来生活便利的同时,也带来了财产安全威胁。因此,如何有效保证网络安全成为一个重要的热点问题。钓鱼威胁是众多网络安全问题比较突出的一个,钓鱼网站的智能检测已然成为网络安全领域最关注的问题之一。钓鱼网站是通过模仿正规网站的URL地址、网站内容等,欺骗用户浏览、注册、登录,钓鱼者通过网站后台获取用户私人信息,盗取用户网上账户财产,或出售用户信息获得非法利益。
针对钓鱼网站带来的威胁,互联网公司纷纷推出相关浏览器插件,虽然取得了良好效果,但这些插件对钓鱼网站的检测效果仍不尽人意。目前关于防范钓鱼网站的研究很多,但以国外研究为主,针对的主要是英文网站,且在网站的特征选择上,以网站URL地址、网站排名等信息作为网站特征进行检测钓鱼网站。而通过实验,对收集到的钓鱼网站进行分析,以URL地址等为特征的钓鱼网站只占约10%,而模仿正规网站的网页内容是钓鱼网站的主要表现形式。因此,以网页内容为主要特征,结合URL等特征,可以有效的对钓鱼网站进行智能检测。
在实际网络构成中,正规网站的数量往往远大于钓鱼网站的数量,因此检测数据集存在严重的类别不平衡现象,而常用的分类预测算法对不平衡数据集的分类结果存在偏斜性。另一方面,钓鱼网站层出不穷,不断更新,分类预测算法利用原来数据集训练好的分类器,面对新增数据集具有一定局限性,需要重新训练,这会增加模型复杂程度,及系统计算时间。基于以上的分析,本文提出了一种新的检测钓鱼网站方法,基于URL和网页内容的综合特征,采用增量式的不平衡支持向量机方法,在降低误判率和漏判率的同时,也降低了检测网站的时间开销,达到快速有效的检测钓鱼网站的目的。通过对大量、真实的数据集的实验表明,新提出的方法分类效果要优于传统分类方法,并具有良好的鲁棒性和实用性。
1 钓鱼网站特征选取和检测过程
1.1 钓鱼网站特征选取
通过实验观察,钓鱼网站主要在以下几个方面与正规网站不同:host长度,和目标网站的编辑距离,服务器位置,首页包含的资源数,网站内的连接数,网站深度,文本内容等,大部分主要表现在URL上,称为URL特征,URL特征的分析是检测钓鱼网站的基础环节。
除了URL特征,网站内容是钓鱼欺骗信息的主要展示渠道,对钓鱼者意图具有较强的表达能力。因此对于给定的网站,首先检查网页中是否含有文本输入部分,如果网页中至少有一个文本输入部分,则对网页进行页面内容特征提取,如果没有,就判定这个网站是可信的,接着提取下一个网站。通过已有文献分析结合实验观察,选取以下特征来表征页面内容。
URL相关特征。包括host长度、和目标网站host的编辑距离、服务器位置、首页包含的资源数、网站内的链接数、网站深度等6个维度。
网页文本内容主要通过TF-IDF算法进行词频统计,频次高的作为分类维度。
根据以上分析,可以选取URL特征、网页文本内容两种特征来描述网站,每种特征可以构造基础分类器,通过集成分类结果得到综合判定结果。
1.2 钓鱼网站检测过程
对于给定检测网站,先提取各部分特征信息,构建各个基础分类器,综合各分类结果得到最终判定结果,具体检测过程如下。
(1) 对待检测网站提取特征信息。
(2) 对各部分特征构建基础分类器。
(3) 集成各分类结果,对待检测网站进行判定,得到判定结果。
2 相关算法描述
2.1 支持向量机
对于给定分类问题,其训练样本集为{xi, yi},i=1, 2, 3, … n, {xi}∈R, yi∈{±1}。SVM的目标就是构造一个最优分类超平面,使得类别间的分类间隔最大。通过选取适当核函数使k(xi,xj)=φ(xxi) φ(xj),引入松弛变量ε1,ε2,…εn,及惩罚因子C,求解如下规划问题。

为了求解该优化问题,建立了拉格朗日函数:
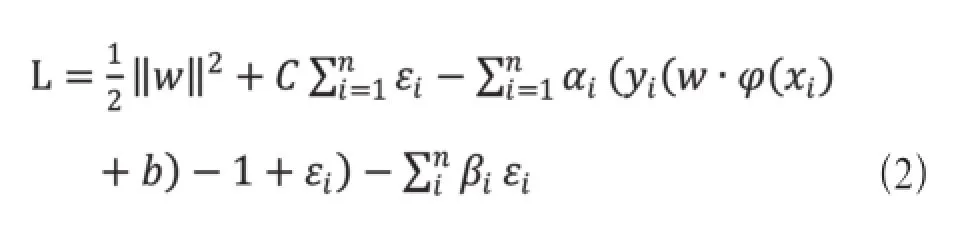
其中αi,βi为拉格朗日乘子。
根据对偶原理,转化其对偶问题为

求得超平面法向量为

选取某个0<αi<C所对应的xi, yi,代入
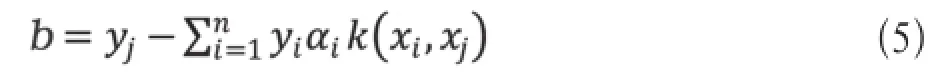
求得判别函数为
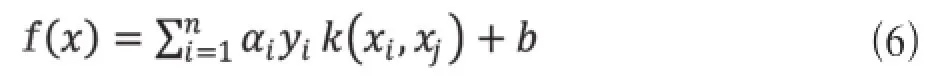
2.2 增量学习
在现实应用中,训练初期对数据理解的局限性和面对问题的复杂性,很难定义完整的训练集,面对不断更新的数据,也很难收集一个完整的训练集,因此需要分类器具备学习能力,并且在学习过程中保持学习精度甚至提高学习精度,这是增量学习的思想。
在SVM理论中,支持向量SV对增量学习具有十分重要意义,SV集充分描述了整个训练数据集的特征,对SV集的划分等价于对整个样本集的划分,因此可以用SV集取代整个训练集进行训练。
对(7)式求得最优解α=(α1,α2,…αn)使得每个样本满足优化问题的KKT条件:
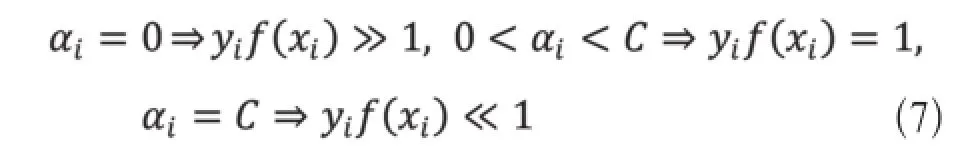
其中非零的αi为SV。考虑函数系f(x)=h,可知f(x)=0为分类面,f(x)=±1为分类间隔面,则α=0对应的样本分布在分类器分类间隔面之外,0<α<C对应的样本位于分类间隔面之上,α=C对应的样本位于分类间隔面关于本类的异侧。研究表明,满足KKT条件的新增样本将不会改变SV集,而违背KKT条件的新增样本将使SV集发生变化。增量学习的目标就是在样本增加过程中找出能够使SV集发生变化的新样本并加以训练得到新的模型,关注SV集的变化可以保持训练精度的同时有效降低训练数据的数量,这是区别重复学习的主要特点。
根据以上的分析,增量学习算法主要过程如下。
(1)定义初始训练样本集合为N,定义增量学习过程中满足KKT条件的样本存放集合M,对于给定的初始样本集L1,则有N=L1。
(2)以初始样本集L1训练得到初始分类器H1,以H1检验增量样本集W1,其中违背KKT条件的样本记为M1,符合KKT条件的样本记为K1,若M1=φ则本轮增量学习结束,否则转到第三步。
(3)令N=N∪M1,M=M∪K1,对N训练得到增量分类器ZH1。
(4)对M用ZH1进行再次分类得到违背KKT条件的样本ZM1,若ZM1=φ,则ZH1为最终分类器,否则令N=N∪ZM1,进行再次训练得到修正增量分类器XZH1。
在第四步可以不断迭代直到对形成的分类器在对数据分类时不存在违背KKT条件的情况,但不限制迭代次数会影响分类效率,因此,可以人为限定一个阈值,具体可以根据实验决定。通过上述过程就完成了一次增量学习。
2.3 不平衡SVM算法
在钓鱼网站检测中,正规网站的数量远远大于钓鱼网站的数量,样本集存在类别不平衡的情况,用标准的SVM方法进行分类时结果存在偏斜性。对此提出了不平衡SVM方法,在标准SVM方法中,影响SVM精度的是沿分离超平面的法向量w方向的分散程度,用投影标准差来表示,在实际应用时,先用标准SVM方法训练得到一个分离超平面的法向量,计算各类样本投影到法向量上的投影值的标准差,根据各类样本数和标准差得到各类惩罚因子,再用标准SVM方法训练得到新的分离超平面。在增量学习过程中,计算SV集在法向量上的投影值的标准差,进而得到惩罚因子。
设给定有S个样本点的训练集s={(xi, yi)},其中xi∈R, y_i∈{+1,-1}, i=1, 2, …n。不平衡SVM模型的形式如下。

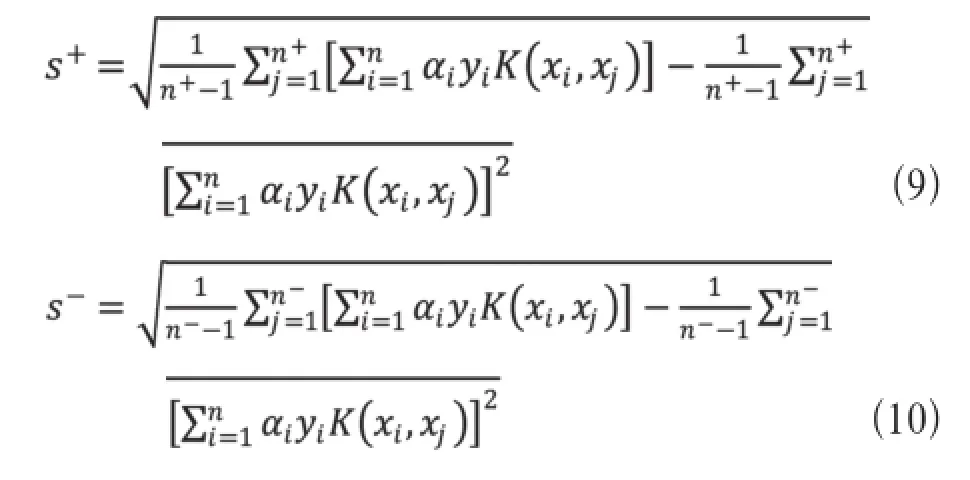
为了求解(11)式,建立拉格朗日函数为

其中,αi,βi,γi为拉格朗日乘子。
转化为求其对偶规划问题如第(3)式,其中
0≤αi≤C+,yi=1, i=1, 2, … n+
0≤αi≤C-,yi=1, i=n++1, … n
由此可得αi(i=1, 2, … n),选取位于区间(0, C)的分量计算b*得


图1 实验框架图
最后构造决策函数为
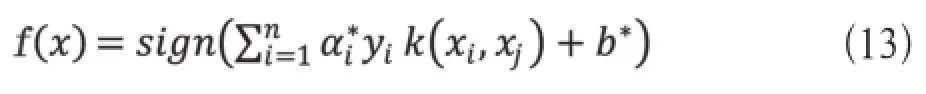
2.4 集成分类
集成学习是用有限个学习器对同一个问题进行学习,按照分类器之间的种类关系可以把集成学习分为以下两种。
(1)同态集成学习:指集成的基础分类器都是同一种分类器,只是这些基础分类器的参数不大相同。
(2)异态集成学习:指使用各种不同训练算法的分类器进行集成。
本文采用的是同态集成学习,对于不同的特征,采用的都是增量学习的不平衡SVM方法,通过对各个基础分类器预测结果的加权平均取符号得到最终预测结果,计算公式如下。
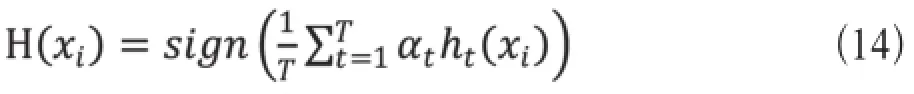
其中T为基础分类器个数,αt为对应基础分类器权重,ht(xi)为对用基础分类器预测结果。
3 实验结果与评估
实验使用数据以用户上网日志数据和分布式爬虫获得的页面数据为主,通过相关技术提取了两个方面特征描述检测网站,利用本文提出的基于增量学习的不平衡SVM方法,采用配置的大数据检测平台,集成各方面的分类结果得到实验最终结果,实现可疑网站的钓鱼检测。
3.1 大数据检测平台
获取用户上网日志数据,结合爬虫集群,以海量的页面数据作为数据源;在数据存储上采用经典的分布式存储系统HDFS与NOSQL类分布式数据库(如MongoDB)相结合的方式;在计算层上则采用目前如火如荼的Spark计算框架,在Spark上实现关键的钓鱼网站甄别算法。具体实现框架如图1所示。
3.2 评估方法
本次实验利用混淆矩阵(表1)中的数据计算准确率、覆盖率等评估模型,用到的评估参数有负类准确率(NA)、正类覆盖率(PA),根据不平衡数据集特点,采用G-means值评价预测结果。计算公式如下。


表1 混淆矩阵
其中,TP表示本来为正类预测也为正类的个数,FP表示本来为负类预测为正类的个数,FN表示本来为正类预测为负类的个数,TN表示本来为负类预测为负类的个数。
3.3 实验结果分析
本次实验数据共有100 000个样本,其中钓鱼网站样本1 000个,根据前面提出的算法,选定初始样本集,并进行9次增量学习实验,为了得到和其它方法的结果比较,用同一个样本集分别使用标准SVM方法和本文提出的基于增量学习思想的不平衡SVM方法进行检测,并通过集成学习综合各基础分类器的预测结果,得到最终判定标准。每次实验中遵循训练集和测试集为3:1的比例,测试集从总样本中随机抽取得到,并且每次实验训练集和测试集中正规网站和钓鱼网站的比例相近,具体实验结果如表2所示。

表2 标准SVM方法和增量不平衡SVM方法增量学习过程预测结果
在图2中,1表示标准SVM方法,2表示不平衡SVM方法,通过图2(a)知道,标准SVM方法具有较高的漏判率,较低误判率,不平衡SVM方法具有较低漏判率,较高的误判率。在增量学习过程中,不平衡SVM方法具有较低的漏判率,尽可能多的检测出要检测的目标,虽然起始误判率较高,但在后续分类器学习过程中,误判率呈下降趋势,而且误判的负类部分可以通过人工检测剔除,误判的正类部分可不断加入后续的学习过程继续检测。因此,增量式不平衡SVM方法相较于传统SVM方法对不平衡数据集具有更好的分类效果。
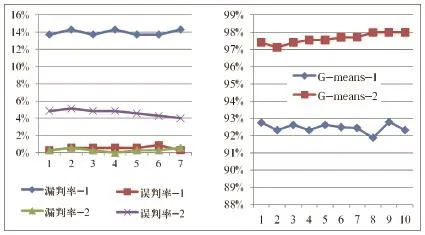
图2 不平衡SVM方法和标准SVM方法误漏判率(a)和准确率(b)比较
通过图2(b)可以看出,增量不平衡SVM方法整体预测精度要好于标准SVM方法,虽然开始有所下降,但随着样本量增加,标准SVM方法预测准确率维持在92%~93%之间并有少许波动,波动的原因可能是随着增加新的数据集,模型重新训练造成分类器改变较大,因此分类准确率不稳定;而不平衡SVM方法准确率在97%以上,且随着增量学习过程,准确率稳定并有少量提高,这是在学习过程中,分类器不断得到了修正,所以具有更好的分类效果。总之,增量式的不平衡SVM方法为不平衡数据集提供了一条在线学习的有效途径。
4 结论
本文提出了一种有效的钓鱼网站检测方法,根据数据集特点,提取了两方面网页的特征,基于增量学习思想,采用不平衡SVM方法构建各基础分类器,通过集成学习综合各基础分类器的预测结果,得到最终分类。通过实验结果分析,说明增量不平衡SVM方法在准确度上略好于标准SVM方法,训练速度上有较大提升,并具备在线学习能力,是一种有效的钓鱼网站在线智能检测技术。
[1]JCranor L F, Egelman S, Hong J I, et al. Phinding phish: Evaluating anti-phishing tools[C]. Proceedings of the 14th Annual Network and Distributed System Security Symposium (NDSS'07), USA:ACM New York 2007:88-99.
[2]Pan Y, Ding X H. Anomaly based web phishing page detection[C].Computer Security Applications Conference,Miami: ACSAC 2006 22nd Annual, 2006: 381-392.
[3]Sanglerdsinlapachai N, Rungsawang A. Using domain top-page similarity feature in machine learning-based web phishing detection[C]. 2010 Third International Conference on Knowledge Discovery and Data Mining,Phuket:CPS,2010: 187-190.
[4]Kim Y G, Cho S Y, Lee J S, et al. Method for evaluating the security risk of a website against phishing attacks[J]. Lecture Notes in Computer Science, 2010(5075):21-31.
[5]Santhana L V,Vijaya M S. Efficient prediction of phishing websites using supervised learning algorithms[J]. Procedia Engineering, 2012(30):798-805.
[6]He Mingxing, Homg Shi-Jinn. An efficient phishing webpage detector[J].Expert Systems with Applications,2011(38):12018-12027.
[7]周伟达,张莉,焦李成. 支撑矢量机推广能力分析[J]. 电子学报,2001,29(5):590-594.
[8]肖嵘, 王继成, 孙正兴, 等. 一种SVM增量学习算法α-ISVM [J].软件学报, 2001,12(12)pp.1818-1824.
[9]刘万里, 刘三阳, 薛贞霞. 不平衡支持向量机的平衡方法[J].模式识别与人工智能, 2008(4):136-141.
Detection method of phishing website based on imbalance SVM-incremental learning of massive data
YE Zhi-xiong, WANG Dan-hong
(China Mobile Group Guangdong Co., Ltd., Guangzhou 510625, China)
For each year, phishing website in electronic commerce, communications, banking and other areas to give users a great loss, so successfully and effectively prevent phishing website become a diffi cult task. In this paper, through the analysis of the actual data, extracts 2 kinds of characteristics such as the characteristics of URL, webpage text content to describe the page, classifiers are then built based on these different feature representations, and optimized based on the theory of incremental learning, the online learning ability of the algorithm is improved. Finally, the classifi cation ensemble method is used to synthesize the prediction results of each classifi er, which can achieve the goal of online intelligent detection for phishing website. According to the experimental results, the ensemble classifi cation has good online learning ability and generalization ability.
incremental learning; phishing website; imbalance SVM method; ensemble classifi cation
TN918
A
1008-5599(2016)12-0026-06
2016-11-24
