高炉炼铁过程多元铁水质量非线性子空间建模及应用
2016-12-17宋贺达周平王宏柴天佑
宋贺达 周平 王宏,2 柴天佑
高炉炼铁过程多元铁水质量非线性子空间建模及应用
宋贺达1周平1王宏1,2柴天佑1
高炉炼铁是一个物理化学反应复杂、多相多场耦合的大滞后、非线性动态系统,其关键工艺指标—铁水质量参数的检测、建模和控制一直是冶金工程和自动控制领域的难题.本文提出一种面向控制的数据驱动高炉炼铁多元铁水质量非线性子空间建模方法.首先,为了提高建模效率和降低计算复杂度,采用数据驱动典型相关性分析与相关性分析相结合的方法提取与铁水质量相关性最强的关键可控变量作为建模的输入变量;同时,为了更好地反映高炉非线性动态特性,将相关输入输出变量的时序和时滞关系在建模过程进行考虑;最后,采用基于最小二乘支持向量机(Least square support vector machine, LS-SVM)的非线性Hammerstein系统子空间辨识方法建立数据驱动的多元铁水质量非线性状态空间模型.同时,将核函数表示的模型非线性特性用多项式函数拟合,在仅损失很小模型精度的前提下大大降低模型的计算复杂度.基于实际数据的工业试验验证了所提建模方法的准确性、有效性和先进性.
高炉炼铁,子空间辨识,Hammerstein模型,典型相关性分析,非线性系统建模,最小二乘支持向量机,多元铁水质量
钢铁是国民经济的命脉,高炉炼铁则是钢铁生产中最为重要的环节之一.如图1所示,整个高炉炼铁系统分为高炉本体、给料系统、热风系统、煤粉喷吹系统、高炉煤气处理系统以及出铁系统等几个子系统,其中高炉本体又可分为炉喉、炉身、炉腰、炉腹和炉缸等几个部分.高炉炼铁时,铁矿石、焦炭、溶剂按一定比例及布料制度逐层从高炉顶部装载到炉喉中,在其下部将预热的空气、氧气和煤粉鼓入炉缸中,空气、氧气、煤粉和焦炭在高温作用下发生一系列复杂物理化学反应,生成大量的高温还原性气体,这些还原性气体不断向上运动将铁从铁矿石中还原出来,而上行的气体最终变为高炉煤气从炉顶回收.炉料则随着炉缸中焦炭的不断燃烧和铁水的不断滴落逐渐向下运动,在下降过程中,炉料经过加热、还原、熔化等一系列复杂的物理化学变化,最终生成液态的生铁和炉渣从出铁口排出[1−2].

图1 高炉炼铁过程示意图Fig.1 diagram of a typical BF ironmaking process
高炉炼铁的目标是实现冶炼过程的高产量与低能耗,为了实现这一目标,就应对高炉内部状态进行实时监测与有效控制.然而高炉内部冶炼环境极其严酷,反应最剧烈的区域温度高达2000多度,压强高达标准大气压的4倍左右,且伴随着固、液、气多相共存的状态,使高炉内部状态的实时监测难以实现,从而难以对高炉进行优化控制.目前,被广泛用来间接反映高炉内部状态的指标为铁水质量参数,综合性的铁水质量指标通常采用硅含量([Si])、磷含量([P])、硫含量([S])和铁水温度(Molten iron temperature,MIT)来衡量.硅含量是评定高炉炉况稳定性和生铁质量的重要指标,也是表征高炉热状态及其变化的标志之一,硅含量的变化可由多种高炉内部状态变化引起,比如,熔化区域的垂直位移、原料的变更和热量流动等[3].硫和磷在钢材中均是有害元素,在高炉冶炼过程中应严格控制铁水中的硫含量和磷含量.硫含量过高说明渣铁之间的脱硫反应不够彻底.铁水温度是物理热的表征,是影响高炉稳定顺行及节能降耗的重要指标.采用这四种铁水质量参数作为高炉内部状态的评判指标可以较全面地了解高炉内部的运行状态,为高炉的控制操作提供指导.因此,要实现面向高炉铁水质量和稳定顺行的控制与优化,首先要建立铁水质量的动态模型.
高炉炼铁系统是一个物理化学反应复杂、多相多场耦合的非线性、大滞后、动态时变系统,因此,铁水质量的预测模型应该是一个非线性的动态模型.目前,针对铁水质量建模的研究已有很多,包括基于机理分析的数学模型[4]、基于规则的推理模型[5]以及基于数据的统计模型[6].近些年来,随着计算机的快速发展,数据驱动的建模方法已被广泛应用于解决铁水质量的建模问题.数据驱动是一种黑箱建模方法,它的主要思想是利用一些数学工具和智能算法基于过程数据直接近似得到过程的输入输出关系而不需要任何先验知识[7−9].已有的铁水质量数据驱动建模方法有偏最小二乘法[10]、人工神经网络(Artificial neural network,ANN)[11−12]、支持向量回归机(Support vector regression,SVR)[13−14]等.但是,这些铁水质量预测模型大多只是对单一铁水质量参数硅含量或铁水温度的建模,并不能全面地反映高炉内部复杂的状态,且部分模型并未考虑高炉系统的非线性与动态特性.另外,这些以铁水质量软测量为目标的输入输出智能模型用于解决铁水质量尤其是多元铁水质量控制系统设计时,总是存在诸多局限性和不足.虽然,Zeng等[15]采用子空间辨识方法建立了铁水硅含量的线性输入输出预测模型,Marutiram等[16]采用线性回归的方法建立了铁水硅含量的线性ARMA(Auto regressive and moving average)预测模型,并且二者均针对建立的线性模型进行了预测控制,取得了一定的效果.但是,高炉本身是一个极其复杂的非线性动态系统,用线性模型去近似非线性系统,并不能完全准确地表征铁水质量,因而,基于线性模型的线性控制方法也难于对多元铁水质量指标进行有效控制.
针对上述问题,为了建立一种既适合于控制器设计,又能充分体现高炉非线性动态特性,同时又无需任何先验知识的高炉炼铁多元铁水质量非线性预测模型,本文首先采用典型相关性分析与相关性分析相结合的方法选取与铁水质量相关性最强的高炉本体可控变量作为模型的输入变量,然后采用基于LS-SVM(Least square support vector machine)的非线性子空间辨识方法[17]建立数据驱动的多元铁水质量非线性状态空间动态模型.同时,将核函数表示的非线性特性用多项式函数拟合,以降低模型的复杂度.最后基于实际工业现场数据进行工业试验和比较分析.状态空间模型是现代控制理论的经典模型,针对此模型的控制方法研究已有很多,且理论也很成熟.另外,Hammerstein模型由于其特殊的线性与非线性模块串联结构,相较于SVR和ANN等非线性智能模型,更易于设计非线性控制器.所以本文建立的多元铁水质量模型可以直接应用于多元铁水质量的控制研究中,是一种面向控制的模型.
1 建模策略
从提高产品质量、节约能源的角度而言,高炉系统控制与优化的主要对象是铁水质量参数,尤其是铁水[Si]和铁水温度,它们也是衡量高炉内热状态和稳定顺行的重要参数,其过高和过低对于燃料消耗和成本有较大的影响.为此,对铁水质量参数进行建模意义重大,这也是实现铁水质量控制与优化的关键.针对前述已有铁水质量建模存在的诸多问题,提出图2所示的多元铁水质量非线性动态建模策略:
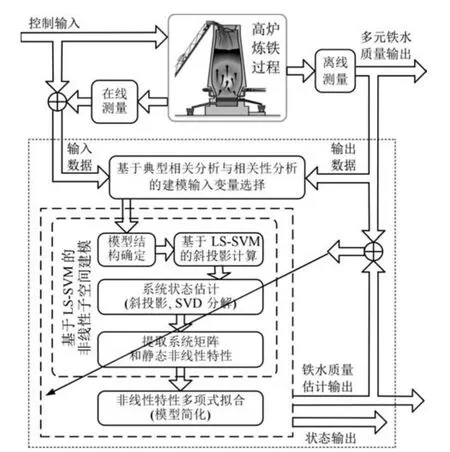
图2 多元铁水质量参数非线性子空间建模策略Fig.2 Strategy diagram of multivariable nonlinear dynamic modeling for molten iron quality
1)高炉本体参数较多,且变量之间存在着较强的相关性,若所有的变量均被用来建立铁水质量模型,势必会增大建模过程的计算复杂度,影响模型的准确性和有效性.已有的铁水质量建模研究中,辅助变量的选取方法有机理分析、主成分分析(Principle component analysis,PCA)和相关性分析等[11−12,18−19],但是这些选取方法大多是针对单一铁水质量,并未考虑对多个铁水质量指标的综合影响,且已有研究中选取的变量多是针对建模问题的,在控制问题中有些变量并不适用.所以,采用典型相关性分析方法选择与铁水质量指标相关性最大的几个可控变量,并用相关性分析方法对这些可控变量做进一步筛选,去除冗余变量.
2)子空间辨识建模是一种由输入输出数据辨识系统状态空间模型的方法,它有三种基本算法,分别为N4SID(Numerical algorithms for subspace state space system identification)[20]、MOESP (Multi-variable output error state space)[21]、CVA (Canonical variate analysis)[22].子空间辨识可以在系统状态完全未知的情况下,仅由输入输出数据将系统的状态估计出来,从而构造系统的状态空间模型.本文采用基于LS-SVM的非线性Hammerstein系统子空间建模方法[17]建立多元铁水质量参数的状态空间模型.该方法在传统线性子空间建模算法N4SID基础上,引入LS-SVM去解决无需任何先验知识的静态非线性环节的辨识问题,最终可建立一个能够较为准确刻画炼铁过程动态特性和非线性特性的状态空间模型.该模型不但能准确地对多元铁水质量进行在线动态估计,并且可用于解决面向多元铁水质量的控制和优化问题.
3)由于基于LS-SVM非线性Hammerstein子空间模型的非线性特性是用核函数表示,计算效率较低.因此,采用多项式拟合方法[23]拟合模型的非线性特性,即将核函数表示的非线性部分替换为计算较为简单的多项式表达式,以降低模型的计算复杂度.
2 建模算法
2.1 基于典型相关分析和相关性分析的建模辅助变量选择
典型相关分析的基本思想与PCA类似,首先在两组变量(2)所示,(y1,y2,···,yq)中分别找出变量的一个线性组合,即
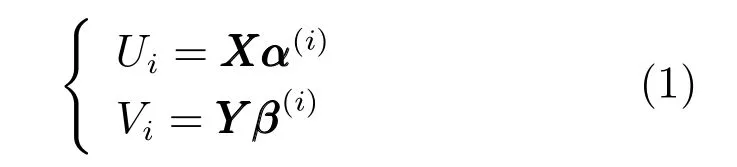
式中,α(i),β(i)分别为线性组合的系数向量,使得两组线性组合之间具有最大的相关系数.然后选取相关系数仅次于第一对线性组合并且与第一对线性组合不相关的第二对线性组合,如此继续下去,直到两组变量之间的相关性被提取完毕为止.Ui,Vi的配对称为典型变量,它们之间的相关系数称为典型相关系数.
在进行辅助变量选择时,首先要对各对典型变量的典型相关系数进行显著性检验,若某一对典型变量的相关程度不显著,说明这对变量不具有代表性,舍弃这一对典型变量.因为Ui中系数绝对值较大的n个变量对Ui起决定性作用,所以若Ui,Vi的相关程度显著且又具有很大的相关系数,则这n个变量便与Vi,即中q个变量的线性组合具有很大的相关性.因此,选取辅助变量时,先找出相关程度显著且典型相关系数较高的几对典型变量,然后选取这几个Ui中线性组合系数绝对值较大的几个变量作为候选辅助变量.
在高炉本体变量中,各个变量均具有一定的相关性,若两个变量相关性达到80%以上,则可近似认为二者呈线性关系,不必将二者同时选为辅助变量.因此,在确定辅助变量时,要用相关性分析的方法对候选辅助变量进一步缩减,缩减的原则是保留可控变量,舍弃不可控变量.
2.2 基于LS-SVM的非线性Hammerstein系统子空间建模
Hammerstein模型是一类非线性系统,由静态非线性环节和动态线性环节串联而成.这种模型能较好地反映过程特征,可以描述一大类非线性系统,如无线发射器[24]、聚丙烯牌号切换系统[25]、燃料电池[26]、生物系统[27]等.在状态空间模型输入端加入静态非线性函数即构成Hammerstein模型,如式

在文献[17]中,Goethals等以预测为目的提出了一种针对如式(2)所示的多输入多输出Hammerstein系统的系统辨识方法.通过将N4SID算法中的斜投影计算问题改写为一系列分量形式的LS-SVMs回归问题,从而对N4SID算法进行非线性扩展.Goethals等指出Hammerstein系统中的线性模型和式(2)中的静态非线性特性可以通过对LS-SVMs回归问题得到的矩阵进行低秩逼近得到.具体建模过程描述如下.
2.2.1 计算斜投影
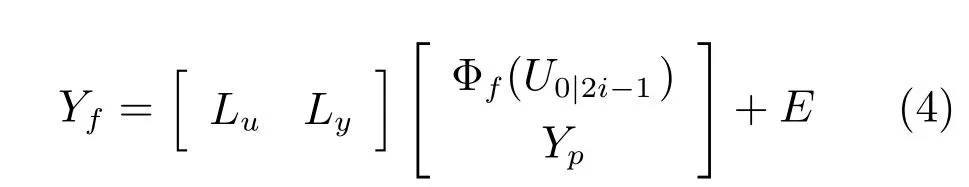
式(4)亦可写为

式中,s=1,···,li,t=1,···,j.一旦式(4)、(5)中的的估计值通过最小二乘法确定下来,斜投影可计算如下:
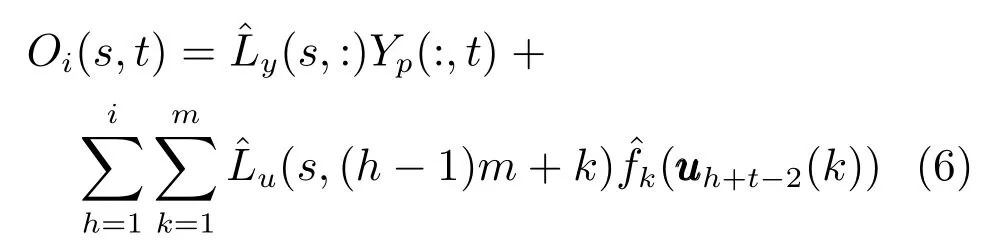
然而式(5)中包含参数矩阵Lu与非线性函数f的相乘项,使得优化问题非凸,为此引入一组函数gh,s,k:R→R,

式(10)的形式可以方便地引入核函数及分量形式(Componentwise)LS-SVM的方法去估计参数.

式中,ψ:Rn→Rn,δu,δy均为常数向量.由于系统模型加入了一个新的参数δy,因此式(10)变换为

式中⊗表示Kronecker积.对于所有h=1,···,2i, s=1,···,li,均有则原LS-SVM回归问题可表示为一个有约束的优化问题

通过构造式 (12)的拉格朗日函数 (Lagrangian),Ly和δy的估计值可以从如下对偶系统求解
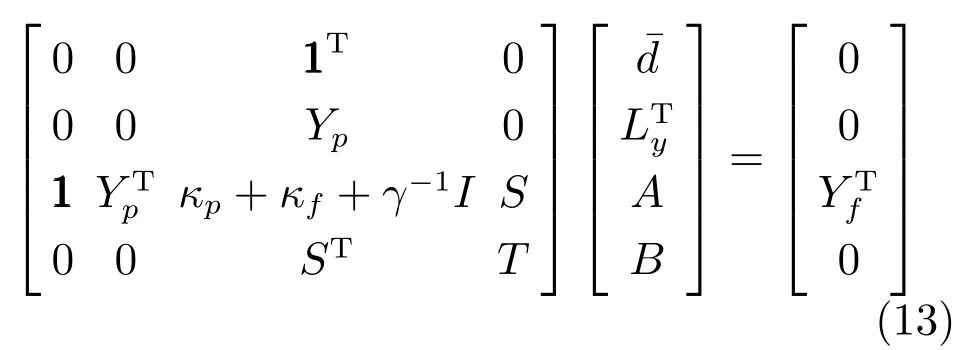

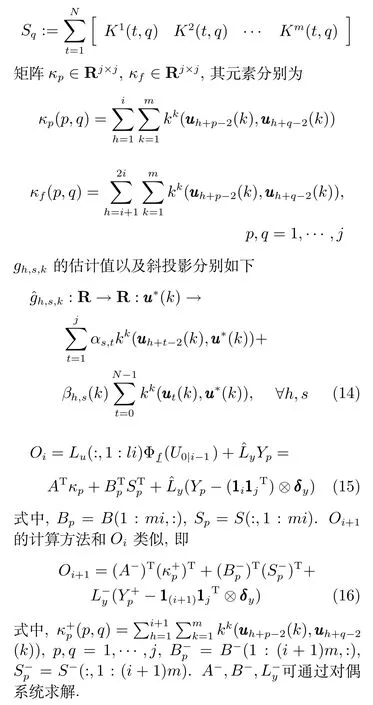
2.2.2 系统状态估计
2.2.3 提取系统矩阵和静态非线性函数
系统矩阵和静态非线性可由式(17)估计得出

如同上节,这个最小二乘问题依然可以变为一个LS-SVM回归问题,定义

式中,E为式(17)的残差.则LS-SVM回归的原始问题可以写为

式中,γBD为一个正则化常数,与第2.2.1节中的γ相区别.
式(18)所示ΘAC中的系统矩阵A,C可由如下所示的对偶问题求出:
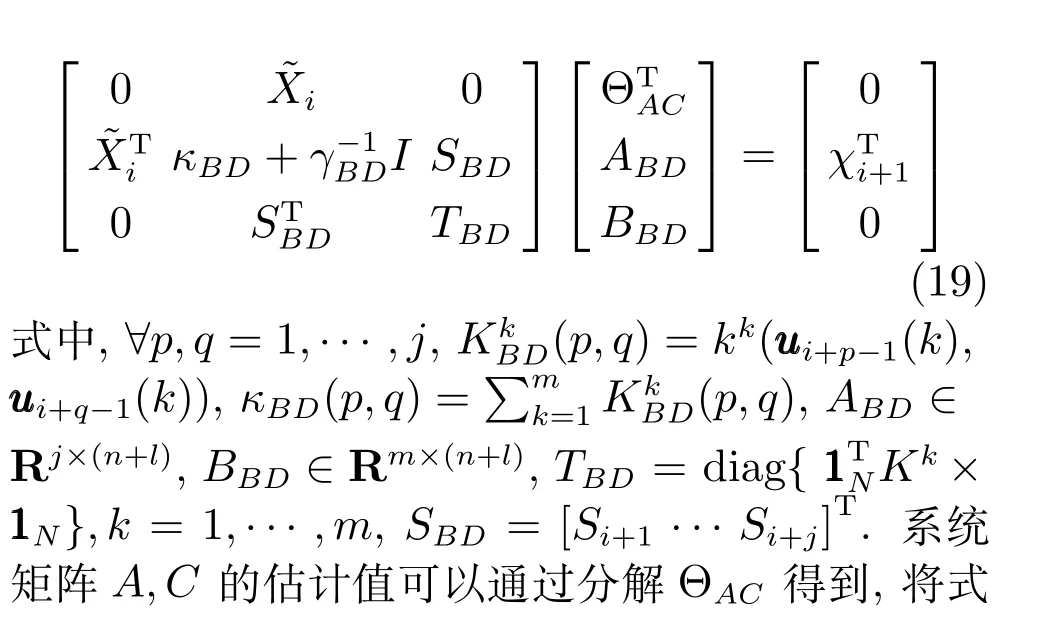

对ΘBD中的系统矩阵B,D的第k列和非线性特性的估计可通过奇异值分解(SVD)得到.
2.3 多项式拟合模型静态非线性特性

然后,将多项式曲线拟合问题转化为如下最小二乘问题求解

利用多元函数求极值方法,分别对ai求偏导,可得m+1个方程,写成矩阵形式如式(22)所示.
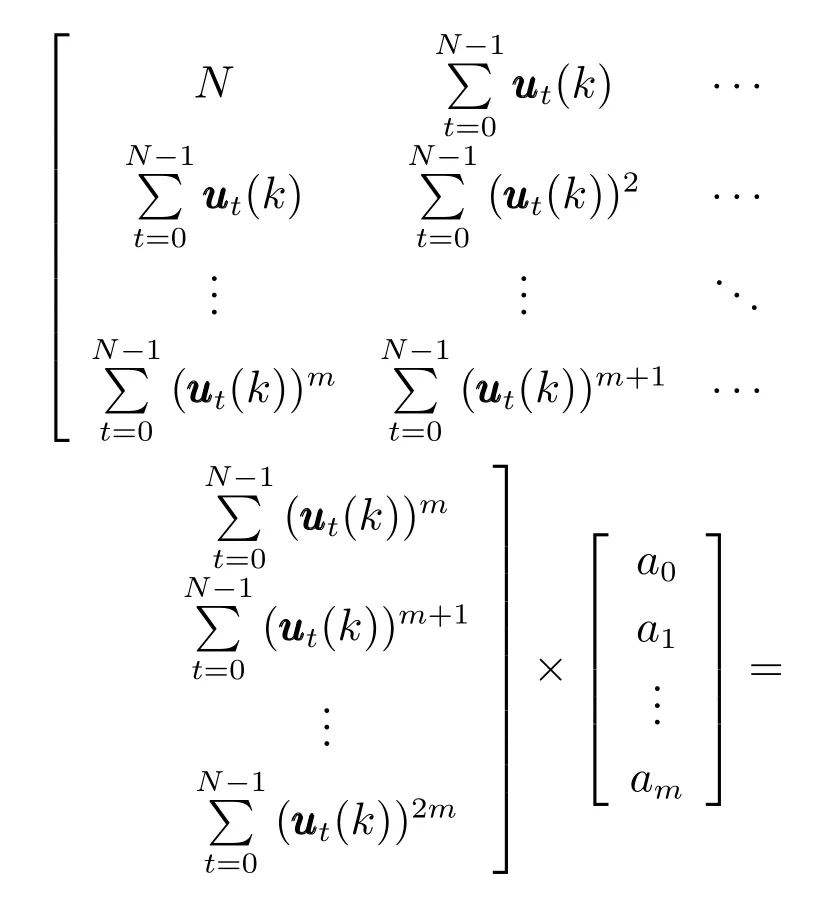

求解如式(22)所示的关于a0,a1,···,am的线性方程组,即可获得非线性特性的多项式函数表达式.从而,Hammerstein模型中用核函数表示的静态非线性特性可由多项式函数取代,降低了模型的复杂度.
2.4 建模算法实现步骤
基于前述讨论,最终的输入变量选择及非线性子空间辨识建模过程可以总结如下:
1)根据式(1)针对输入输出数据求典型相关性系数.
2)进行显著性检验和相关性分析,以此确定建模输入变量.
3)根据式(15)和式(16)计算斜投影Oi和Oi+1.
4)通过对斜投影Oi,Oi+1进行SVD分解估计出系统的状态.
5)根据式(19)获得系统矩阵A,C及ABD,BBD的估计值.
6)通过对式(20)进行秩为1的近似,获得系统矩阵B,D的第k列及非线性特性
3 工业实验
3.1 模型建立
本文基于柳钢2#高炉的实际生产数据进行工业试验,建立多元铁水质量模型.由生产现场数据库可得18个高炉主体参数分别为:送风比、热风压力、顶压、压差、顶压风量比、透气性、阻力系数、热风温度、富氧流量、富氧率、设定喷煤量、鼓风湿度、理论燃烧温度、标准风速、实际风速、鼓风动能、炉腹煤气量、炉腹煤气指数.在建立高炉多元铁水质量模型之前,首先要从这18个高炉主体参数中确定出对多元铁水质量影响最大的几个辅助变量.应用第2.1节基于典型相关分析和相关性分析的方法进行建模输入变量选择.首先,采用典型相关分析的方法针对柳钢2#高炉2013年10月10日到18日的200组(采样间隔为1h)高炉本体数据与铁水质量数据进行分析,去除相关性不显著的1对典型变量,得到相关系数分别为0.715、0.571、0.531的3对典型变量,典型相关分析结果如表1所示.
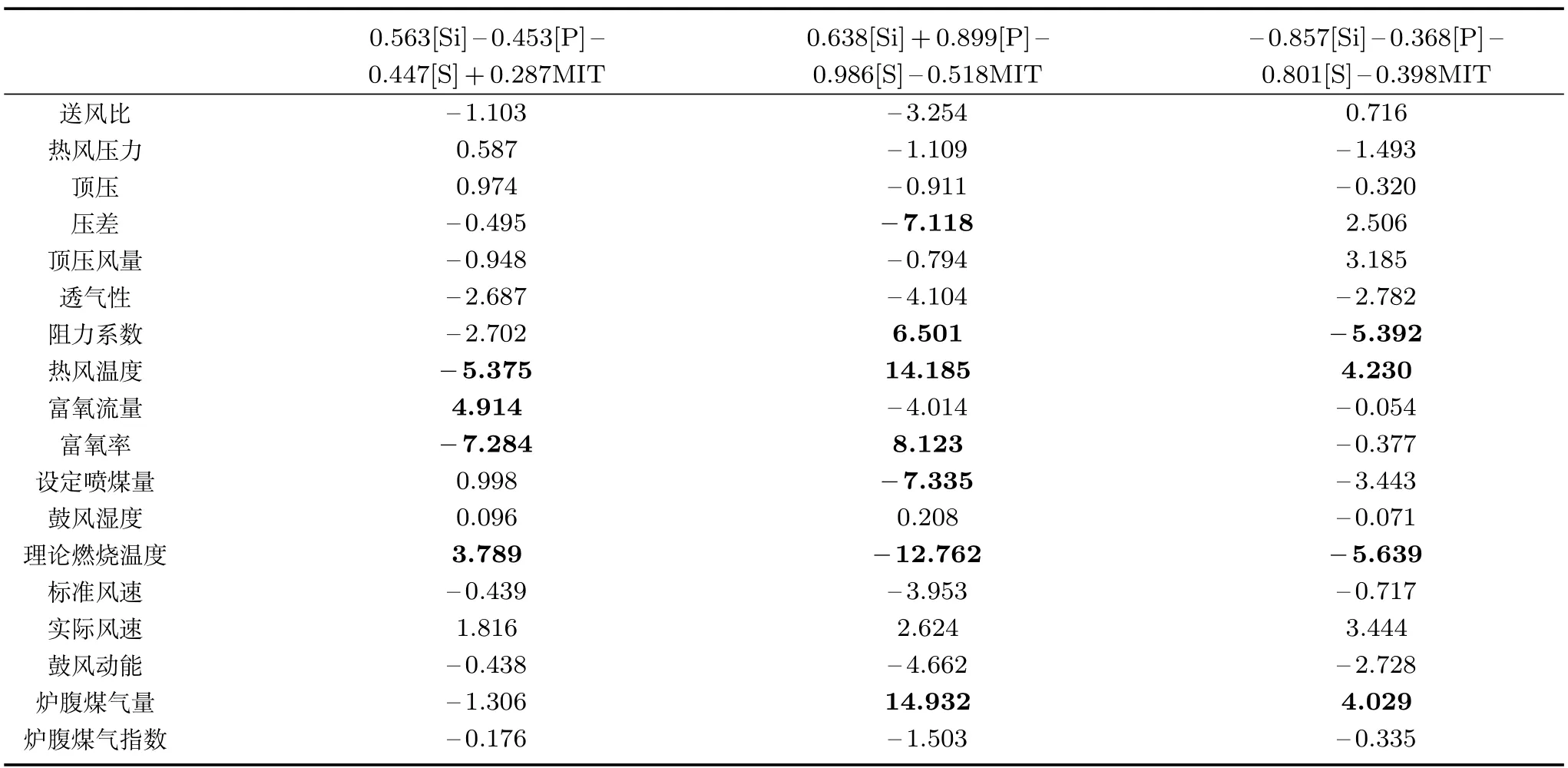
表1 典型相关分析结果Table 1 The results of canonical correlation analysis
选出表1中对输出典型变量影响较大的几个高炉主体参数作为候选辅助变量,即压差、阻力系数、热风温度、富氧流量、富氧率、设定喷煤量、理论燃烧温度和炉腹煤气量.然后通过相关性分析的方法选出候选辅助变量中相关性较大的几组中的可调控变量,如富氧流量与富氧率的相关系数为0.999,选取富氧率;理论燃烧温度和富氧率的相关系数为0.78,舍弃理论燃烧温度.压差和阻力系数均为模型间接计算值,考虑到压差和阻力系数均通过热风压力计算得出,且热风压力可控,所以选取热风压力替代压差和阻力系数.炉腹煤气量由富氧流量、设定喷煤量等可调控量计算得来,为间接可调控量,所以选为辅助变量.最终确定用于建模的可调可控辅助变量为热风压力、热风温度、富氧率、设定喷煤量和炉腹煤气量.另外,为了反映高炉的非线性动态特性以及输入输出变量的时序关系,将上一采样时刻辅助变量测量值以及上一采样时刻多元铁水质量值,连同当前采样时刻输入辅助变量检测值共同作为动态模型的综合输入.
高炉是一个强噪声系统,因此在建模前首先要对工业现场采集到的实际生产数据进行数据预处理.针对由于高炉炉况不稳定和检测仪器不精确造成的跳变数据,采用异常值检测算法剔除高炉生产过程中的噪声尖峰跳变数据;然后采用移动平均滤波算法减弱训练数据中的高斯噪声干扰.之后基于预处理后的数据,采用本文所提方法进行多元铁水质量参数的非线性状态空间模型建模,并采用遗传算法优化模型可调参数σ,γ,γBD.当可调参数确定为σ=1,γ=0.67,γBD=1时,得到的模型如式(23)所示:


图3 多项式拟合非线性Fig.3 Polynomial fitting for nonlinearity
3.2 建模及其估计效果
图4为建立的非线性状态空间模型在多项式拟合非线性特性前后对多元铁水质量参数(即[Si],[P], [S]和MIT)的建模效果比较,图5为建立的非线性状态空间模型在多项式拟合非线性特性前后对实际数据的多元铁水质量参数估计效果比较.可以看出多项式拟合非线性特性的式(23)所示模型及用核函数表示非线性特性的模型得到的多元铁水质量预测值的大小和变化趋势几乎完全一致,两种表示形式的非线性子空间辨识建立的多元铁水质量模型均具有非常高的建模和估计精度,建模误差以及估计误差均非常小,且变化趋势与其实际值非常一致,即模型估计输出与其实际值已基本吻合.另外,由于建立的模型既能对多元铁水质量输出进行准确估计,并且还能输出系统的状态估计曲线,因而可更好地用于各种控制算法的研究和设计.
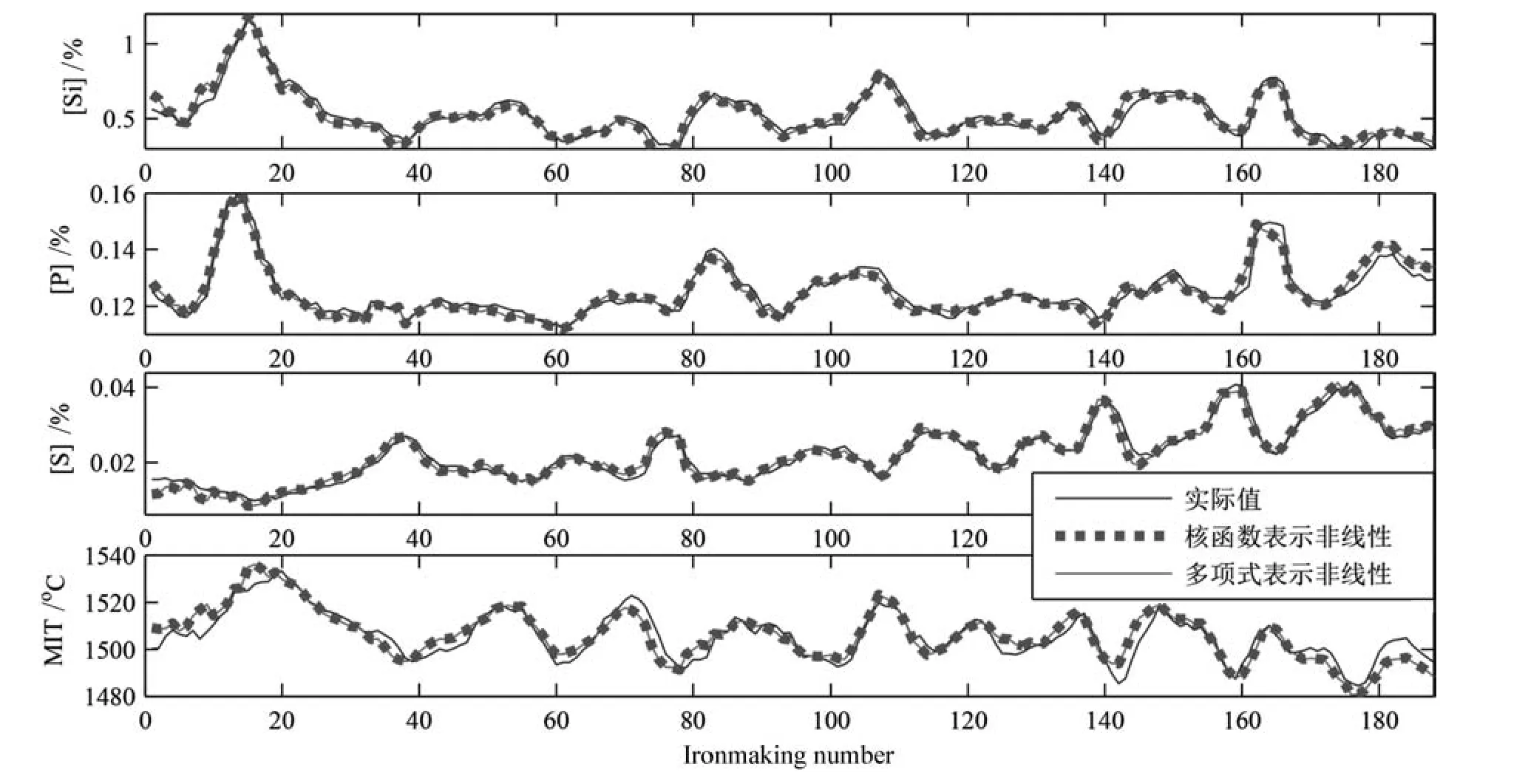
图4 基于非线性子空间辨识的多元铁水质量模型在多项式拟合非线性特性前后的建模结果Fig.4 Modeling results of molten iron quality prediction with and without polynomial fitting
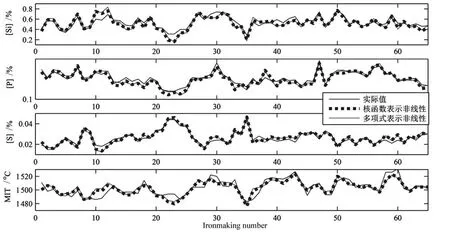
图5 模型在多项式拟合非线性特性前后对多元铁水质量参数的实际估计效果Fig.5 Estimation results of molten iron quality prediction with and without polynomial fitting
为了进一步说明多项式拟合非线性特性的模型相比于核函数表示非线性特性模型的优越性,计算二者在实际数据上预测的均方根误差(Root mean square error,RMSE)及计算时间进行定量分析.在实际工业测试数据计算得到的两种模型的估计RMSE和计算时间如表2所示.可以看出两种模型的预测精度相差非常小,核函数表示非线性特性的模型略好于多项式拟合非线性特性的模型,但是在计算时间上多项式拟合非线性特性的模型要明显优于核函数表示非线性特性的模型,计算效率提高了十几倍.因此,综合以上的分析和评价,可以看出多项式拟合非线性特性的多元铁水质量非线性Hammerstein模型可以在损失非常小建模精度的前提下,大大降低模型复杂度,提高实际应用过程中的计算效率.

表2 两种模型对各个铁水质量指标估计的均方根误差和计算时间比较Table 2 Comparison between two models in RMSE for molten iron quality prediction and computation time
为了进一步验证本文方法的优越性,将本文建模方法即多项式拟合非线性特性的模型(Nonlinear subspace model,N-SM)与文献[20]提出的线性子空间辨识(Linear subspace model,L-SM)方法、文献[28]提出的多输出LS-SVR(Multi-output least square vector regression,M-LS-SVR)方法以及常见的RLS-ARMA(Recursive least square-auto regressive and moving average)方法进行比较研究.这几种方法根据实际工业数据对多元铁水质量的估计效果如图6所示.可以看出,本文模型得到的各个铁水质量参数的估计值相比其他方法能够更好地拟合真实值的变化趋势,且能保证较高的精度,具有更好的估计性能.为了进一步说明这个问题,引入误差自相关函数来评价不同方法的建模性能.众所周知,一个好的模型,它的估计误差自相关函数曲线应该近似为一个白噪声序列.所以,画出不同建模方法得到的模型的估计误差自相关函数曲线,如图7所示.可以看出,相对于L-SM、M-LS-SVR以及RLS-ARMA这几种算法,本文模型4个铁水质量参数估计误差自相关曲线综合来说更加接近于白噪声序列.
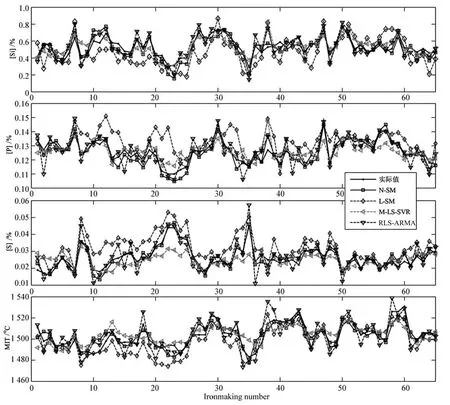
图6 不同建模方法对多元铁水质量的实际估计效果对比Fig.6 Estimation results of molten iron quality prediction with different models
另外,为了进一步对比不同模型的估计精度,将铁水质量的实际值与模型估计值分别作为横、纵坐标,画出上述各个方法对各个指标的估计值与实际值散点图,并求出各个散点图回归线的斜率.由图8可以看出,相较于L-SM、M-LS-SVR以及RLSARMA这几种建模方法,本文建立的模型得到的各个铁水质量参数散点更加集中地分布在对角线附近,且回归线的斜率更加接近于1,这进一步表明本文模型得到的多元铁水质量估计值更加接近于各个指标参数的实际值.评价一个模型的精度通常还会选用一些标准的统计指标,如均方误差(MSE)、均方根误差(RMSE)等.本文选用RMSE作为评价指标对4种不同模型的估计精度进行定量评估.在实际工业测试数据计算得到的各个模型的估计RMSE如表3所示.可以看出本文模型对各个铁水质量指标的RMSE数值均为最小,这进一步验证了建立的模型具有最好的估计精度.

表3 多元铁水质量估计值均方根误差比较Table 3 RMSE for molten iron quality prediction
3.3 应用于多元铁水质量非线性预测控制
为了进一步验证本文方法建立的多元铁水质量模型的有效性,将建立的Hammerstein状态空间模型作为预测模型应用于多元铁水质量的非线性预测控制.预测控制的性能指标如式(25)所示.

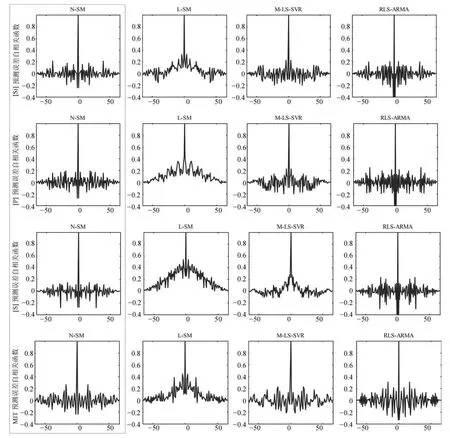
图7 不同模型估计误差自相关函数Fig.7 Autocorrelation function of estimating error of different models
选取预测时域Np为1,控制时域Nc为1,控制项权重R为0.001.多元铁水质量的初始设定值为[Si]=0.45%,[P]=0.115%,[S]=0.025%, MIT=1500°C,在20、40、60、80时刻分别更改设定值,将设定值分别更改为MIT=1510°C, [S]=0.015%,[P]=0.125%,[Si]=0.50%,在100、120、140、160、180时刻分别对热风压力(u1)、热风温度(u2)、富氧率(u3)、设定喷煤量(u4)、炉腹煤气量(u5)加入较大的脉冲干扰,得到的多元铁水质量响应曲线如图9所示,控制量曲线如图10所示.可以看出4个铁水质量参数均能够快速地跟随设定值的阶跃变化,且达到稳态时与设定值的偏差较小,在对输入变量加入较大干扰时,铁水质量参数能够从较大的波动中迅速地回到设定值,有效地抑制干扰.实验结果验证了基于本文模型的非线性预测控制在多元铁水质量控制上的有效性.

图8 不同建模方法的估计值与实际值散点图Fig.8 Scatter diagram of estimated and actual value by different models
综合,可以看出本文建立的模型应用于多元铁水质量在线估计与预测时,具有较好的估计性能.另外,本文方法是一种面向控制的非线性系统状态空间建模方法,建立的多元铁水质量非线性状态空间模型不仅可以用于多元铁水质量参数的在线估计,为工业现场的操作人员提供指导,并且还可进一步应用于铁水质量的控制与优化.
4 结论

图9 多元铁水质量预测控制结果Fig.9 Predictive control results of molten iron quality parameters
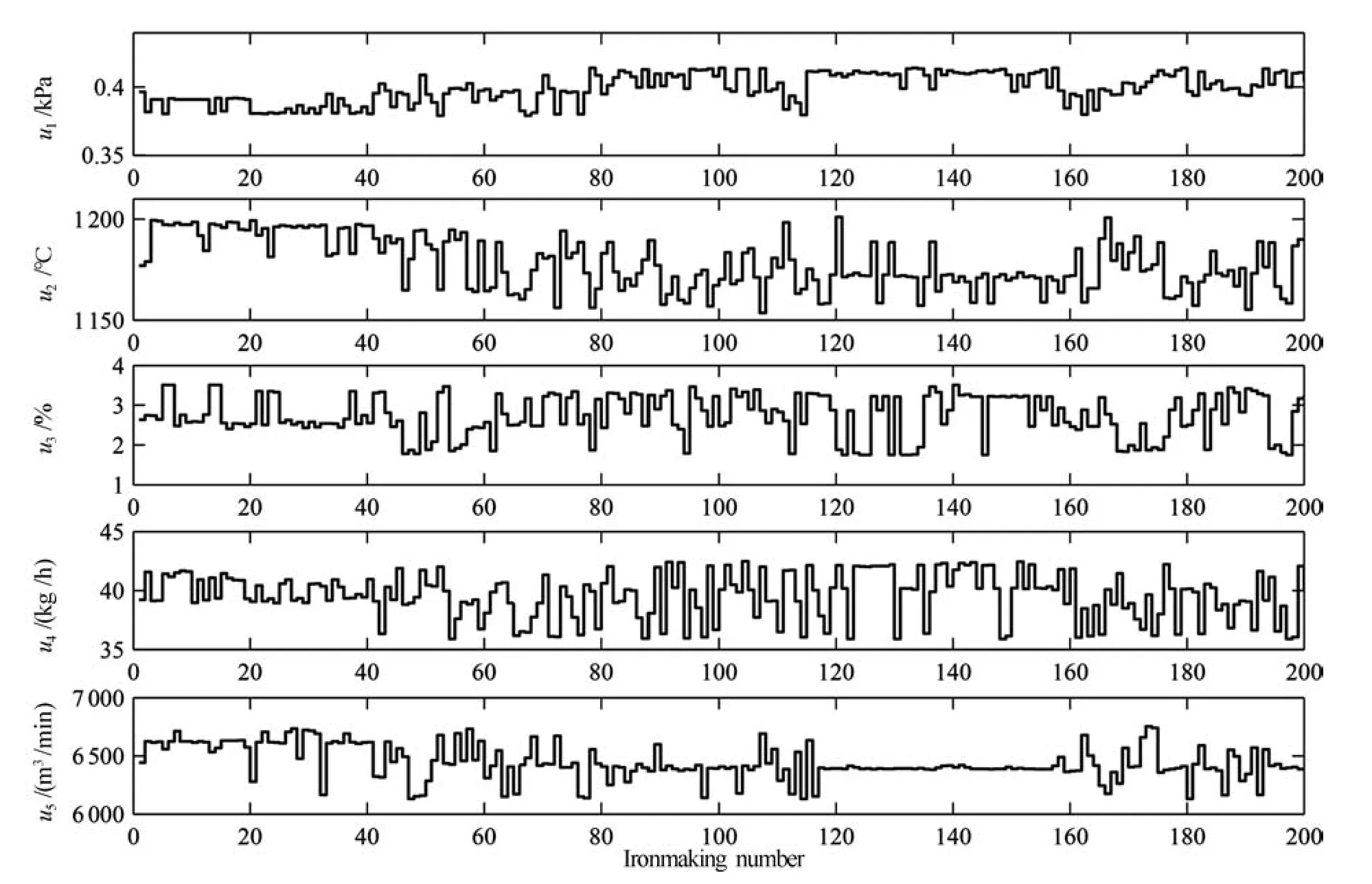
图10 多元铁水质量预测控制控制量曲线Fig.10 Control input curves of predictive control of molten iron quality parameters
高炉炼铁的最终任务是生产出符合要求的铁水.因此,面向[Si]、[P]、[S]和铁水温度等多元铁水质量参数的建模、控制与优化历来是高炉炼铁生产及其控制工程非常重要的一环.本文针对现有铁水质量参数建模的诸多不足,提出一种面向控制的数据驱动高炉炼铁多元铁水质量参数非线性子空间建模方法.首先,为了提高建模效率和降低计算复杂度,采用典型相关性分析与相关性分析相结合的方法从众多关联变量中提取与铁水质量相关性最强的5个关键可控变量作为建模输入变量;然后基于实际工业现场数据,采用基于LS-SVM的非线性Hammerstein系统子空间辨识方法,建立数据驱动的多元铁水质量非线性状态空间动态模型,并将核函数表示的非线性特性用多项式函数拟合,以降低模型的复杂度.工业试验结果表明:建立的模型不仅能够对多元铁水质量参数进行准确在线估计,而且可很好地用于面向铁水质量参数的控制研究.
1 Gao C H,Jian L,Luo S H.Modeling of the thermal state change of blast furnace hearth with support vector machines.IEEE Transaction on Industrial Electronics,2012, 59(2):1134−1145
2 Kuang S B,Li Z Y,Yan D L,Qi Y H,Yu A B.Numerical study of hot charge operation in ironmaking blast furnace. Minerals Engineering,2014,63:45−56
4 Das S K,Kumari A,Bandopadhay D,Akbar S A,Mondal G K.A mathematical model to characterize effects of liquid hold-up on bosh silicon transport in the dripping zone of a blast furnace.Applied Mathematical Modeling,2011,35(9): 4208−4221
5 Zarandi M H F,Ahmadpour P.Fuzzy agent-based expert system for steel making process.Expert Systems with Applications,2009,36(5):9539−9547
6 Chao Y C,Su C W,Huang H P.The adaptive autoregressive models for the system dynamics and prediction of blast furnace.Chemical Engineering Communications,1986, 44(1−6):309−330
7 Hou Z S,Wang Z.From model-based control to data-driven control:survey,classification and perspective.Information Sciences,2013,235:3−35
8 Hou Z S,Jin S T.Data-driven model-free adaptive control for a class of MIMO nonlinear discrete-time systems.IEEE Transactions on Neural Networks,2011,22(12):2173−2188
9 Zhou P,Lu S W,Chai T Y.Data-driven soft-sensor modeling for product quality estimation using case-based reasoning and fuzzy-similarity rough sets.IEEE Transactions on Automation Science and Engineering,2014,11(4): 992−1003
10 Shi L,Li Z L,Yu T,Li J P.Model of hot metal silicon content in blast furnace based on principal component analysis application and partial least square.Journal of Iron and Steel Research,International,2011,18(10):13−16
11 Zhou P,Yuan M,Wang H,Wang Z,Chai T Y.Multivariable dynamic modeling for molten iron quality using online sequential random vector functional-link networks with self-feedback connections.Information Sciences,2015,325: 237−255
12 Yuan M,Zhou P,Li M L,Li R F,Wang H,Chai T Y. Intelligent multivariable modeling of blast furnace molten iron quality based on dynamic AGA-ANN and PCA.Journal of Iron and Steel Research,International,2015,22(6): 487−495
13 Tang X L,Zhuang L,Jiang C J.Prediction of silicon content in hot metal using support vector regression based on chaos particle swarm optimization.Expert Systems with Applications,2009,36(9):11853−11857
14 Liu Y,Gao Z L.Enhanced just-in-time modelling for online quality prediction in BF ironmaking.Ironmaking and Steelmaking,2015,42(5):321−330
15 Zeng J S,Gao C H,Su H Y.Data-driven predictive control for blast furnace ironmaking process.Computers and Chemical Engineering,2010,34(11):1854−1862
16 Marutiram K,Radhakrishnan V R.Predictive control of blast furnaces.In:Proceedings of the 1991 IEEE International Conference on EC3–Energy,Computer,Communication and Control Systems(TENCON'91).New Delhi,India: IEEE,1991.488−491
17 Goethals I,Pelckmans K,Suykens J A K,De Moor B. Subspace identification of Hammerstein systems using least squares support vector machines.IEEE Transactions on Automatic Control,2005,50(10):1509−1519
19 Phadke M,Wu S M.Identification ofmultiinputmultioutput transfer function and noise model of a blast furnace from closed-loop data.IEEE Transactions on Automatic Control,1974,19(6):944−951
20 Van Overschee P,De Moor B.N4SID:subspace algorithms for the identification of combined deterministic-stochastic systems.Automatic,1994,30(1):75−93
21 Verhaegen M,Dewilde P.Subspace model identification part 1.The output-error state-space model identification class of algorithms.International Journal of Control,1992,56(5): 1187−1210
22 Larimore W E.Canonical variate analysis in identification, filtering,and adaptive control.In:Proceedings of the 29th Conference on Decision Control.Honolulu,HI:IEEE,1990. 596−601
23 Liu Y,Gao Y C,Gao Z L,Wang H Q,Li P.Simple nonlinear predictive control strategy for chemical processes using sparse kernel learning with polynomial form.Industrial& Engineering Chemistry Research,2010,49(17):8209−8218
24 Moon J,Kim B.Enhanced Hammerstein behavioral model for broadband wireless transmitters.IEEE Transactions on Microwave Theory and Techniques,2011,59(4):924−933
25 He De-Feng,Yu Li.Nonlinear predictive control of constrained Hammerstein systems and its research on simulation of polypropylene grade transition.Acta Automatica Sinica,2009,35(12):1558−1563 (何德峰,俞立.约束Hammerstein系统非线性预测控制及其在聚丙烯牌号切换中的仿真研究.自动化学报,2009,35(12): 1558−1563)
26 Huo H B,Zhu X J,Hu W Q,Tu H Y,Li J,Yang J.Nonlinear model predictive control of SOFC based on a Hammerstein model.Journal of Power Sources,2008,185(1):338−344
27 Su S W,Wang L,Celler B G,Savkin A V,Guo Y.Identification and control for heart rate regulation during treadmill exercise.IEEE Transactions on Biomedical Engineering,2007,54(7):1238−1246
28 Xu S,An X,Qiao X D,Zhu L J,Li L.Multi-output leastsquares support vector regression machines.Pattern Recognition Letters,2013,34(9):1078−1084

宋贺达 东北大学硕士研究生.2013年获得东北大学学士学位.主要研究方向为数据驱动建模与控制,机器学习算法.
E-mail:1401124@stu.neu.edu.cn
(SONG He-Da Master student at Northeastern University.He received his bachelor degree from Northeastern University in 2013.His research interest covers data-driven modeling and control and machine learning algorithm.)

周 平 东北大学副教授.分别于2003年,2006年,2013年获得东北大学学士、硕士和博士学位.主要研究方向为工业过程运行反馈控制,数据驱动建模与控制.本文通信作者.
E-mail:zhouping@mail.neu.edu.cn
(ZHOU Ping Associate professor at Northeastern University.He received his bachelor,master and Ph.D.degrees from Northeastern University in 2003,2006 and 2013,respectively.His research interest covers operation feedback control of industrial process,data-driven modeling and control.Corresponding author of this paper.)

王 宏 中组部“千人计划”教授,国家特聘专家,IET和InstMC Fellow,长江学者讲座教授,英国曼彻斯特大学教授.主要研究方向为非高斯随机系统的随机分布控制,故障检测与诊断,非线性控制,基于数据的复杂系统建模.
E-mail:hong.wang@manchester.ac.uk
(WANG Hong IET,InstMC fellow,professor at the Control System Centre,University of Manchester,Manchester,UK since 2002.His research interest covers stochastic distribution control of non-Gaussian stochastic system,fault detection and diagnosis, nonlinear control,and data-based modeling for complex systems.)

柴天佑 中国工程院院士,东北大学教授,IEEE Fellow,IFAC Fellow.1985年获得东北大学博士学位.主要研究方向为自适应控制,多变量智能解耦控制,流程工业综合自动化理论、方法与技术.
E-mail:tychai@mail.neu.edu.cn
(CHAI Tian-You Academician of Chinese Academy of Engineering,professor at Northeastern University,IEEE Fellow,IFAC Fellow.He received his Ph.D.degree from Northeastern University in 1985.His research interest covers adaptive control,intelligent decoupling control,and integrated automation theory,method and technology of industrial process.)
Nonlinear Subspace Modeling of Multivariate Molten Iron Quality in Blast Furnace Ironmaking and Its Application
SONG He-Da1ZHOU Ping1WANG Hong1,2CHAI Tian-You1
Blast furnace ironmaking is a nonlinear dynamic process containing complex physical-chemical reaction,multiphase multi-field coupling and large time delay.Measuring,modeling and control of the key process indices of ironmaking process,molten iron quality(MIQ)parameters,have always been treated as a difficult problem in metallurgic engineering and automation field.This paper presents a control oriented data-driven nonlinear subspace modeling method for multivariate prediction of MIQ.First,to improve modeling efficiency,data driven canonical correlation analysis(CCA) and correlation analysis(CA)are combined to pick out the most influential controllable variables from multitudinous factors to serve as the input variables of modeling.Second,to better reflect the nonlinear dynamic characteristics of blast furnace ironmaking process,the time series and time delays of the relevant input and output variables are taken into account.Finally,a data-driven nonlinear state-space model of MIQ is built using least square support vector machine (LS-SVM)based nonlinear subspace identification method for Hammerstein system.With polynomial fitting method,the nonlinear parts expressed by kernel functions in the obtained Hammerstein model are simplified,so as to greatly reduce the computational complexity of the model on the premise of only a small loss of accuracy.Industrial experiments based on real data verifies the accuracy,effectiveness and advancement of the proposed method.
Blast furnace ironmaking,subspace identification,Hammerstein model,canonical correlation analysis (CCA),nonlinear system modeling,least square support vector machine(LS-SVM),multivariate molten iron quality
宋贺达,周平,王宏,柴天佑.高炉炼铁过程多元铁水质量非线性子空间建模及应用.自动化学报,2016,42(11): 1664−1679
Song He-Da,Zhou Ping,Wang Hong,Chai Tian-You.Nonlinear subspace modeling of multivariate molten iron quality in blast furnace ironmaking and its application.Acta Automatica Sinica,2016,42(11):1664−1679
2015-12-04 录用日期2016-04-18
Manuscript received December 4,2015;accepted April 18,2016
国家自然科学基金(61473064,61290323,61333007),中央高校基本科研业务费项目(N130108001),辽宁省教育厅科技项目(L20150186)资助
Supported by National Natural Science Foundation of China (61473064,61290323,61333007),the Fundamental Research Funds for the Central Universities(N130108001),the General Project on Scientific Research for the Education Department of Liaoning Province(L20150186)
本文责任编委候忠生
Recommended by Associate Editor HOU Zhong-Sheng
1.东北大学流程工业综合自动化国家重点实验室 沈阳110819 中国2.曼切斯特大学控制系统中心曼彻斯特M60 1QD英国
1.State Key Laboratory of Synthetical Automation for Process Industries,Northeastern University,Shenyang 110819,China 2.Control System Center,Manchester University,Manchester M60 1QD,UK
DOI 10.16383/j.aas.2016.c150819
